 队列ADT,实现与使用接口
队列ADT,实现与使用接口
周立功教授数年之心血之作《程序设计与数据结构》以及《面向AMetal框架与接口的编程(上)》,电子版已无偿性分享到电子工程师与高校群体,在公众号回复【编程】即可在线阅读。书本内容公开后,在电子行业掀起一片学习热潮。经周立功教授授权,本公众号特对《程序设计与数据结构》一书内容进行连载,愿共勉之。
>>>3.6.1建立抽象
队列可以简单的描述为:队列是一种特殊的容器,其限制插入位置在容器的尾部(队尾),删除位置在容器的头部(队头),是一种“先进先出”(First In-First Out,FIFO)的线性结构。比如,排队买票,人们从队尾加入队列,买完票后从队头离开(假定没有人插队),示意图详见图 3.28。
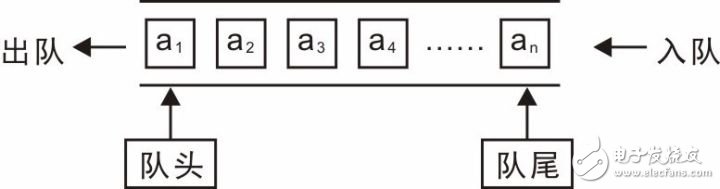
图 3.28 队列示意图
其抽象定义如下:
-
类型名:队列(Queue)
-
类型属性:存储一系列项
-
类型操作:从队尾添加项,从队头删除项,确定队列是否为空,确定队列是否已满,确定队列中的项数。
>>>3.6.2 建立接口
接口是通过头文件向用户提供的。首先创建一个头文件,命名为queue.h。在接口文件中,需要包含两部分内容:其一,抽象类型queueADT的定义;其二,声明各队列ADT的操作函数。
1、定义抽象类型queueADT
与栈类似,使用结构体类型来表示一个队列,在头文件中,只需要定义一个该结构体指针类型即可。结构体实际定义的细节、包含的具体成员无需在头文件中定义,交由具体实现完成对其的定义。定义抽象类型queueADT如下:
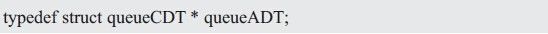
2、接口函数声明
-
创建队列
在使用队列前,必须正确的创建一个队列,因此需要提供一个用于创建新的queueADT的函数。其函数原型如下:

后置条件:返回队列。
其调用形式如下:

-
销毁队列
在创建队列时,具体实现会根据实际情况分配队列相关的存储空间,如队列对象本身的存储空间,队列项的存储空间等。因此,当一个队列不在使用时,应该释放掉队列相关的内存空间,以销毁一个队列,销毁后的队列不再存在,无法继续使用。其函数原型如下:

前置条件:queue为之前创建的队列;
后置条件:释放队列相关的所有内存,队列被销毁,不再有效。
其调用形式如下:

-
从队尾添加项(入队列)
用户通过该函数可以从队列尾部向队列中添加新元素,其函数原型如下:

前置条件:queue为之前创建的队列,value是待加入队尾的数据;
后置条件:如果队列不满,将value添加至队尾,该函数返回true;否则,队列已满,队列保持不变,该函数返回false。
其调用形式如下:
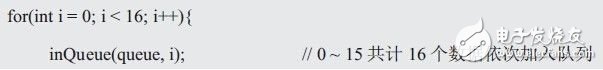
-
从队头移除项(出队列)
用户通过该函数可以从队列头部移除一个元素,其函数原型如下:

前置条件:queue为之前创建的队列,p_value为指向存储“移出队列的值”的变量的指针;
后置条件:如果队列不空,将队头的值拷贝到*p_value,同时删除当前队头,该函数返回true;否则,队列为空,该函数返回false。
其调用形式如下:

-
判断队列是否为空
判断队列是否为空的函数原型如下:
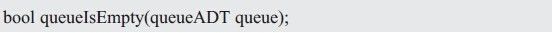
前置条件:queue为之前创建的队列;
后置条件:如果队列为空,则返回true,否则返回false。
其调用形式如下:

-
判断队列是否已满
判断队列是否已满的函数原型如下:

前置条件:queue为之前创建的队列;
后置条件:如果队列为空,则返回true,否则返回false。
其调用形式如下:

-
确定队列中元素的个数
确定栈中元素的个数的函数原型如下:

前置条件:queue为之前创建的队列;
后置条件:返回队列中元素的个数。
其调用形式如下:
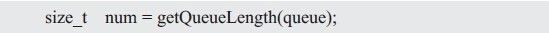
程序清单 3.70 抽象队列接口(queue.h)

>>>3.6.3 实现与使用接口
在实现队列之前,首先需要确定使用何种数据存储结构。一般来说,可以使用地址连续的内存空间存储数据,比如,使用数组或动态分配一段内存空间;也可以使用地址非连续的链表结构存储数据。
1、顺序队列
在实现队列之前,我们先来分析一下顺序队列的原理。顺序队列采用连续的内存空间,假定使用front和rear两个变量来分别表示队头和队尾的位置,初始时,队列为空,队头和队尾都在为0,详见图3.29 (a)。
当从队尾增加数据时,rear增大向后移动,如data0入队列后,示意图详见图3.29 (b),此时,队头front保持不变,队尾rear增加1,继续入队列,data1、data2、data3入队列后的示意图详见图3.29 (c)。
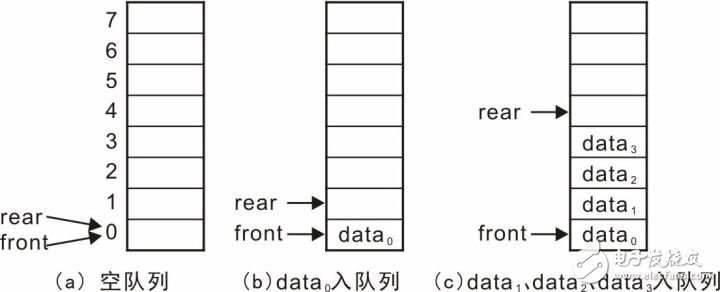
图3.29 队列示意图——入队列
当从队头移除数据时,例如,移除data0后,队头front指向的数据必须更新为data1,这就有两种方式:一是front保持不动,将所有数据向前移动一格,如图3.30(a);二是数据保持不动,front增加1,使其指向data1。显然,将所有数据向前移动一格存在大量的数据拷贝,队列中数据越多,数据拷贝操作就越多,效率也就越低,而将front的值加1是非常简单快捷的,因此,一般来讲,都是选择第二种处理方式。
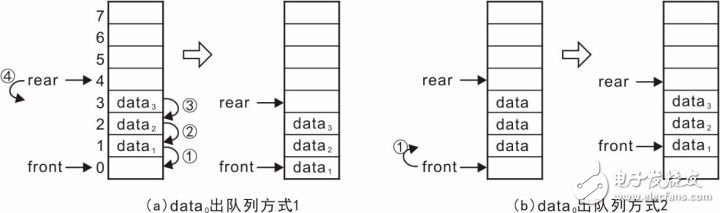
图3.30 队列示意图——出队列
按照方式2,继续将data1、data2、data3出队列,示意图详见图3.31(a),此时,队列中不存在任何有效数据,rear与front相等,队列为空。
若继续进行数据入队列操作,data4、data5、data6、data7依次进入队列后的示意图详见图3.31(b),由于队列元素已经存储至最高地址的存储空间,rear已经指向了无效的地址,这种状态时,不能再简单的按照之前的方式,继续向队尾添加数据,否则会因为数组越界而导致程序异常。
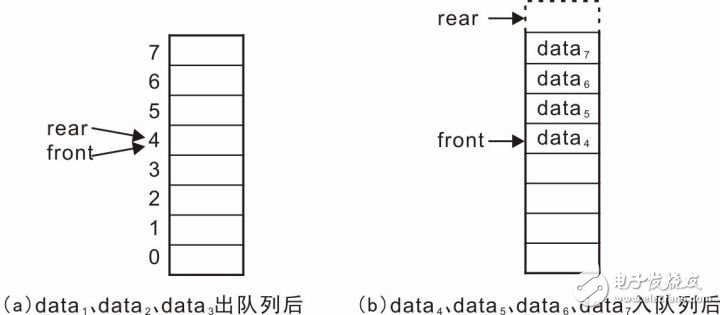
图3.31 继续进行出队列、入队列操作
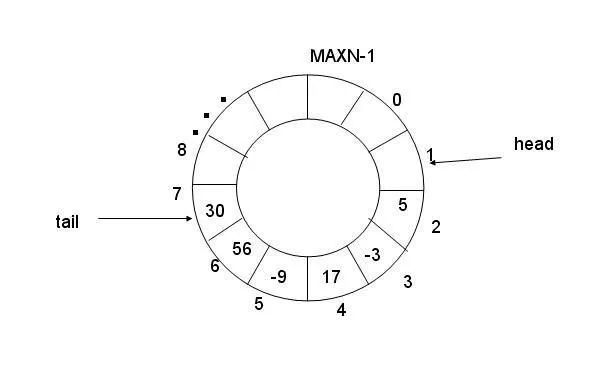
那么,在图3.31(b)所示的情况下,就不能再添加新元素了吗?显然,此时还有一半的空间没有填充数据,一个将空闲空间利用起来的巧妙方法是:当rear或front的值超过最大值后,自动回滚到0。在图3.31(b),rear已经超过了最大地址,因此,将其回滚到0,详见图3.32(a)。即在逻辑上,将顺序队列视为一个环状的空间,详见图3.32(b)。入队列后,不再是简单的将rear值加1,而是当加1后,判断是否超过了最大地址空间,若超过了,则重新将rear的值设置为0。
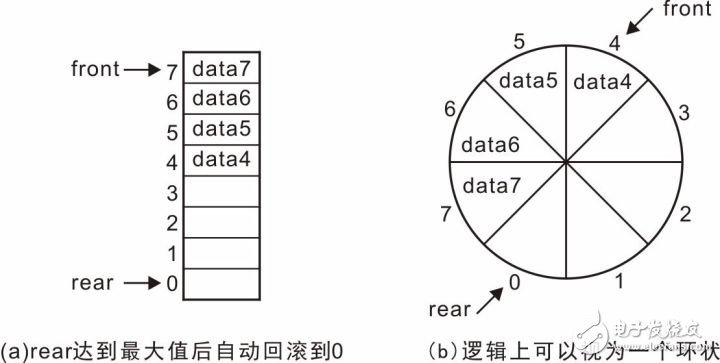
图3.32 循环队列
将存储空间视为一个环状后,将更加方便的理解入队列和出队列操作。入队列时,仅需将数据存储值rear指向的空间中,存储完毕后,将rear的值更新为指向下一个存储单元。出队列时,将front指向的空间中的数据取出,并将front的值更新为指向下一个存储单元。
特别地,当front与rear相等时,表示队列为空,无法进行出队列操作,与之对应的,什么时候队列视已满呢?在图3.32(b)的基础上,继续将data8、data9、data10、data11加入队列,使所有空闲单元都存储数据,可以看到加入各个数据后的示意图详见图3.33。
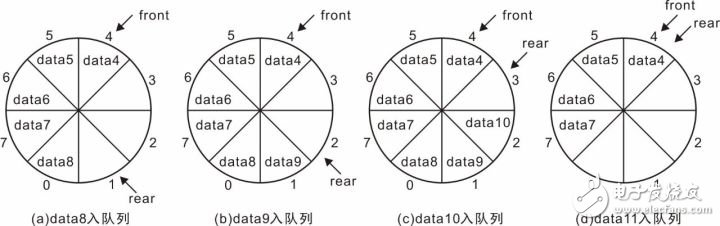
图3.33 data8~data11依次入队列
当data11加入队列后,所有存储单元都存储了数据,此时队列已满,可以看到,当前的front与rear相等,而队列为空时,front与rear也相等。由此可见,只凭front与rear是否相等,无法判断队列是“满”还是“空”。如何解决呢?最简单的方法是增加一个标志,当数据入队列后,出现front与rear相等时,设置该标志位1,以标志当前是“满”状态。而还有一种巧妙的方法,就是实际少用一个存储单元,当front在rear的下一位置时,即图3.33(c)所示状态,就视为队列已满,不再允许新元素加入队列,这种方法的优点是无需增加额外标志,只是将判定队列是否已满的方式修改一下,但其缺点也是很明显的,会浪费一个数据的存储空间。实际上,额外增加标志时,增加的标志也同样需要占用内存空间。
至此,分析了入队列、出队列、判定队列是否为空、判定队列是否为满的实现方法,还剩下最后一个操作没有提及,即确定队列中元素的个数。
而本质上求取元素个数非常简单,只需要将队尾值rear减去队头值front即可,得到的差值即表示队头与队尾之间的数据个数。但需要考虑特殊情况,因为在循环队列中,队尾的值可能小于队头的值,如图3.34(a)、(b)、(c)所示。此时,它们的差值即为负值,如在图3.35(a)中:rear = 1,front = 4,它们的差值为 -3,而实际元素的个数为5。可见,当值为负数时,只需要将其加上存储空间的大小(示例中为8)即可。
上面分析了循环队列的原理,接下来使用程序来实现队列的各个接口,将实现代码全部存放在queue.c文件中。在建立接口时,首先在头文件中定义了抽象队列的类型为:

这里的结构体类型struct queueCDT只有声明,还没有具体的定义。因此无论何种实现方式,都需要先实现struct queueCDT类型的定义。
假定使用的连续空间通过malloc动态分配得到,则在结构体中需要包含一个指向连续空间首地址的指针,以便使用这片内存空间。此外,在上面原理的分析中,需要使用front和rear分别表示队头和队尾的位置,因此队列结构体中需要包含这两个成员,定义队列结构体类型为:

理解了队列各种操作的原理后,则实现起来就较为容易了,详见程序清单 2.34。
程序清单3.71 顺序队列的实现(queue.c)

在getQueueLength()函数的实现中,巧妙地避免了使用if语句判断rear和front的差值是否为负值,差值无论正负,都加上了MAXQSIZE(队列的容量大小)。此时,若差值为负值,则可以得到正确的结果,但若差值为正值,则结果会恰好多出MAXQSIZE,因此最后需要将结果对MAXQSIZE取余,以丢弃可能多出的MAXQSIZE,确保了结果的正确性。
2、链队列
在链队列中,各个数据的存储空间可以不连续,基于链表的队列(假定数据域为int类型)示意图详见图3.36。
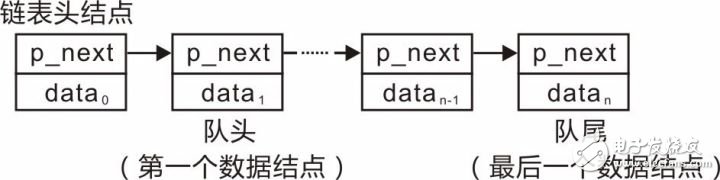
图3.36 链队列示意图
需要注意的是,链表头结点代表的是链表头,为了方便添加结点操作而定义的,不携带有效的应用数据。其后的结点才是有效结点,因此队头是第一个有效的数据结点,队尾是最后一个有效的数据结点。
入队列即将新元素添加至链表尾部,出队列就是移除第一个数据结点。这些操作在链表程序中都已经有相应的接口。因此基于之前的链表程序,实现链队列非常容易。在队列结构体中,仅需包含链表头结点,无需front、rear等成员。定义队列结构体类型为:

若队列中各个结点的数据类型为int类型,则对应的链表结点类型为:

如程序清单3.72所示为一种链队列的实现范例。
程序清单3.72 链队列的实现(queue_list.c)

对于大多数操作而言,链表都已经提供了相应的接口,因此入队列、出队列、判断满或空都非常容易。稍微复杂点的是得到队列中的元素个数,其需要遍历整个链表,每遍历到一个结点时,都将计数器count的值加1(count的地址通过遍历函数的p_arg参数传递),遍历结束后,计数器的值即为队列中的元素个数。
在入队列函数的实现中,每次都需要将新的结点添加至链表尾部,而对于单向链表,直接将结点添加至链表尾部的效率是非常低的,每次都需要从头开始遍历,直到找到最后一个结点,才能执行实际的添加操作。如何解决这个问题呢?最简单的办法是使用双向链表,但双向链表需要占用更多内存,同时,在队列的实现中,并不需要双向链表那么灵活,不需要随意的寻找上一个结点,显然,这里使用双向链表有点“小题大做”了。把握到一个核心的问题,就是需要将新结点添加至链表尾部,如果使用一个指针p_rear来指向尾结点,那么,添加结点至链表尾部时,可以直接将结点添加至p_rear指向的结点后面,无需再从头开始遍历链表,即“slist_add (p_head, p_rear, p_node);”。
添加结束后,新的p_node结点为新的尾结点,因此需要更新p_rear的值,使其指向新的尾结点,即“p_rear = p_node;”。p_rear可以作为队列结构体的一个成员,以便使用。读者可以按照这种方式,自行尝试修改入队列函数,提升入队列的效率。
对于使用者来讲,无需关心队列的具体实现方式。只要正确把握接口的使用方法(前置条件和后置条件),就可以编写使用队列的应用程序。将整数入队列,再出队列的范例程序详见程序清单 2.35。
程序清单3.73 使用队列接口的范例程序

-
程序
+关注
关注
116文章
3773浏览量
80830 -
周立功
+关注
关注
38文章
130浏览量
37578
原文标题:周立功:队列ADT——实现与使用接口
文章出处:【微信号:ZLG_zhiyuan,微信公众号:ZLG致远电子】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
FIFO队列原理简述
ADT6501/ADT6502/ADT6503/ADT650
ADT6501/ADT6502/ADT6503/ADT650
adt6501/adt6502/adt6503/adt6504采用SOT-23微温度开关数据表
AN-1250: ADT7310/ADT7410与基于Cortex-M3的精密模拟微控制器(ADuCM360)的接口






 工商网监
工商网监
评论