 大模型向边端侧部署,AI加速卡朝高算力、小体积发展
大模型向边端侧部署,AI加速卡朝高算力、小体积发展
电子发烧友网报道(文/李弯弯)AI加速卡是专门用于处理人工智能应用中的大量计算任务的模块。它集成了高性能的计算核心和大量的内存,旨在加速机器学习、深度学习等算法的计算过程。当前,AI加速卡市场呈现出快速增长的态势。随着技术的不断演进和成本效益的持续优化,AI加速卡的应用场景日益丰富,市场边界不断拓展。
AI加速卡的核心组成部分
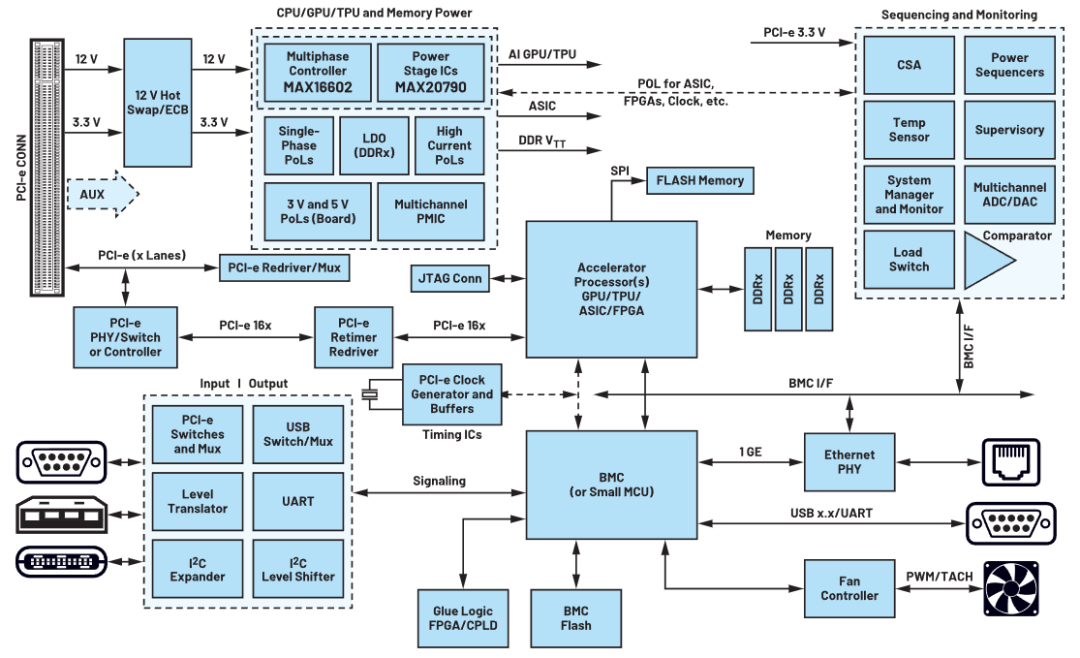
AI加速卡的组成结构相对复杂,包括几个核心的部分:一是计算单元,包括核心处理器,AI加速卡的核心是高性能的计算单元,这些单元可能是基于ASIC(专用集成电路)、GPU(图形处理单元)或FPGA(现场可编程门阵列)等技术。这些处理器针对AI计算任务进行了高度优化,能够提供强大的并行计算能力和高效的算法支持。
还包括Tensor Core/CUDA Core,如在NVIDIA的GPU中,Tensor Core是专门用于加速深度学习等AI任务的计算单元,而CUDA Core则是更通用的计算单元。这些核心能够执行大量的浮点运算,特别是针对矩阵乘法和卷积等AI计算中常见的操作进行优化。
二是内存系统,包括显存,AI加速卡配备了大容量的显存,用于存储计算过程中需要频繁访问的数据和模型参数。显存的容量和带宽对AI加速卡的性能有重要影响。常见的显存类型包括GDDR和HBM,其中HBM(高带宽内存)具有更高的带宽和更低的延迟。还包括内存控制器,负责管理和调度显存中的数据访问,确保计算单元能够高效地获取所需数据。
三是接口与通信,包括PCIe接口,AI加速卡通常通过PCIe(Peripheral Component Interconnect Express)接口与主机系统相连,实现数据的高速传输。PCIe接口的版本和性能会直接影响AI加速卡与主机系统之间的通信带宽。
除了PCIe接口外,一些高端的AI加速卡还可能支持其他高速接口,如NvLink或GPUDirect RDMA等,以进一步提升多GPU或多GPU/CPU系统配置的可扩展性和通信性能。
另外,还有电源与散热,AI加速卡需要稳定的电源供应以确保其正常工作。电源管理系统负责监控和调整AI加速卡的功耗,以平衡性能和能耗之间的关系。由于AI加速卡在工作过程中会产生大量热量,因此需要配备高效的散热系统来保持其稳定运行。散热系统可能包括风扇、热管、散热片等组件。
AI加速卡丰富的应用场景
当前,AI加速卡市场呈现出快速增长的态势。随着技术的不断演进和成本效益的持续优化,AI加速卡的应用场景日益丰富,市场边界不断拓展。在云计算服务、高性能计算、自动驾驶汽车、医疗影像处理、金融服务、智能制造等多个领域,AI加速卡都发挥着核心作用。
在深度学习模型的训练过程中,AI加速卡能够利用其强大的并行计算能力,加速大规模数据的处理和计算,从而缩短模型训练时间。在模型部署后,AI加速卡同样能够加速推理过程,实现快速且准确的预测和响应。这对于实时性要求较高的AI应用,如自动驾驶、智能安防等至关重要。
在图像识别领域,AI加速卡能够快速处理和分析图像数据,提取关键特征并进行分类和识别。这广泛应用于人脸识别、物体检测、场景理解等场景。AI加速卡还能加速图像美化、风格转换等计算密集型任务,提高图像处理的速度和效果。
在自然语言处理领域,AI加速卡还能够加速NLP模型的训练和推理过程,提高文本分类、情感分析等任务的性能和准确性。在机器翻译领域,AI加速卡能够加速翻译模型的计算过程,实现快速且准确的翻译结果。
在AI加速卡领域,NVIDIA、Intel、Xilinx、Google等厂商是主要的竞争者。例如,NVIDIA的GPU产品在AI加速领域具有广泛应用,Intel的Habana Labs和Xilinx的FPGA产品在特定应用场景下表现出色。Google的TPU和华为的Ascend系列ASIC也在市场上占据一定份额。
此外,今年不少厂商积极推出用于边端侧AI加速卡,用于大模型推理,如AI芯片创企芯动力科技今年初面向大模型推出了一款新产品——AzureBlade L系列M.2加速卡。M.2加速卡是目前国内最强的高性能体积小的加速卡,其强大的性能使其能够顺利运行大模型系统。
M.2加速卡的大小仅为80mm(长)x22mm(宽),并已经实现与Llama 2、Stable Diffusion模型的适配。具备体积小、性能强,且有通用接口的M.2加速卡成为助推大模型在PC等端侧设备上部署的加速器。
云天励飞今年7月推出了IPU-X6000加速卡,内置高效大模型推理DeepEdge200芯片,具有256T大算力、486GB/s超高带宽、128GB大显存、c2c mesh互联,可应用于语言大模型、视觉大模型、多模态大模型等各类大模型推理加速领域。
目前已经支持适配云天书、通义千问、百川智能、智谱清言、Meta等30+开源大模型,涵盖1.5B参数到70B参数量,预期能使大模型推理成本大幅度下降。
写在最后
不难想到,随着人工智能技术的不断发展和应用领域的不断拓展,AI加速卡的市场需求将持续增长。未来,AI加速卡将继续朝着更高性能、更低功耗、更多功能集成的方向发展。同时,随着定制化设计需求的增加,AI加速卡市场也将呈现出更加多元化的竞争格局。
-
AI
+关注
关注
87文章
29838浏览量
268146 -
算力
+关注
关注
1文章
907浏览量
14701 -
大模型
+关注
关注
2文章
2281浏览量
2370
发布评论请先 登录
相关推荐
YXC高频差分晶振,频点312.5mhz,高精度.高稳定性,应用于AI加速卡

摩尔线程携手东华软件完成AI大模型推理测试与适配
云天励飞推出IPU-X6000加速卡,针对大模型推理任务设计
后摩智能推出边端大模型AI芯片M30,展现出存算一体架构优势
万卡集群解决大模型训算力需求,建设面临哪些挑战

大模型端侧部署加速,都有哪些芯片可支持?
OpenAI Sora模型需大量AI加速卡及电力支持
英伟达发布最强AI加速卡Blackwell GB200

瞬变对AI加速卡供电的影响
走向边缘智能,美格智能携手阿加犀成功在高算力AI模组上运行一系列大语言模型
走向边缘智能,美格智能携手阿加犀成功在高算力AI模组上运行一系列大语言模型






 工商网监
工商网监
评论