 周立功来讲解哈希表的实现
周立功来讲解哈希表的实现
近日周立功教授公开了数年的心血之作《程序设计与数据结构》,电子版已无偿性分享到电子工程师与高校群体下载,经周立功教授授权,特对本书内容进行连载。
>>>>1.1.1 哈希表的实现
1. 初始化
hash_db_init()接口用于哈希表实例的初始化,在定义哈希表结构体类型时,哈希表数组大小、记录长度、关键字长度和哈希函数都需要由用户根据实际情况确定,其函数原型定义如下(hash_db.h):
int hash_db_init (
hash_db_t *p_hash, //指向哈希表实例的指针
unsigned int size, //哈希表大小
unsigned int key_len, //关键字长度
unsigned int value_len, //记录长度
hash_func_t pfn_hash); //哈希函数在这里,以学生记录为例,创建一个大小为250组的哈希表:
hash_db_t hash_students;
hash_db_init(
&hash_students,
250, //大小为250
6, //关键字长度为6字节
sizeof(student_t), //记录的长度
(hash_func_t)db_id_to_idx); //哈希函数在初始化函数的实现中,需要按照size指定的大小分配内存,用于存储哈希表的各个表项(链表头),接着需要完成各个链表头和结构体成员的初始化,初始化函数的实现范例详见程序清单3.63。
程序清单3.63初始化函数范例程序
1 int hash_db_init (hash_db_t *p_hash, unsigned int size, unsigned int key_len,
2 unsigned int value_len, hash_func_t pfn_hash)
3 {
4 int i;
5 if ((p_hash == NULL) || (pfn_hash == NULL)){6 return NULL;
7 }
8 p_hash -> p_head = (slist_head_t *)malloc(size * sizeof(slist_head_t));
9 if (p_hash -> p_head == NULL) {
10 return -1;
11 }
12 for (i = 0; i < size; i++){
13 slist_init(&p_hash -> p_head[i]);
14 }15 p_hash -> size = size;
16 p_hash -> key_len = key_len;
17 p_hash -> value_len = value_len;
18 p_hash -> pfn_hash = pfn_hash;
19 return 0;
20 }2. 添加记录
hash_db_add()接口用于向已经初始化的哈希表中添加一条记录,添加一条记录时,需要指定关键字信息和记录值信息,其函数原型定义(hash_db.h):
int hash_db_add (hash_db_t *p_hash, void *key, const void *value);
其中,p_hash为指向哈希表实例的指针,key为指向关键字的指针,value为指向记录值的指针。特别地,由于在添加记录时,程序不会修改key和value指针所指向的值,因此,指针都加了const修饰符。以添加一条学生记录为例,使用范例如下:
student_t stu = {
"zhangsan",
'M',
173.3,
60
};
unsigned char id[6] = {0x20, 0x14, 0x44, 0x70, 0x02, 0x39};
hash_db_add(&hash_students, id, &stu);在添加记录函数的实现中,首先需要使用哈希函数找到关键字对应的记录在哈希表中的索引,以确定该条记录所在链表的表头,然后分配一个存储记录的结点空间,将关键字、记录等信息存储在该空间中,然后将结点添加到对应链表的头部(由于记录在链表中的具体位置不重要,因此直接添加在链表头部,效率更高)。函数实现的范例详见程序清单3.64。
程序清单3.64添加记录函数范例程序
1 int hash_db_add (hash_db_t *p_hash, const void *key, const void *value)
2 {
3 int idx = p_hash -> pfn_hash(key); //使用哈希函数通过关键字得到哈希值
4 //分配内存,存储链表结点+关键字+记录5 char *p_mem = (char *)malloc(sizeof(slist_node_t) + p_hash -> key_len + p_hash -> value_len);
6 if (p_mem == NULL) {
7 return -1;
8 }
9 memcpy(p_mem + sizeof(slist_node_t), key, p_hash -> key_len); //存储关键字
10 memcpy(p_mem + sizeof(slist_node_t) + p_hash->key_len, value, p_hash->value_len); //存储记录
11 return slist_add_head(&p_hash -> p_head[idx], (slist_node_t *)p_mem); //将结点加入链表
12 }程序分配了一个结点的空间,该结点的空间需要存储一个slist_node_t类型链表结点,便于添加结点到链表中,存储长度为p_hash->key_len的关键字,存储长度为p_hash->value_len的记录值,详见图3.26,其内存的大小为:
sizeof(slist_node_t) + p_hash -> key_len + p_hash -> value_len

图3.26 结点存储空间
由于结点空间的首部用于存储结点slist_node_t的值以组织链表。因此需要将结点添加到链表中时,直接将p_mem转换为slist_node_t*类型使用即可,通用链式哈希表的结构示意图详见图3.27。
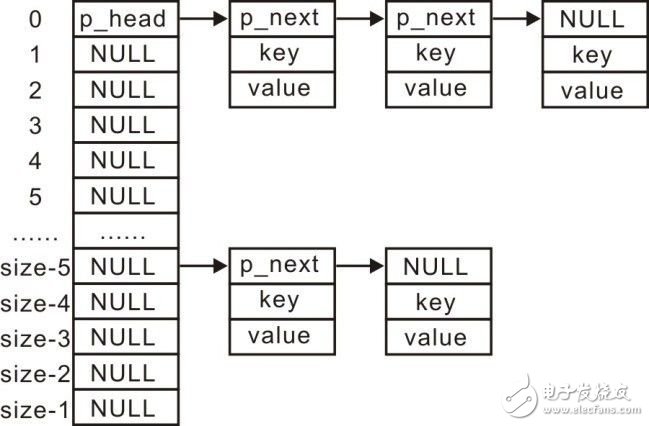
图3.27 通用的链式哈希表结构示意图
与图3.25中管理学生记录的链式哈希表结构示意图对比发现,它们表达的含义是完全一致的,仅仅是具体类型变为了更加通用的void *类型。
3. 查找记录
hash_db_search()接口通过关键字查找与之对应的记录,查找记录时,需要指定关键字信息,同时还需要使用一个指向记录的指针获取查找到的记录值,其函数原型(hash_db.h)如下:
int hash_db_search(hash_db_t *p_hash,const void *key, void *value);
虽然参数与添加记录是完全一样的,但value表示的含义却不一样,此处的value是输出参数,用于得到查找到的记录值。而添加记录函数中的value是输入参数,提供需要存储的记录值。由于此处的value指向指向的值是需要被改变的(改变为查找到的记录值),因此,其不能增加const修饰符。以查找ID为201444700239的学生记录为例,使用范例如下:
student_t stu;
unsigned char id[6] = {0x20, 0x14, 0x44, 0x70, 0x02, 0x39};
if (hash_db_search(&hash_students, id, &stu) == 0) {
//查找到该学号的学生记录
} else {
//查找失败,未找到该学号的学生记录
}在该函数的实现中,首先需要使用哈希函数找到关键字对应的记录在哈希表中的索引,以确定该条记录所在链表的表头,然后遍历链表的各个结点,将提供的关键字与结点中存储的关键字比对,直到找到关键字完全一致的记录(查找成功)或链表遍历结束(查找失败)。找到该记录对应的结点后,将结点中存储的value值拷贝到参数value指针指向的空间中即可。函数实现的范例详见程序清单3.65。
程序清单3.65查找记录函数范例程序
1 //寻找结点的上下文(仅内部使用)
2 struct _node_find_ctx {
3 void *key; //查找关键字
4 unsigned int key_len; //关键字长度
5 slist_node_t *p_result; //用于存储查找到的结点
6 };
7
8 //遍历链表的回调函数,查找指定结点
9 static int __hash_db_node_find (void *p_arg, slist_node_t *p_node)
10 {11 struct _node_find_ctx *p_info = (struct _node_find_ctx *)p_arg; //用户参数为寻找结点的上下文
12 char *p_mem = (char *)p_node + sizeof(slist_node_t); //关键字存储在结点之后
13
14 if (memcmp(p_mem, p_info->key, p_info->key_len) == 0) {
15 p_info->p_result = p_node;
16 return -1; //找到该结点,终止遍历
17 }
18 return 0;
19 }
2021 int hash_db_search(hash_db_t *p_hash, const void *key, void *value)
22 {
23 int idx = p_hash->pfn_hash(key); //得到关键字对应的哈希表的索引
24 struct _node_find_ctx info = {key, p_hash->key_len, NULL}; //设置遍历链表的上下文信息
25 slist_foreach(&p_hash->p_head[idx], __hash_db_node_find, &info); //遍历,寻找关键字对应结点
2627 if (info.p_result != NULL) { //找到对应结点, 将存储的记录值拷贝到用户提供的空间中
28 memcpy(value, (char *)info.p_result+sizeof(slist_node_t)+p_hash->key_len+p_hash->value_len);
29 return 0;
30 }
31 return -1;
32 }程序中,由于查找结点时需要遍历链表,关键字比对的操作需要在遍历函数的回调函数中完成,因此,需要将用户查找记录使用的关键字信息(关键字及其长度)提供给回调函数,同时,当查找到记录时,需要将查找到的结点反馈给调用遍历函数的主程序。为此,定义了一个内部使用的用于寻找一个结点的上下文结构体:
struct _node_find_ctx {
const void *key; //查找关键字
unsigned int key_len; //关键字长度
slist_node_t *p_result; //用于存储查找到的结点
};调用遍历函数时,需要提供一个设置好关键字信息的结构体作为回调函数的用户参数。遍历函数结束时,可以通过该结构体中的p_result成员获取遍历结果。
4. 删除记录
该接口用于删除指定关键字对应的记录,可以定义其函数名为:hash_db_del()。删除记录时,需要指定关键字信息。可以定义函数的原型为:
int hash_db_del(hash_db_t *p_hash, const void *key);
以删除学号为201444700239的学生记录为例,使用范例如下:
unsigned char id[6] = {0x20, 0x14, 0x44, 0x70, 0x02, 0x39};
hash_db_del(&hash_students, id);在该函数的实现中,绝大部分操作与查找记录是相同的,唯一的不同是,当找到关键字对应的结点时,不再需要将记录值提取出来,直接将该结点删除即可。函数实现的范例详见程序清单3.66。
程序清单3.66删除记录函数范例程序
1 int hash_db_del (hash_db_t *p_hash, const void *key)
2 {
3 int idx = p_hash->pfn_hash(key); //得到关键字对应的哈希表的索引
4 struct _node_find_ctx info = {key, p_hash->key_len, NULL}; //设置遍历链表的上下文信息
5 slist_foreach(&p_hash->p_head[idx], __hash_db_node_find, &info); //遍历,寻找关键字对应结点
6 if (info.p_result != NULL) {7 slist_del(&p_hash->p_head[idx], info.p_result); //从链表中删除该结点
8 free(info.p_result); //释放结点空间
9 return 0;
10 }
11 return -1;
12 }5. 解初始化
对应于哈希表的初始化,用于当不再使用哈希表时,释放相关的空间。可以定义其函数名为:hash_db_deinit()。需要通过参数指定需要解初始化的哈希表实例,可以定义函数的原型为(hash_db.h):
int hash_db_deinit (hash_db_t *p_hash);
如不再使用学生信息管理系统,则需使用解初始化函数释放哈希表的相关资源,使用范例如下:
hash_db_deinit(&hash_students);
在该函数的实现中,需要释放程序中分配的所有空间,主要包括添加记录时分配的结点空间,链表头结点数组空间。函数实现详见程序清单3.67。
程序清单3.67解初始化函数范例程序
1 int hash_db_deinit (hash_db_t *p_hash)
2 {
3 int i;
4 slist_node_t *p_node;
5 for (i = 0; i < p_hash->size; i++) { //释放哈希表中各个表项中存储的所有结点
67 while (slist_begin_get(&p_hash->p_head[i]) != slist_end_get(&p_hash->p_head[i])) {
8 p_node = slist_begin_get(&p_hash->p_head[i]);
9 slist_del(&p_hash->p_head[i], p_node); //删除第一个结点
10 free(p_node);
11 }
12 }
13 free(p_hash->p_head); //释放链表头结点数组空间
15 return 0;
16 }为便于查阅,如程序清单3.29所示展示了hash_db.h文件的内容。
程序清单3.68 hash_db.h文件内容
1 #pragma once;
2 #include "slist.h"
3
4 typedef unsigned int (*hash_func_t) (const void *key); //哈希函数类型,返回值为整数,参数为关键字
5 struct _hash_db{
6 slist_head_t *p_head; //指向数组首地址
7 unsigned int size; //数组成员数
8 unsigned int value_len; //一条记录的长度
9 unsigned int key_len; //关键字的长度
10 hash_func_t pfn_hash; //哈希函数
11 };
12 typedef struct _hash_db *hash_db_t; //指向哈希表对象的指针类型
13
14 int hash_db_init (hash_db_t *p_hash, // 哈希表初始化
15 unsigned int size,
16 unsigned int key_len,
17 unsigned int value_len,
18 hash_func_t pfn_hash);
19
20 int hash_db_add (hash_db_t *p_hash, const void *key,const void *value); //添加记录
21 int hash_db_del (hash_db_t *p_hash, const void *key); //删除记录
22 int hash_db_search(hash_db_t *p_hash, const void *key, void *value); // 查找记录
23 int hash_db_deinit (hash_db_t *p_hash); //解初始化以使用该链式哈希表管理系统来管理学生记录为例,综合范例程序详见程序清单3.30。
程序清单3.69哈希表综合范例程序
1 #include
2 #include
3 #include "hash_db.h"
4
5 typedef struct _student{
6 char name[10]; //姓名
7 char sex; //性别
8 float height, weight; //身高、体重
9 } student_t;
10
11 int db_id_to_idx (unsigned char id[6]) //通过ID得到数组索引
12 {13 int i;
14 int sum = 0;
15 for (i = 0; i < 6; i++){
16 sum += id[0];
17 }
18 return sum % 250;
19 }
20
21 int student_info_generate (unsigned char *p_id, student_t *p_student) //随机产生一条学生记录
22 {23 int i;
24 for (i = 0; i < 6; i++) { // 随机产生一个学号
25 p_id[i] = rand();
26 }
27 for (i = 0; i < 9; i++) { // 随机名字,由 'a' ~ 'z' 组成
28 p_student->name[i] = (rand() % ('z' - 'a')) + 'a';
29 }
30 p_student->name[i]= '\0'; //字符串结束符31 p_student->sex = (rand() & 0x01) ? 'F' : 'M'; //随机性别
32 p_student->height = (float)rand() / rand();
33 p_student->weight = (float)rand() / rand();
34 return 0;
35 }
36
37 int main ()
38 {39 student_t stu;
40 unsigned char id[6];
41 int i;
42 hash_db_t hash_students;
43
44 hash_db_init(&hash_students, 250, 6, sizeof(student_t), (hash_func_t)db_id_to_idx);
45
46 for (i = 0; i < 100; i++) { // 添加100个学生的信息
47 student_info_generate(id, &stu); //设置学生的信息,当前一随机数作为测试48 if (hash_db_search(&hash_students, id, &stu) == 0) { //查找到已经存在该ID的学生记录
49 printf("该ID的记录已经存在!\n");
50 continue;
51 }52 printf("增加记录:ID : %02x%02x%02x%02x%02x%02x",id[0],id[1],id[2],id[3],id[4],id[5]);
53 printf("信息: %s %c %.2f %.2f\n", stu.name, stu.sex, stu.height, stu.weight);
54 if (hash_db_add(&hash_students, id, &stu) != 0) {
55 printf("添加失败");
56 }
57 }
5859 printf("查找ID为:%02x%02x%02x%02x%02x%02x的信息\n",id[0],id[1],id[2],id[3],id[4],id[5]);
60 if (hash_db_search(&hash_students, id, &stu) == 0) {
61 printf("学生信息: %s %c %.2f %.2f\n", stu.name, stu.sex, stu.height, stu.weight);
62 } else {
63 printf("未找到该ID的记录!\r\n");
64 }
65 hash_db_deinit(&hash_students);66 return 0;
67 }在这里,首先创建了一个哈希表,然后向其中添加了100个学生信息(以随机数的方式产生的),接着查找了ID对应的学生信息(这里的ID没有特别设置,即查找最后添加的学生记录),最后释放哈希表。
-
周立功
+关注
关注
38文章
130浏览量
37672 -
大数据
+关注
关注
64文章
8896浏览量
137514 -
哈希表
+关注
关注
0文章
9浏览量
4858
原文标题:周立功:哈希表的实现,干货!
文章出处:【微信号:Zlgmcu7890,微信公众号:周立功单片机】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
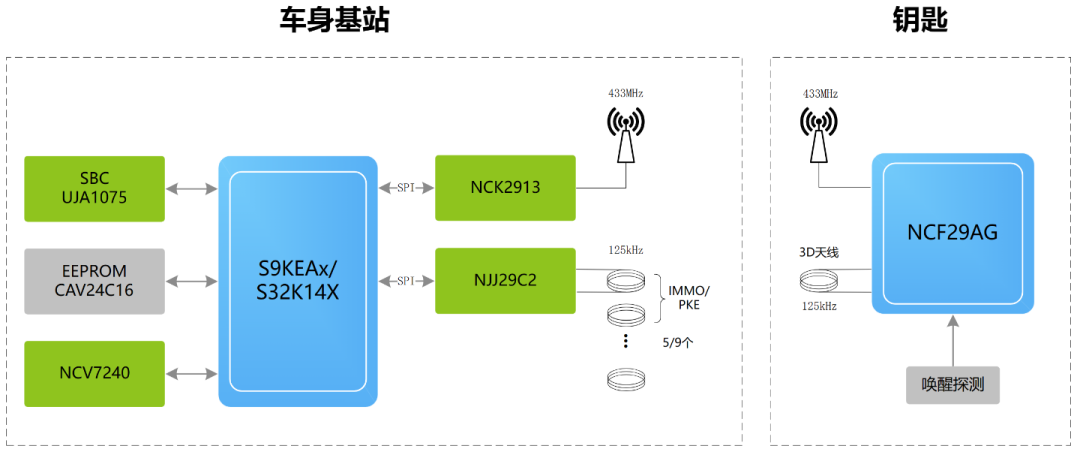
立功科技与求远电子推出全新蓝牙汽车数字钥匙方案

立功科技汽车防盗方案介绍
华纳云:Chord算法如何管理节点间的联系?



立功科技ISD智能交互车灯技术方案
中国电子党组副书记、总经理李立功调研CET中电技术马来西亚数据中心项目

鸿蒙ArkTS开始实例:【canvas实现签名板功能】
乐华工业显示器日常应该如何维护

毫厘中的绚烂绽放,先楫携手立功科技发布HPM6800数字仪表方案







 工商网监
工商网监
评论