 linux经典的rcu如何实现?
linux经典的rcu如何实现?
一、RCU有什么用?
RCU主要用于对性能要求苛刻的并行实时计算。例如:天气预报、模拟核爆炸计算、内核同步等等。
假设你正在编写一个并行实时程序,该程序需要访问随时变化的数据。这些数据可能是随着温度、湿度的变化而逐渐变化的大气压。这个程序的实时响应要求是如此严格,需要处理的数据量如此巨大,以至于不允许任何自旋或者阻塞,因此不能使用任何锁。
幸运的是,温度和压力的范围通常变化不大,因此使用默认的数据集也是可行的。当温度、湿度和压力抖动时,有必要使用实时数据。但是温度、湿度和压力是逐渐变化的,我们可以在几分钟内更新数据,但没必要实时更新值。
在这种情况下,可以使用一个全局指针,即gptr,通常为NULL,表示要使用默认值。偶尔也可以将gptr指向假设命名为a、b和c的变量,以反映气压的变化。
传统的软件可以使用自旋锁这样的同步机制,来保护gptr指针的读写。一旦旧的值不被使用,就可以将旧指针指向的数据释放。这种简单的方法有一个最大的问题:它会使软件效率下降数个数量级(注意,不是下降数倍而是下降数个数量级)。
在现代计算系统中,向gptr写入a、b、c这样的值,并发的读者要么看到一个NULL指针要么看到指向新结构gptr的指针,不会看到中间结果。也就是说,对于指针赋值来说,某种意义上这种赋值是原子的。读者不会看到a、b、c之外的其他结果。并且,更好的一点,也是更重要的一点是:读者不需要使用任何代价高昂的同步原语,因此这种方法非常适合于实时使用。
真正的难点在于:在读者获得gptr的引用时,它可能看到a、b、c这三个值中任意一个值,写者何时才能安全的释放a、b、c所指向的内存数据结构?
引用计数的方案很有诱惑力,但正如锁和顺序锁一样,引用计数可能消耗掉数百个CPU指令周期,更致命的是,它会引用缓存行在CPU之间的来回颠簸,破坏各个CPU的缓存,引起系统整体性能的下降。很明显,这种选择不是我们所期望的。
想要理解Linux经典RCU实现的读者,应当认真阅读下面这段话:
一种实现方法是,写者完全不知道有哪些读者存在。这种方法显然让读者的性能最佳,但留给写者的问题是:如何才能确定所有的老读者已经完成。
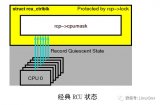
最简单的实现是:让线程不会被抢占,或者说,读者在读RCU数据期间不能被抢占。在这种不可抢占的环境中,每个线程将一直运行,直到它明确地和自愿地阻塞自己(现实世界确实有这样的操作系统,它由线程自己决定何时释放CPU。例如大名鼎鼎的Solaris操作系统)。这要求一个不能阻塞的无限循环将使该CPU在循环开始后无法用于任何其他目的,还要求还要求线程在持有自旋锁时禁止阻塞。否则会形成死锁。
这种方法的示意图下所示,图中的时间从顶部推移到底部,CPU 1的list_del()操作是RCU写者操作,CPU2、CPU3在读端读取list节点。

Linux经典RCU的概念即是如此。虽然这种方法在生产环境上的实现可能相当复杂,但是玩具实现却非常简单。
2 run_on(cpu);
for_each_online_cpu()原语遍历所有CPU,run_on()函数导致当前线程在指定的CPU上执行,这会强制目标CPU执行上下文切换。因此,一旦for_each_online_cpu()完成,每个CPU都执行了一次上下文切换,这又保证了所有之前存在的读线程已经完成。
请注意,这个方法不能用于生产环境。正确处理各种边界条件和对性能优化的强烈要求意味着用于生产环境的代码实现将十分复杂。此外,可抢占环境的RCU实现需要读者实际做点什么事情(也就是在读临界区内,禁止抢占。这是Linux经典RCU读锁的实现)。不过,这种简单的不可抢占的方法在概念上是完整的,有助于我们理解RCU的基本原理。
二、RCU是什么?
RCU是read-copy-update的简称,翻译为中文有点别扭“读-复制-更新”。它是是一种同步机制,有三种角色或者操作:读者、写者和复制操作,我理解其中的复制操作就是不同CPU上的读者复制了不同的数据值,或者说拥有同一个指针的不同拷贝值,也可以理解为:在读者读取值的时候,写者复制并替换其内容(后一种理解来自于RCU作者的解释)。它于2002年10月引入Linux内核。
RCU允许读操作可以与更新操作并发执行,这一点提升了程序的可扩展性。常规的互斥锁让并发线程互斥执行,并不关心该线程是读者还是写者,而读/写锁在没有写者时允许并发的读者,相比于这些常规锁操作,RCU在维护对象的多个版本时确保读操作保持一致,同时保证只有所有当前读端临界区都执行完毕后才释放对象。RCU定义并使用了高效并且易于扩展的机制,用来发布和读取对象的新版本,还用于延后旧版本对象的垃圾收集工作。这些机制恰当地在读端和更新端并行工作,使得读端特别快速。在某些场合下(比如非抢占式内核里),RCU读端的函数完全是零开销。
Seqlock也可以让读者和写者并发执行,但是二者有什么区别?
首先是二者的目的不一样。Seqlock是为了保证读端在读取值的时候,写者没有对它进行修改,而RCU是为了多核扩展性。
其次是保护的数据结构大小不一样。Seqlock可以保护一组相关联的数据,而RCU只能保护指针这样的unsigned long类型的数据。
最重要的区别还在于效率,Seqlock本质上是与自旋锁同等重量级的原语,其效率与RCU不在同一个数量级上面。
下面从三个基础机制来阐述RCU究竟是什么?
RCU由三种基础机制构成,第一个机制用于插入,第二个用于删除,第三个用于让读者可以不受并发的插入和删除干扰。分别是:
发布/订阅机制,用于插入。
等待已有的RCU读者完成的机制,用于删除。
维护对象多个版本的机制,以允许并发的插入和删除操作。
1、发布/订阅机制
RCU的一个关键特性是可以安全的读取数据,即使数据此时正被修改。RCU通过一种发布/订阅机制达成了并发的数据插入。举个例子,假设初始值为NULL的全局指针gp现在被赋值指向一个刚分配并初始化的数据结构。如下所示的代码片段:
1 structfoo {
2 inta;
3 intb;
4 intc;
5 };
6 structfoo *gp =NULL;
7
8 /*. . . */
9
10 p= kmalloc(sizeof(*p), GFP_KERNEL);
11 p->a= 1;
12 p->b= 2;
13 p->c= 3;
14 gp = p;
“发布”数据结构(不安全)
不幸的是,这块代码无法保证编译器和CPU会按照编程顺序执行最后4条赋值语句。如果对gp的赋值发生在初始化p的各字段之前,那么并发的读者会读到未初始化的值。这里需要内存屏障来保证事情按顺序发生,可是内存屏障又向来以难用而闻名。所以这里我们用一句rcu_assign_ pointer()原语将内存屏障封装起来,让其拥有发布的语义。最后4行代码如下。
1 p->a= 1;
2 p->b= 2;
3 p->c= 3;
4 rcu_assign_pointer(gp, p);
rcu_assign_pointer()“发布”一个新结构,强制让编译器和CPU在为p的各字段赋值后再去为gp赋值。
不过,只保证更新者的执行顺序并不够,因为读者也需要保证读取顺序。请看下面这个例子中的代码。
1 p= gp;
2 if(p != NULL){
3 do_something_with(p->a, p->b,p->c);
4 }
这块代码看起来好像不会受到乱序执行的影响,可惜事与愿违,在DEC Alpha CPU机器上,还有启用编译器值猜测(value-speculation)优化时,会让p->a,p->b和p->c的值在p赋值之前被读取。
也许在启动编译器的值猜测优化时比较容易观察到这一情形,此时编译器会先猜测p->a、p->b、p->c的值,然后再去读取p的实际值来检查编译器的猜测是否正确。这种类型的优化十分激进,甚至有点疯狂,但是这确实发生在剖析驱动(profile-driven)优化的上下文中。
然而读者可能会说,我们一般不会使用编译器猜测优化。那么我们可以考虑DEC Alpha CPU这样的极端弱序的CPU。在这个CPU上面,引起问题的根源在于:在同一个CPU内部,使用了不止一个缓存来缓存CPU数据。这样可能使用p和p->a被分布不同一个CPU的不同缓存中,造成缓存一致性方面的问题。
显然,我们必须在编译器和CPU层面阻止这种危险的优化。rcu_dereference()原语用了各种内存屏障指令和编译器指令来达到这一目的。
1 rcu_read_lock();
2 p= rcu_dereference(gp);
3 if(p != NULL){
4 do_something_with(p->a, p->b,p->c);
5 }
6 rcu_read_unlock();
其中rcu_read_ lock()和rcu_read_unlock()这对原语定义了RCU读端的临界区。事实上,在没有配置CONFIG_PREEMPT的内核里,这对原语就是空函数。在可抢占内核中,这这对原语就是关闭/打开抢占。
rcu_dereference()原语用一种“订阅”的办法获取指定指针的值。保证后续的解引用操作可以看见在对应的“发布”操作(rcu_assign_pointer())前进行的初始化,即:在看到p的新值之前,能够看到p->a、p->b、p->c的新值。请注意,rcu_assign_pointer()和rcu_dereference()这对原语既不会自旋或者阻塞,也不会阻止list_add_ rcu()的并发执行。
虽然理论上rcu_assign_pointer()和rcu_derederence()可以用于构造任何能想象到的受RCU保护的数据结构,但是实践中常常只用于构建更上层的原语。例如,将rcu_assign_pointer()和rcu_dereference()原语嵌入在Linux链表的RCU变体中。Linux有两种双链表的变体,循环链表struct list_head和哈希表structhlist_head/struct hlist_node。前一种如下图所示。

对链表采用指针发布的例子如下:
1 struct foo {
2struct list_head *list;
3 int a;
4 int b;
5 int c;
6 };
7LIST_HEAD(head);
8
9 /* .. . */
10
11 p =kmalloc(sizeof(*p), GFP_KERNEL);
12p->a = 1;
13p->b = 2;
14p->c = 3;
15list_add_rcu(&p->list,&head);
RCU发布链表
第15行必须用某些同步机制(最常见的是各种锁)来保护,防止多核list_add()实例并发执行。不过,同步并不能阻止list_add()的实例与RCU的读者并发执行。
订阅一个受RCU保护的链表的代码非常直接。
1 rcu_read_lock();
2 list_for_each_entry_rcu(p, head,list) {
3 do_something_with(p->a, p->b,p->c);
4 }
5 rcu_read_unlock();
list_add_rcu()原语向指定的链表发布了一项条目,保证对应的list_for_each_ entry_rcu()可以订阅到同一项条目。
Linux的其他链表、哈希表都是线性链表,这意味着它的头结点只需要一个指针,而不是象循环链表那样需要两个。因此哈希表的使用可以减少哈希表的hash bucket数组一半的内存消耗。
向受RCU保护的哈希表发布新元素和向循环链表的操作十分类似,如下所示。
1 struct foo {
2struct hlist_node *list;
3 int a;
4 int b;
5 int c;
6 };
7HLIST_HEAD(head);
8
9 /* .. . */
10
11 p =kmalloc(sizeof(*p), GFP_KERNEL);
12p->a = 1;
13p->b = 2;
14p->c = 3;
15hlist_add_head_rcu(&p->list,&head);
和之前一样,第15行必须用某种同步机制,比如锁来保护。
订阅受RCU保护的哈希表和订阅循环链表没什么区别。
1rcu_read_lock();
2hlist_for_each_entry_rcu(p,q, head, list){
3do_something_with(p->a,p->b, p->c);
4 }
5 rcu_read_unlock();
表9.2是RCU的发布和订阅原语,另外还有一个删除发布原语。

请注意,list_replace_rcu()、list_del_rcu()、hlist_replace_rcu()和hlist_ del_rcu()这些API引入了一点复杂性。何时才能安全地释放刚被替换或者删除的数据元素?我们怎么能知道何时所有读者释放了他们对数据元素的引用?
2、等待已有的RCU读者执行完毕
从最基本的角度来说,RCU就是一种等待事物结束的方式。当然,有很多其他的方式可以用来等待事物结束,比如引用计数、读/写锁、事件等等。RCU的最伟大之处在于它可以等待(比如)20,000种不同的事物,而无需显式地去跟踪它们中的每一个,也无需去担心对性能的影响,对扩展性的限制,复杂的死锁场景,还有内存泄漏带来的危害等等使用显式跟踪手段会出现的问题。
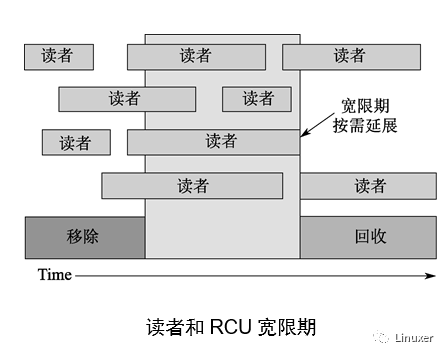
在RCU的例子中,被等待的事物称为“RCU读端临界区”。RCU读端临界区从rcu_read_lock()原语开始,到对应的rcu_read_unlock()原语结束。RCU读端临界区可以嵌套,也可以包含一大块代码,只要这其中的代码不会阻塞或者睡眠(先不考虑可睡眠RCU)。如果你遵守这些约定,就可以使用RCU去等待任何代码的完成。
RCU通过间接地确定这些事物何时完成,才完成了这样的壮举。
如上图所示,RCU是一种等待已有的RCU读端临界区执行完毕的方法,这里的执行完毕也包括在临界区里执行的内存操作。不过请注意,在某个宽限期开始后才启动的RCU读端临界区会扩展到该宽限期的结尾处。
下列伪代码展示了写者使用RCU等待读者的基本方法。
1.作出改变,比如替换链表中的一个元素。
2.等待所有已有的RCU读端临界区执行完毕(比如使用synchronize_rcu()原语)。这里要注意的是后续的RCU读端临界区无法获取刚刚删除元素的引用。
3.清理,比如释放刚才被替换的元素。
下图所示的代码片段演示了这个过程,其中字段a是搜索关键字。
1 struct foo {
2struct list_head *list;
3 int a;
4 int b;
5 int c;
6 };
7LIST_HEAD(head);
8
9 /* .. . */
10
11 p =search(head, key);
12 if (p== NULL) {
13 /* Takeappropriate action, unlock,and
return.*/
14 }
15 q =kmalloc(sizeof(*p), GFP_KERNEL);
16 *q = *p;
17q->b = 2;
18q->c = 3;
19list_replace_rcu(&p->list,&q->list);
20synchronize_rcu();
21 kfree(p);
标准RCU替换示例
第19、20和21行实现了刚才提到的三个步骤。第16至19行正如RCU其名(读-复制-更新),在允许并发读的同时,第16行复制,第17到19行更新。
synchronize_rcu()原语可以相当简单。然而,想要达到产品质量,代码实现必须处理一些困难的边界情况,并且还要进行大量优化,这两者都将导致明显的复杂性。理解RCU的难点,主要在于synchronize_rcu()的实现。
3、维护最近被更新对象的多个版本
下面展示RCU如何维护链表的多个版本,供并发的读者访问。通过两个例子来说明在读者还处于RCU读端临界区时,被读者引用的数据元素如何保持完整性。第一个例子展示了链表元素的删除,第二个例子展示了链表元素的替换。
例子1:在删除过程中维护多个版本
1 p= search(head, key);
2 if(p != NULL){
3 list_del_rcu(&p->list);
4 synchronize_rcu();
5 kfree(p);
6 }
如下图,每个元素中的三个数字分别代表字段a、b、c的值。红色的元素表示RCU读者此时正持有该元素的引用。请注意,我们为了让图更清楚,忽略了后向指针和从尾指向头的指针。

等第3行的list_del_rcu()执行完毕后,“5、6、7”元素从链表中被删除。因为读者不直接与更新者同步,所以读者可能还在并发地扫描链表。这些并发的读者有可能看见,也有可能看不见刚刚被删除的元素,这取决于扫描的时机。不过,刚好在取出指向被删除元素指针后被延迟的读者(比如,由于中断、ECC内存错误),就有可能在删除后还看见链表元素的旧值。因此,我们此时有两个版本的链表,一个有元素“5、6、7”,另一个没有。元素“5、6、7”用黄色标注,表明老读者可能还在引用它,但是新读者已经无法获得它的引用。
请注意,读者不允许在退出RCU读端临界区后还维护元素“5、6、7”的引用。因此,一旦第4行的synchronize_rcu()执行完毕,所有已有的读者都要保证已经执行完,不能再有读者引用该元素。这样我们又回到了唯一版本的链表。
此时,元素“5、6、7”可以安全被释放了。这样我们就完成了元素“5、6、7”的删除。
例子2:在替换过程中维护多个版本
1 q= kmalloc(sizeof(*p), GFP_KERNEL);
2 *q = *p;
3 q->b = 2;
4 q->c = 3;
5list_replace_rcu(&p->list,&q->list);
6synchronize_rcu();
7 kfree(p);
链表的初始状态包括指针p都和“删除”例子中一样。

RCU从链表中替换元素
和前面一样,每个元素中的三个数字分别代表字段a、b、c。红色的元素表示读者可能正在引用,并且因为读者不直接与更新者同步,所以读者有可能与整个替换过程并发执行。请注意我们为了图表的清晰,再一次忽略了后向指针和从尾指向头的指针。
下面描述了元素“5、2、3”如何替换元素“5、6、7”的过程,任何特定读者可能看见这两个值其中一个。
第1行用kmalloc()分配了要替换的元素。此时,没有读者持有刚分配的元素的引用(用绿色表示),并且该元素是未初始化的(用问号表示)。
第2行将旧元素复制给新元素。新元素此时还不能被读者访问,但是已经初始化了。
第3行将q->b的值更新为2,第4行将q->c的值更新为3。
现在,第5行开始替换,这样新元素终于对读者可见了,因此颜色也变成了红色。此时,链表就有两个版本了。已经存在的老读者可能看到元素“5、6、7”(现在颜色是黄色的),而新读者将会看见元素“5、2、3”。不过这里可以保证任何读者都能看到一个完好的链表。
随着第6行synchronize_rcu()的返回,宽限期结束,所有在list_replace_rcu()之前开始的读者都已经完成。特别是任何可能持有元素“5、6、7”引用的读者保证已经退出了它们的RCU读端临界区,不能继续持有引用。因此,不再有任何读者持有旧数据的引用,,如第6排绿色部分所示。这样我们又回到了单一版本的链表,只是用新元素替换了旧元素。
等第7行的kfree()完成后,链表就成了最后一排的样子。
不过尽管RCU是因替换的例子而得名的,但是RCU在内核中的主要用途还是用于简单的删除。
-
rcu
+关注
关注
0文章
21浏览量
5440
原文标题:谢宝友:深入理解RCU之三:概念
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
谢宝友教你学Linux:深入理解Linux RCU之从硬件说起
深入理解Linux RCU:经典RCU实现概要
基于Linux内核源码的RCU实现方案
Linux内核RCU锁的原理与使用
深入理解RCU:玩具式实现
分级RCU的基础知识
Linux内核中RCU的用法
linux内核rcu机制详解
深入理解Linux RCU:RCU是读写锁的替代者
深入了解RCU是怎样实现的?





 工商网监
工商网监
评论