 AMD助力HyperAccel开发全新AI推理服务器
AMD助力HyperAccel开发全新AI推理服务器

HyperAccel 是一家成立于 2023 年 1 月的韩国初创企业,致力于开发 AI 推理专用型半导体器件和硬件,最大限度提升推理工作负载的存储器带宽使用,并通过将此解决方案应用于大型语言模型来提高成本效率。HyperAccel 针对新兴的生成式 AI 应用提供超级加速的芯片 IP/解决方案。HyperAccel 已经打造出一个快速、高效且低成本的推理系统,加速了基于转换器的大型语言模型( LLM )的推理,此类模型通常具有数十亿个参数,例如 OpenAI 的 ChatGPT 和 Meta 的 Llama 3 等 Llama LLM。其 AI 芯片名为时延处理单元( LPU ),是专门用于 LLM 端到端推理的硬件加速器。
项目挑战
随着 LLM 应用的扩展,对高效、快速和具成本效益的推理解决方案的需求不断上升。对于云服务提供商而言,快速且成本效益高的推理硬件对于托管高性能的生成式 AI 应用并降低总拥有成本( TCO )至关重要。对于 AI 企业来说,一个直观的软件堆栈平台是实现其应用或模型无缝部署的必备条件。对于服务业务,提供全面的端到端解决方案也是必要的,有利于将最先进的 AI 技术集成到更有效和先进的服务中。
解决方案
HyperAccel 提出通过开发名为“Orion”的服务器来解决成本和性能问题,该服务器搭载了一个为 LLM 推理量身定制的专用处理器,基于多个高性能 AMD FPGA部署。Orion 充分利用每个 FPGA 的存储器带宽和硬件资源以获得最高水平的性能。这种可扩展的架构支持最新的 LLM,此类模型通常包含数十亿个参数。
Orion 拥有 16 个时延处理单元( LPU ),它们分布在两个 2U 机架中,提供总共 7.36TB/s 的 HBM 带宽和 14.4 万个 DSP。LPU 能加速内存和计算都非常密集的超大规模生成式 AI 工作负载。Orion 及其 256GB 的 HBM 容量支持多达千亿参数的最先进 LLM。上图展示了两个 2U 机箱之一,配有 8 个 LPU。
下图显示了 LPU 架构,其中矢量执行引擎由 AMD Alveo U55C 高性能计算卡支持。Alveo U55C 卡具有高带宽存储器( HBM2 ),解决了提供低时延AI 的最关键性能瓶颈——存储器带宽。此外,它们能够将 200 Gbps的高速网络集成到单个小型板卡中,并且经过精心设计可在任何服务器中部署。
反过来,每个 Alveo 加速卡都由 FPGA 架构驱动。鉴于 FPGA 的大规模硬件并行性和灵活应变的存储器层次结构,FPGA 固有的低时延特性非常适合 LLM 所需的实时 AI 服务。Alveo 卡采用了强大的 Virtex XCU55P UltraScale+ FPGA,可提供高达 38 TOPS 的 DSP 计算性能,有助于 AI 推理优化,包括用于定点与浮点计算的 INT8。这款 FPGA 能够根据客户反馈调整其处理器( LPU )的架构,例如,根据要求在Llama模型中实现一些非标准的处理,进而提供灵活的解决方案,能够适应不断变化的市场和 LLM 参数条件。
设计成效
Orion 的高性能和可扩展性是通过 LPU 实现的,由 AMD Alveo 加速卡和相关的 FPGA 以及HyperAccel 的可扩展同步链路( ESL )技术提供支持。这些技术最大限度提升了 P2P 传输中的存储器带宽使用,有利于灵活处理,同时消除了 P2P 计算的同步开销 ESL 属于为 LLM 推理中的数据传输优化的通信链路。值得注意的是,Orion 在支持标准 FP16 数据精度的硬件上保持了卓越的准确性。
HyperAccel Orion
的性能
针对时延进行优化的 HyperAccel Orion 与基于转换器的 LLM(如 GPT、Llama 和 OPT)无缝集成,能够在 1.3B 模型上每秒生成超过 520 个令牌,在 7B 模型上每秒生成 175 个令牌。除了卓越的性能外,Orion 还展示了出色的能源效率,在 66B 模型上生成单个令牌只需 24 毫秒,而功耗仅为 600W。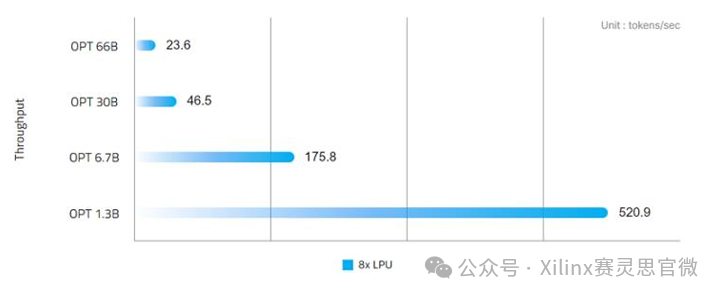
HyperAccel LPU 的性能(来源:https://www.hyperaccel.ai)
HyperAccel Orion
—— 工作负载多样性
Orion 提供端到端的解决方案服务,可作为云端服务部署。对于拥有专有 LLM 的AI 企业或存在内部数据隐私与安全需求的专业部门,Orion 也能够以本地解决方案的形式进行安装。Orion 能够处理以下工作负载/应用:
客户服务:通过虚拟聊天机器人和虚拟助手实时处理查询,因此人工客服将有时间处理更复杂的问题。
人机界面:在自助服务终端、机器人和其它设备中支持与语言相关的功能,以增强客户互动体验。
文本生成:协助生产、总结和精炼复杂的文本内容,为用户提供便利。
语言翻译:翻译客户查询和回复信息,打破语言障碍,扩大企业的全球影响力。
问答:根据大量数据以及此前的互动和偏好记录,定制针对个别客户的回复,以提高客户满意度。
进一步了解AMD Virtex UltraScale+ FPGA和Alveo U55C 加速卡,请访问产品专区。
-
FPGA
+关注
关注
1664文章
22553浏览量
640506 -
amd
+关注
关注
25文章
5720浏览量
140602 -
服务器
+关注
关注
14文章
10429浏览量
91839 -
AI
+关注
关注
91文章
41885浏览量
302994
原文标题:HyperAccel 借助 AMD 加速卡与 FPGA 打造全新 AI 推理服务器
文章出处:【微信号:赛灵思,微信公众号:Xilinx赛灵思官微】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
AI 服务器电源:现状剖析与未来展望

RENESAS 932S890C:AMD 服务器系统时钟解决方案
服务器发展趋势:迎接数字时代新变革

利用BigQuery MCP服务器开发面向数据分析的生成式AI应用

LabCompanion宏展全新推出高发热大负载Walk-in试验箱,助力AI算力用大型服务器测试验


普通服务器电源与AI服务器电源的区别(上)

AI 服务器电源测试项目研究报告

Microchip推出模型语境协议(MCP)服务器,助力AI驱动的产品数据访问
AMD Vitis AI 5.1测试版发布
对话|AI服务器电源对磁性元件提出的新需求

ROHM推出全新100V功率MOSFET助力AI服务器和工业电源高效能




评论