 浅谈Vivado编译时间
浅谈Vivado编译时间
随着FPGA规模的增大,设计复杂度的增加,Vivado编译时间成为一个不可回避的话题。尤其是一些基于SSI芯片的设计,如VU9P/VU13P/VU19P等,布局布线时间更是显著增加。当然,对于一些设计而言,十几个小时是合理的。但我们依然试图分析设计存在的问题以期缩短编译时间。
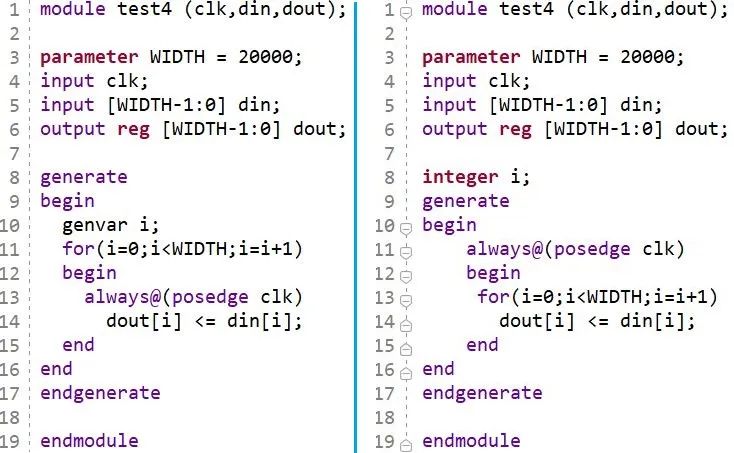
通常,综合(Synthesis)所消耗的时间比布局布线要短,但从代码风格角度而言,我们也能找到一些端倪来缩短综合所用的时间。如下图所示代码,左右两侧功能是一致的,区别在于左侧采用了for generate语句,for循环里嵌套了always模块;右侧实际上不需要generate语句,always里直接使用了for循环(注意:实际上,这里不需要for循环,只是为了说明for循环对编译时间的影响)。单独对左侧模块采用OOC综合,耗时2分钟;而右侧耗时1分钟。因此,我们在用for循环时要谨慎一些。
Vivado还支持多线程可进一步缩短编译时间,这需要通过如下的Tcl脚本进行设置。综合阶段,Vivado可支持的最大线程数为4。布局布线阶段,可支持的最大线程数为8(Windows系统默认值为2,Linux系统默认值为8)。实际上,DRC检查、静态时序分析和物理优化也支持多线程,最大线程数为8。我们可以在log文件中查看到当前使用的线程数。
set_param general.maxThreads 4

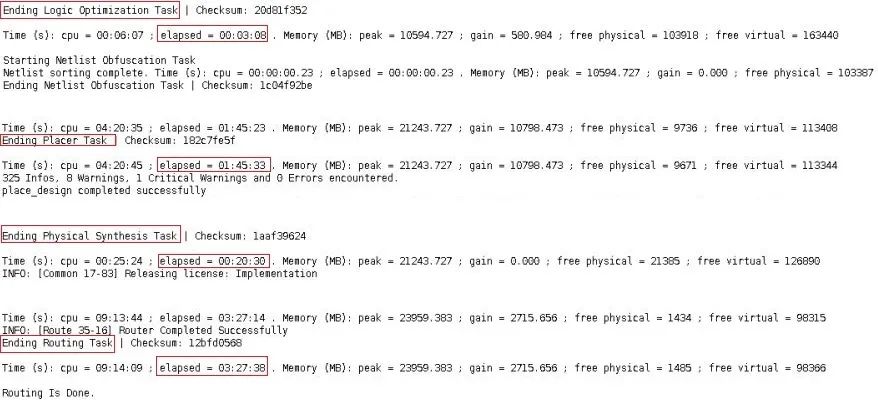
在Vivado Design Run窗口,我们可以查看到整个设计综合和实现的耗时,如下图所示。对于实现各个子阶段的耗时就需要在log文件中查看。只需要搜索关键字Ending,如下图所示。可以看到opt_design耗时3分钟,place_design耗时1小时45分钟,phys_opt_design耗时20分钟,route_design耗时3小时27分钟。

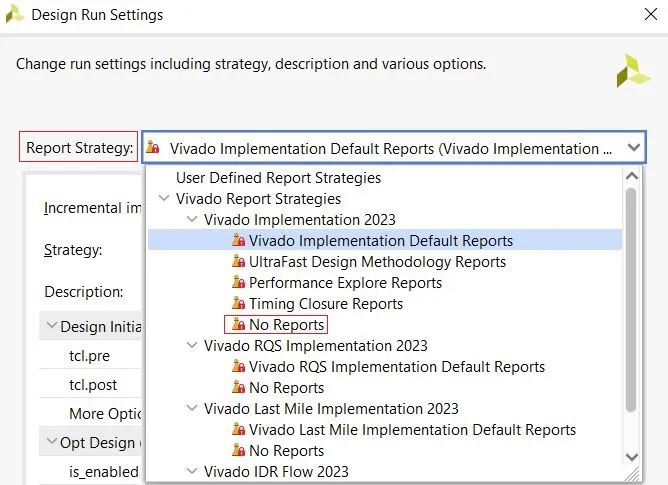
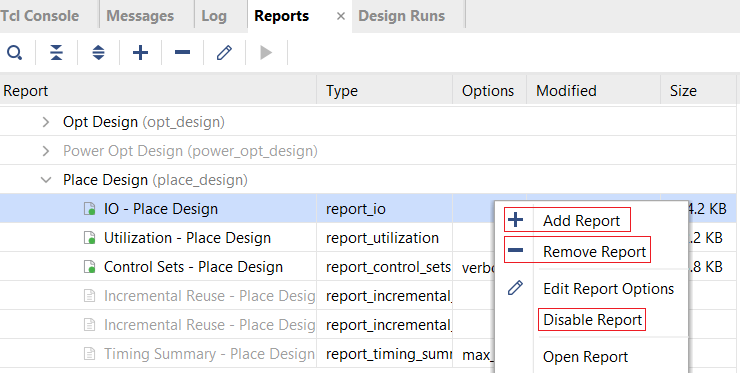
Vivado还提供了报告策略,如下图所示。本身生成报告也是需要时间的,因此可根据设计需要选择报告策略,去除不必要的报告以节省时间。同时,对于已确定的报告策略仍然可以进一步编辑,增加期望的报告或者删除不需要的报告。这可通过Report窗口中的Add Report或Remove Report/Disable Report完成。
通常,布线是耗时最长的部分,为此Vivado对route_design提供了选项-ultrathreads,其目的是使布线器更快的运行,但是以牺牲结果的一致性为代价的。
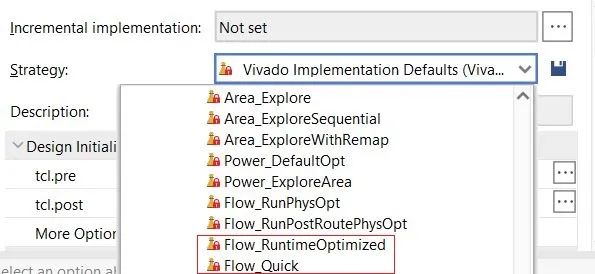
从策略角度看,如果仅仅是为了评估资源利用率,那么Implementation Strategy可以选择Flow_Quick。如果时序裕量比较大,那么也可以选择Flow_RuntimeOptimized,该策略是以牺牲性能为代价来缩短编译时间的。
-
FPGA
+关注
关注
1635文章
21837浏览量
608318 -
芯片
+关注
关注
459文章
51566浏览量
429752 -
编译时间
+关注
关注
0文章
4浏览量
5523 -
Vivado
+关注
关注
19文章
819浏览量
67255
原文标题:再谈Vivado编译时间
文章出处:【微信号:Lauren_FPGA,微信公众号:FPGA技术驿站】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何缩短Vivado的运行时间

谁能缩短大容量FPGA的编译时间?增量式编译QIC!
Vivado中的Incremental Compile增量编译技术详解
Vivado Design Suite 2015.3新增量编译功能介绍
讲述增量编译方法,提高Vivado编译效率
赛灵思Vivado ML版优化应用设计
Vivado里如何手动调整编译顺序
Vivado增量编译的基本概念、优点、使用方法以及注意事项
Vivado那些事儿:节省编译时间系列文章

Vivado编译常见错误与关键警告梳理与解析
每次Vivado编译的结果都一样吗






 工商网监
工商网监
评论