 基于Achronix Speedster7t FPGA器件的AI基准测试
基于Achronix Speedster7t FPGA器件的AI基准测试
作者:Myrtle.ai的Aiken Cairncross、Basile Henry、Chris Chalmers、Douglas Reid,Jonny Shipton、Jon Fowler、Liz Corrigan、Mike Ash
摘要——在部署具有自回归关键路径或递归能力的机器学习网络通常不能很好地利用AI加速器硬件。这类网络就像自动语音识别(Automatic Speech Recognition,简称ASR)中使用的网络一样,必须以低延迟和确定性尾部延迟运行,以适用于大规模实时应用进程。在本文中,我们提出了一种推理引擎的叠加架构,然后在Speedster7t FPGA上实现该架构。Speedster7t系列FPGA芯片是Achronix半导体公司推出的为计算加速优化的器件。我们展示了所考虑到的网络类型的潜在高利用率。其特别之处在于,我们描述了一种双时钟方法,该方法采用的时钟频率为Speedster器件中嵌入的机器学习处理模块(MLP)的额定频率的74.7%。这一结果表明,该器件可以在一组标准的AI基准测试中达到36.4TOPS的算力,并且可以在一系列场景中达到的器件总体效率大约为60%。然后,我们重点介绍该架构对低延迟实时应用进程(如自动语音识别)的优势。
I.简介
Achronix半导体公司推出了为AI优化的Speedster7t系列FPGA芯片,该系列包含专门针对AI工作负载的强化计算引擎。随着AI在各个领域变得普遍,在FPGA芯片上部署AI应用的需求促使了架构创新,关注点放在了在所有深度神经网络处理的核心中添加足够的计算能力来支持核心完成矩阵乘法运算,同时灵活使用FPGA的逻辑阵列来实现AI处理所需的各种其他运算。
FPGA历来都是被用于电信设备,工业系统,汽车电子等嵌入式系统中。现在也被用于数据中心的大规模AI推理加速,如微软的Project Brainwave[1]、SK Telecom [2]和快手[3]所证明的那样。这些部署正在被用于低延迟实时部署,其中FPGA架构支持小批量的高效处理,从而使AI能够被用于那些因为延迟而影响用户体验的地方,例如对话式 AI服务。在这些部署中使用FPGA作为AI推理ASIC经济有效的替代方案,同时保持了灵活的软件可编程优势,可以更好地跟进快速发展的AI技术开发。
在本文中,我们讨论了Achronix最新为AI优化的Speedster7t FPGA器件的特性,以及如何将其高效地用于如自动语音识别(ASR)等的实时应用。我们描述了一种可以高效发挥FPGA作用的叠加架构,并且为核心计算指标GEMV和机器学习处理模块(MLP)的AI操作提供了一组基准测试结果。最后,我们将实现的TOPS和内存带宽数据与器件的总体性能数据进行了比较,以突出部署于AI工作负载时可实现的效率。
II.用于人工智能的Speedster7t器件的特性
当考虑用于AI推理的FPGA器件时,相关器件的关键特性是器件支持的数值精度、可提供的计算单元数量和高速存储器接口的规格。这些因素共同影响目标网络可实现的整体质量和性能。在本节中,我们介绍了用于AI推理的Speedster7t器件的功能,并且在本节的最后,我们讨论了如何组合这些功来确定器件用于低延迟AI推理的能力。
A.机器学习处理模块
Speedster7t 1500 FPGA器件在片上包含了2560个机器学习处理模块。这些硬化的模块运行频率高达750 MHz,在INT8整数格式下可以提供高达61.44 TOPS的总算力。该机器学习处理模块集成了Block RAM和乘法累加电路。这些特性支持其实现最大的性能,因为所有的高带宽数据流都保持在机器学习处理模块内,从而大大减少了将权重和激活移动到器件计算组件中造成的FPGA 路由开销。。机器学习处理模块包含一条相邻模块之间的级联路径,用于共享内存和数据权重或激活数据,并实现有效的数据结构,如脉动阵列架构。
机器学习处理模块的架构如图1所示。
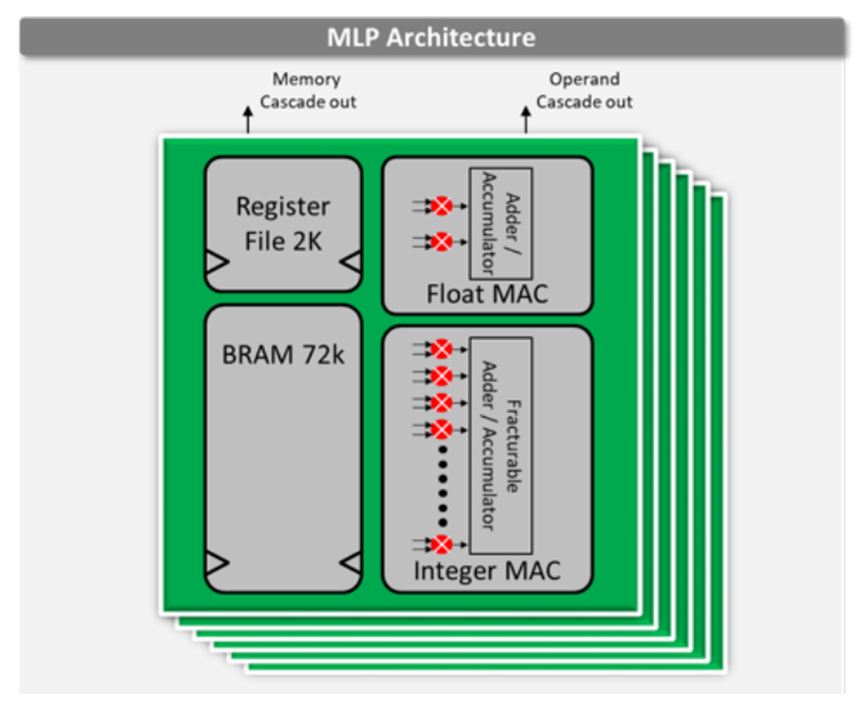
图1. Achronix Speedster7t FPGA上的MLP架构
B. Speedster7t的数值精度
用于推理的量化模型是一种广泛使用的技术,其中的计算操作以一种计算成本较低的格式运行中。该方法已被广泛应用于各种模型,包括BERT[4]、ResNet和GNMT[5],并被广泛认可的机器学习基准测试所采用[6]。
量化过程包括以下一项或两项:
1)减少数据类型的位数。例如,使用8位而不是32位。
2)使用成本较低的格式。例如,使用整数代替浮点数。
量化为整数是人工智能推理的常用选择。以INTX(通常是INT8)整数格式运行推理被广泛用于部署,包括机器翻译[7]、自动语音识别[8]、计算机视觉[9]和嵌入式自然语言处理(NLP)[5]等领域的模型。
得益于硬件供应商的支持,除了INTX和FP16之外的其他格式正变得越来越通用。例如,Google TPU和Intel Xeon CPU就支持BrainFloat16格式。最近,微软也已展示了块浮点格式[10]能够利用训练后的量化流程使网络保持精度,并且实现更高效的硬件计算。块浮点格式可在一系列小数值部分(通常为8或16)上共享单个指数值。该方案比定点算法提供更好的动态范围,同时精度接近传统的浮点,但计算效率相当于整数处理。图2演示了块浮点格式。
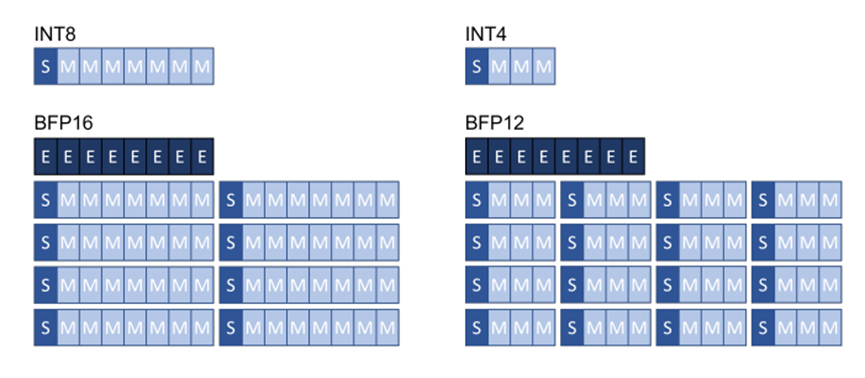
图2. 块浮点量化格式
Achronix Speedster7t FPGA器件可以支持一系列数值格式,因为它在FPGA上的机器学习处理模块中具有完全可拆分的整数MAC。该机器学习处理模块支持INT16、INT8或INT4乘法运算。浮点MAC的增加使器件能够支持fp16, fp24和bf16浮点格式。通过组合两个MAC,则可以支持使用任意块大小的块浮点格式,从而使器件能够实现BFP16和BFP12等格式。表1显示了所支持的数值格式及其可实现的TOPS和相关的内存压缩系数。在本文中,我们使用块大小为8的BFP16和块大小为16的BFP12。
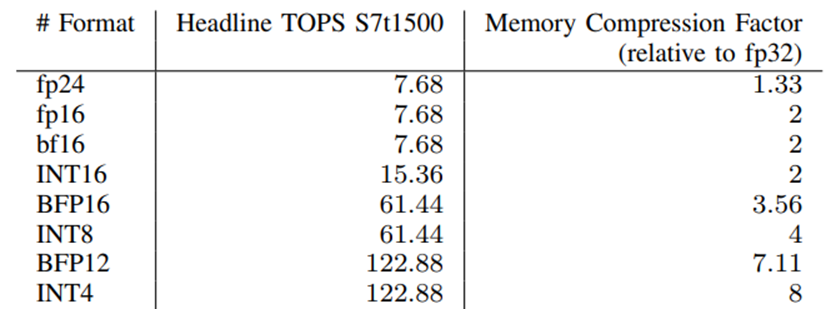
表1. Speedster7t1500在不同数值格式下的计算能力
除了提高计算效率外,精度更低的格式还降低了推理平台的内存带宽要求,这对于受限于内存的处理和低延迟应用来说,可以带来性能的线性提高。
C. GDDR6存储器
Speedster7t的机器学习处理模块中包含的BRAM提供了总计195Mbit的片上存储资源,足以持久地容纳精度为INT8的、规模在24Mbyte以下的AI模型。当神经网络的大小超过这个阈值时,模型参数就需要存储在更大的外部存储器中。就Speedster7t而言,该器件支持最大32GB的外部GDDR6存储器。GDDR6存储器接口如图3所示。这样就可以处理更大的模型,基于4Tb /s的带宽将模型参数移动到器件上,以支持低延迟处理。
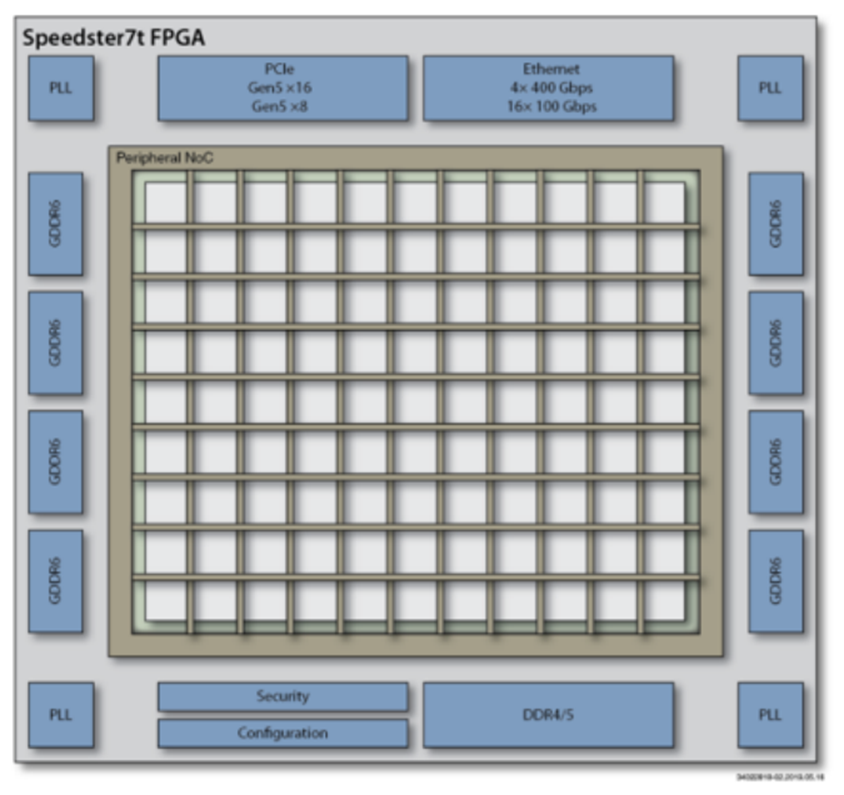
图3. Achronix Speedster7t FPGA的外部接口
想要理解一款器件用于AI推理的性能,重要的是要同时综合考虑计算性能和存储性能;这对于理解低延迟部署或存储密集型网络情况下的性能限制尤为重要;我们可以看到实时数据流ASR和transformer模型架构等方面的案例。卷积神经网络(CNN)通常要求低存储带宽,即使是在小批量的情况下也是如此,因此用于CNN的推理解决方案并没有针对高带宽存储进行优化。
D.全硬件化的片上网络
只有在模型参数能够被移动到器件上的计算引擎中同时不损失效率的情况下,拥有大的外部存储带宽才有用武之地。Speedster7t系列器件包含一个硬核的二维片上网络(2D-NoC),在整个FPGA的总数据传输带宽可以到20Tb/s。这使得数据可以方便地从外部存储器移动到器件的计算引擎中,并可实现跨FPGA逻辑阵列传输,从而不会受限于FPGA计算资源对外部存储的访问带宽。此外,这种2D-NoC减少了为搬运数据而造成逻辑资源的消耗,从而节省了FPGA逻辑中用于路由的资源,并实现更好的时序收敛效果。
2D-NoC的原理如图4所示。
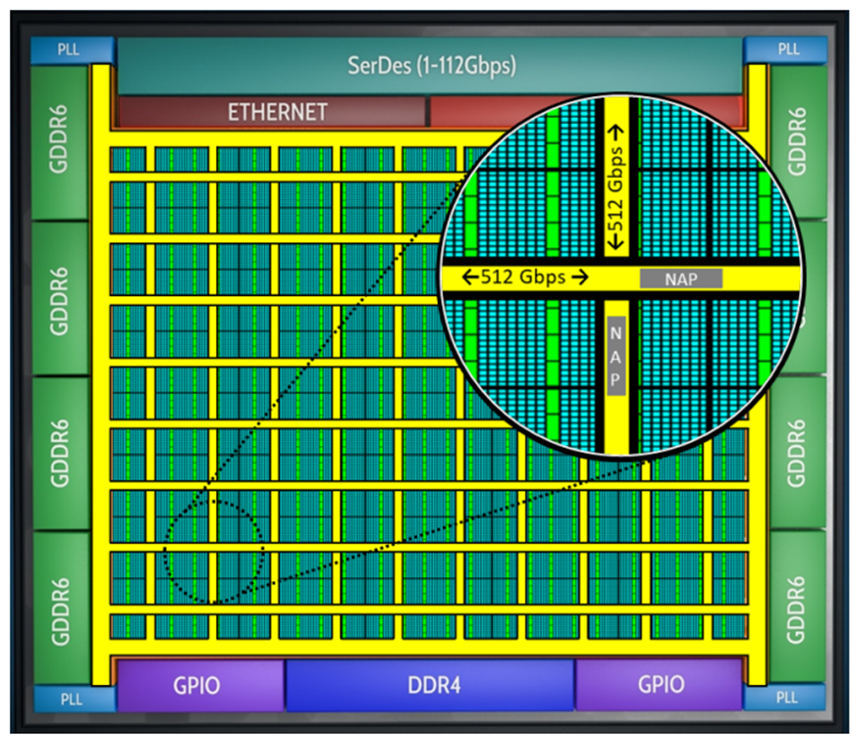
图4. Achronix Speedster7t FPGA中带有的二维片上网络(2D-NoC)
III. 针对Speedster7t的一种AI叠加层架构
为了对Speedster7t系列FPGA器件进行基准测试,我们给在Bittware S7t-VG6 VectorPath PCIe加速卡上的FPGA器件(Speedster7t1500)创建了一个AI推理叠加设计。叠加层采用Myrtle.ai可编程的MAU Accelerator架构来构建,MAU内核是一个用于深度神经网络的可编程的处理引擎,它通过FPGA逻辑资源来构建,以提供一个灵活的且运行时可配置的推理引擎。我们将4个专门为Achronix FPGA器件(Speedster7t1500)进行优化的MAU内核放置在其加速卡上的Achronix FPGA(Speedster7t1500)中去运行,并演示可实现的利用率和时序结果。
该设计使用4个MAU 加速器内核,每个内核都包含512个机器学习处理模块(MLP)模块,以形成所有机器学习推理所需的核心点积电路。完整的设计使用了80%的MLP资源来实现点积计算,剩余的20%用于额外的计算操作和非线性运算,或者仅作为块RAM。
该设计使用BFP16格式实现,如图2所示。它使用8位尾数和8位指数,模块大小均为8。这样可以得到较好的模型精度,可以应用于训练后的模型,而不会损失网络精度,同时简化了架构叠加的用户流程。
我们通过Achronix ACE软件中对MAU Accelerator内核进行布局,以确保保持高时钟频率的同时可以实现高的逻辑资源利用率。
叠加架构的总算力为36.4 TOPS,是FPGA逻辑阵列采用INT8格式时总计算能力的59.2%。这样高的效率数字是通过使用双时钟方案来实现的,使MLP模块能够以560MHz运行,是这些组件的750MHz额定Fmax的74.7%,同时可以在FPGA逻辑中以280MHz的频率实现所有逻辑功能。
为MAU Accelerator内核优化的Achronix Speedster7t FPGA架构如图5所示。它具有面向GEMV和多层感知器(MLP)操作来实现AI基准测试所需的所有功能。
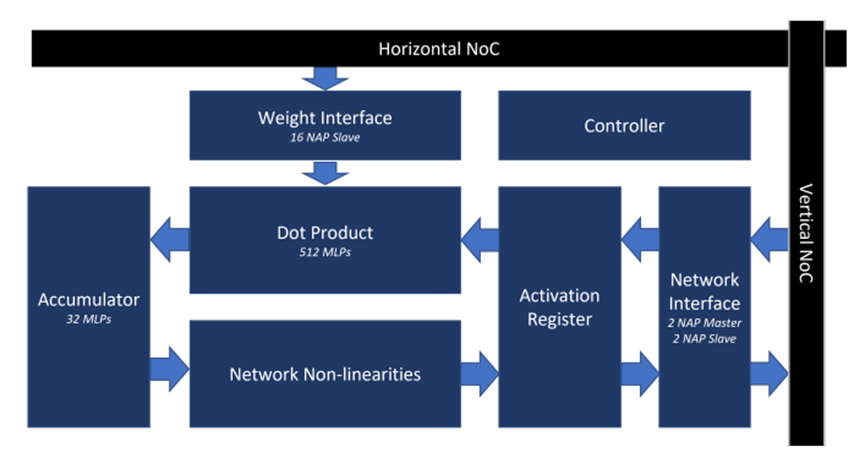
图5. Achronix Speedstert FPGA上的MAU内核架构
A.针对机器学习处理模块的一种双时钟方案
一种双时钟方案被用来为该FPGA中的机器学习处理模块提供时钟。这使得硬核化的芯片组件能够以比逻辑阵列主频更高的时钟频率运行,从而使实际设计应用可以接近这些模块的设计规范的工作频点。这是可能的,因为机器学习处理模块内的BRAM和MAC单元相互紧密耦合,从而使得高权重的数据通过模块内的专用线路传输到MAC。BRAM和MAC之间用于在机器学习处理模块中传输权重的专用线路可承载177 Tb/s的速率,是激活输入的16倍。
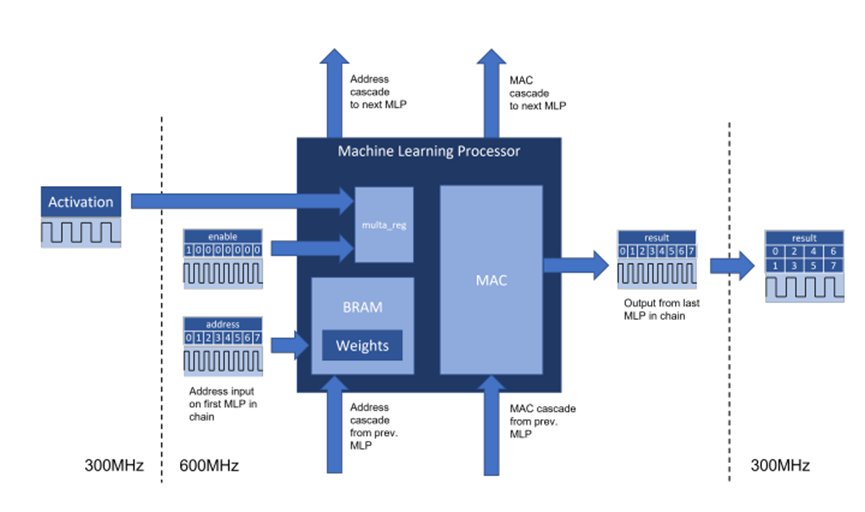
图6. 在Achronix Speedster7t FPGA器件上用于MAU内核架构的双时钟方案
位于MAU Accelerator内核中心的点积电路将256x256矩阵和256向量数据进行相乘。矩阵通常用于权重,向量通常用于激活。激活向量在560MHz时钟域上保持恒定超过8个周期,而权重则从与MAC紧密耦合的BRAM中读取,并在每个周期进行更改。机器学习处理模块被排列成每列32个共16列,它们被级联在一起以便每列都可计算两个大小为256的BFP16点积。
激活向量通过激活扇出组件分发到机器学习处理模块中,该组件还处理延迟激活,以与机器学习处理模块之间的级联传递的部分和相对齐。要从结果中读取的权重索引在列的顶部输出。输出在560MHz域上,相邻时钟周期的值则通过一个逻辑反序列化器连接并传输到280MHz域上。机器学习处理模块在每个内核中都被布置为两个外部列,并保留中央列以供其他设计单元和网络特定操作使用。这可以在图7的布局中看到。
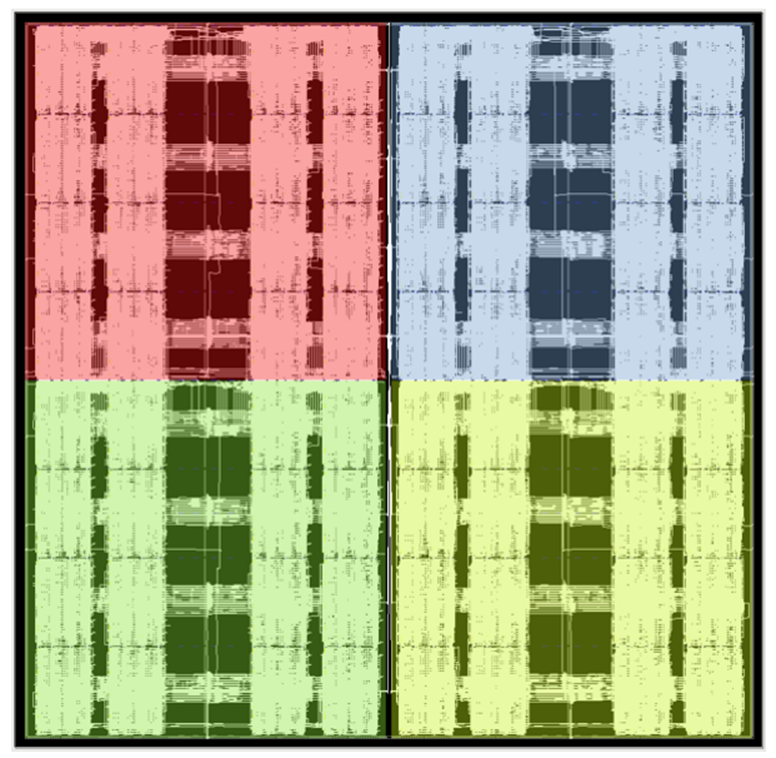
图7. Achronix Speedster7t FPGA上点积电路的平面布置图
B.二维片上网络(2D-NoC)的使用
二维片上网络(2D-NoC)被用于在整个设计中传输数据,降低了将逻辑阵列资源用于数据传输的需求。2D-NoC用于通过PCIe接口在CPU和FPGA之间传输推理数据;于运行时在GDDR6和MAU Accelerator加速器内核之间传输权重数据,从而使大型网络能够保存在片外存储器中;并可以用于在芯片上的MAU Accelerator加速器内核之间传输推理数据,从而使数据能够在实现不同层操作的内核之间传递,或跨内核拆分矩阵操作。
每个内核都有16个网络接入点(NAP),用于从GDDR6加载权重;这些接入点NAP在280MHz主频时提供高达1.12 Tb/s的带宽,这大于每个内核分配到的1Tb/s可用内存带宽。这可以确保在受限于内存的网络和低延迟操作场景中去实现最高性能。每个内核所具有的16个NAP Slave的从连接分布在4个hNoC行上。
对于主机到内核和内核到内核的数据传输,该设计中每个内核都具有2个NAP Master主连接和2个NAP Slave从连接。内核间的数据带宽为143.36 Gbps。除了非常小的矩阵计算外,这对于在内核之间传输的大多数操作来说已经足够了。
C.器件利用率
该器件用于加速器叠加架构时的资源利用率如表II所示。这表明,用于实现高性能AI计算的机器学习处理模块和BRAM的利用率都非常高,同时只有LUT和DFF在逻辑阵列中具有低资源利用率。这为在逻辑阵列中实现其他功能提供了空间,并减少了逻辑阵列中的路由拥塞,从而在FPGA中获得更高的时钟频率。
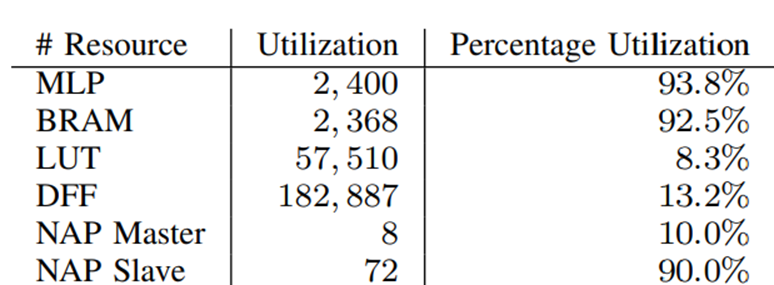
表2. MAU Accelerator加速器内核叠加架构的资源利用率
IV. AI基准测试结果
A.测试方法
我们在Speedster7t上对两种简单的操作进行基准测试,以说明AI网络可以达到的性能。我们执行了GEMV基准测试和多层感知器(MLP)基准测试。GEMV测试展示了所有AI基准测试的核心操作的性能。
GEMV-N基准测试计算Ax + y,其中A是维数为N的方阵,x和y为N的向量。MLP-N基准测试计算一个5层的多层感知器,每层都被定义为layeri(xi) = Wixi+bi,其中Wi为N × N方阵。每一层的输入如下,xi+1 = layeri(xi), x0是输入。
我们使用硬件周期计数器来测量计算一个特定基准测试所需的时间,并从稳态测量中推断吞吐量。我们没有对CPU和FPGA之间的数据传输进行计时,因为这只会支配这些非常小的基准测试操作的处理时间。在最初从外部GDDR6存储器加载之后,所有的基准测试都使用存储于BRAM中的常量。
B,计算性能
图8显示了GEMV和MLP在不同大小的矩阵上所展示的高性能。基准测试在四个内核上并行进行,因此Batch 4意味着在每个内核上独立运行一个推理。对于Batch 20的结果,每个内核就要运行5个流水线推理。叠加架构被用作GEMV基准测试,效率为100%,其中矩阵可被512整除。
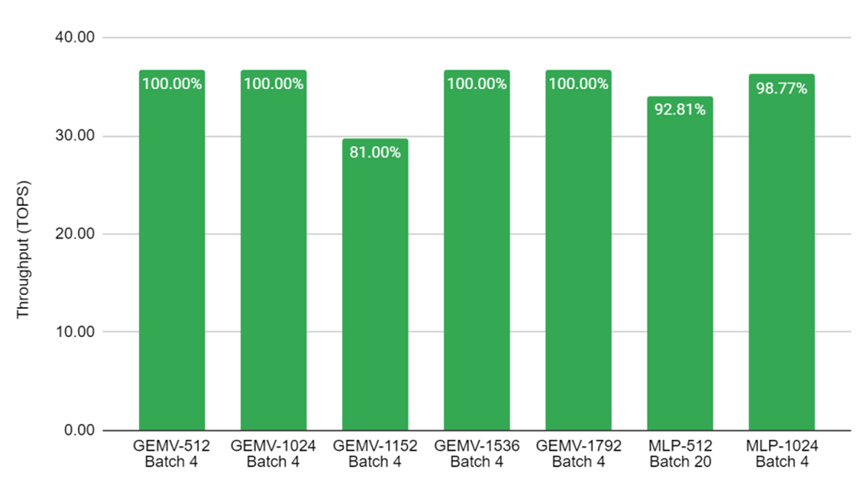
图8.在Achronix S7t-VG6 VectorPath加速卡上进行关键AI基准测试的吞吐量数值。结果是在C2速度等级的器件上以560MHz运行来测量的。坐标标签显示了利用率占MAU Accelerator总性能的百分比。
C.可实现最高性能
考虑到用于低延迟和实时应用的加速平台,图9显示了Achronix Speedster7t1500器件实现的最高性能曲线。在该器件上可以36.4 TOPS的算力实现算术强度超过70个运算/字节的网络以 RNN-T 操作点为例,突出显示加速器在流式部署中以批处理大小为 8 和 80ms 块大小的 MLPerf RNN-T 参考模型的处理需求。
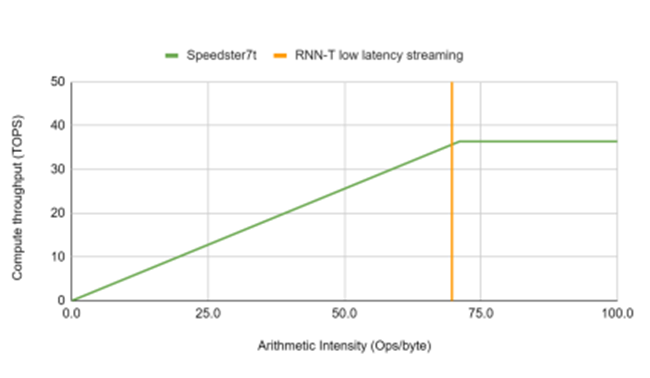
图9. 通过使用总内存带宽,Achronix器件实现的最高性能曲线和RNN-T工作点
V.结论
本文展示了由Achronix提供的全新专为AI优化的FPGA器件——Speedster7t1500系列,当被应用于关键AI基准测试时,能够实现59.2%的效率和36.4 TOPS的算力。其专为AI优化的架构支持高时钟频率计算,且高外部内存带宽使该器件非常适合用于低延迟工作负载。
-
FPGA
+关注
关注
1629文章
21736浏览量
603313 -
半导体
+关注
关注
334文章
27362浏览量
218640 -
AI
+关注
关注
87文章
30887浏览量
269060 -
Achronix
+关注
关注
1文章
76浏览量
22538
原文标题:基于Achronix Speedster®7t FPGA器件的AI基准测试
文章出处:【微信号:Achronix,微信公众号:Achronix】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Achronix Speedster7t FPGA如何运用GDDR6满足网络产品的高带宽需求
利用片上高速网络(2D NoC)创新地实现FPGA内部超高带宽逻辑互连
中高端FPGA如何选择
Achronix推出Speedster7tFPGA系列产品 简化设计FPGA灵活性

Achronix推全新7nm FPGA 首度支持GDDR6高带宽存储

BittWare和Achronix合作推出采用7纳米的Speedster7t FPGA
2D NoC可实现FPGA内部超高带宽的逻辑互连
Achronix展示Speedster7t高性能接口 贸泽备货Molex电路板连接器
Achronix Speedster7t FPGA芯片中2D NoC的设计细节
Speedster7t FPGA中可编程逻辑的架构
Achronix将在SC22上展示全系列基于FPGA的硬件数据处理加速器
Achronix的FPGA有哪方面的优势?

采用创新的FPGA 器件来实现更经济且更高能效的大模型推理解决方案





 工商网监
工商网监
评论