 光进铜退,已成定局?
光进铜退,已成定局?
来源:半导体行业观察 翻译自Timothy Prickett Morgan
如今,众所周知的是,用于连接分布式系统的交换机并不是网络中最昂贵的部分,而光收发器和光纤电缆才是成本的主要部分。由于这一点,以及光学元件运行时温度高且经常发生故障,人们除非必要,否则不会使用光学元件。
因此,我们有了铜缆,越来越多地直接从交换机 ASIC 及其连接的设备驱动,用于短距离传输,以及光缆用于长距离传输,这些设备是为 AI 和 HPC 系统提供 1000、10000 或 100000 台设备所必需的。早在 5 月份,当Broadcom 推出其“Thor 2”网络接口卡芯片时,以及在 Nvidia 于 3 月份推出GB200 NVL72 机架式系统之后,我们就曾打趣过这个问题,在可以的时候使用铜缆,在必须的时候使用光缆。Broadcom 和 Nvidia 都会告诉你,机器的经济性和可靠性取决于这种方法。
GB200 NVL72 系统将这一原则发挥到了极致。该系统使用 5184 条大铜缆将 72 个“Blackwell”GPU 捆绑在一起,形成一个全对全共享内存配置,NVL72 系统核心的九台 NVLink Switch 4 交换机中的 200 Gb/秒 SerDes 可以通过铜线直接驱动每个 Blackwell GPU 上的 1.8 TB/秒 NVLink 5 端口,无需重定时器,当然也不需要长途数据中心网络中使用的光收发器。
据 Nvidia 联合创始人兼首席执行官黄仁勋介绍,与使用光收发器和重定时器相比,这种方法非常有效,可节省约 20 千瓦的电力,将机架功耗从原来的 120 千瓦降至 100 千瓦。(黄仁勋最初给出的规格说明称,NVL72 的功率为 120 千瓦,但现在的规格表显示,如果使用全铜互连,机架级节点的功率为 100 千瓦。我们认为,他在讲话时未使用光学器件,因此节省了 20 千瓦的功率。)
无论如何,这张 NVL72 节点的图片足以让您想在商品市场上购买铜:

Ayar Labs 的联合创始人兼首席执行官马克·韦德 (Mark Wade) 却不相信这些,该公司发明了名为 TeraPHY 的光学 I/O 芯片以及用于驱动该芯片的名为 SuperNova 的外部激光光源。
“我认为铜缆已经不起作用了,”韦德在本周的人工智能硬件峰会上发表主题演讲之前向The Next Platform解释道。“目前没有一家公司在应用层面真正实现了显著的经济产出。问题不在于铜缆何时失效,光学器件何时成本持平并变得可靠。铜缆已经无法以经济的方式支持人工智能工作负载。是的,投资者资助的淘金热已经持续了两年,这确实推动了玩家硬件的所有利润。但铜缆已经无法支持高效、经济、高性能的人工智能工作负载系统。该行业实际上正在努力摆脱技术已经失败的困境,硬件制造商需要大幅提高这些系统的成本效益吞吐量。否则,我们都将走向互联网式的危机。”
显然,这些话非常有说服力,尤其是考虑到 Nvidia、AMD、台湾半导体制造公司、SK 海力士、三星、美光科技等 GPU 加速器供应链各部分的订单量和实力。但请听听韦德的说法,因为他将提出一个有趣的案例。
Ayar Labs 显然有既得利益,可以迫使公司转向封装在 GPU 上的光学 I/O 以及将它们互连的交换机,为了证明这一点,该公司构建了一个系统架构模拟器,该模拟器不仅关注各种技术的进给和速度,还关注它们在 chewing on和 generating tokens方面的盈利能力。
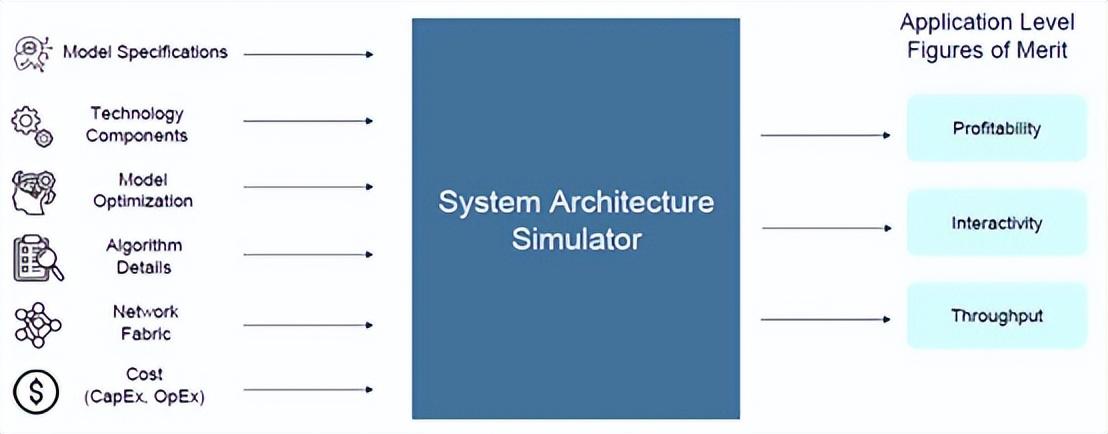
现在,Wade 承认,这个用 Python 编写且尚未命名的模拟器并不是“周期精确的 RTL 模拟器”(cycle accurate RTL simulator),但表示它的设计旨在整合一大堆关键组件的规格——GPU 速度和馈送、HBM 内存和容量、封装外 I/O、网络、CPU 主机、GPU 的 DRAM 扩展内存等等——并预测各种 AI 基础模型的性能以及处理每个token的相对成本。
AI 系统架构模拟器关注三个性能指标,而不仅仅是大多数人谈论的两个。它们是吞吐量和交互性,每个人都对此着迷,但也将处理的盈利能力纳入考量。提醒一下:
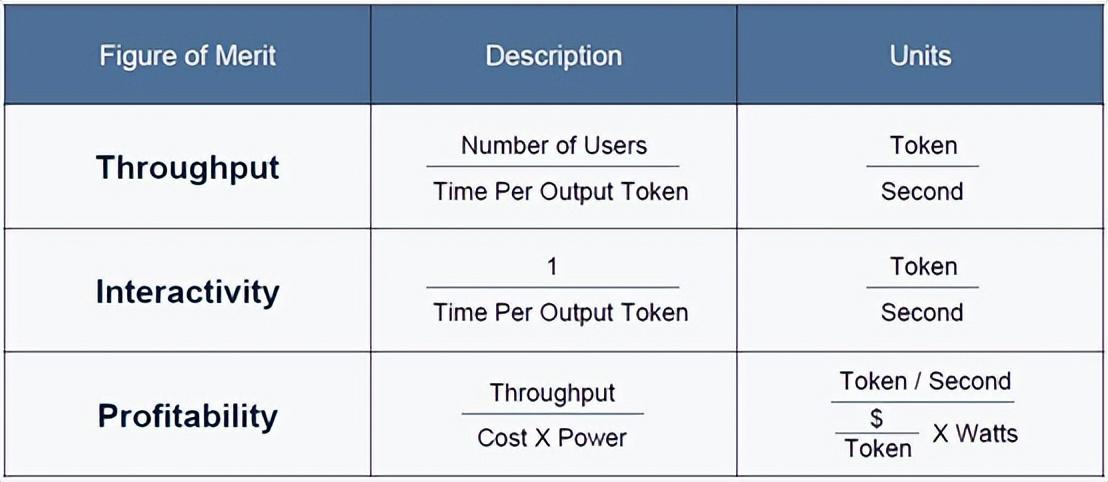
显然,Ayar Labs 认为 AI 集群节点的所有关键元素——CPU、GPU、扩展 DRAM 内存以及用于连接 GPU 的节点内扩展交换——都应该使用光学而不是电互连,具体来说,AI 服务器应该使用由其 SuperNova 激光器泵浦(pumped )的 TeraPHY 设备。
但在我们开始进行系统架构比较之前,Wade 为他的论点添加了另一个层次,区分了三种不同类型的 AI 应用领域:
第一种是批处理( batch processing),其中查询组被捆绑在一起并一起处理,就像五十年前的大型机事务更新一样。(好吧,就像大型机在今天的夜班期间所做的大量工作一样。)批处理级别需要每秒 25 个tokens或更少的交互级别。人机交互(我们习惯于以生成文本或图像的 API 形式公开的应用程序)需要以每秒 25 到 50 个tokens的速度运行。而机器对机器代理应用程序的圣杯,其中各种 AI 以高速相互通信以解决特定问题 - 需要每秒 50 个tokens以上的交互率(interactivity rates)。
后一种应用在使用电气互连的经济实惠的系统上很难实现,正如 Ayar Labs 模拟器所示。公平地说,像 Nvidia 这样的公司之所以如此粗暴地使用电气互连和铜线,是因为个别光学元件的可靠性和成本问题仍需要解决。
但 Wade 表示,这些问题正在得到解决,而且其 TeraPHY 和 SuperNova 组合可以与 2026 年及以后推出的 GPU 一代相交叉。
话虽如此,让我们来看看 Blackwell GPU 的馈送和速度,以及Nvidia 2026 年路线图上的未来“Rubin”GPU 以及 2027 年内存升级,可能会采用当前的电气/铜线方式和假设的光纤/光纤方式进行架构。看一下这个:
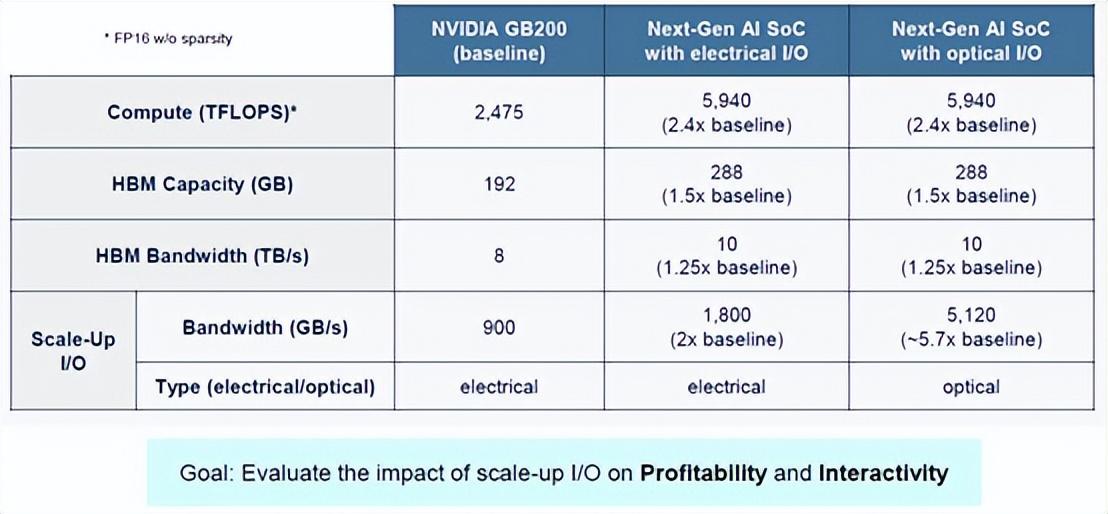
Nvidia GB200 节点有一个“Grace”CG100 Arm CPU 和一对 Blackwell GB100 GPU 加速器,因此显示的计算容量是规格表上的一半。看起来 GB200 将获得 192 GB 的 HBM 容量和 8 TB/秒的完整带宽,而 HGX B100 和 HGX B200 卡将获得容量仅为 180 GB 的 Blackwell。至少目前如此。扩展电气 I/O 来自每个 Blackwell 芯片上的 NVLink 5 控制器,该控制器有 18 个端口,运行速度为 224 Gb/秒,为 Blackwell GPU 提供 900 GB/秒的总传输和接收带宽(总计 1.8 TB/秒)。
Wade 对 Rubin GPU 的外观做了一些假设,我们认为它很有可能由四个通过 NVLink 6-C2C SerDes 互连的受限光罩(reticle-limited) GPU 芯片组成,就像 Blackwell 是两个通过 NVLink 5-C2C SerDes 互连的受限光罩 GPU 一样。我们知道 Rubin HBM 内存将提升至 288 GB,我们和 Wade 都预计 Rubin 设备中的带宽将提升至每台设备约 10 TB/秒。(2027 年,Rubin Ultra kicker 中的带宽可能会进一步提升至 12 TB/秒。)可以合理地假设 NVLink 6 端口将再次将电气互连的性能提高一倍,达到单向 1.8 TB/秒,这可能是通过将每个端口的信号量增加一倍来实现的。
Ayar Labs 模拟器用 TeraPHY 光纤链路替换 NVLink 6-C2C,这样,每个方向的带宽将增加 5.7 倍,达到 5 TB/秒。模拟器还假设,与机架式 Blackwell 系统中使用的 NVSwitch 4 ASIC 相比,NVSwitch 5 芯片在 Rubin 一代中的性能将翻倍,而 Nvidia 将再次直接从 NVSwitch 5 芯片中驱动电信号。如果您通过 Ayar Labs AI 系统架构模拟器运行这两个假设的 Nvidia 场景,并测量吞吐量和盈利能力(在互联网时代我们称之为每 SWaP 的美元,SWaP 是空间、瓦特和功率的缩写),在一系列交互中,您会得到这张漂亮的图表:
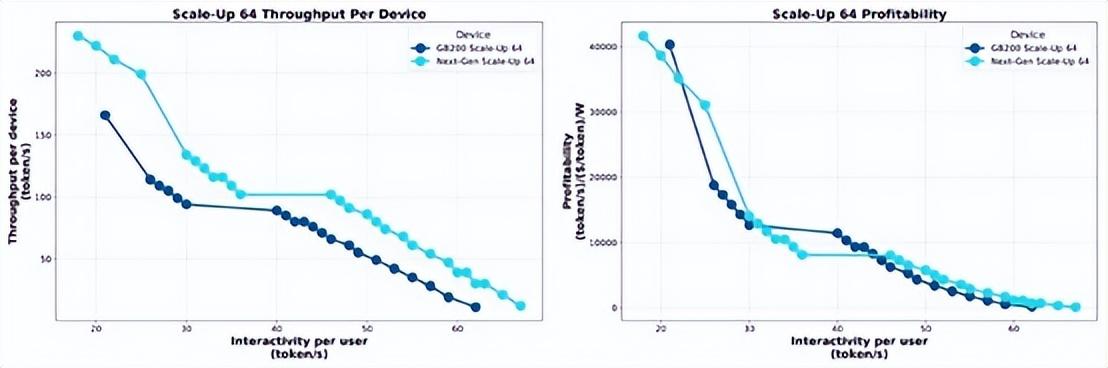
正如您所看到的,在具有电信号的 64 GPU 系统中,从 Blackwell 转移到 Rubin 并没有真正在一定交互水平的吞吐量方面产生太大的变化,并且每瓦特每单位工作成本也不会有太大变化。看起来,对于给定的工作单位,Rubin 的成本将与 Blackwell 相同,至少对于 Wade 所做的假设而言是如此。(考虑到现在在 AI 领域的高层,时间就是金钱,这对我们来说是合理的。)
现在事情会变得有趣起来。让我们看看 OpenAI 的 GPT-4 大型语言模型如何在 Ayar Labs 模拟器中针对不同规模的不同 Nvidia GPU 在盈利能力与交互性方面对运行推理进行对比:
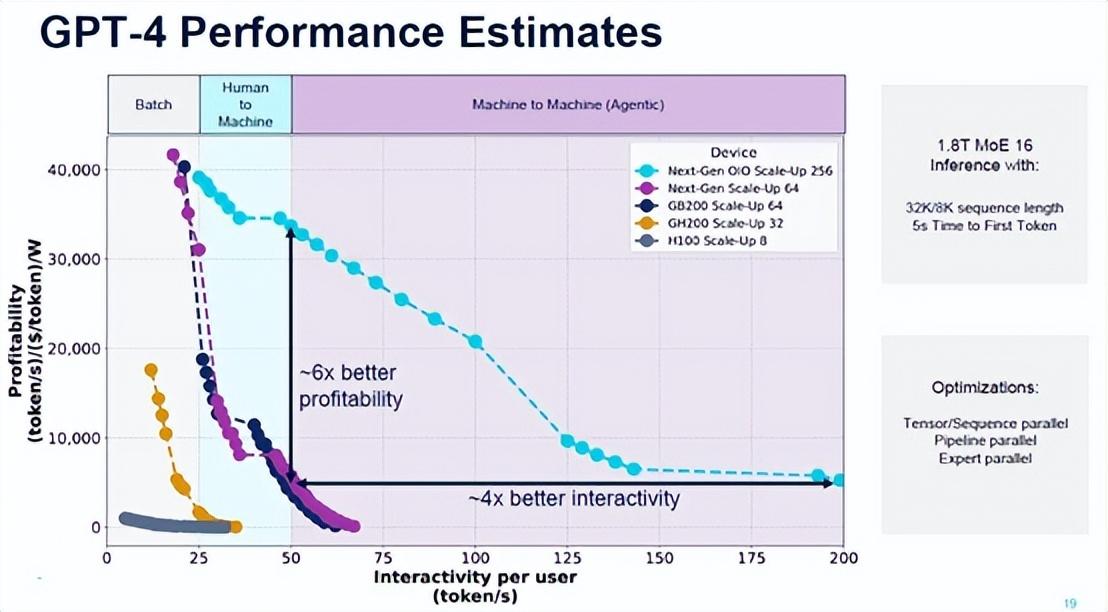
这张图表非常有趣。
首先,它表明八路 Hopper H100 节点对于批量 GenAI 来说是可以接受的,并且几乎无法进行人机对话。有了 32 个 GH200 超级芯片集群(配备 141 GB HBM3E 内存),批量 GenAI 的成本大大降低,性能相对于较小的 H100 节点也有了很大的提高。配备 64 个 GPU 的 GB200 节点开始真正弯曲曲线,但在 64 个 GPU 的情况下,GB200 和未来的 GR200 之间的差异并不明显。
但是,看看当 Rubin 推出光学 I/O 而不是电气 NVLink 端口和电气 NVSwitch 端口时会发生什么,并且机器扩展到 256 个连贯的 GPU,这在铜缆中是不可能的,因为您无法将那么多 GPU 彼此靠近以进行互连。机器对机器的多模型处理不仅成为可能。(再次,我们将指出:不要将机器联网…… TeraPHY 确实如此。)假设的 Rubin GPU 的盈利能力和吞吐量相互作用的曲线在使用光学 I/O 时要好得多。
这张图表表明了一些事情:Ayar Labs 正在试图让 Nvidia 收购它,或者试图让 Nvidia 使用其 OIO 芯片,或者尝试过但失败了,并利用这个故事试图让 AMD 收购它。英特尔现在连一杯咖啡都买不起。
现在,让我们来看看 OpenAI 在 2026 年左右推出的最先进的 GPT 模型,我们假设它将被称为 GPT-6,但为了安全起见,Wade 将其称为 GPT-X。
随着 2026 年 GPT-X 的推出,该模型的复杂度将翻倍,达到 32 个不同的模型(称为专家模型),而 Wade 预计模型的层数将从 GPT-4 的 120 层增加到 128 层。(我们认为层数可能会更高,可能高达 192 层;我们拭目以待)。标记序列长度将保持稳定,输入为 32k,输出为 8K,文本嵌入的模型维数将翻倍,达到 20,480。
如下所示,现有的 Hopper 和 Blackwell 配置从 8 个 GPU 扩展到 64 个 GPU,所有机器都被推入批量性能领域,只有采用铜 NVLink 互连的 Rubin 机架式机器才能进入人机领域。但是,借助节点内和节点间的光学 I/O 以及扩展到 256 个 Rubin GPU,Nvidia 可以构建一台可以扩展到人机和机器对机器领域的推理机,同时在交互性和成本方面提供可接受的改进。
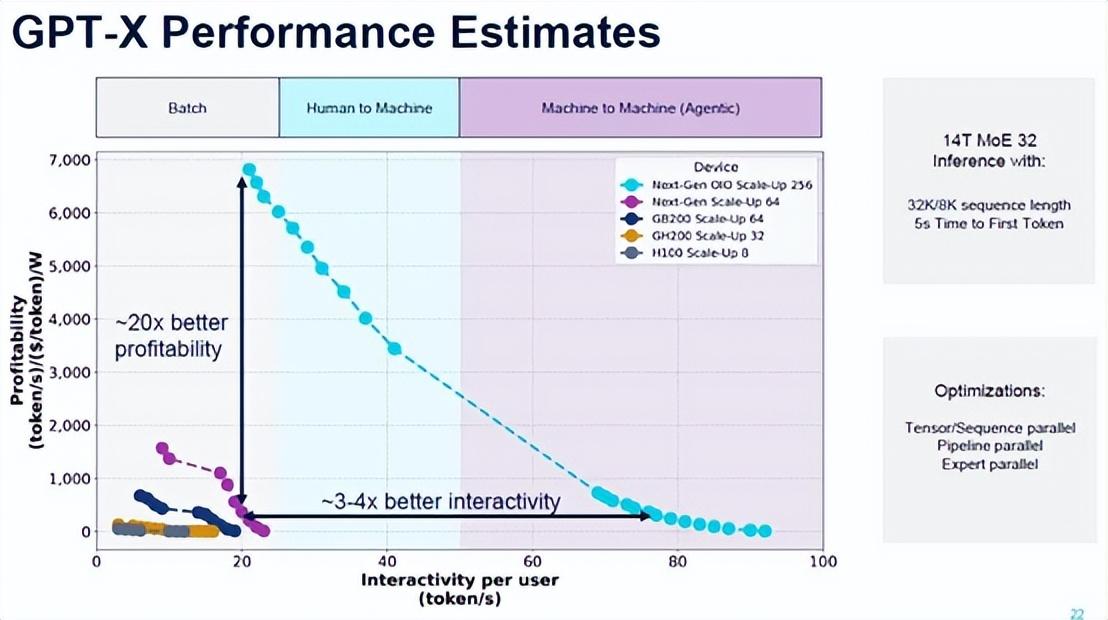
该图表是 Ayar Labs、Eliyan、Avicena、Lightmatter 和 Celestial AI 等公司的广告。我们强烈怀疑 Rubin 会将 NVLink 转移到光学互连,坦率地说,考虑到Nvidia 多年前所做的原型设计以及 Nvidia 已经与 Ayar Labs 以及很可能与上面提到的其他一些公司合作的工作,我们已经预料到这样的机器了。
NVLink 只是一种协议,现在或许是时候将其转移到光学传输中了。我们迫不及待地想看看 Nvidia 会在这里做些什么。在机架中塞入更多 GPU 并将功率密度提高到 200 千瓦或人们谈论的疯狂的 500 千瓦可能不是答案。光学互连会将这个铁芯稍微隔开一点,也许足以防止光学器件出现不良行为。
-
半导体
+关注
关注
334文章
27320浏览量
218303 -
gpu
+关注
关注
28文章
4733浏览量
128912 -
交换机
+关注
关注
21文章
2639浏览量
99573
发布评论请先 登录
相关推荐
车载光纤通信技术革命,“光进铜退” 的趋势不可逆转
PCB设计中填充铜和网格铜有什么区别?
光猫产品需不需要做CTA进网许可认证?







 工商网监
工商网监
评论