 简单快捷地用小型Xiliinx FPGA加速卷积神经网络CNN
简单快捷地用小型Xiliinx FPGA加速卷积神经网络CNN
刚好在知乎上看到这个问题如何用FPGA加速卷积神经网络CNN,恰巧我的硕士毕业设计做的就是在FPGA上实现CNN的架构,在此和大家分享。
先说一下背景,这个项目的目标硬件是Xilinx的PYNQ。该开发板加载了Linux Ubuntu操作系统,可以在CPU上运行现有的Python CNN架构如Caffe和Theano。本设计旨在用PYNQ加载的ZYNQ FPGA对于CNN核心计算进行硬件加速,以达到对于大规模信息流进行大吞吐量CNN处理。
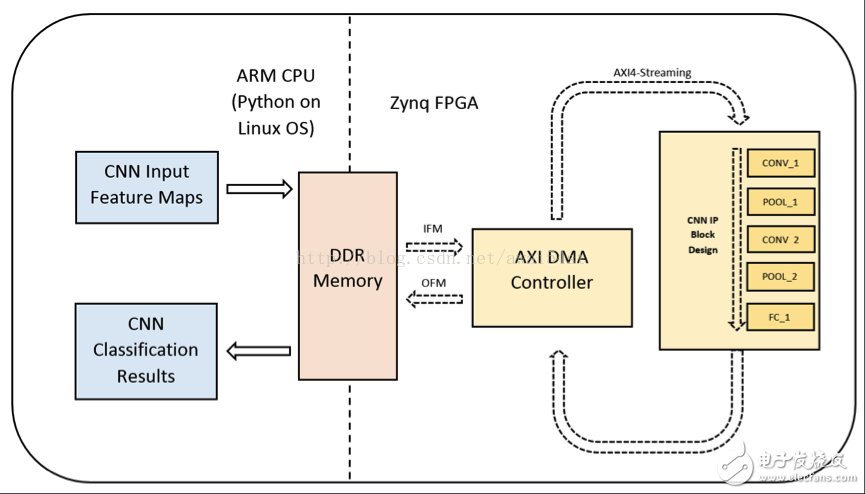
该设计结构可以分为CPU端(前端)和FPGA端(后端)两部分。前端使用的是Python,用来与其他软件项目进行交互。前端将数据以数据流的形式由DDR传输到FPGA kernel。后端的FPGA硬件设计使用的是Synchronous Dataflow Paradigm。在这个结构之下,数据流以AXI-Stream的协议穿梭于每一个CNN层。每一个层都使用并行结构加上高性能流水线,使整体吞吐量效率达到一个非常可观的水平。
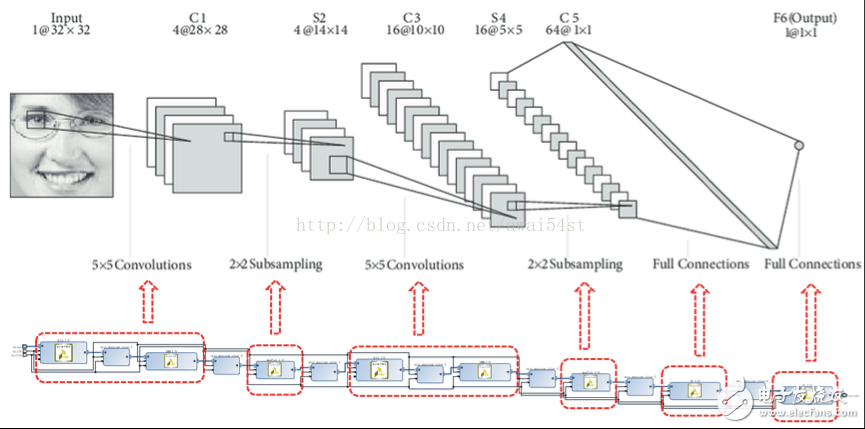
上图为实现LeNet-5的硬件结构示意图。对于LeNet-5,该设计达到了1.88GOP/S的吞吐量,与PYNQ上的DUAL CORE ARM CPU相比加速约32倍。目前该架构可运行LeNet和CIFAR10,有教程。
这个项目结构比较简单,适合FPGA初学者作为研究起点使用。感兴趣的话,可以以这个架构为基础设计几个CNN的应用,或者在它的基础上进行优化和再创造。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
FPGA
+关注
关注
1630文章
21761浏览量
604390 -
神经网络
+关注
关注
42文章
4774浏览量
100912
发布评论请先 登录
相关推荐
【PYNQ-Z2申请】基于PYNQ的卷积神经网络加速
项目名称:基于PYNQ的卷积神经网络加速试用计划:申请理由:本人研究生在读,想要利用PYNQ深入探索卷积神经网络的硬件
发表于 12-19 11:37
卷积神经网络如何使用
卷积神经网络(CNN)究竟是什么,鉴于神经网络在工程上经历了曲折的历史,您为什么还会在意它呢? 对于这些非常中肯的问题,我们似乎可以给出相对简明的答案。
发表于 07-17 07:21
卷积神经网络简介:什么是机器学习?
抽象人工智能 (AI) 的世界正在迅速发展,人工智能越来越多地支持以前无法实现或非常难以实现的应用程序。本系列文章解释了卷积神经网络 (CNN) 及其在 AI 系统中机器学习中的重要性。CNN
发表于 02-23 20:11
卷积神经网络CNN图解
之前在网上搜索了好多好多关于CNN的文章,由于网络上的文章很多断章取义或者描述不清晰,看了很多youtobe上面的教学视频还是没有弄懂,最后经过痛苦漫长的煎熬之后对于神经网络和卷积有了
发表于 11-16 13:18
•5.7w次阅读


卷积神经网络CNN架构分析 - LeNet
之前在网上搜索了好多好多关于CNN的文章,由于网络上的文章很多断章取义或者描述不清晰,看了很多youtobe上面的教学视频还是没有弄懂,最后经过痛苦漫长的煎熬之后对于神经网络和卷积有了
发表于 10-02 07:41
•677次阅读
cnn卷积神经网络分类有哪些
卷积神经网络(CNN)是一种深度学习模型,广泛应用于图像分类、目标检测、语义分割等领域。本文将详细介绍CNN在分类任务中的应用,包括基本结构、关键技术、常见





 工商网监
工商网监
评论