 澎峰科技高性能大模型推理引擎PerfXLM解析
澎峰科技高性能大模型推理引擎PerfXLM解析
自ChatGPT问世以来,大模型遍地开花,承载大模型应用的高性能推理框架也不断推出,大有百家争鸣之势。在这种情况下,澎峰科技作为全球领先的智能计算服务提供商,在2023年11月25日发布了针对大语言模型的高性能推理框架,并受到广泛关注。在历经数月的迭代开发后,澎峰科技重磅发布升级版本,推出全新的高性能大模型推理引擎:PerfXLM。
PerfXLM采用了云端一体架构,支持云端推理和本地推理两种模式。在硬件支持上,PerfXLM适配了包含多种国产处理器在内的不同硬件,并针对硬件体系结构特征进行了深入性能优化,大幅提升了大模型推理性能。
一、PerfXLM整体架构

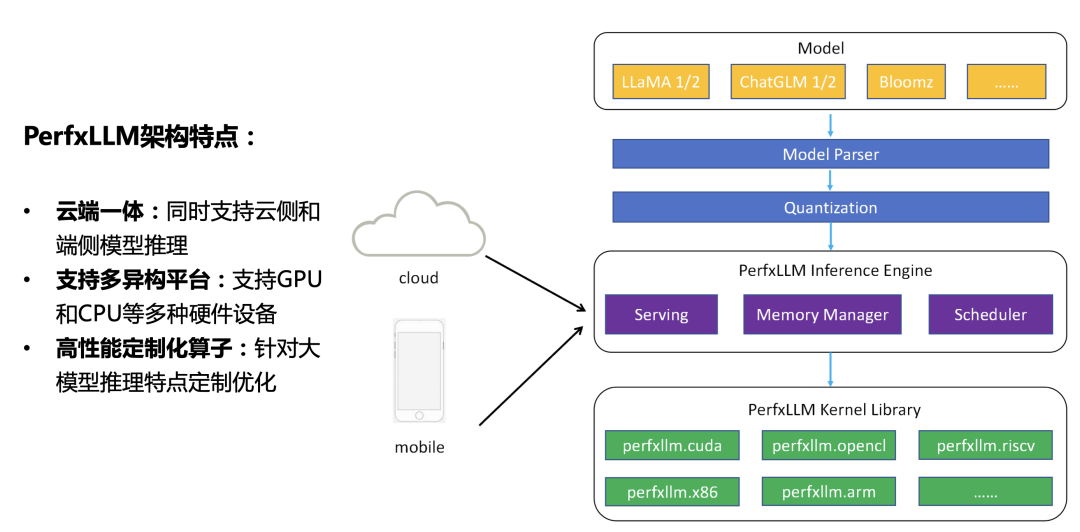
图1.PerfXLM整体架构
如图1所示,PerfXLM整体架构分为三层:
1.模型转换层。将Torch或者Huggingface格式的大模型转化为统一的内部模型结构,并最终统一表达为ONNX图。
2.推理引擎层。实现了ONNX图解析、算子调度、统一内存管理等功能,大幅提升硬件资源利用率;同时,也提供了针对云端推理的专用Serving模块,以获得更高的硬件利用率和QPS响应。
3.性能层。提供了针对大模型推理的高性能算子库,并针对各种主流硬件进行了适配和优化。
PerfXLM具有的三大特点:
1.云端一体,同时支持云侧和端侧大模型推理,能够让大模型适用于各种应用场景之中。
2.支持多异构平台,支持了包括NVIDIA GPU、海光DCU、高通Adreno GPU、Intel iGPU、某国产GPU在内的多种硬件设备
3.高性能定制优化算子,实现了结合体系结构特征和大模型推理应用特征的定制优化。
二、大模型推理中的MxN问题
PerfXLM向上对接各种模型网络,向下适配各种硬件架构。这就存在着一个组合问题:假设需要支持M个模型和N种硬件,那么一共有MxN种组合方式。PerfXLM需要实现对主流模型的支持,目前主流模型大概有几十种,国内甚至一度“千模大战”。同时,PerfXLM也需要实现对主流硬件的支持,包括NVIDIA GPU、AMD GPU、海光DCU、沐曦GPU等通用GPU架构;X86、ARM、RISC-V等通用CPU架构;高通Adreno GPU、ARM MALI GPU等移动GPU架构;华为昇腾、寒武纪MLU、燧原等专用处理器架构等。考虑到模型和硬件的迅猛发展,这个组合数大概有上千种,这就对大模型推理框架提出了很高的兼容性要求。
面对这样的一个复杂问题,PerfXLM提出了一套解决方案:通过统一的模型表达,实现了对不同大模型的快速支持;通过统一算子API的定义,实现了对大模型图的快速算子构建;通过融合体系结构特征和应用特征的算子库的构建,实现了对不同硬件的快速适配。
同时,为了便于用户使用,PerfXLM上层采用了与vllm一致的顶层API接口。用户只需要在导入python模块时,简单地将vllm修改成perfxlm就能够将原有的代码运行起来并且获得更高的性能表现。具体的使用示例如下图。
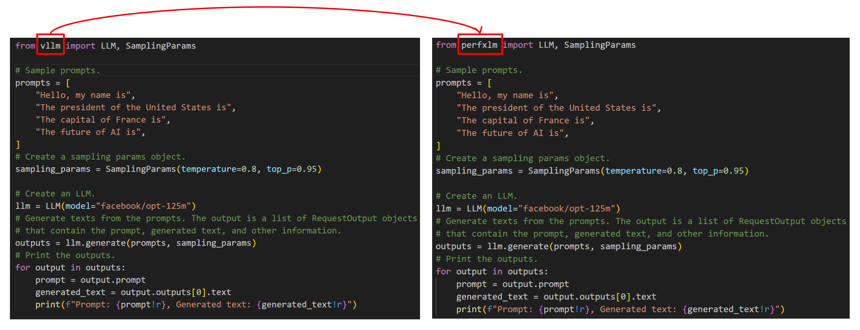
图2. PerfXLM API接口
通过这样的一套架构体系,PerfXLM可以快速地支持新的模型和新的硬件。以近日Meta开源的LLaMA3为例,假设算子完备的情况下,只需几个小时的时间,就能够将该最新模型运行在各种主流硬件设备上。
三、PerfXLM性能
云侧和端侧的应用场景不同:云上侧重于多用户服务,关注的是整体吞吐;端侧侧重于单用户的使用体验,关注的是在低算力硬件上的响应速度和延迟。下面讲描述PerfXLM在单Batch和多Batch下的性能。
1)PerXLM在NVIDIA GPU上的性能
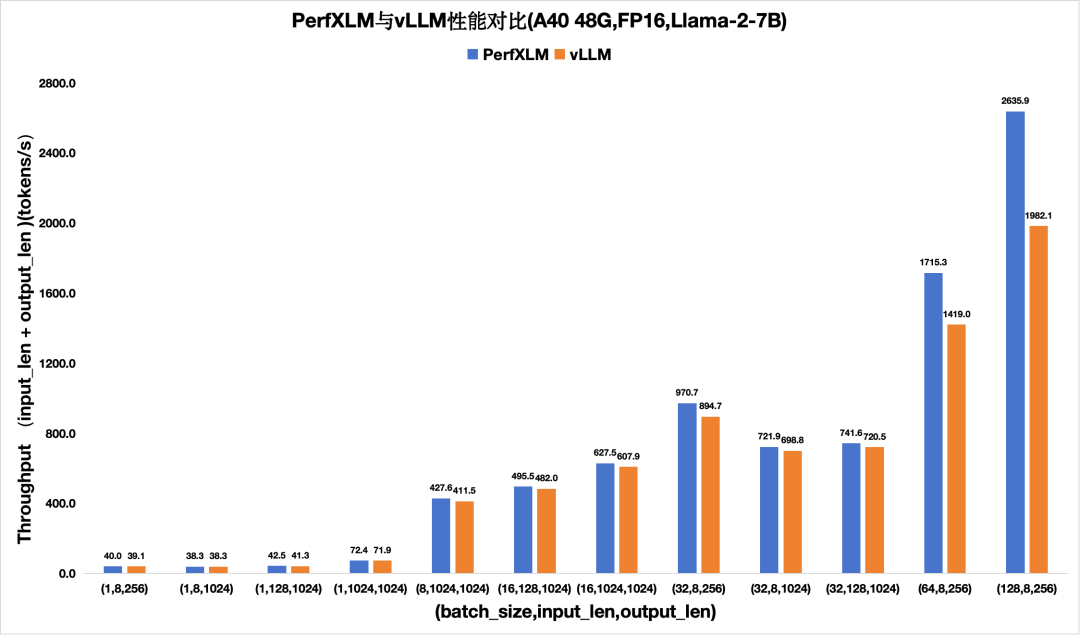
图3. PerfXLM与vllm在A40上FP16的llama2性能对比
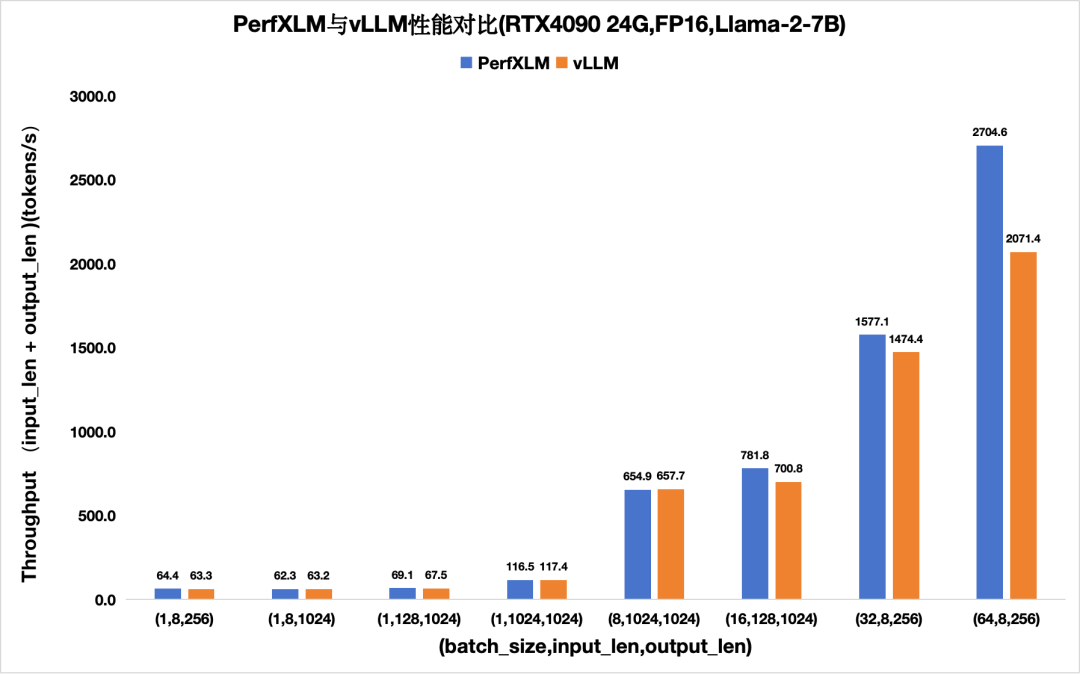
图4. PerfXLM与vllm在4090上FP16的llama2性能对比
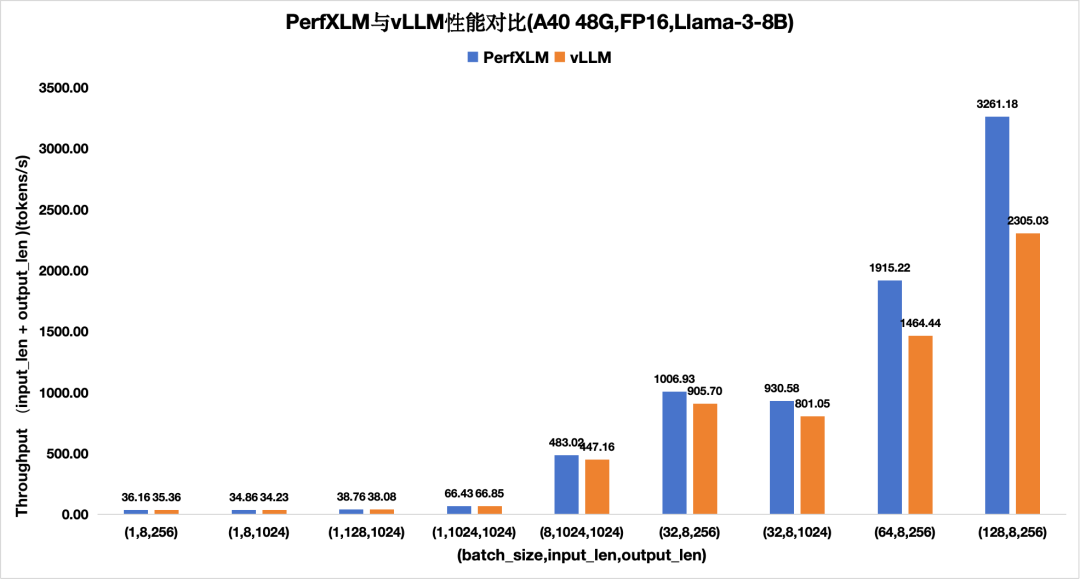
图5.PerfXLM与vllm在A40上FP16的llama3性能对比
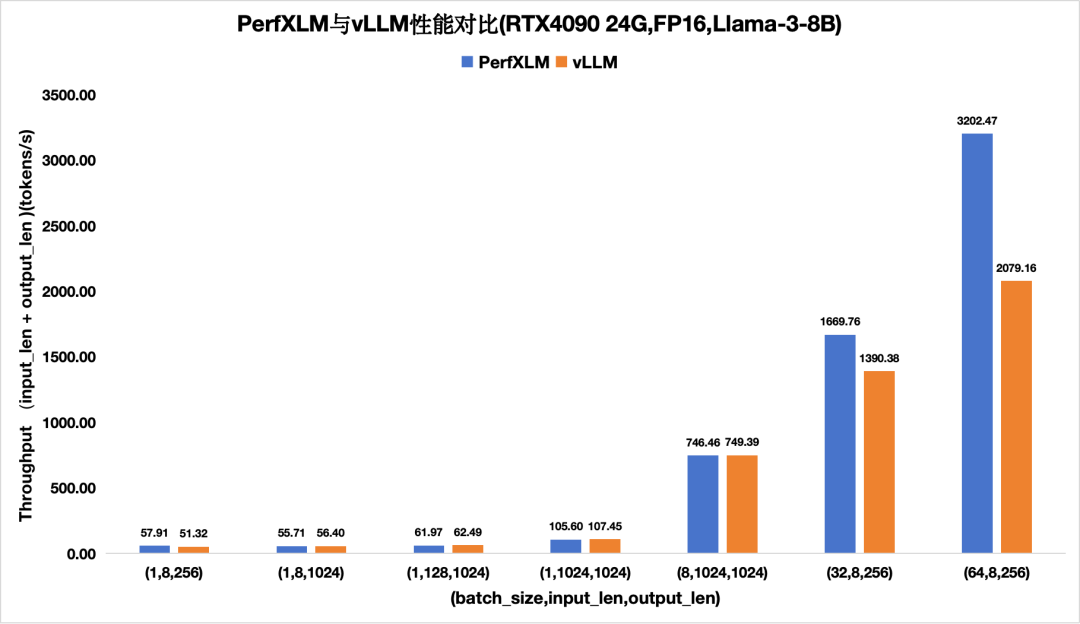
图6.PerfXLM与vllm在4090上FP16的llama3性能对比
2)PerfXLM在海光DCU上的性能
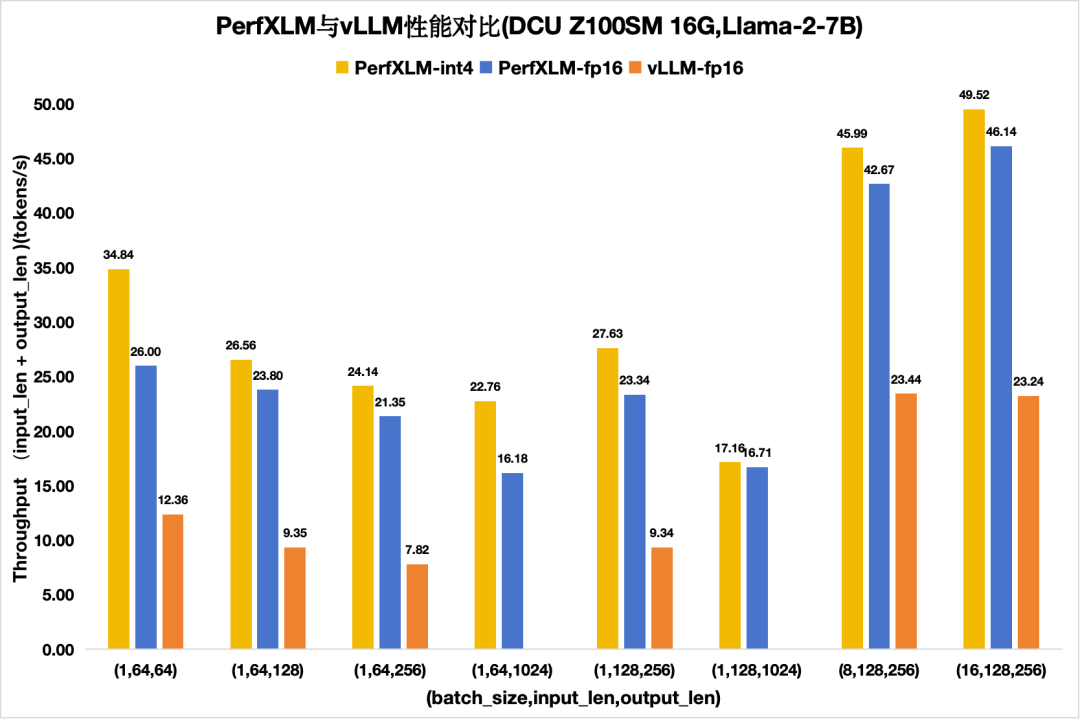
图7 PerfXLM与vllm在DCU Z100SM上的llama2性能对比
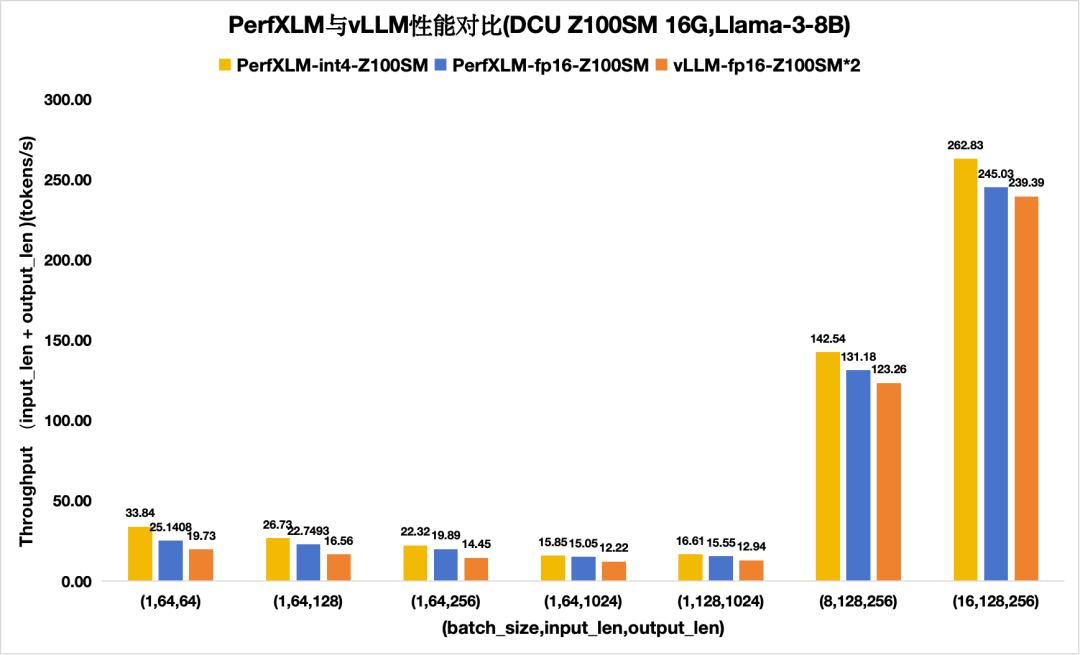
图8 PerfXLM与vllm在DCU Z100SM上的llama3性能对比
3)PerfXLM在国产某GPU上的性能
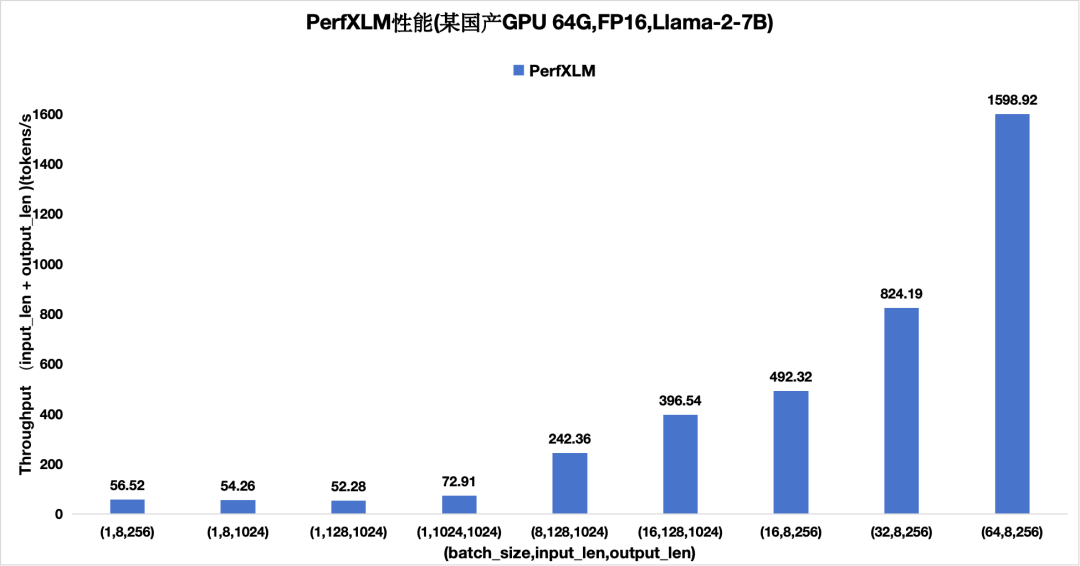
图9 PerfXLM在某国产GPU上的性能
4)PerfXLM在高通Adreno GPU上的性能
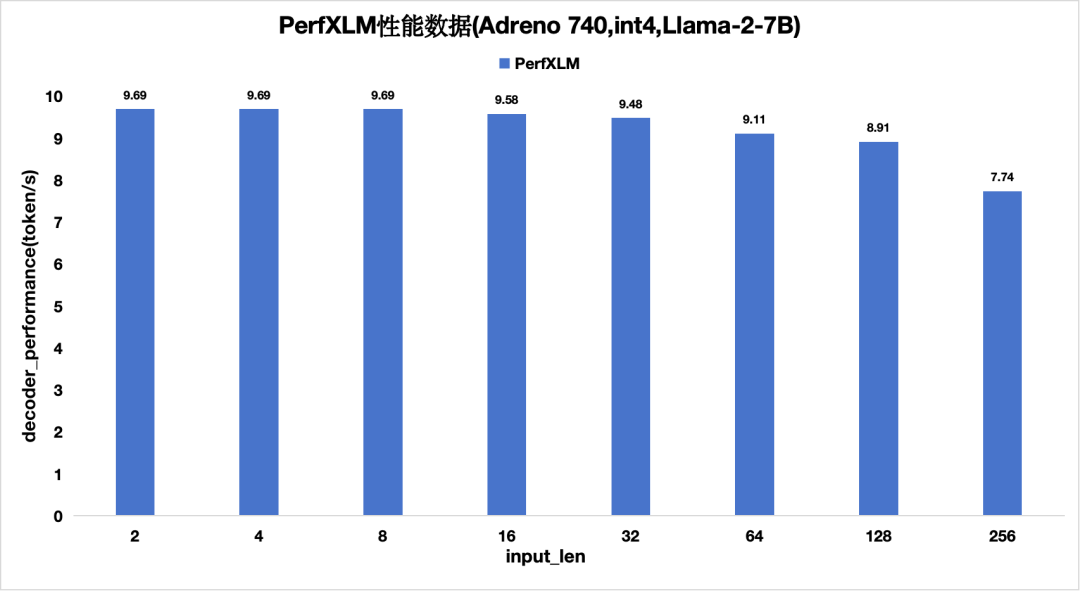
图10 PerfXLM在高通Adreno的性能(单batch)
5)PerfXLM在Intel iGPU上的性能
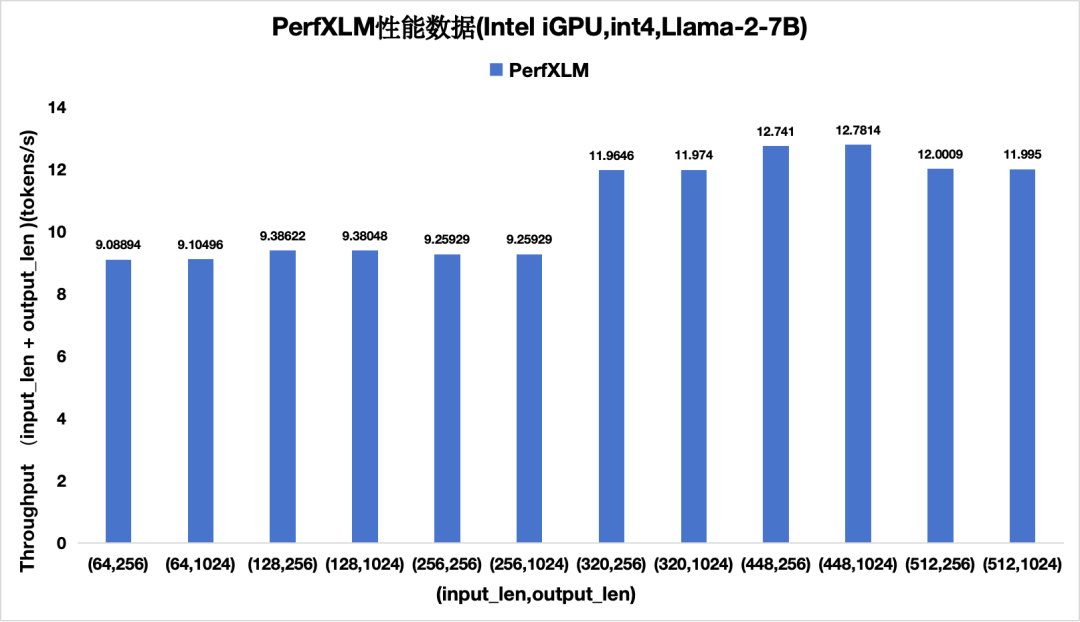
图11 PerfXLM在Intel iGPU上的性能(单batch)
未来,PerfXLM将继续支持"更多的硬件 x更多的模型"。
-
澎峰科技
+关注
关注
0文章
45浏览量
3145 -
大模型
+关注
关注
2文章
2171浏览量
2087
原文标题:爆款·大模型推理引擎PerfXLM发布
文章出处:【微信号:perfxlab,微信公众号:perfxlab】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
赛昉科技与澎峰科技结成合作伙伴关系,共同推动RISC-V应用生态发展
赛昉科技与澎峰科技结成合作伙伴关系,共同推动RISC-V应用生态发展
压缩模型会加速推理吗?
如何提高YOLOv4模型的推理性能?
2023RISC-V中国峰会,澎峰科技成果发布抢先看!
HarmonyOS:使用MindSpore Lite引擎进行模型推理
用于深度学习推理的高性能工具包
在推理引擎中去除TOPS的顶部
澎峰科技发布大模型推理引擎PerfXLLM
澎峰科技再获数千万融资,加速算力时代
澎峰科技与并行科技共拓AI大模型技术创新应用服务

PerfXCloud大模型开发与部署平台开放注册
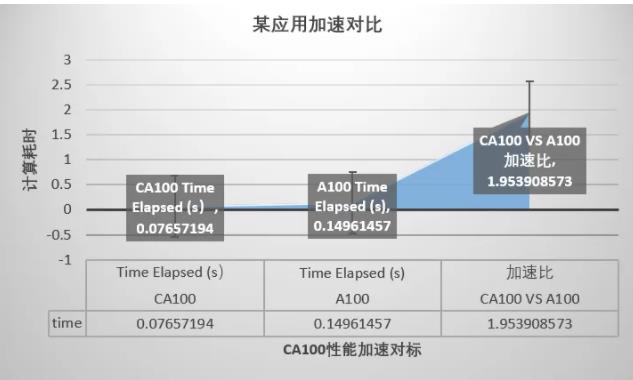
澎峰科技CA100智能计算一体机核心优势解读
澎峰科技受聘为“主权级大模型”创新联合体学术委员会委员
澎峰科技受邀参加全球AI芯片峰会,探讨大模型推理引擎PerfXLM面向RISC-V的移植和优化






 工商网监
工商网监
评论