 一种适用于动态环境的实时视觉SLAM系统
一种适用于动态环境的实时视觉SLAM系统

既能保证效率和精度,又无需GPU,行业第一个达到此目标的视觉动态SLAM系统。
01摘要
在动态环境中实现准确且鲁棒的相机跟踪对于视觉SLAM是一个重大挑战。本文提出了一种新颖的视觉SLAM系统,通过引入掩模预测机制,在CPU上实现了实时性能。该系统还引入了双阶段光流跟踪方法,并采用光流和ORB特征的混合使用,显著提高了效率和鲁棒性。与当前最先进方法相比,在动态环境中保持了高精度定位,并在单台笔记本电脑CPU上以56帧每秒的跟踪速率运行而无需任何硬件加速。这证明即使没有GPU支持,深度学习方法仍然可应用于动态SLAM。根据目前已有信息,这是第一个达到此目标的SLAM系统。
02概述
SLAM研究的一个关键焦点是视觉SLAM,即利用摄像头进行定位和建图。尽管已有许多视觉SLAM算法在各种场景中展示了高精度的跟踪性能,但其中大多数都是在静态环境假设下设计的。因此,在动态环境下,基于这些方法进行摄像头跟踪时通常会遇到漂移问题,从而导致定位精度大大降低。
随着计算机视觉和深度学习的进步,许多SLAM算法将深度学习模型融入其中,根据语义信息在输入图像中识别和过滤潜在的动态物体,这在动态环境中的跟踪精度方面带来了显著提升。然而,采用深度神经网络通常会导致计算要求大幅增加和跟踪时间延长。
这是因为相机跟踪需要等待深度学习模型为每个输入帧提供的动态物体掩模。因此,动态环境中的SLAM越来越注重提高效率。然而,目前实现实时性能的方法要么仅能有限地提高效率,要么在定位精度方面存在妥协,并且仍然依赖于GPU。
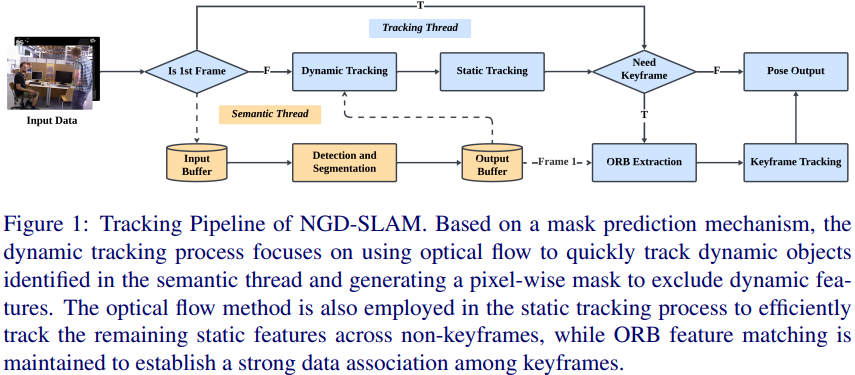
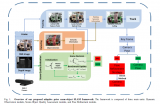
为此,本文提出NGD-SLAM,这是一种无需GPU支持的实时SLAM系统,适用于动态环境。该系统基于ORB-SLAM3框架,并包含一个用于动态对象检测的语义线程(YOLO)。本文的一个核心创新是图1所示的跟踪管道。与其专注于部署更轻量级的深度学习模型或在跟踪过程中更少地使用它们,该方法将提高效率视为利用过去的信息快速生成所需当前结果的任务。具体来说,它引入了一种简单但非常有效且与框架无关的掩模预测机制(如图2所示),该机制利用语义线程的先前分割结果来预测当前帧中动态物体的掩模。该机制可以集成到任何视觉SLAM框架中,从而使相机跟踪和动态物体分割能够并行执行,使得两个过程无需等待对方的输出。为了进一步提高鲁棒性和效率,该系统采用双阶段跟踪,使用光学流方法在图像之间连续跟踪识别出的动态和静态特征,并采用混合策略结合光学流和ORB特征的优点来进行相机跟踪。
通过全面的实验,NGD-SLAM展示了与当前最先进方法相似的定位精度,并在所有基准的实时方法中成为最精确的一个。值得注意的是,它在没有硬件加速的情况下,在单个笔记本电脑CPU上实现了56fps的跟踪帧率。
03相关研究
为了应对动态环境中的挑战,识别来自动态物体的像素或关键点至关重要。例如,早期研究利用视差几何约束和贝叶斯方法来识别移动物体。Klappstein等人利用从光学流中提取的运动度量来检测移动物体。使用这些传统方法可以保留SLAM的实时特性,但它们在不同场景下的适应性有限,导致定位精度降低。
随着深度学习的进步,人们开发出了更多复杂的方法,利用语义信息在输入图像中检测或分割动态实例。在ORB-SLAM2的基础上,DS-SLAM通过将SegNet应用于动态实例分割来提高动态环境中的定位精度,并保持移动一致性检查的同名几何约束。同样地,DynaSLAM采用MaskR-CNN和多视几何来消除动态ORB特征。Detect-SLAM没有使用分割模型,而是利用YOLO模型进行动态对象检测,并通过移动概率传播来移除动态对象。最近,CFP-SLAM提出了一种粗到精的静态概率方法,通过计算和更新静态概率作为姿态优化的权重来提高定位精度。
虽然基于深度学习的方法在准确性方面取得了显著的进步,但由于深度神经网络具有计算密集的特点,它们通常需要强大的GPU才能实现(接近)实时性能。而提高效率的一种策略是为深度学习模型添加一个独立的语义线程。基于这一想法,常见的方法是并行执行特征提取和动态目标识别,但这只能在一定程度上提高效率,因为后续的跟踪过程必须等待深度神经网络的输出。另一方面,一些算法仅将深度学习方法应用于关键帧,这确实大大缩短了平均跟踪时间,但却导致准确性降低。
虽然NGD-SLAM也包括一个独立的深度神经网络语义线程,但它还有一个掩码预测机制,使跟踪线程能够完全独立地运行,无需等待语义线程的结果。此外,与那些使用光学流或场景流来区分动态点和静态点的方法不同,NGD-SLAM仅使用光学流方法跟踪稀疏特征,并将其应用于两个不同的任务,以提高系统的准确性和效率。
04所提方案
4.1跟踪管道
图1展示了NGD-SLAM的跟踪管道。首先,将第一帧的图像数据发送到语义线程,并设置为关键帧。从语义线程提取ORB特征并使用掩模来过滤动态特征;只有第一帧等待获取掩模。系统随后在关键帧跟踪过程中初始化地图。对于后续帧,系统采用双阶段跟踪,其中包括根据预测机制为潜在动态对象生成掩模,并跟踪上一帧中的剩余静态点以估计相机的姿态。然后决定是否设置新的关键帧。如果需要设置新的关键帧,系统从当前帧中提取静态ORB特征,并过滤掉由动态跟踪过程生成的掩模中的特征,然后继续使用ORB特征进行关键帧跟踪过程。
4.2语义线程
NGD-SLAM通过添加一个语义线程来提高实时性能,该线程使用YOLO-fastest模型检测动态物体。该线程与一个输入缓冲区和一个输出缓冲区协同工作,每个缓冲区存储一个帧。新的输入或输出帧将替换缓冲区中现有的帧。从跟踪线程传递到输入缓冲区的帧将由网络进行处理,然后转移到输出缓冲区供跟踪线程访问。这种设置确保语义线程处理最新的输入帧,而跟踪线程无需等待语义线程的结果,而是直接从缓冲区获取最新的输出。虽然两个线程以不同的频率运行,这意味着从输出缓冲区获取的结果对应于前一帧的结果,NGD-SLAM通过使用此过期结果来预测当前帧中动态物体的掩模来补偿这一差异。
4.3掩模预测
NGD-SLAM的一个重要模块是与框架无关的掩模预测机制,它也是动态跟踪的基础组件。与深度神经网络的前向过程相比,该预测速度要快得多,在CPU上处理只需几毫秒。它可以直接应用于任何视觉SLAM框架,并保持其实时性能。图2展示了掩模预测的管道,由六个组件组成。
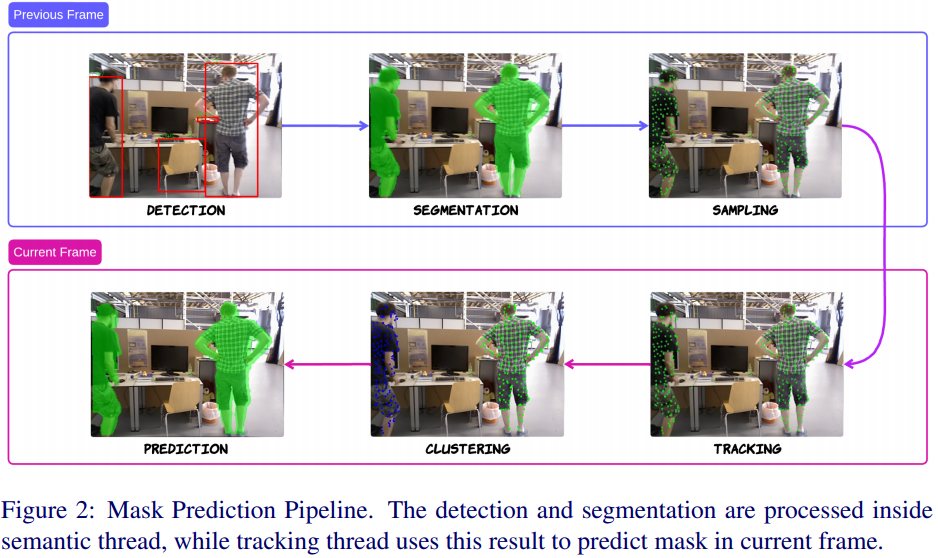
检测:在语义线程中使用的YOLO-最快模型用于在帧中检测多个对象并根据语义信息识别潜在的动态对象。它通过使用OpenCVDNN与C++兼容。NGD-SLAM使用该模型以提高效率,但允许根据需要轻松更换其他模型用于对象检测或分割。
分割:使用目标检测模型比分割网络更高效,但它仅提供检测对象的边界框。为了改进这一点,NGD-SLAM使用深度信息对这些框内的对象进行分割。在识别出动态对象(如人)之后,它会在每个框中对像素深度进行排序,并使用中位数作为该检测对象的估计深度。然后,将框扩大,并将所有接近该深度值的像素屏蔽。这种方法因其计算效率而优于聚类方法。接下来,使用连通组件标签化算法排除那些与主要对象共享相似深度但不属于主要对象的物体掩码,然后在将掩码传递到输出缓冲区之前进行膨胀过程以进一步细化掩码。
采样:在识别出的动态目标的掩模上,从中提取动态点。将图像划分为大小为15×15的单元格。在每个单元格中,识别出满足FAST关键点准则的被掩模像素,并选择阈值最高的像素。如果该单元格中没有合适的FAST关键点,则在该单元格中随机选择一个像素。这种网格结构可以实现动态关键点的均匀提取,并且由于关键点的独特性及其与高梯度区域的关联,可以确保跟踪的稳定性。
跟踪:该系统采用Lucas-Kanade光学流方法来跟踪采样的动态点,该方法假设关键点在不同帧中的灰度值保持不变。从数学上讲,这表示为:
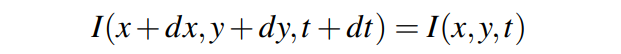
其中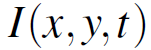 表示坐标为
表示坐标为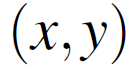 的像素在时间t的灰度强度值。该方程可以通过泰勒级数进一步展开:
的像素在时间t的灰度强度值。该方程可以通过泰勒级数进一步展开:
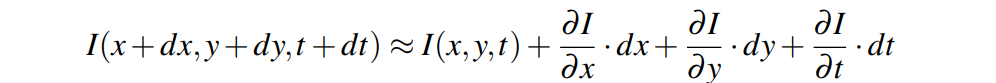
接下来,假设在一个小窗口内像素的移动是均匀的,可以建立一个优化问题,利用窗口内的像素梯度来通过最小化匹配像素的灰度误差来估计像素运动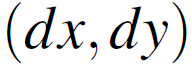 。
。
聚类:对于当前帧中的跟踪动态点,应用DBSCAN(基于密度的空间聚类算法,带有噪声)算法对彼此靠近的点进行聚类,同时区分出明显与任何聚类无关的远距离点作为噪声。采用这种方法可以有效地区分来自不同动态物体的跟踪点。此外,通过考虑每个跟踪点的2D位置和深度,该算法可以有效地排除那些明显偏离聚类或在2D图像中看似接近但深度差异显著的点。
预测:在生成聚类之后,系统会意识到当前帧中动态实体的位置。因此,它会为每个聚类生成一个粗略的掩模,通常是一个矩形,以覆盖该聚类中的所有点。然后,它会利用每个聚类中点的深度信息来细化相应掩模,使其与动态物体的精确形状相匹配。如图2所示,当前帧预测的掩模非常精确。
4.4双阶段追踪

动态跟踪。虽然掩模预测机制本身就具有一定的动态跟踪能力,但由于其依赖于YOLO进行目标检测,有时可能会导致动态目标跟踪失败。例如,当相机旋转时,YOLO可能难以检测到物体。因此,当语义线程无法为跟踪提供掩模时,NGD-SLAM会采用一种简单的解决方案:它使用上一帧预测的掩模来预测当前帧的掩模。这种方法允许动态点连续跟踪,直到动态物体不再出现在摄像头视野内,即使深度神经网络出现问题也能实现。通过不断从上一帧跟踪的掩模中采样新的跟踪点,而不是在多个帧中跟踪相同的点,可以确保关键点保持最新状态,并增强跟踪的鲁棒性(如图3所示)。虽然其他方法涉及从相机姿态旋转部分的四元数表达式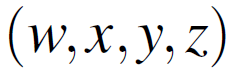 中计算滚动值,但它们通常需要额外的计算资源。
中计算滚动值,但它们通常需要额外的计算资源。
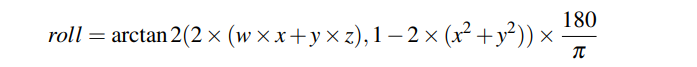
并使用该值来旋转图像进行检测(图4)。动态跟踪的目的是提供在一般情况下的稳健跟踪,因为相机旋转并不是导致检测失败的唯一因素。
静态跟踪。与依赖于ORB特征匹配的原始ORB-SLAM3不同,NGD-SLAM使用与前面描述的相同光学流方法来跟踪上一帧的静态关键点。通过将上一帧的3D地图点与当前帧跟踪的2D关键点链接,形成几何约束,并根据以下运动模型计算当前帧的初始姿态:
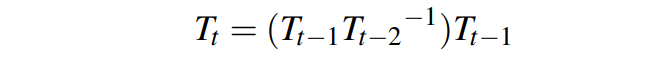
其中,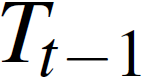 表示上一帧的姿态。基于这些信息,可以使用RANSAC(随机抽样一致性)算法[7]进行迭代估计实际姿态并滤除异常值。
表示上一帧的姿态。基于这些信息,可以使用RANSAC(随机抽样一致性)算法[7]进行迭代估计实际姿态并滤除异常值。

该设计基于以下两个考虑。首先,当动态物体在当前帧中出现但未在用于预测的帧时,通常会出现掩模预测机制的失败。因此,通过提取每个帧的新ORB特征并根据描述符值差异进行匹配,可能会导致动态点之间的匹配或不匹配(如图5所示)。相比之下,静态跟踪过程更稳健,它通过基于图像梯度和滤除噪声的点跟踪来跟踪多个帧中的相同静态点,并在后续跟踪中保留这些点。虽然在关键帧跟踪中也会提取新的ORB特征,但这是在静态点跟踪不足的情况下进行的,这意味着动态物体在多个帧中已经出现了一段时间。其次,静态跟踪过程跳过了非关键帧的耗时的ORB特征提取,使跟踪过程更加高效。
4.5关键帧跟踪
ORB特征被保留用于关键帧之间建立连接。这使得能够维护诸如共视图图和局部地图等ORB-SLAM3关键组件,这些组件对于稳健的跟踪和高效的数据检索至关重要。当静态跟踪表现不佳时,它还可以作为一种备用跟踪方法,因为它对光照变化和运动模糊更加鲁棒。关键帧跟踪是通过使用静态跟踪阶段估计出的姿态将上一关键帧的地图点投影到当前帧中以获取匹配并进行优化来实现的。与原始的ORB-SLAM3类似,会添加新的地图点,并将帧传递给局部映射线程进行进一步优化。
05实验
5.1 实验设置
为了进行对比,选择了当前最先进的SLAM动态环境算法以及其他几种基准方法,包括DynaSLAM、DS-SLAM、CFP-SLAM、RDS-SLAM和TeteSLAM。此外,还对不采用双阶段跟踪(仅保留掩模预测)的NGD-SLAM进行了评估,以进行消融研究。
这些序列展示了各种各样的摄像机运动,包括沿xyz轴的平移、显著的滚转、俯仰变化以及近似于半个球面的轨迹。为了保证准确性,选择了ATE(绝对轨迹误差)和RPE(相对轨迹误差)作为评估指标,RPE测量的间隔为1秒(30帧)。为了提高效率,它以毫秒为单位测量执行给定函数所需的时间。
所有的实验都在一台配备AMD锐龙74800H处理器和NVIDIAGeForce RTX 2060显卡的笔记本电脑上进行。
5.2 实验结果
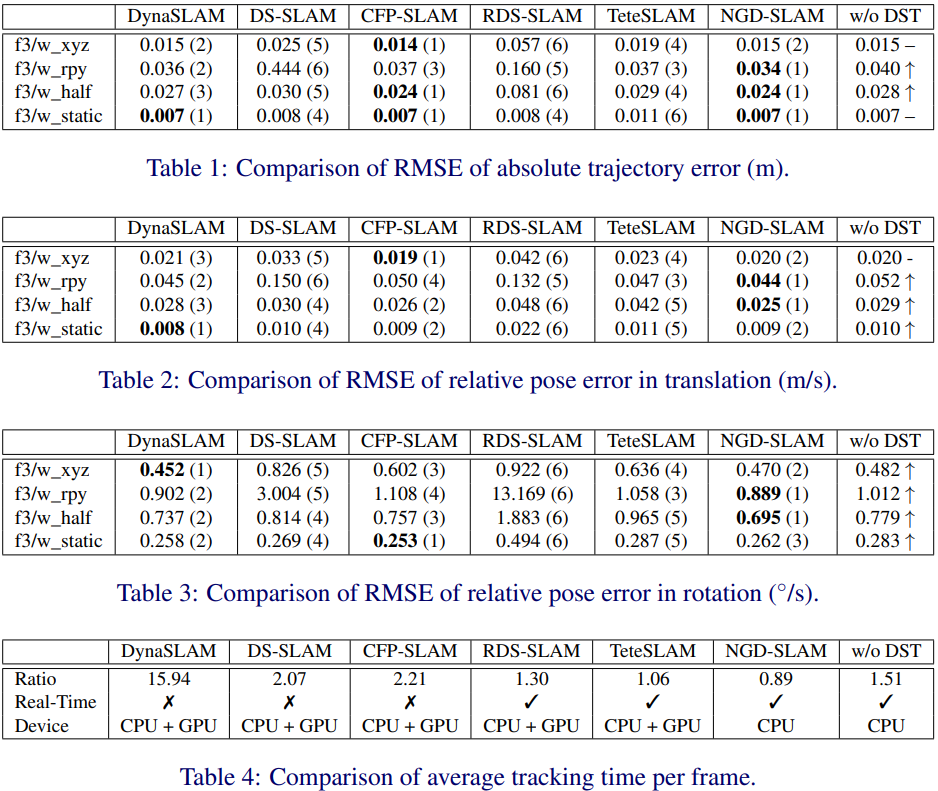
精度。表1展示了NGD-SLAM与各种基线方法在ATERMSE方面的比较。最小误差值用粗体显示,同时附上相应的排名(NGD-SLAM无DST的情况除外,该情况表示与基线实现相比,误差是增加还是减少)。显然,DynaSLAM、CFP-SLAM和NGD-SLAM在所有序列中都表现出很高的精度。然而,DynaSLAM总会给出略高的误差,而CFP-SLAM在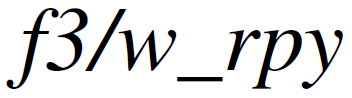 序列中的表现不如人意,因为该方法使用的相位约束在具有旋转的场景中效果不佳。此外,表2和表3显示了RPERMSE的比较,NGD-SLAM仍保持着最先进的结果。
序列中的表现不如人意,因为该方法使用的相位约束在具有旋转的场景中效果不佳。此外,表2和表3显示了RPERMSE的比较,NGD-SLAM仍保持着最先进的结果。
值得注意的是,双阶段跟踪在这里也扮演着至关重要的角色,因为通常情况下,当关闭双阶段跟踪时,系统的ATE和RPE都会增加。这一点在难度较高的序列,如和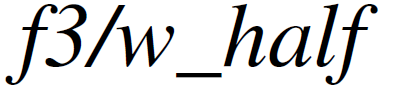 中尤为明显。
中尤为明显。
效率。表4展示了这些动态序列中每帧的平均处理时间的比较。由于一些算法没有开源并且在多种设备上进行测试,因此通过显示算法的每帧平均处理时间与原始ORB-SLAM2/3的每帧平均处理时间的比值(如在原始文献中所报告),可以确保公平的比较。ORB-SLAM2/3的平均跟踪时间约为20毫秒;因此,可以将1.65以内的值视为实时性能。
虽然DynaSLAM和CFP-SLAM的精度很高,但即使在GPU支持下,它们也无法实现实时性能。RDS-SLAM和TeteSLAM可以在实时运行,但它们将深度学习模型仅应用于关键帧,因此牺牲了精度。相比之下,NGD-SLAM和它(不使用DST,仅保留掩模预测)都可以实现实时性能,并且只需要CPU。
实时分析。系统每帧的平均处理时间为17.88毫秒(56fps),这归因于非关键帧中光学流跟踪的高效性。由于NGD-SLAM的所有组件仅在关键帧跟踪中涉及,因此进一步将实验细分,以评估使用静态、动态和关键帧跟踪方法跟踪关键帧所需的平均时间,如表5所示。显然,使用光学流的静态跟踪非常高效,尽管动态跟踪需要稍多的时间,但组合跟踪过程仍能在33.3毫秒(30fps)内完成,这仍然符合实时性能要求。值得注意的是,尽管YOLO检测每帧需要30到40毫秒的时间,但由于跟踪和语义线程以不同的频率并行运行,因此未将其计入该跟踪时间。

06结论
本文介绍了一种适用于动态环境的实时视觉SLAM系统,该系统在CPU上运行,并采用了一种与框架无关的掩模预测机制,以减轻使用深度学习模型带来的低效问题,同时保留其在动态物体识别方面的高准确性。此外,还开发了一种双阶段跟踪方法,以弥补掩模预测机制的局限性,进一步提高系统的效率。在动态环境数据集上的实验评估和与基准方法的比较表明,NGD-SLAM在准确性方面与顶级算法相当,并在不使用任何硬件加速的情况下,在单台笔记本电脑的CPU上实现了实时跟踪。这一进展证明了即使没有GPU支持,深度学习方法一样有在增强动态环境中SLAM系统有效性方面的潜力。
-
cpu
+关注
关注
68文章
11362浏览量
226295 -
算法
+关注
关注
23文章
4816浏览量
98743 -
模型
+关注
关注
1文章
3861浏览量
52322 -
SLAM
+关注
关注
24文章
460浏览量
33441 -
深度学习
+关注
关注
73文章
5613浏览量
124723
原文标题:干货丨无需GPU,面向动态环境的实时视觉SLAM
文章出处:【微信号:gh_c87a2bc99401,微信公众号:INDEMIND】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
一种适用于室内复杂环境的高精度、环境自适应性强的定位算法
一种适用于空间观测任务的实时多目标识别算法分享
一种适用于动态场景的SLAM方法

一种适用于动态场景的多层次地图构建算法
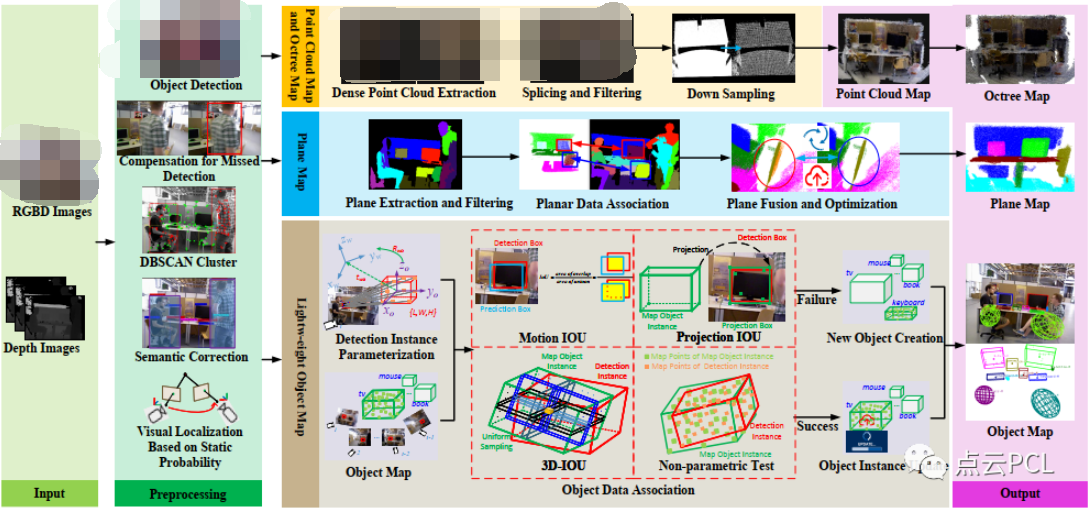
一种基于MASt3R的实时稠密SLAM系统
一种适用于动态环境的3DGS-SLAM系统


一种适用于动态环境的自适应先验场景-对象SLAM框架



评论