 如何运用嵌入式技术实现面部检测应用方案
如何运用嵌入式技术实现面部检测应用方案
嵌入式计算机视觉系统与人类的视觉系统非常相似,对来自范围广泛的各种产品的视频信息进行分析和提取,执行与人类视觉系统相同的视觉功能。
在智能手机、数码相机和便携式摄像机等嵌入式便携产品中,必须在有限的尺寸、成本和功耗条件下提供较高的性能。新兴的大容量嵌入式视觉产品市场包括汽车安全、监控和游戏。计算机视觉算法识别场景中的物体,然后产生一个比其它图像区域更重要的图像区。例如,物体和面部检测可用于增强视频会议体验、公共安全档案管理,以及基于内容的检索和其它许多方面。
可以进行剪裁和尺寸调整,以便适当地将图像放在面部中心。在本文中,我们提出了一种检测数码图像中的面部、剪裁选定的主面部,并将调整尺寸到固定尺寸输出图像的应用(参见图1)。这种应用可在单一图像或在视频流上使用,并且设计用于实时运行。只要人们关注移动产品上的实时面部检测,为了实现实时吞吐量,就必须采取合适的执行步骤。
本文提出了在可编程向量处理器上执行实时面部检测应用的部署步骤,这些步骤可用于在任何移动产品上执行类似的计算机视觉算法,从这一点上说,它们是通用的。
图1:CEVA面部检测应用
虽然静态图像处理消耗少量的带宽和分配内存,但是,视频对于目前的存储器系统的要求却相当严苛。
另一方面,由于检测和区分物体需要更多的处理步骤,计算机视觉算法的存储器系统设计极具挑战性。考虑19x19像素大小的面部图形缩略图。对于这种小图,可能的灰度值组合就有256361种,需要极高的三维空间。由于面部图像的复杂性,明确描述面部特征具有一定的难度;因此,建立了以统计模型为基础的其它方法。这些方法将人脸区域视为一个图形,通过瞄准许多“面部”和“非面部”样品构建区分器,然后通过分析检测区域的图形来确定图像是否包含人脸。
面部检测算法必须克服的其它挑战是:姿态(正面,45度,侧面,倒置)、存在或缺乏结构部分(胡须、眼镜)、面部表情、遮挡(部分面部可能被其它物体遮住)、图像取向(在相机光轴不同的旋转方向,面部外表直接变化)及成像条件(照明、相机特点、分辨率)。
虽然文献中已经介绍了许多面部检测算法,但是,只有少量算法能够满足移动产品的实时限制性。虽然据报道,许多面部检测算法能够产生高的检测率,但是,由于手机等移动产品的计算和存储器限制,很少有算法适合实时部署在这些移动产品上。
通常,面部检测算法的实时执行在具有相对强大的CPU和较大存储器尺寸的PC电脑上进行。针对现有面部检测产品的考察显示,Viola和Jones在2001年推出的算法已经被广泛采纳。这是一项突破性的工作,允许采用基于外表的方法来实时运行,同时保持相同或更高的准确度。
这种算法利用简单特征的增强级联,并且可以分为三个主要部分:(1)积分图 - 用于快速特征评估的高效卷积;(2)使用用于特征选择的Adaboost,并按照重要性顺序对它们进行筛选。每个特征可作为一个简单的(弱)区分器使用;(3)使用Adaboost来了解将最不可能包含面部的区域滤出的级联区分器(弱区分器的集合)。图2是区分器级联的示意图。在图像中,大多数子图像并不是面部实例。
根据这种假设,我们可以利用更小的高效区分器在早期排除许多否定例,同时检测出差不多所有的肯定例。在后期采用更复杂的区分器来审查疑难情况。
例:24级级联区分器
一级2特征区分器=> 排除60%非面部,同时检测100%面部
二级5特征区分器=> 排除80%非面部,同时检测100%面部
3级、4级和5级20特征区分器
6级和7级50特征区分器
8级至12级100特征区分器
13级至24级200特征区分器
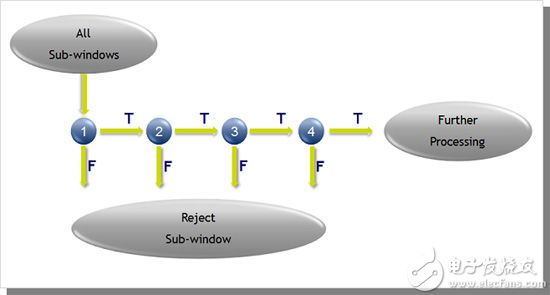
图2:区分器的级联
在面部检测算法的第一级,利用被称为积分图像的中间表示,可以快速计算矩形特征。如图3所示,点(x,y)的积分图像值是上部和左部所有像素的总和。D内像素的总和可以计算为4+1-(2+3)。
图3:采用积分图像对矩形特征进行快速评估
为了在嵌入式产品上执行实时面部检测应用,需要将指令级并行性和和数据级并行性相结合的高级并行性。超长指令字(VLIW)架构能够实现高级并行指令处理,提供扩展的并行性及低功耗。
单指令多数据(SIMD)架构能够在多数据元上运行单指令,从而缩短代码长度并提高性能。使用向量处理器架构,可通过加法器/减法器并行数量因子,加速这些积分和的计算。如果向量寄存器可以加载16像素,而且这些像素可同时加到下一向量,加速因子是16.显然,为处理器增加类似的向量处理单元可以使这一因子翻倍。
在下一面部检测阶段,在多个位置及按多种尺度扫描图像。采用Adaboost强大的区分器(以矩形特征为基础的区分器),以决定搜索窗口是否包含面部。再一次,向量处理器具有明显的优势 - 具有同时将多个位置数据与阈值进行对比的能力。
假设在一个图像中,大多数子图像都不是面部例,可以提供的并行比较器越多,加速越快。
例如,如果架构设计具有在1个循环中比较8个要素中的2个向量的能力,则排除16个位置的子图像仅需1个循环。为了简化数据加载,并且高效率地利用向量处理器加载/储存,各个位置可以在空间上彼此接近。
为了获得高度并行的代码,架构应支持指令预测。这样可以使如果-则-否则(if-then-else)构造导致的分支用顺序码来代替,从而减少循环数和缩短代码长度。允许条件执行,有能力综合各种条件,在控制代码中实现更高的效率。此外,非顺序码,如分支和回路,经设计具有零循环损失,而不需要烦琐的技术,如动态分支预测和增加RISC处理器功率损耗的推理执行。
一个关键的应用挑战是存储器带宽,该应用需要对每帧视频流进行扫描,以执行面部检测。由于其数据量较大,视频流无法储存在紧耦合存储器(TCM)中。例如,一个YUV 4:2:0格式的高清帧占用了3MB数据存储器。这种高存储器带宽导致功率损耗更高,并需要更昂贵的DDR存储器,从而使材料清单成本更高。一个完美的解决方案是采用数据分块(data tiling)来储存像素,其中2维数据块在单次突发中由DDR存取,极大地改善了DDR的效率。直接存储器存取(DMA)可以在外部存储器和核心存储器子系统之间传输数据。在最终面部检测应用阶段,包含检测面部的子图像尺寸重新调整到固定尺寸输出窗口。
当图像在多个比例扫描时,还在检测阶段使用图像尺寸调整过程。尺寸调整算法广泛应用于图像处理,用于视频放大和缩小。面部检测应用中执行的算法是双三次算法。三次卷积插值根据离规定输入坐标最近的16个像素的加权平均值来确定灰度值,并将该值分配给输出坐标。首先,在一个方向(水平方向)上执行四个一维三次卷积,然后,在垂直方向执行更多个一维三次卷积。这意味着要执行一个二维三次卷积,而所需的是一个一维三次卷积。
向量处理器内核具有强大的加载-储存能力,能够快速、有效地存取数据是此类应用的关键特征,其中算法在数据块上运行。可通过在单循环中从存储器访问2维存储器块来满足尺寸调整算法优化。
这一特点使处理器能够有效地实现较高的存储器带宽,不需要载入不必要的数据或执行数据操作的负荷计算单元。此外,能够在数据存取期间转置数据且不存在任何循环损失,这使得转置的数据块能够在单一循环中存取,对于执行水平过滤和垂直过滤非常切实可行。处理器的功率是其执行强大卷积能力的结果,可以在单一循环中执行并行的过滤器。
这里是一个有效解决方案的实例。在一个循环中加载4x8字节块,然后每个迭代利用4个像素,在垂直方向执行三次卷积。这4个像素预先安排在4个独立的向量寄存器中,因此,我们能够同时获得8个结果。然后,同时对这些中间结果进行准确处理,但是,以转置格式加载这些数据,从而完成水平过滤。为了保持结果准确度,需要用结果四舍五入值(rounding value)和后移(post-shift)初始化。过滤器配置应当在不要求专门指令的条件下实现这些特征。
总之,这种并行向量处理解决方案核心可在加载/储存单元操作和处理单元之间实现平衡。一般说来,数据带宽限制及就功耗和晶片面积而言的处理单元的成本限制了执行效率;不过,显然,可以实现标量处理器架构的重要加速。
多媒体器件的多用途可编程HD视频和图像平台
CEVA-MM3000是可以集成到SoC中的可扩展的完全可编程多媒体平台,以全软件形式提供1080p 60fps视频解码和编码、ISP功能和视觉应用。该平台由两个专用处理器,即流处理器和向量处理器组成,集成到一个完整的多核系统中,包括本地存储器和共享存储器、外设、DMA和与外部总线的标准桥接。这款全面的多内核平台专为满足移动产品和其它消费者电子产品的低功耗要求而设计。
向量处理器包括两个独立的向量处理单元(VPU)。VPU负责所有的向量计算,包括向量间运算(利用单指令多数据流)和向量内部运算。向量间指令可在16个8位(字节)或8个16位(字)元上运行,可以使用向量寄存器对,形成32位(双字)元。VPU具有在单循环中完成6个线路(taps)中8个并行滤波器(taps)的能力。
虽然VPU是作为向量处理器的计算主力,但是,向量加载和储存单元(VLSU)作为从数据存储器子系统向向量处理器及从向量处理器向数据存储器子系统传输数据的工具。VLSU具有适用于加载和储存操作的256位带宽,并支持不对齐(non-aligned)存取。VLSU备有在单循环中存取二维数据块的能力,并支持不同的数据块尺寸。
图4:加载4x4像素块
为了简化VPU任务,在读/写向量寄存器时,VLSU可以灵活地操作数据结构。在数据存取期间,数据块可以转置,而不存在任何循环损失,能够在单循环中实现转置数据块的存取。转置功能可以动态设定或清除。采用这种方式,水平过滤器和垂直过滤器可以重复使用相同的功能,从而节省每个过滤器的开发和调试时间,同时缩小程序存储器的占位面积。
结论
对于采用CEVA-MM3000平台的消费产品来说,嵌入式视觉应用是有效地执行算法多样性的一个实例,例如具备裁剪和尺寸调整功能的面部检测。根据预测,将来类似的和更复杂的应用需求将会增长,所有这些应用都可以利用CEVA-MM3000架构的可编程性和可扩展性。
-
智能手机
+关注
关注
66文章
18421浏览量
179750 -
嵌入式
+关注
关注
5062文章
18990浏览量
302414 -
面部检测
+关注
关注
1文章
4浏览量
5858 -
积分图像
+关注
关注
0文章
2浏览量
1307
发布评论请先 登录
相关推荐
嵌入式网络接入怎么实现?
怎样运用Altium Designer平台实现FPGA的嵌入式系统设计?
嵌入式系统的技术特点及广泛运用
玩转S端子 嵌入式方案多种应用运用

基于嵌入式系统对面部检测的设计指南

嵌入式实时面部检测设计方案解析
嵌入式系统死锁检测方法






 工商网监
工商网监
评论