 详解DNN训练中出现的问题与解决方法方法
详解DNN训练中出现的问题与解决方法方法
1、初始化权重由于深度神经网络(DNN)层数很多,每次训练都是逐层由后至前传递。传递项<1,梯度可能变得非常小趋于0,以此来训练网络几乎不会有什么变化,即vanishing gradients problem;或者>1梯度非常大,以此修正网络会不断震荡,无法形成一个收敛网络。因而DNN的训练中可以形成很多tricks。。
起初采用正态分布随机化初始权重,会使得原本单位的variance逐渐变得非常大。例如下图的sigmoid函数,靠近0点的梯度近似线性很敏感,但到了,即很强烈的输入产生木讷的输出。
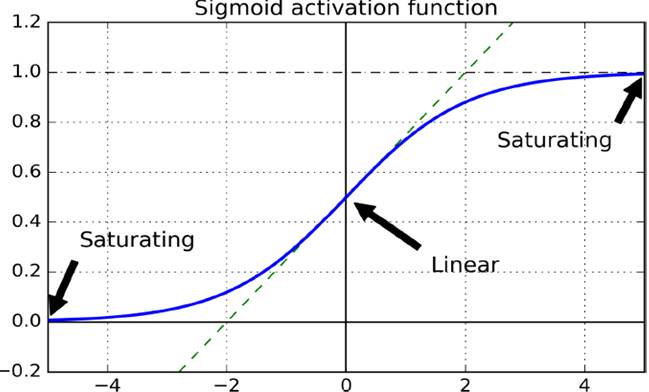
采用Xavier initialization,根据fan-in(输入神经元个数)和fan-out(输出神经元个数)设置权重。
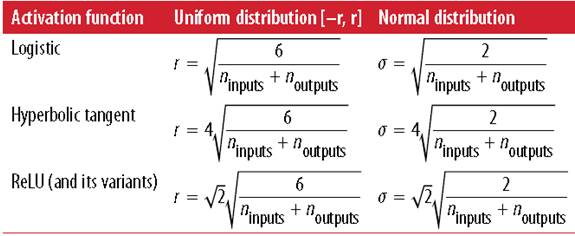
并设计针对不同激活函数的初始化策略,如下图(左边是均态分布,右边正态分布较为常用)
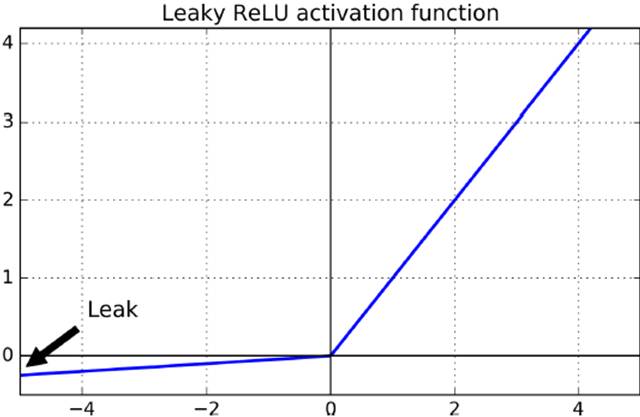
一般使用ReLU,但是不能有小于0的输入(dying ReLUs)
a.Leaky RELU
改进方法Leaky ReLU=max(αx,x),小于0时保留一点微小特征。
具体应用
from tensorflow.examples.tutorials.mnist import input_datamnist = input_data.read_data_sets("/tmp/data/")reset_graph()n_inputs =28*28# MNISTn_hidden1 =300n_hidden2 =100n_outputs =10X=tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")y=tf.placeholder(tf.int64, shape=(None), name="y")withtf.name_scope("dnn"): hidden1 =tf.layers.dense(X, n_hidden1, activation=leaky_relu, name="hidden1") hidden2 =tf.layers.dense(hidden1, n_hidden2, activation=leaky_relu, name="hidden2") logits =tf.layers.dense(hidden2, n_outputs, name="outputs")withtf.name_scope("loss"): xentropy =tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits) loss =tf.reduce_mean(xentropy, name="loss")learning_rate =0.01withtf.name_scope("train"): optimizer =tf.train.GradientDescentOptimizer(learning_rate) training_op = optimizer.minimize(loss)withtf.name_scope("eval"): correct =tf.nn.in_top_k(logits,y,1) accuracy =tf.reduce_mean(tf.cast(correct,tf.float32))init =tf.global_variables_initializer()saver =tf.train.Saver()n_epochs =40batch_size =50withtf.Session()assess: init.run() forepoch inrange(n_epochs): foriteration inrange(mnist.train.num_examples // batch_size): X_batch, y_batch = mnist.train.next_batch(batch_size) sess.run(training_op, feed_dict={X: X_batch,y: y_batch}) ifepoch %5==0: acc_train = accuracy.eval(feed_dict={X: X_batch,y: y_batch}) acc_test = accuracy.eval(feed_dict={X: mnist.validation.images,y: mnist.validation.labels}) print(epoch,"Batch accuracy:", acc_train,"Validation accuracy:", acc_test) save_path = saver.save(sess,"./my_model_final.ckpt")b. ELU改进
另一种改进ELU,在神经元小于0时采用指数变化
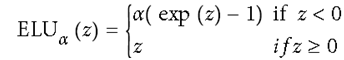
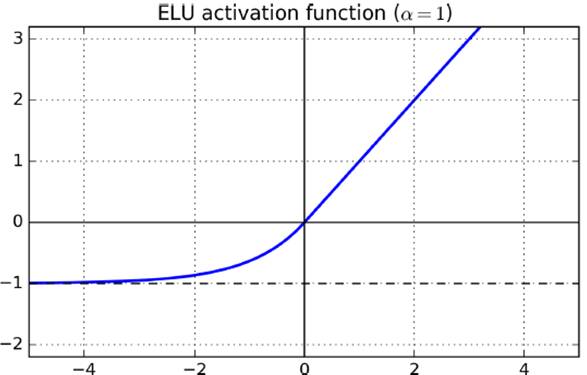
c. SELU
最新提出的是SELU(仅给出关键代码)
withtf.name_scope("dnn"): hidden1 =tf.layers.dense(X, n_hidden1, activation=selu, name="hidden1") hidden2 =tf.layers.dense(hidden1, n_hidden2, activation=selu, name="hidden2") logits =tf.layers.dense(hidden2, n_outputs, name="outputs")# train 过程means = mnist.train.images.mean(axis=0, keepdims=True)stds = mnist.train.images.std(axis=0, keepdims=True) +1e-10withtf.Session()assess: init.run() forepoch inrange(n_epochs): foriteration inrange(mnist.train.num_examples // batch_size): X_batch, y_batch = mnist.train.next_batch(batch_size) X_batch_scaled = (X_batch - means) / stds sess.run(training_op, feed_dict={X: X_batch_scaled,y: y_batch}) ifepoch %5==0: acc_train = accuracy.eval(feed_dict={X: X_batch_scaled,y: y_batch}) X_val_scaled = (mnist.validation.images - means) / stds acc_test = accuracy.eval(feed_dict={X: X_val_scaled,y: mnist.validation.labels}) print(epoch,"Batch accuracy:", acc_train,"Validation accuracy:", acc_test) save_path = saver.save(sess,"./my_model_final_selu.ckpt")3、Batch Normalization在2015年,有研究者提出,既然使用mini-batch进行操作,对每一批数据也可采用,在调用激活函数之前,先做一下normalization,使得输出数据有一个较好的形状,初始时,超参数scaling(γ)和shifting(β)进行适度缩放平移后传递给activation函数。步骤如下:
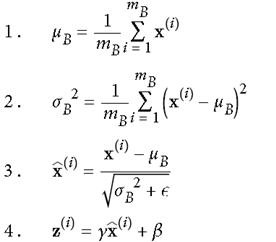
现今batch normalization已经被TensorFlow实现成一个单独的层,直接调用
测试时,由于没有mini-batch,故训练时直接使用训练时的mean和standard deviation(),实现代码如下
import tensorflowastfn_inputs =28*28n_hidden1 =300n_hidden2 =100n_outputs =10batch_norm_momentum =0.9X=tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")y=tf.placeholder(tf.int64, shape=(None), name="y")training =tf.placeholder_with_default(False, shape=(), name='training')withtf.name_scope("dnn"): he_init =tf.contrib.layers.variance_scaling_initializer() #相当于单独一层 my_batch_norm_layer = partial( tf.layers.batch_normalization, training=training, momentum=batch_norm_momentum) my_dense_layer = partial( tf.layers.dense, kernel_initializer=he_init) hidden1 = my_dense_layer(X, n_hidden1, name="hidden1") bn1 =tf.nn.elu(my_batch_norm_layer(hidden1))# 激活函数使用ELU hidden2 = my_dense_layer(bn1, n_hidden2, name="hidden2") bn2 =tf.nn.elu(my_batch_norm_layer(hidden2)) logits_before_bn = my_dense_layer(bn2, n_outputs, name="outputs") logits = my_batch_norm_layer(logits_before_bn)# 输出层也做一个batch normalizationwithtf.name_scope("loss"): xentropy =tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits) loss =tf.reduce_mean(xentropy, name="loss")withtf.name_scope("train"): optimizer =tf.train.GradientDescentOptimizer(learning_rate) training_op = optimizer.minimize(loss)withtf.name_scope("eval"): correct =tf.nn.in_top_k(logits,y,1) accuracy =tf.reduce_mean(tf.cast(correct,tf.float32)) init =tf.global_variables_initializer()saver =tf.train.Saver()n_epochs =20batch_size =200#需要显示调用训练时得出的方差均值,需要额外调用这些算子extra_update_ops =tf.get_collection(tf.GraphKeys.UPDATE_OPS)#在training和testing时不一样withtf.Session()assess: init.run() forepoch inrange(n_epochs): foriteration inrange(mnist.train.num_examples // batch_size): X_batch, y_batch = mnist.train.next_batch(batch_size) sess.run([training_op, extra_update_ops], feed_dict={training:True,X: X_batch,y: y_batch}) accuracy_val = accuracy.eval(feed_dict={X: mnist.test.images, y: mnist.test.labels}) print(epoch,"Test accuracy:", accuracy_val) save_path = saver.save(sess,"./my_model_final.ckpt")4、Gradient Clipp处理gradient之后往后传,一定程度上解决梯度爆炸问题。(但由于有了batch normalization,此方法用的不多)
threshold =1.0optimizer = tf.train.GradientDescentOptimizer(learning_rate)grads_and_vars = optimizer.compute_gradients(loss)capped_gvs = [(tf.clip_by_value(grad, -threshold, threshold),var) forgrad,varingrads_and_vars]training_op = optimizer.apply_gradients(capped_gvs)5、重用之前训练过的层(Reusing Pretrained Layers)
对之前训练的模型稍加修改,节省时间,在深度模型训练(由于有很多层)中经常使用。
一般相似问题,分类数等和问题紧密相关的output层与最后一个直接与output相关的隐层不可以直接用,仍需自己训练。
如下图所示,在已训练出一个复杂net后,迁移到相对简单的net时,hidden1和2固定不动,hidden3稍作变化,hidden4和output自己训练。。这在没有自己GPU情况下是非常节省时间的做法。
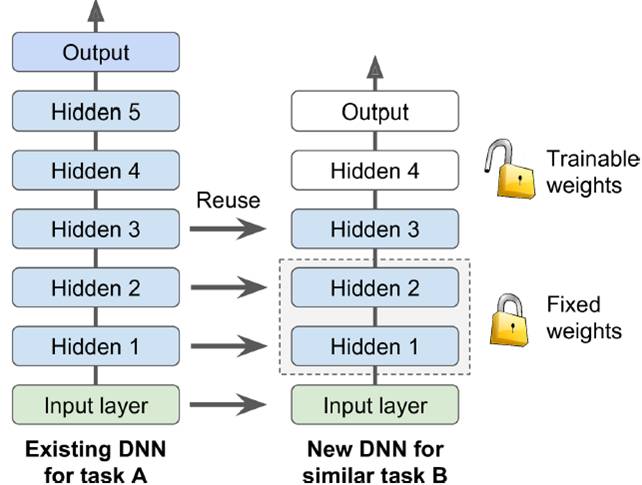
a. Freezing the Lower Layers
训练时固定底层参数,达到Freezing the Lower Layers的目的
# 以MINIST为例n_inputs=28*28# MNISTn_hidden1=300# reusedn_hidden2=50# reusedn_hidden3=50# reusedn_hidden4=20# new!n_outputs=10# new!X= tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")y= tf.placeholder(tf.int64, shape=(None), name="y")withtf.name_scope("dnn"): hidden1 =tf.layers.dense(X, n_hidden1, activation=tf.nn.relu, name="hidden1") # reused frozen hidden2 =tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu, name="hidden2") # reused frozen hidden2_stop =tf.stop_gradient(hidden2) hidden3 =tf.layers.dense(hidden2_stop, n_hidden3, activation=tf.nn.relu, name="hidden3") # reused, not frozen hidden4 =tf.layers.dense(hidden3, n_hidden4, activation=tf.nn.relu, name="hidden4") # new! logits =tf.layers.dense(hidden4, n_outputs, name="outputs") # new!withtf.name_scope("loss"): xentropy =tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits) loss =tf.reduce_mean(xentropy, name="loss")withtf.name_scope("eval"): correct =tf.nn.in_top_k(logits,y,1) accuracy =tf.reduce_mean(tf.cast(correct,tf.float32), name="accuracy")withtf.name_scope("train"): optimizer =tf.train.GradientDescentOptimizer(learning_rate) training_op = optimizer.minimize(loss)reuse_vars =tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope="hidden[123]") # regular expressionreuse_vars_dict = dict([(var.op.name, var)forvar in reuse_vars])restore_saver =tf.train.Saver(reuse_vars_dict) #torestore layers1-3init =tf.global_variables_initializer()saver =tf.train.Saver()withtf.Session()assess: init.run() restore_saver.restore(sess,"./my_model_final.ckpt") forepoch inrange(n_epochs): foriteration inrange(mnist.train.num_examples // batch_size): X_batch, y_batch = mnist.train.next_batch(batch_size) sess.run(training_op, feed_dict={X: X_batch,y: y_batch}) accuracy_val = accuracy.eval(feed_dict={X: mnist.test.images, y: mnist.test.labels}) print(epoch,"Test accuracy:", accuracy_val) save_path = saver.save(sess,"./my_new_model_final.ckpt")b. Catching the Frozen Layers
训练时直接从lock层之后的层开始训练,Catching the Frozen Layers
# 以MINIST为例n_inputs =28*28# MNISTn_hidden1 =300# reusedn_hidden2 =50# reusedn_hidden3 =50# reusedn_hidden4 =20# new!n_outputs =10# new!X=tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")y=tf.placeholder(tf.int64, shape=(None), name="y")withtf.name_scope("dnn"): hidden1 =tf.layers.dense(X, n_hidden1, activation=tf.nn.relu, name="hidden1") # reused frozen hidden2 =tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu, name="hidden2") # reused frozen & cached hidden2_stop =tf.stop_gradient(hidden2) hidden3 =tf.layers.dense(hidden2_stop, n_hidden3, activation=tf.nn.relu, name="hidden3") # reused, not frozen hidden4 =tf.layers.dense(hidden3, n_hidden4, activation=tf.nn.relu, name="hidden4") # new! logits =tf.layers.dense(hidden4, n_outputs, name="outputs") # new!withtf.name_scope("loss"): xentropy =tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits) loss =tf.reduce_mean(xentropy, name="loss")withtf.name_scope("eval"): correct =tf.nn.in_top_k(logits,y,1) accuracy =tf.reduce_mean(tf.cast(correct,tf.float32), name="accuracy")withtf.name_scope("train"): optimizer =tf.train.GradientDescentOptimizer(learning_rate) training_op = optimizer.minimize(loss)reuse_vars =tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope="hidden[123]") # regular expressionreuse_vars_dict = dict([(var.op.name, var)forvar in reuse_vars])restore_saver =tf.train.Saver(reuse_vars_dict) #torestore layers1-3init =tf.global_variables_initializer()saver =tf.train.Saver()importnumpyasnpn_batches = mnist.train.num_examples // batch_sizewithtf.Session()assess: init.run() restore_saver.restore(sess,"./my_model_final.ckpt") h2_cache = sess.run(hidden2, feed_dict={X: mnist.train.images}) h2_cache_test = sess.run(hidden2, feed_dict={X: mnist.test.images})# not shown in the book forepochinrange(n_epochs): shuffled_idx = np.random.permutation(mnist.train.num_examples) hidden2_batches = np.array_split(h2_cache[shuffled_idx], n_batches) y_batches = np.array_split(mnist.train.labels[shuffled_idx], n_batches) forhidden2_batch, y_batchinzip(hidden2_batches, y_batches): sess.run(training_op, feed_dict={hidden2:hidden2_batch, y:y_batch}) accuracy_val = accuracy.eval(feed_dict={hidden2: h2_cache_test,# not shown y: mnist.test.labels}) # not shown print(epoch,"Test accuracy:", accuracy_val) # not shown save_path = saver.save(sess,"./my_new_model_final.ckpt")6、Unsupervised Pretraining该方法的提出,让人们对深度学习网络的训练有了一个新的认识,可以利用不那么昂贵的未标注数据,训练数据时没有标注的数据先做一个Pretraining训练出一个差不多的网络,再使用带label的数据做正式的训练进行反向传递,增进深度模型可用性
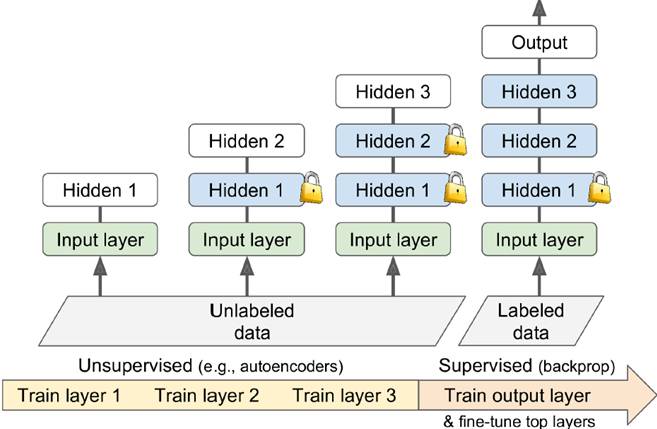
也可以在相似模型中做pretraining
7、Faster Optimizers在传统的SGD上提出改进
有Momentum optimization(最早提出,利用惯性冲量),Nesterov Accelerated Gradient,AdaGrad(adaptive gradient每层下降不一样),RMSProp,Adam optimization(结合adagrad和momentum,用的最多,是缺省的optimizer)
a. momentum optimization
记住之前算出的gradient方向,作为惯性加到当前梯度上。相当于下山时,SGD是静止的之判断当前最陡的是哪里,而momentum相当于在跑的过程中不断修正方向,显然更加有效。
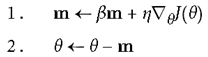
b. Nesterov Accelerated Gradient
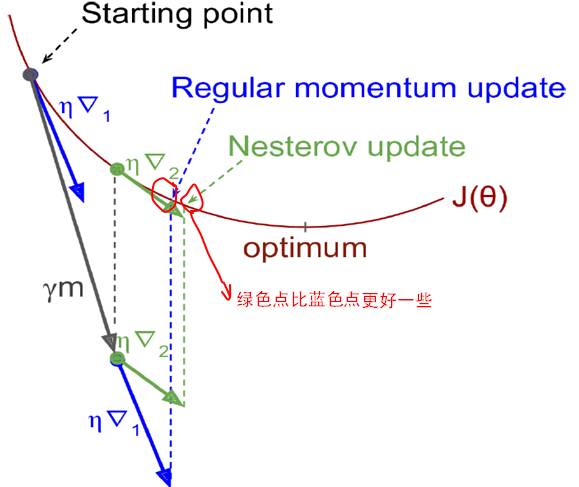
只计算当前这点的梯度,超前一步,再往前跑一点计算会更准一些。
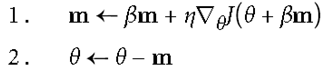
c. AdaGrad
各个维度计算梯度作为分母,加到当前梯度上,不同维度梯度下降不同。如下图所示,横轴比纵轴平缓很多,传统gradient仅仅单纯沿法线方向移动,而AdaGrad平缓的θ1走的慢点,陡的θ2走的快点,效果较好。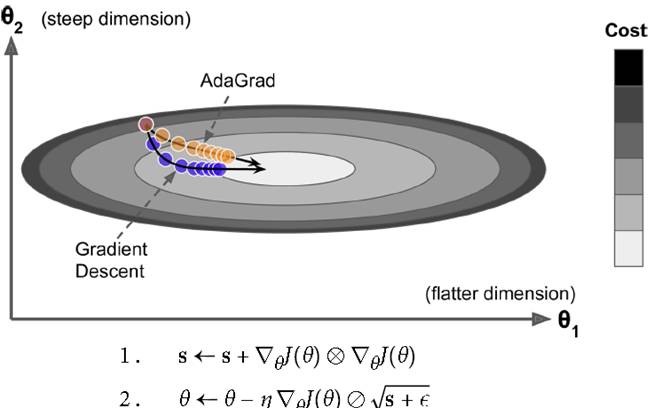
但也有一定缺陷,s不断积累,分母越来越大,可能导致最后走不动。
d. RMSProp(Adadelta)
只加一部分,加一个衰减系数只选取相关的最近几步相关系数
e. Adam Optimization
目前用的最多效果最好的方法,结合AdaGrad和Momentum的优点
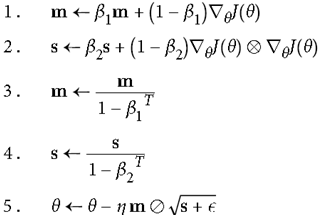
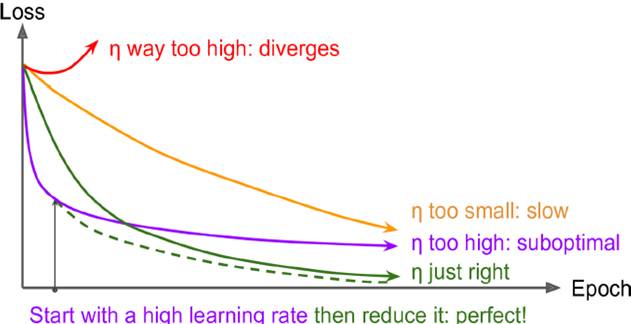
learning rate的设置也很重要,如下图所示,太大不会收敛到全局最优,太小收敛效果最差。最理想情况是都一定情况缩小learning rate,先大后小
a. Exponential Scheduling
指数级下降学习率
initial_learning_rate=0.1decay_steps=10000decay_rate=1/10global_step= tf.Variable(0, trainable=False)learning_rate= tf.train.exponential_decay(initial_learning_rate, global_step, decay_steps, decay_rate)optimizer= tf.train.MomentumOptimizer(learning_rate, momentum=0.9)training_op= optimizer.minimize(loss, global_step=global_step)9、Avoiding Overfitting Through Regularization解决深度模型过拟合问题
a. Early Stopping
训练集上错误率开始上升时停止
b. l1和l2正则化
# construct the neural networkbase_loss =tf.reduce_mean(xentropy, name="avg_xentropy")reg_losses =tf.reduce_sum(tf.abs(weights1)) +tf.reduce_sum(tf.abs(weights2))loss =tf.add(base_loss, scale * reg_losses, name="loss")with arg_scope( [fully_connected], weights_regularizer=tf.contrib.layers.l1_regularizer(scale=0.01)): hidden1 = fully_connected(X, n_hidden1, scope="hidden1") hidden2 = fully_connected(hidden1, n_hidden2, scope="hidden2") logits = fully_connected(hidden2, n_outputs, activation_fn=None,scope="out")reg_losses =tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)loss =tf.add_n([base_loss] + reg_losses, name="loss")c. dropout
一种新的正则化方法,随机生成一个概率,大于某个阈值就扔掉,随机扔掉一些神经元节点,结果表明dropout很能解决过拟合问题。可强迫现有神经元不会集中太多特征,降低网络复杂度,鲁棒性增强。
加入dropout后,training和test的准确率会很接近,一定程度解决overfit问题
training =tf.placeholder_with_default(False, shape=(), name='training')dropout_rate =0.5# ==1- keep_probX_drop =tf.layers.dropout(X, dropout_rate, training=training)withtf.name_scope("dnn"): hidden1 =tf.layers.dense(X_drop, n_hidden1, activation=tf.nn.relu, name="hidden1") hidden1_drop =tf.layers.dropout(hidden1, dropout_rate, training=training) hidden2 =tf.layers.dense(hidden1_drop, n_hidden2, activation=tf.nn.relu, name="hidden2") hidden2_drop =tf.layers.dropout(hidden2, dropout_rate, training=training) logits =tf.layers.dense(hidden2_drop, n_outputs, name="outputs")d. Max-Norm Regularization
可以把超出threshold的权重截取掉,一定程度上让网络更加稳定
defmax_norm_regularizer(threshold, axes=1, name="max_norm", collection="max_norm"): defmax_norm(weights): clipped = tf.clip_by_norm(weights, clip_norm=threshold, axes=axes) clip_weights = tf.assign(weights, clipped, name=name) tf.add_to_collection(collection, clip_weights) returnNone# there is no regularization loss term returnmax_normmax_norm_reg = max_norm_regularizer(threshold=1.0)hidden1 = fully_connected(X, n_hidden1, scope="hidden1", weights_regularizer=max_norm_reg)e. Date Augmentation
深度学习网络是一个数据饥渴模型,需要很多的数据。扩大数据集,例如图片左右镜像翻转,随机截取,倾斜随机角度,变换敏感度,改变色调等方法,扩大数据量,减少overfit可能性
10、default DNN configuration

-
深度神经网络
+关注
关注
0文章
62浏览量
4591
原文标题:【机器学习】DNN训练中的问题与方法
文章出处:【微信号:AI_shequ,微信公众号:人工智能爱好者社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
电子焊接的常见问题及解决方法
gitee 常见问题及解决方法
mac的常见问题解决方法
三坐标测量机常见故障及解决方法


接地网阻值偏大的原因及解决方法
常见的DC电源模块故障及解决方法







 工商网监
工商网监
评论