 自然语言处理技术入门之基于关键词生成文本的技术实现过程
自然语言处理技术入门之基于关键词生成文本的技术实现过程

文章节选自《自然语言处理技术入门与实战》
在自然语言处理中,另外一个重要的应用领域,就是文本的自动撰写。关键词、关键短语、自动摘要提取都属于这个领域中的一种应用。不过这些应用,都是由多到少的生成。这里我们介绍其另外一种应用:由少到多的生成,包括句子的复写,由关键词、主题生成文章或者段落等。
基于关键词的文本自动生成模型
本章第一节就介绍基于关键词生成一段文本的一些处理技术。其主要是应用关键词提取、同义词识别等技术来实现的。下面就对实现过程进行说明和介绍。
场景
在进行搜索引擎广告投放的时候,我们需要给广告撰写一句话描述。一般情况下模型的输入就是一些关键词。比如我们要投放的广告为鲜花广告,假设广告的关键词为:“鲜花”、“便宜”。对于这个输入我们希望产生一定数量的候选一句话广告描述。
对于这种场景,也可能输入的是一句话,比如之前人工撰写了一个例子:“这个周末,小白鲜花只要99元,并且还包邮哦,还包邮哦!”。需要根据这句话复写出一定数量在表达上不同,但是意思相近的语句。这里我们就介绍一种基于关键词的文本(一句话)自动生成模型。
原理
模型处理流程如图1所示。

图1
首先根据输入的数据类型不同,进行不同的处理。如果输入的是关键词,则在语料库中选择和输入关键词相同的语句。如果输入的是一个句子,那么就在语料库中选择和输入语句相似度大于指定阈值的句子。
对于语料库的中句子的关键词提取的算法,则使用之前章节介绍的方法进行。对于具体的算法选择可以根据自己的语料库的形式自由选择。
图2
语句相似度计算,这里按照图2左边虚线框中的流程进行计算:
首先对待计算的两个语句进行分词处理,对于分词后的语句判断其是否满足模板变换,如果满足则直接将语句放入候选集,并且设置相似度为0。如果不满足则进入到c)步进行计算。
判断两个语句是否满足模板变换的流程图,如图2中右边虚线框所标记的流程所示:(1)首先判断分词后,两个句子的词是不是完全一样,而只是位置不同,如果是则满足模板变换的条件。(2)如果词不完全相同,就看看对不同的词之间是否可以进行同义词变换,如果能够进行同义词变换,并且变换后的语句两个句子去公共词的集合,该集合若为某一句话的全部词集合,则也满足模板变换条件。(3)如果上述两个步骤都不满足,则两个句子之间不满足模板变换。
对两个句子剩余的词分别两两计算其词距离。假如两个句子分别剩余的词为,句1:“鲜花”、“多少钱”、“包邮”。句2:“鲜花”、“便宜”、“免运费”。那么其距离矩阵如下表所示:
得到相似矩阵以后,就把两个句子中相似的词替换为一个,假设我们这里用“包邮”替换掉“免运费”。那么两个句子的词向量就变为:句1:<鲜花、多少钱、包邮>,句2:<鲜花、便宜、包邮>。
对于两个句子分别构建bi-gram统计向量,则有:(1)句1:< begin,鲜花>、<鲜花,多少钱>、<多少钱,包邮>、<包邮,end>。(2)句2:< begin,鲜花>、<鲜花,便宜>、<便宜,包邮>、<包邮,end>。
这两个句子的相似度由如下公式计算:

所以上面的例子的相似度为:1.0-2.0*2/8=0.5。
完成候选语句的提取之后,就要根据候选语句的数量来判断后续操作了。如果筛选的候选语句大于等于要求的数量,则按照句子相似度由低到高选取指定数量的句子。否则要进行句子的复写。这里采用同义词替换和根据指定模板进行改写的方案。
实现
实现候选语句计算的代码如下:
Map
if (type == 0) {//输入为关键词
result = getKeyWordsSentence(keyWordsList);
}else {
result = getWordSimSentence(sentence);
}
//得到候选集数量大于等于要求的数量则对结果进行裁剪
if (result.size() >= number) {
result = sub(result, number);
}else {
//得到候选集数量小于要求的数量则对结果进行添加
result = add(result, number);
}
首先根据输入的内容形式选择不同的生成模式进行语句生成。这一步的关键在于对语料库的处理,对于相似关键词和相似语句的筛选。对于关键词的筛选,我们采用布隆算法进行,当然也可以采用索引查找的方式进行。对于候选语句,我们首先用关键词对于语料库进行一个初步的筛选。确定可能性比较大的语句作为后续计算的语句。
对于得到的候选结果,我们都以map的形式保存,其中key为后续语句,value为其与目标的相似度。之后按照相似度从低到高进行筛选。至于map的排序我们在之前的章节已经介绍了,这里就不再重复了。
实现语句相似筛选计算的代码如下。
for (String sen : sentenceList) {
//对待识别语句进行分词处理
List
List
//首先判断两个语句是不是满足目标变换
boolean isPatternSim = isPatternSimSentence(wordsList1, wordsList2);
if (!isPatternSim) {//不满足目标变换
//首先计算两个语句的bi-gram相似度
double tmp = getBigramSim(wordsList1, wordsList2);
//这里的筛选条件是相似度小于阈值,因为bi-gram的相似度越小,代表两者越相似
if (threshold > tmp) {
result.put(sen,tmp);
}
}else {
result.put(sen,0.0);
}
}
首先对待识别的两个语句进行分词,并对分词后的结果进行模板转换的识别,如果满足模板转换的条件,则将语句作为候选语句,并且赋值一个最小的概率。如果不满足则计算两者的bi-gram的相似度。再根据阈值进行筛选。
这里使用的bi-gram是有改进的,而常规的bi-gram是不需要做比例计算的。这里进行这个计算是为了避免不同长度的字符的影响。对于相似度的度量也可以根据自己的实际情况选择合适的度量方式进行。
拓展
本节处理的场景是:由文本到文本的生成。这个场景一般主要涉及:文本摘要、句子压缩、文本复写、句子融合等文本处理技术。其中本节涉及文本摘要和句子复写两个方面的技术。文本摘要如前所述主要涉及:关键词提取、短语提取、句子提取等。句子复写则根据实现手段的不同,大致可以分为如下几种。
基于同义词的改写方法。这也是本节使用的方式,这种方法是词汇级别的,能够在很大程度上保证替换后的文本与原文语义一致。缺点就是会造成句子的通顺度有所降低,当然可以结合隐马尔科夫模型对于句子搭配进行校正提升整体效果。
基于模板的改写方法。这也是本节使用的方式。该方法的基本思想是,从大量收集的语料中统计归纳出固定的模板,系统根据输入句子与模板的匹配情况,决定如何生成不同的表达形式。假设存在如下的模板。
rzv n, a a ——> a a, rzv n
那么对于(输入):这/rzv, 鲜花/n, 真/a, 便宜/a就可以转换为(输出):真/a, 便宜/a, 这/rzv, 鲜花/n该方法的特点是易于实现,而且处理速度快,但问题是模板的通用性难以把握,如果模板设计得过于死板,则难以处理复杂的句子结构,而且,能够处理的语言现象将受到一定的约束。如果模板设计得过于灵活,往往产生错误的匹配。
基于统计模型和语义分析生成模型的改写方法。这类方法就是根据语料库中的数据进行统计,获得大量的转换概率分布,然后对于输入的语料根据已知的先验知识进行替换。这类方法的句子是在分析结果的基础上进行生成的,从某种意义上说,生成是在分析的指导下实现的,因此,改写生成的句子有可能具有良好的句子结构。但是其所依赖的语料库是非常大的,这样就需要人工标注很多数据。对于这些问题,新的深度学习技术可以解决部分的问题。同时结合知识图谱的深度学习,能够更好地利用人的知识,最大限度地减少对训练样本的数据需求。
RNN模型实现文本自动生成
6.1.2节介绍了基于短文本输入获得长文本的一些处理技术。这里主要使用的是RNN网络,利用其对序列数据处理能力,来实现文本序列数据的自动填充。下面就对其实现细节做一个说明和介绍。
场景
在广告投放的过程中,我们可能会遇到这种场景:由一句话生成一段描述文本,文本长度在200~300字之间。输入也可能是一些主题的关键词。
这个时候我们就需要一种根据少量文本输入产生大量文本的算法了。这里介绍一种算法:RNN算法。在5.3节我们已经介绍了这个算法,用该算法实现由拼音到汉字的转换。其实这两个场景的模式是一样的,都是由给定的文本信息,生成另外一些文本信息。区别是前者是生成当前元素对应的汉字,而这里是生成当前元素对应的下一个汉字。
原理
同5.3节一样,我们这里使用的还是Simple RNN模型。所以整个计算流程图如图3所示。
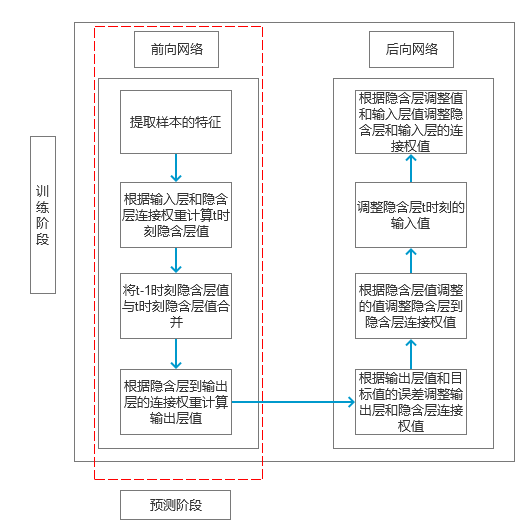
图3
在特征选择的过程中,我们需要更多地考虑上下两段之间的衔接关系、一段文字的长度、段落中感情变化、措辞变换等描述符提取。这样能更好地实现文章自然的转承启合。
在生成的文章中,对于形容词、副词的使用可以给予更高的比重,因为形容词、副词一般不会影响文章的结构,以及意思的表达,但同时又能增加文章的吸引力。比如最好的,最漂亮的,最便宜的等,基本都是百搭的词,对于不同的名词或者动名词都可以进行组合,同时读者看到以后,一般都有欲望去深度了解。
对于和主题相关的词,可以在多处使用,如果能替换为和主题相关的词都尽量替换为和主题相关的词。因为这个不仅能提升文章的连贯性,还能增加主题的曝光率。
上面这些是对于广告场景提出的一些经验之谈,其他场景的模式或许不太适用,不过可以根据自己的场景确定具体的优化策略。
具体的计算流程和5.3节基本一致,在这里就不再赘述了。
代码
实现特征训练计算的代码如下:
public double train(List
alreadyTrain = true;
double minError = Double.MAX_VALUE;
for (int i = 0; i < totalTrain; i++) {
//定义更新数组
double[][] weightLayer0_update = new double[weightLayer0.length][weightLayer0[0].length];
double[][] weightLayer1_update = new double[weightLayer1.length][weightLayer1[0].length];
double[][] weightLayerh_update = new double[weightLayerh.length][weightLayerh[0].length];
List
List
double[] hiddenLayerInitial = new double[hiddenLayers];
//对于初始的隐含层变量赋值为0
Arrays.fill(hiddenLayerInitial, 0.0);
hiddenLayerInput.add(hiddenLayerInitial);
double overallError = 0.0;
//前向网络计算预测误差
overallError = propagateNetWork(x, y, hiddenLayerInput,
outputLayerDelta, overallError);
if (overallError < minError) {
minError = overallError;
}else {
continue;
}
first2HiddenLayer = Arrays.copyOf(hiddenLayerInput.get(hiddenLayerInput.size()-1), hiddenLayerInput.get(hiddenLayerInput.size()-1).length);
double[] hidden2InputDelta = new double[weightLayerh_update.length];
//后向网络调整权值矩阵
hidden2InputDelta = backwardNetWork(x, hiddenLayerInput,
outputLayerDelta, hidden2InputDelta,weightLayer0_update, weightLayer1_update, weightLayerh_update);
weightLayer0 = matrixAdd(weightLayer0, matrixPlus(weightLayer0_update, alpha));
weightLayer1 = matrixAdd(weightLayer1, matrixPlus(weightLayer1_update, alpha));
weightLayerh = matrixAdd(weightLayerh, matrixPlus(weightLayerh_update, alpha));
}
return -1.0;
}
首先对待调整的变量进行初始化,在完成这一步之后,就开始运用前向网络对输入值进行预测,完成预测之后,则运用后向网络根据预测误差对各个权值向量进行调整。
这个过程需要注意的是,每次权值的更新不是全量更新,而是根据学习速率alpha来进行更新的。其他的步骤基本和之前描述的一样。
实现预测计算的代码如图下:
public double[] predict(double[] x) {
if (!alreadyTrain) {
new IllegalAccessError("model has not been trained, so can not to be predicted!!!");
}
double[] x2FirstLayer = matrixDot(x, weightLayer0);
double[] firstLayer2Hidden = matrixDot(first2HiddenLayer, weightLayerh);
if (x2FirstLayer.length != firstLayer2Hidden.length) {
new IllegalArgumentException("the x2FirstLayer length is not equal with firstLayer2Hidden length!");
}
for (int i = 0; i < x2FirstLayer.length; i++) {
firstLayer2Hidden[i] += x2FirstLayer[i];
}
firstLayer2Hidden = sigmoid(firstLayer2Hidden);
double[] hiddenLayer2Out = matrixDot(firstLayer2Hidden, weightLayer1);
hiddenLayer2Out = sigmoid(hiddenLayer2Out);
return hiddenLayer2Out;
}
在预测之前首先要确定模型是不是已经训练完成,如果没有训练完成,则要先进行训练得到预测模型。当然这是一个跟具体业务逻辑有关的校验,这主要是针对预测和训练分开的情况,如果训练和预测是在一个流程内的,则也可以不用校验。
在得到训练模型之后,就根据前向网络的流程逐步计算,最终得到预测值。因为我们这里是一个分类问题,所以最终是选择具有最大概率的字作为最终的输出。
拓展
文本的生成,按照输入方式不同,可以分为如下几种:
文本到文本的生成。即输入的是文本,输出的也是文本。
图像到文本。即输入的是图像,输出的是文本。
数据到文本。即输入的是数据,输出的是文本。
其他。即输入的形式为非上面三者,但是输出的也是文本。因为这类的输入比较难归纳,所以就归为其他了。
其中第2、第3种最近发展得非常快,特别是随着深度学习、知识图谱等前沿技术的发展。基于图像生成文本描述的试验成果在不断被刷新。基于GAN(对抗神经网络)的图像文本生成技术已经实现了非常大的图谱,不仅能够根据图片生成非常好的描述,还能根据文本输入生成对应的图片。
由数据生成文本,目前主要应用在新闻撰写领域。中文和英文的都有很大的进展,英文的以美联社为代表,中文的则以腾讯公司为代表。当然这两家都不是纯粹地以数据为输入,而是综合了上面4种情况的新闻撰写。
从技术上来说,现在主流的实现方式有两种:一种是基于符号的,以知识图谱为代表,这类方法更多地使用人的先验知识,对于文本的处理更多地包含语义的成分。另一种是基于统计(联结)的,即根据大量文本学习出不同文本之间的组合规律,进而根据输入推测出可能的组合方式作为输出。随着深度学习和知识图谱的结合,这两者有明显的融合现象,这应该是实现未来技术突破的一个重要节点。
-
自然语言
+关注
关注
1文章
293浏览量
14036
原文标题:如何使用 RNN 模型实现文本自动生成 | 赠书
文章出处:【微信号:AI_Thinker,微信公众号:人工智能头条】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录



评论