 著名的 Box86/Box64 模拟器现在有了更好的 RISC-V RVV 1.0 支持,性能提升显著
著名的 Box86/Box64 模拟器现在有了更好的 RISC-V RVV 1.0 支持,性能提升显著
部分机器翻译。转载自:https://box86.org/2024/10/optimizing-the-risc-v-backend/
大家好!一个半月前,我们撰写了关于 RISC-V DynaRec(动态重编译器,即 Box64 的 JIT 后端)的最新状态的文章,并分享了在 RISC-V 上运行《巫师 3》的令人欣慰的进展。如果您还没有看过那篇文章,千万不要错过!无论如何,上个月,我们并没有只是坐在那里无所事事,而是专注于性能改进,现在我们有一些东西可以分享了。
Are We SIMD Yet?
多年来,x86 指令集慢慢扩展了大量 SIMD 指令,分散在多个 SIMD 扩展中,从最初的 MMX 到 SSE、SSE2、SSE3、SSSE3、SSE4,再到 AVX、AVX-2、AVX-512 以及即将推出的 AVX10。您可能已经猜到,这些指令一定有广泛的应用,值得对编码空间产生如此大的影响。
事实上,由于现代编译器的存在,如今几乎所有 x86 程序或多或少都会使用 SIMD 指令。特别是,一些性能敏感且并行友好的程序将在热代码路径中使用手写 SIMD 内核,以大幅提高性能。因此,box64 需要有效地翻译这些指令。
幸运的是,x86 并不是唯一一个拥有 SIMD 或矢量扩展的指令集。它是如此重要,以至于几乎所有的指令集都有它。例如,AArch64 有 Neon、SVE和 SVE2,LoongArch 有 LSX 和 LASX,RISC-V 有 Vector 扩展(或 RVV)。本质上,这些扩展的目标是相同的,即加速并行友好代码的执行。因此,即使它们有这样或那样的差异,它们通常是相似的,许多基本指令是完全相同的,因此可以通过 box64 等模拟器一对一地翻译。
那么 box64 对这些 x86 SIMD 指令的支持程度如何?嗯,这是一个复杂的问题。例如,目前最完整的 AArch64 DynaRec 支持从 MMX 到 AVX-2 的几乎所有指令。简单来说,这些指令将被翻译成一个或多个 Neon 指令来完成等效的工作。同时,最不完整的LoongArch64 DynaRec目前仅支持一小部分MMX和SSE*指令,未实现的操作码将回退到解释器,速度非常慢。
So, what about our beloved RISC-V? Are we SIMD yet?
嗯,一个半月前,答案是否定的。RISC-V DynaRec 确实实现了从 MMX 到SSE4的大多数指令,但这些指令是用标量指令模拟的。
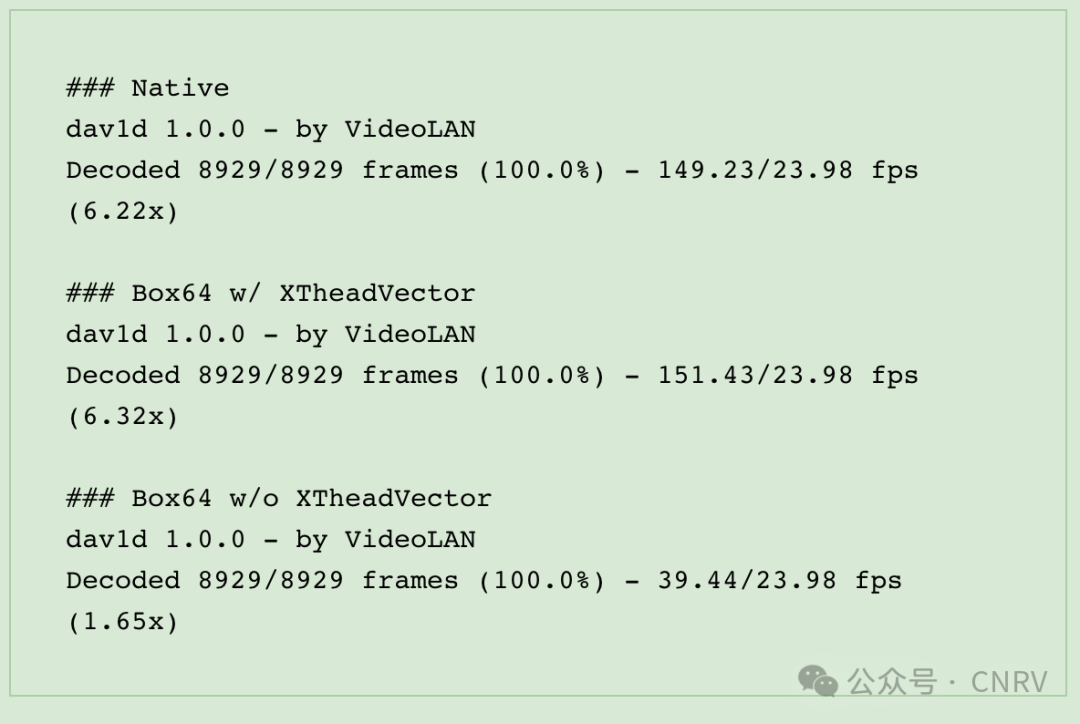
For example, for the SSE2paddqopcode, what this instruction does is:
 So how is it emulated on RISC-V? Let’s take a look at it via the dump functionality of Box64:
So how is it emulated on RISC-V? Let’s take a look at it via the dump functionality of Box64:

You can see that the translation is implemented by twoLOAD LOAD ADD STOREsequences, totaling 8 instructions. This is probably the easiest opcode to simulate so it will be even worse for other more complex opcodes.
So how is this implemented on AArch64?

Ah ha, this opcode is translated one-to-one to theVADDinstruction! No surprises at all.
可以想象,在 RISC-V 上,这种方法确实会比简单地回退到解释器有更好的性能,但与手头有 Neon 指令的 AArch64 相比,它就差远了。
RISC-V 指令集以多样性而闻名(如果你讨厌 RISC-V,你也可以说是碎片化)。这意味着除了基本指令集之外,供应商还有充分的自由来实现或不实现官方扩展,以及添加或不添加自定义扩展。
你看,在 AArch64 中,Neon 扩展是强制性的,因此 box64 可以随意使用它,无需担心它的存在。但RVV却大不相同。例如,JH7110(VisionFive 2、MilkV Mars 等)没有任何矢量扩展,而 SpacemiT K1/M1(Banana Pi F3、MilkV Jupiter 等)支持矢量寄存器宽度为 256 位的 RVV 1.0,SG2042(MilkV Pioneer)支持旧 RVV 版本 0.7.1(或 XTheadVector),寄存器宽度为 128 位。
In fact, the one on SG2042 is not strictly 0.7.1, but based on 0.7.1, that why it is called XTheadVector. Although it has some differences with RVV 1.0, such as the encoding of instructions, the behavior of some instructions, and the lack of a small number of instructions, it is generally very similar.
Anyway, on RISC-V we cannot assume that RVV (or XTheadVector) is always present, so using a scalar implementation as a fallback is reasonable and necessary.
But for a long time, the RISC-V DynaRec only had a scalar solution, which was a huge waste of hardware performance for hardware with RVV (or XTheadVector) support, until recently.Yes, in the past month, we added preliminary RVV and XTheadVector support to the RISC-V backend!Also, we managed to share most of the code between RVV 1.0 and XTheadVector, so no additional maintenance burden for supporting 2 extensions at once.
Ohhhh, I can’t wait, let me show you what thatpaddqlooks like now!

Hmmm, okay, it looks much nicer. But, you may ask, what the heck is thatVSETIVLI? Well… that’s a long story.
In “traditional” SIMD extensions, the width of the selected elements is encoded directly into the instruction itself, e.g. in x86 there is not onlypaddqfor 64bit addition, but alsopaddb,paddwandpadddfor 8bit, 16bit and 32bit respectively.
In RVV, on the other hand, there is only 1 vector-wise addition instruction, which isvadd.vv. The selected element width (SEW) is instead stored in a control register calledvtype, and you need to use the dedicatedvsetivliinstruction to set the value ofvtype. Every time a vector instruction is executed, thevtyperegister must be in a valid state.
In the abovevsetivliinstruction, we essentially set the SEW to 64bit along with other configurations. However, inserting avsetivlibefore every SIMD opcode doesn’t sound like a good idea. Ifvtypedoes not need to change between adjacent opcodes, we can safely eliminate them. And that’s how we did it in Box64.
Look at these dumps:

You can see that among the 5 SSE opcodes, as the actual SEW has not changed, we only callvsetivlionce at the top. We achieved this by adding a SEW tracking mechanism to the DynaRec and only insertingvsetvliwhen it’s necessary. This tracking not only includes the linear part but also considers control flow. A lot of state caching in box64 is done using a similar mechanism, so nothing new here.
For now, we haven’t implemented every x86 SIMD instruction in RVV / XTheadVector, but we implemented enough of them to do a proper benchmark. By tradition, we use the dav1d AV1 decoding benchmark as a reference, which happens to use SSE instructions a LOT, and here is the command we used:
dav1d -i ./Chimera-AV1-8bit-480x270-552kbps.ivf --muxer null --threads 8
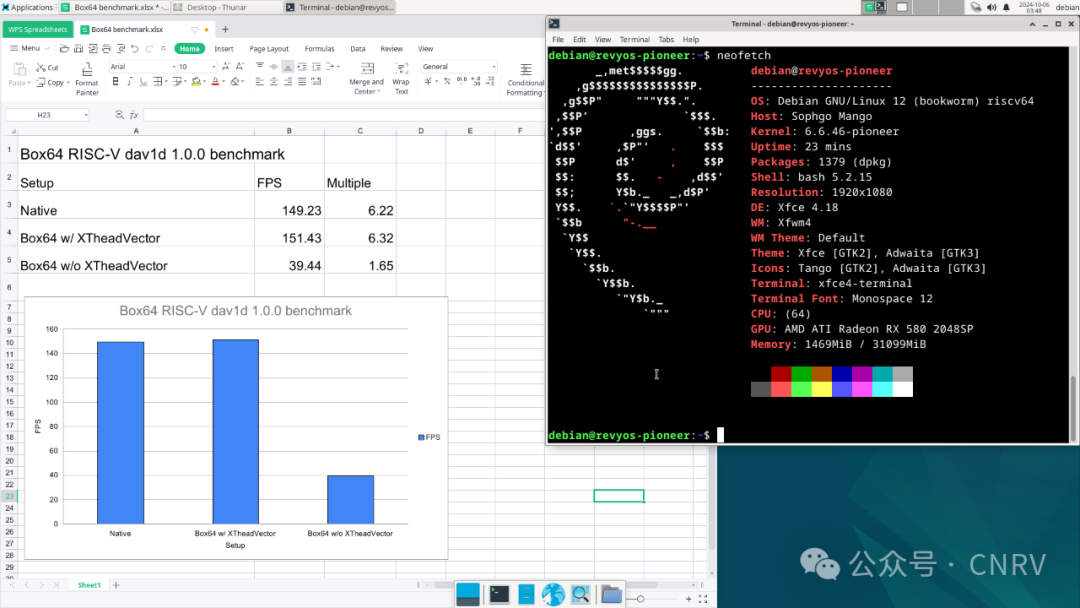
We did the test on the MilkV Pioneer, which has the XTheadVector extension.
We also tested RVV 1.0 with the SpacemiT K1, the result is more or less the same.
Compared to the scalar version, we get a nearly 4x performance improvement! Even faster than native! Ugh… well, the faster-than-native part is more symbolic. The comparison is meaningful only if native dav1d fully supports XTheadVector, which the native dav1d does not support at all.
Last But Not Least
In thelast post, we complained about RISC-V not having bit range insert and extract instructions, and therefore not being able to efficiently implement things like 8bit and 16bit x86 opcodes.camel-cdrcame up with a great solution:https://news.ycombinator.com/item?id=41364904. Basically, for anADD AH, BL, you can implement it using the following 4 instructions!
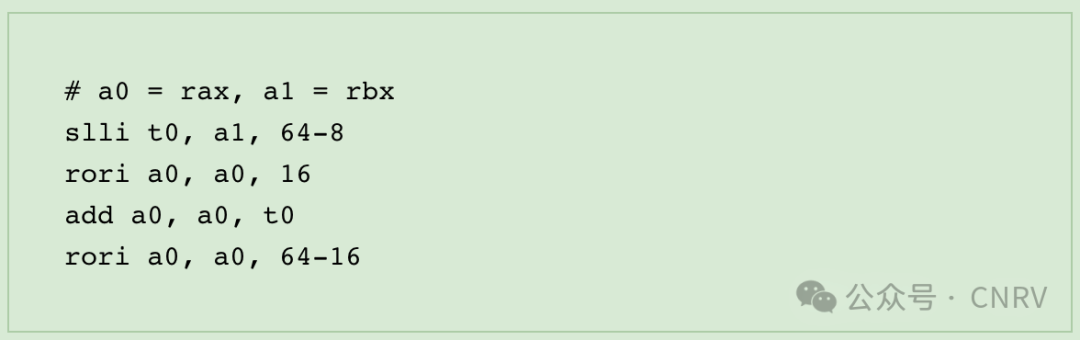
The core idea is to shift the actual addition to the high part to eliminate the effect of the carry, which is a pretty neat trick. And it can be applied to almost all of the 8-bit and 16-bit opcodes when there is noeflagscomputation required, which covers most scenarios. We have adopted this approach as a fast path to box64. Thank you very muchcamel-cdr!
This method requires an instruction from the Zbb extension calledRORI(Rotate Right Immediate). Fortunately, at least all the RISC-V hardware I own provides this extension, so it’s commonly available. (Well, SG2042 does not have Zbb, but it has an equivalent instructionTH.SRRIin the XTheadBb extension).
We also found that in the XTheadBb extension, there is aTH.EXTUinstruction, which did the bit extract operation. We’ve adapted this instruction to some places too, for example, the indirect jump table lookup — when box64 DynaRec needs to jump out of the current dynablock to the next dynablock, it needs to find where the next is.
In short, there are two cases. The first is a direct jump, that is, the jump address is known at compile time. In this case, box64 can directly query the jump table at compile time to obtain the jump address and place it in the built-in data area of dynablock, which can be used directly when jumping at runtime, no problem there.
The second is an indirect jump, that is, the jump address is stored in a register or memory and is unknown at compile time. In this case, box64 has no choice but to generate code that queries the jump table at runtime.
The lookup table is a data structure similar to page table, and the code for the lookup is as follows:

Hmmm, I know, it’s hard to see what’s happening there, but it seems like a lot of instructions there for a jump, right? But withTH.ADDSLandTH.EXTUfrom XTheadBb, it becomes:
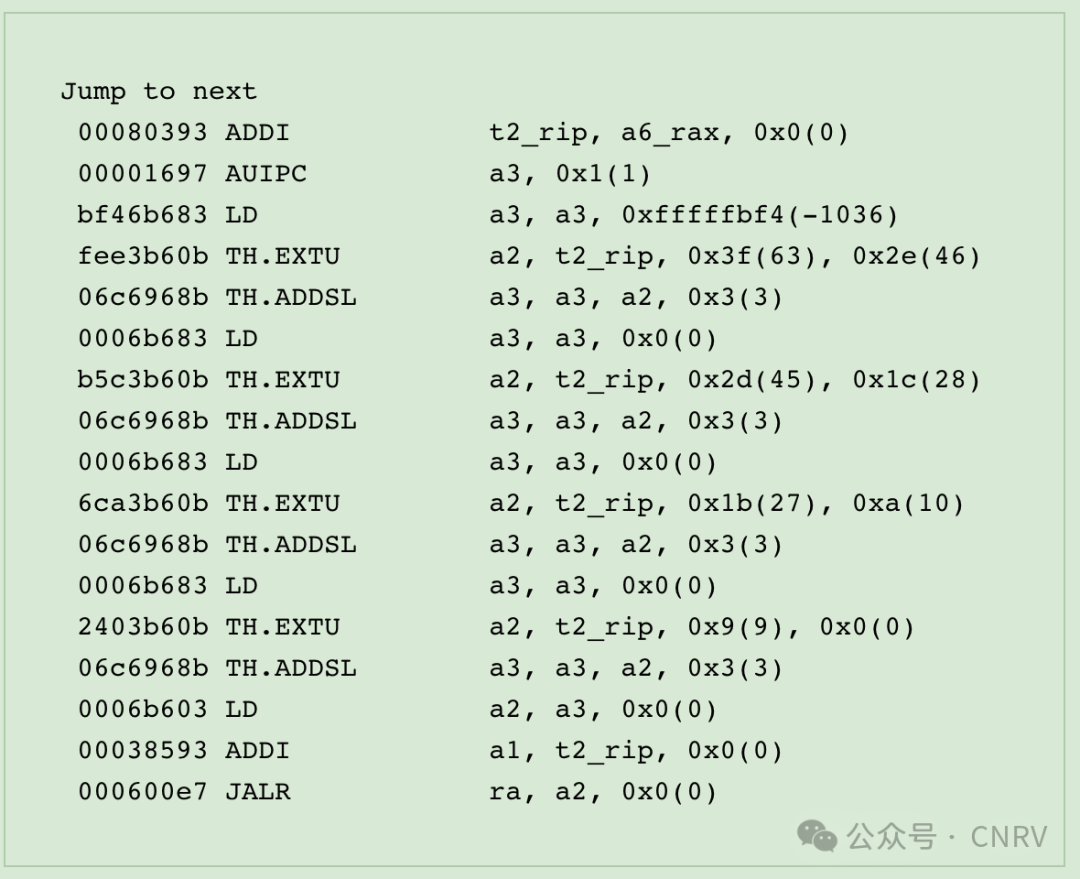
Now it’s much more readable; you should be able to see that this is a 4-layer lookup table, and the number of instructions required has also been reduced a bit.
Okay, all these optimizations look good, but does it show effects in real-world benchmarks? Well, we tested 7z b, dav1d and coremark, and there are no visible differences in the scores with or without XTheadBb. But, a quote from theSQLite website:
A microoptimization is a change to the code that results in a very small performance increase. Typical micro-optimizations reduce the number of CPU cycles by 0.1% or 0.05% or even less. Such improvements are impossible to measure with real-world timings. But hundreds or thousands of microoptimizations add up, resulting in measurable real-world performance gains.
So, let’s do our best and hope for the best!
In the End
Well, this is the end of this post, but it is not the end of optimizing the RISC-V DynaRec, we’ve barely started!
Next, we’ll add more SSE opcodes to the vector units, as well as MMX opcodes and AVX opcodes, and we will make the RISC-V DynaRec as shiny as the AArch64 one!
So, a bit more work, and we can have a look again at gaming, with, hopefully, playable framerates and more games running so stay tuned!
-
编译器
+关注
关注
1文章
1634浏览量
49136 -
模拟器
+关注
关注
2文章
875浏览量
43239 -
RISC-V
+关注
关注
45文章
2283浏览量
46174
发布评论请先 登录
相关推荐
【「RISC-V体系结构编程与实践」阅读体验】-- SBI及NEMU环境
什么是RISC-V?以及RISC-V和ARM、X86的区别
算能 SG2042 / Milk-V Pioneer 的含金量还在不断提升:RISC-V 生态逐步完善,玩大型游戏已经不远了!

浅谈RISC-C C Intrinsic的发展情况
RISC-V Vector Intrinsic使用标准
探索RISC-V二进制翻译,openKylin成功在SG2042平台运行X86架构软件!





 工商网监
工商网监
评论