 从五个步骤来讲解Redis架构设计
从五个步骤来讲解Redis架构设计
摘要:本文章主要分成五个步骤内容讲解
Redis、RedisCluster和Codis;
我们更爱一致性;
Codis在生产环境中的使用的经验和坑们;
对于分布式数据库和分布式架构的一些看法;
Q & A环节。
Codis是一个分布式Redis解决方案,与官方的纯P2P的模式不同,Codis采用的是Proxy-based的方案。今天我们介绍一下Codis及下一个大版本RebornDB的设计,同时会介绍一些Codis在实际应用场景中的tips。最后抛砖引玉,会介绍一下我对分布式存储的一些观点和看法,望各位首席们雅正。

一、 Redis,RedisCluster和Codis
Redis:想必大家的架构中,Redis已经是一个必不可少的部件,丰富的数据结构和超高的性能以及简单的协议,让Redis能够很好的作为数据库的上游缓存层。但是我们会比较担心Redis的单点问题,单点Redis容量大小总受限于内存,在业务对性能要求比较高的情况下,理想情况下我们希望所有的数据都能在内存里面,不要打到数据库上,所以很自然的就会寻求其他方案。 比如,SSD将内存换成了磁盘,以换取更大的容量。更自然的想法是将Redis变成一个可以水平扩展的分布式缓存服务,在Codis之前,业界只有Twemproxy,但是Twemproxy本身是一个静态的分布式Redis方案,进行扩容/缩容时候对运维要求非常高,而且很难做到平滑的扩缩容。Codis的目标其实就是尽量兼容Twemproxy的基础上,加上数据迁移的功能以实现扩容和缩容,最终替换Twemproxy。从豌豆荚最后上线的结果来看,最后完全替换了Twem,大概2T左右的内存集群。
Redis Cluster :与Codis同期发布正式版的官方cluster,我认为有优点也有缺点,作为架构师,我并不会在生产环境中使用,原因有两个:
cluster的数据存储模块和分布式的逻辑模块是耦合在一起的,这个带来的好处是部署异常简单,all-in-the-box,没有像Codis那么多概念,组件和依赖。但是带来的缺点是,你很难对业务进行无痛的升级。比如哪天Redis cluster的分布式逻辑出现了比较严重的bug,你该如何升级?除了滚动重启整个集群,没什么好办法。这个比较伤运维。
对协议进行了较大的修改,对客户端不太友好,目前很多客户端已经成为事实标准,而且很多程序已经写好了,让业务方去更换Redisclient,是不太现实的,而且目前很难说有哪个Rediscluster客户端经过了大规模生产环境的验证,从HunanTV开源的Rediscluster proxy上可以看得出这个影响还是蛮大的,否则就会支持使用cluster的client了。
Codis:和Redis cluster不同的是,Codis采用一层无状态的proxy层,将分布式逻辑写在proxy上,底层的存储引擎还是Redis本身(尽管基于Redis2.8.13上做了一些小patch),数据的分布状态存储于zookeeper(etcd)中,底层的数据存储变成了可插拔的部件。这个事情的好处其实不用多说,就是各个部件是可以动态水平扩展的,尤其无状态的proxy对于动态的负载均衡,还是意义很大的,而且还可以做一些有意思的事情,比如发现一些slot的数据比较冷,可以专门用一个支持持久化存储的server group来负责这部分slot,以节省内存,当这部分数据变热起来时,可以再动态的迁移到内存的server group上,一切对业务透明。比较有意思的是,在Twitter内部弃用Twmeproxy后,t家自己开发了一个新的分布式Redis解决方案,仍然走的是proxy-based路线。不过没有开源出来。可插拔存储引擎这个事情也是Codis的下一代产品RebornDB在做的一件事情。btw,RebornDB和它的持久化引擎都是完全开源的,见https://github.com/reborndb/reborn和https://github.com/reborndb/qdb。当然这样的设计的坏处是,经过了proxy,多了一次网络交互,看上去性能下降了一些,但是记住,我们的proxy是可以动态扩展的,整个服务的QPS并不由单个proxy的性能决定(所以生产环境中我建议使用LVS/HA Proxy或者Jodis),每个proxy其实都是一样的。
二、我们更爱一致性
很多朋友问我,为什么不支持读写分离,其实这个事情的原因很简单,因为我们当时的业务场景不能容忍数据不一致,由于Redis本身的replication模型是主从异步复制,在master上写成功后,在slave上是否能读到这个数据是没有保证的,而让业务方处理一致性的问题还是蛮麻烦的。而且Redis单点的性能还是蛮高的,不像mysql之类的真正的数据库,没有必要为了提升一点点读QPS而让业务方困惑。这和数据库的角色不太一样。所以,你可能看出来了,其实Codis的HA,并不能保证数据完全不丢失,因为是异步复制,所以master挂掉后,如果有没有同步到slave上的数据,此时将slave提升成master后,刚刚写入的还没来得及同步的数据就会丢失。不过在RebornDB中我们会尝试对持久化存储引擎(qdb)可能会支持同步复制(syncreplication),让一些对数据一致性和安全性有更强要求的服务可以使用。
说到一致性,这也是Codis支持的MGET/MSET无法保证原本单点时的原子语义的原因。 因为MSET所参与的key可能分不在不同的机器上,如果需要保证原来的语义,也就是要么一起成功,要么一起失败,这样就是一个分布式事务的问题,对于Redis来说,并没有WAL或者回滚这么一说,所以即使是一个最简单的二阶段提交的策略都很难实现,而且即使实现了,性能也没有保证。所以在Codis中使用MSET/MGET其实和你本地开个多线程SET/GET效果一样,只不过是由服务端打包返回罢了,我们加上这个命令的支持只是为了更好的支持以前用Twemproxy的业务。
在实际场景中,很多朋友使用了lua脚本以扩展Redis的功能,其实Codis这边是支持的,但记住,Codis在涉及这种场景的时候,仅仅是转发而已,它并不保证你的脚本操作的数据是否在正确的节点上。比如,你的脚本里涉及操作多个key,Codis能做的就是将这个脚本分配到参数列表中的第一个key的机器上执行。所以这种场景下,你需要自己保证你的脚本所用到的key分布在同一个机器上,这里可以采用hashtag的方式。
比如你有一个脚本是操作某个用户的多个信息,如uid1age,uid1sex,uid1name形如此类的key,如果你不用hashtag的话,这些key可能会分散在不同的机器上,如果使用了hashtag(用花括号扩住计算hash的区域):{uid1}age,{uid1}sex,{uid1}name,这样就保证这些key分布在同一个机器上。这个是twemproxy引入的一个语法,我们这边也支持了。
在开源Codis后,我们收到了很多社区的反馈,大多数的意见是集中在Zookeeper的依赖,Redis的修改,还有为啥需要Proxy上面,我们也在思考,这几个东西是不是必须的。当然这几个部件带来的好处毋庸置疑,上面也阐述过了,但是有没有办法能做得更漂亮。于是,我们在下一阶段会再往前走一步,实现以下几个设计:
使用proxy内置的Raft来代替外部的Zookeeper,zk对于我们来说,其实只是一个强一致性存储而已,我们其实可以使用Raft来做到同样的事情。将raft嵌入proxy,来同步路由信息。达到减少依赖的效果。
抽象存储引擎层,由proxy或者第三方的agent来负责启动和管理存储引擎的生命周期。具体来说,就是现在codis还需要手动的去部署底层的Redis或者qdb,自己配置主从关系什么的,但是未来我们会把这个事情交给一个自动化的agent或者甚至在proxy内部集成存储引擎。这样的好处是我们可以最大程度上的减小Proxy转发的损耗(比如proxy会在本地启动Redis instance)和人工误操作,提升了整个系统的自动化程度。
还有replication based migration。众所周知,现在Codis的数据迁移方式是通过修改底层Redis,加入单key的原子迁移命令实现的。这样的好处是实现简单、迁移过程对业务无感知。但是坏处也是很明显,首先就是速度比较慢,而且对Redis有侵入性,还有维护slot信息给Redis带来额外的内存开销。大概对于小key-value为主业务和原生Redis是1:1.5的比例,所以还是比较费内存的。
在RebornDB中我们会尝试提供基于复制的迁移方式,也就是开始迁移时,记录某slot的操作,然后在后台开始同步到slave,当slave同步完后,开始将记录的操作回放,回放差不多后,将master的写入停止,追平后修改路由表,将需要迁移的slot切换成新的master,主从(半)同步复制,这个之前提到过。
三、Codis在生产环境中的使用的经验和坑们
来说一些 tips,作为开发工程师,一线的操作经验肯定没有运维的同学多,大家一会可以一起再深度讨论。
关于多产品线部署:很多朋友问我们如果有多个项目时,codis如何部署比较好,我们当时在豌豆荚的时候,一个产品线会部署一整套codis,但是zk共用一个,不同的codis集群拥有不同的product name来区分,codis本身的设计没有命名空间那么一说,一个codis只能对应一个product name。不同product name的codis集群在同一个zk上不会相互干扰。
关于zk:由于Codis是一个强依赖的zk的项目,而且在proxy和zk的连接发生抖动造成sessionexpired的时候,proxy是不能对外提供服务的,所以尽量保证proxy和zk部署在同一个机房。生产环境中zk一定要是>=3台的奇数台机器,建议5台物理机。
关于HA:这里的HA分成两部分,一个是proxy层的HA,还有底层Redis的HA。先说proxy层的HA。之前提到过proxy本身是无状态的,所以proxy本身的HA是比较好做的,因为连接到任何一个活着的proxy上都是一样的,在生产环境中,我们使用的是jodis,这个是我们开发的一个jedis连接池,很简单,就是**zk上面的存活proxy列表,挨个返回jedis对象,达到负载均衡和HA的效果。也有朋友在生产环境中使用LVS和HA Proxy来做负载均衡,这也是可以的。 Redis本身的HA,这里的Redis指的是codis底层的各个server group的master,在一开始的时候codis本来就没有将这部分的HA设计进去,因为Redis在挂掉后,如果直接将slave提升上来的话,可能会造成数据不一致的情况,因为有新的修改可能在master中还没有同步到slave上,这种情况下需要管理员手动的操作修复数据。后来我们发现这个需求确实比较多的朋友反映,于是我们开发了一个简单的ha工具:codis-ha,用于监控各个server group的master的存活情况,如果某个master挂掉了,会直接提升该group的一个slave成为新的master。 项目的地址是:https://github.com/ngaut/codis-ha。
关于dashboard:dashboard在codis中是一个很重要的角色,所有的集群信息变更操作都是通过dashboard发起的(这个设计有点像docker),dashboard对外暴露了一系列RESTfulAPI接口,不管是web管理工具,还是命令行工具都是通过访问这些httpapi来进行操作的,所以请保证dashboard和其他各个组件的网络连通性。比如,经常发现有用户的dashboard中集群的ops为0,就是因为dashboard无法连接到proxy的机器的缘故。
关于go环境:在生产环境中尽量使用go1.3.x的版本,go的1.4的性能很差,更像是一个中间版本,还没有达到production ready的状态就发布了。很多朋友对go的gc颇有微词,这里我们不讨论哲学问题,选择go是多方面因素权衡后的结果,而且codis是一个中间件类型的产品,并不会有太多小对象常驻内存,所以对于gc来说基本毫无压力,所以不用考虑gc的问题。
关于队列的设计:其实简单来说,就是「不要把鸡蛋放在一个篮子」的道理,尽量不要把数据都往一个key里放,因为codis是一个分布式的集群,如果你永远只操作一个key,就相当于退化成单个Redis实例了。很多朋友将Redis用来做队列,但是Codis并没有提供BLPOP/BLPUSH的接口,这没问题,可以将列表在逻辑上拆成多个LIST的key,在业务端通过定时轮询来实现(除非你的队列需要严格的时序要求),这样就可以让不同的Redis来分担这个同一个列表的访问压力。而且单key过大可能会造成迁移时的阻塞,由于Redis是一个单线程的程序,所以迁移的时候会阻塞正常的访问。
关于主从和bgsave:codis本身并不负责维护Redis的主从关系,在codis里面的master和slave只是概念上的:proxy会将请求打到「master」上,master挂了codis-ha会将某一个「slave」提升成master。而真正的主从复制,需要在启动底层的Redis时手动的配置。在生产环境中,我建议master的机器不要开bgsave,也不要轻易的执行save命令,数据的备份尽量放在slave上操作。
关于跨机房/多活:想都别想。。。codis没有多副本的概念,而且codis多用于缓存的业务场景,业务的压力是直接打到缓存上的,在这层做跨机房架构的话,性能和一致性是很难得到保证的
关于proxy的部署:其实可以将proxy部署在client很近的地方,比如同一个物理机上,这样有利于减少延迟,但是需要注意的是,目前jodis并不会根据proxy的位置来选择位置最佳的实例,需要修改。
四、对于分布式数据库和分布式架构的一些看法(one more Thing)
Codis相关的内容告一段落。接下来我想聊聊我对于分布式数据库和分布式架构的一些看法。 架构师们是如此贪心,有单点就一定要变成分布式,同时还希望尽可能的透明:P。就MySQL来看,从最早的单点到主从读写分离,再到后来阿里的类似Cobar和TDDL,分布式和可扩展性是达到了,但是牺牲了事务支持,于是有了后来的OceanBase。Redis从单点到Twemproxy,再到Codis,再到Reborn。到最后的存储早已和最初的面目全非,但协议和接口永存,比如SQL和Redis Protocol。
NoSQL来了一茬又一茬,从HBase到Cassandra到MongoDB,解决的是数据的扩展性问题,通过裁剪业务的存储和查询的模型来在CAP上平衡。但是几乎还是都丢掉了跨行事务(插一句,小米上在HBase上加入了跨行事务,不错的工作)。
我认为,抛开底层存储的细节,对于业务来说,KV,SQL查询(关系型数据库支持)和事务,可以说是构成业务系统的存储原语。为什么memcached/Redis+mysql的组合如此的受欢迎,正是因为这个组合,几个原语都能用上,对于业务来说,可以很方便的实现各种业务的存储需求,能轻易的写出「正确」的程序。但是,现在的问题是数据大到一定程度上时,从单机向分布式进化的过程中,最难搞定的就是事务,SQL支持什么的还可以通过各种mysqlproxy搞定,KV就不用说了,天生对分布式友好。
于是这样,我们就默认进入了一个没有(跨行)事务支持的世界里,很多业务场景我们只能牺牲业务的正确性来在实现的复杂度上平衡。比如一个很简单的需求:微博关注数的变化,最直白,最正常的写法应该是,将被关注者的被关注数的修改和关注者的关注数修改放到同一个事务里,一起提交,要么一起成功,要么一起失败。但是现在为了考虑性能,为了考虑实现复杂度,一般来说的做法可能是队列辅助异步的修改,或者通过cache先暂存等等方式绕开事务。
但是在一些需要强事务支持的场景就没有那么好绕过去了(目前我们只讨论开源的架构方案),比如支付/积分变更业务,常见的搞法是关键路径根据用户特征sharding到单点MySQL,或者MySQLXA,但是性能下降得太厉害。
后来Google在他们的广告业务中遇到这个问题,既需要高性能,又需要分布式事务,还必须保证一致性:),Google在此之前是通过一个大规模的MySQL集群通过sharding苦苦支撑,这个架构的可运维/扩展性实在太差。这要是在一般公司,估计也就忍了,但是Google可不是一般公司,用原子钟搞定Spanner,然后再Spanner上构建了SQL查询层F1。我在第一次看到这个系统的时候,感觉简直惊艳,应该是第一个可以真正称为NewSQL的公开设计的系统。所以,BigTable(KV)+F1(SQL)+Spanner(高性能分布式事务支持),同时Spanner还有一个非常重要的特性是跨数据中心的复制和一致性保证(通过Paxos实现),多数据中心,刚好补全了整个Google的基础设施的数据库栈,使得Google对于几乎任何类型的业务系统开发都非常方便。我想,这就是未来的方向吧,一个可扩展的KV数据库(作为缓存和简单对象存储),一个高性能支持分布式事务和SQL查询接口的分布式关系型数据库,提供表支持。
五、Q & A
Q1:我没看过Codis,您说Codis没有多副本概念,请问是什么意思?
A1:Codis是一个分布式Redis解决方案,是通过presharding把数据在概念上分成1024个slot,然后通过proxy将不同的key的请求转发到不同的机器上,数据的副本还是通过Redis本身保证
Q2:Codis的信息在一个zk里面存储着,zk在Codis中还有别的作用吗?主从切换为何不用sentinel
A2:Codis的特点是动态的扩容缩容,对业务透明;zk除了存储路由信息,同时还作为一个事件同步的媒介服务,比如变更master或者数据迁移这样的事情,需要所有的proxy通过**特定zk事件来实现 可以说zk被我们当做了一个可靠的rpc的信道来使用。因为只有集群变更的admin时候会往zk上发事件,proxy**到以后,回复在zk上,admin收到各个proxy的回复后才继续。本身集群变更的事情不会经常发生,所以数据量不大。Redis的主从切换是通过codis-ha在zk上遍历各个server group的master判断存活情况,来决定是否发起提升新master的命令。
Q3:数据分片,是用的一致性hash吗?请具体介绍下,谢谢。
A3:不是,是通过presharding,hash算法是crc32(key)%1024
Q4:怎么进行权限管理?
A4:Codis中没有鉴权相关的命令,在reborndb中加入了auth指令。
Q5:怎么禁止普通用户链接Redis破坏数据?
A5:同上,目前Codis没有auth,接下来的版本会加入。
Q6:Redis跨机房有什么方案?
A6:目前没有好的办法,我们的Codis定位是同一个机房内部的缓存服务,跨机房复制对于Redis这样的服务来说,一是延迟较大,二是一致性难以保证,对于性能要求比较高的缓存服务,我觉得跨机房不是好的选择。
Q7:集群的主从怎么做(比如集群S是集群M的从,S和M的节点数可能不一样,S和M可能不在一个机房)?
A7:Codis只是一个proxy-based的中间件,并不负责数据副本相关的工作。也就是数据只有一份,在Redis内部。
Q8:根据你介绍了这么多,我可以下一个结论,你们没有多租户的概念,也没有做到高可用。可以这么说吧?你们更多的是把Redis当做一个cache来设计。
A8:对,其实我们内部多租户是通过多Codis集群解决的,Codis更多的是为了替换twemproxy的一个项目。高可用是通过第三方工具实现。Redis是cache,Codis主要解决的是Redis单点、水平扩展的问题。把codis的介绍贴一下: Auto rebalance Extremely simple to use Support both Redis or rocksdb transparently. GUI dashboard & admin tools Supports most of Redis commands. Fully compatible with twemproxy(https://github.com/twitter/twemproxy). Native Redis clients are supported Safe and transparent data migration, Easily add or remove nodes on-demand.解决的问题是这些。业务不停的情况下,怎么动态的扩展缓存层,这个是codis关注的。
Q9:对于Redis冷备的数据库的迁移,您有啥经验没有?对于Redis热数据,可以通过migrate命令实现两个Redis进程间的数据转移,当然如果对端有密码,migrate就玩完了(这个我已经给Redis官方提交了patch)。
A9:冷数据我们现在是实现了完整的Redissync协议,同时实现了一个基于rocksdb的磁盘存储引擎,备机的冷数据,全部是存在磁盘上的,直接作为一个从挂在master上的。实际使用时,3个group,keys数量一致,但其中一个的ops是另外两个的两倍,有可能是什么原因造成的?key的数量一致并不代表实际请求是均匀分布的,不如你可能某几个key特别热,它一定是会落在实际存储这个key的机器上的。刚才说的rocksdb的存储引擎:https://github.com/reborndb/qdb,其实启动后就是个Redis-server,支持了PSYNC协议,所以可以直接当成Redis从来用。是一个节省从库内存的好方法。
Q10:Redis实例内存占比超过50%,此时执行bgsave,开了虚拟内存支持的会阻塞,不开虚拟内存支持的会直接返回err,对吗?
A10:不一定,这个要看写数据(开启bgsave后修改的数据)的频繁程度,在Redis内部执行bgsave,其实是通过操作系统COW机制来实现复制,如果你这段时间的把几乎所有的数据都修改了,这样操作系统只能全部完整的复制出来,这样就爆了。
Q11:刚读完,赞一个。可否介绍下codis的autorebalance实现。
A11:算法比较简单,https://github.com/wandoulabs/codis/blob/master/cmd/cconfig/rebalancer.go#L104。代码比较清楚,code talks:)。其实就是根据各个实例的内存比例,分配slot好的。
Q12:主要想了解对降低数据迁移对线上服务的影响,有没有什么经验介绍?
A12:其实现在codis数据迁移的方式已经很温和了,是一个个key的原子迁移,如果怕抖动甚至可以加上每个key的延迟时间。这个好处就是对业务基本没感知,但是缺点就是慢。
原文标题:细说分布式Redis架构设计和踩过的那些坑
文章出处:【微信号:C_Expert,微信公众号:C语言专家集中营】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
软件架构设计的三个维度
软件架构设计的三个维度
系统架构设计的详细讲解
SWE.2的软件架构设计
五个步骤,讲解PCBA成本如何估算资料下载

Redis基础架构设计及核心网络模型架构演进
架构与微架构设计
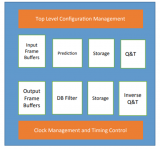
如何从0到1构建一个稳定、高性能的Redis集群?

Redis架构演化之路





 工商网监
工商网监
评论