 携程信息安全部在web攻击识别方面的机器学习实践之路
携程信息安全部在web攻击识别方面的机器学习实践之路
背景
通俗地讲,任何一个的机器学习问题都可以等价于一个寻找合适变换函数的问题。例如语音识别,就是在求取合适的变换函数,将输入的一维时序语音信号变换到语义空间;而近来引发全民关注的围棋人工智能AlphaGo则是将输入的二维布局图像变换到决策空间以决定下一步的最优走法;相应的,人脸识别也是在求取合适的变换函数,将输入的二维人脸图像变换到特征空间,从而唯一确定对应人的身份。
在web应用攻击检测的发展历史中,到目前为止,基本是依赖于规则的黑名单检测机制,无论是web应用防火墙或ids等等,主要依赖于检测引擎内置的正则,进行报文的匹配。虽说能够抵御绝大部分的攻击,但我们认为其存在以下几个问题:
规则库维护困难,人员交接工作,甚至时间一长,原作者都很难理解当初写的规则,一旦有误报发生,上线修改都很困难。
规则写的太宽泛易误杀,写的太细易绕过。
例如一条检测sql注入的正则语句如下:
Stringinj_str = “’|and|exec|insert|select|delete|update|count|*|%|chr|mid|master|truncate|char|declare|;|or|-|+|,”;
一条正常的评论,“我在selected买的衬衫脏了”,遭到误杀。
正则引擎严重影响性能,尤其是正则条数过多时,比如我们之前就遇到kafka中待检测流量严重堆积的现象。
那么该如何解决以上问题呢?尤其在大型互联网公司,如何在海量请求中又快又准地识别出恶意攻击请求,成为摆在我们面前的一道难题。
近来机器学习在信息安全方面的应用引起了人们的大量关注,我们认为信息安全领域任何需要对数据进行处理,做出分析预测的地方都可以用到机器学习。本文将介绍携程信息安全部在web攻击识别方面的机器学习实践之路。
恶意攻击检测系统nile架构介绍

图1: 携程nile 攻击检测系统架构第一版
首先我们简单介绍一下携程攻击检测系统nile的最初架构,如上图1所示,我们在流量进入规则引擎(这里指正则匹配引擎)之前,先用白名单过滤掉大于97%的正常流量(我们认为如http://ctrip.com/flight?Search?key=value,只要value参数值里面没有英文标点和控制字符的都是“正常流量”,另外还有携程的出口ip流量等等)。
剩下的3%流量过正则规则引擎,如果结果为黑(恶意攻击),就会发到漏洞自动化验证系统hulk(hulk介绍可以参考https://zhuanlan.zhihu.com/p/28115732),例如调用sqlmap去重放流量,复验攻击者能否真的攻击成功。
目前nile系统我们改进到了第五版,架构如下图2,其中最重要的改变是在规则引擎之前加入了spark机器学习引擎,目前使用的是spark mllib库来建模和预测。如果机器学习引擎为黑,则会继续抛给正则规则引擎做二次检查,若复验依然为黑,则会抛给hulk漏洞验证系统。

图2:携程nile 攻击检测系统架构最新版
这么做带来了以下好处:
机器学习的处理速度比较快,能够过滤掉大部分流量再扔给正则引擎。解决了过去正则导致kafka堆积严重的问题(即使是原始流量中的3%也存在此问题)。
可以对比正则引擎和机器学习引擎的结果,互相查缺补漏。例如我们可以发现正则的漏报或误报,手工修改或补充已有的正则库。若是机器学习误报,白流量识别为黑,首先想到的是否黑样本不纯,另外就是特征提取有问题。
如果机器学习漏报,那怎么办呢?按图2的流程我们根本不知道我们漏报了哪些。最直接的想法就是并列机器学习引擎和正则引擎,来查缺补漏,但这样违背了我们追求效率的前提。
最近的一个版本我们加入了动态ip黑名单,时间窗口内多次命中的的高风险ip重点关注,直接忽略storm白名单。在实践中,我们借鉴了此部分黑ip的流量来补充我们的学习样本(黑ip的流量99%以上都是攻击流量),我们发现了referer,ua注入等,其他还发现了其他逻辑攻击的痕迹,比如订单遍历等等。
有人可能会问,根据上面的架构,如果对方拿新流出的攻击poc来攻击你,只攻击1次,那不是检测不出来了么?首先如果poc中还是有很多的特殊英文标点和敏感单词的话,我们还是能检测出来的;另一种情况如果真的漏了,那怎么办,这时候只能人肉写新的正则加入检测逻辑中,如图2中我们加入了“规则引擎(新上规则)”直接进行检测,经过不断的打标签吐到es日志,新型攻击的日志又可以作为学习用的黑样本了,如此循环。
加入机器学习前后的效果对比:kafka消费流量:1万/分钟->400万+,白名单之后的检测量:1万/分钟->10万+。
我们设置了一分钟一个批次消费,每分钟有10万+数据从storm过来,只花了10秒钟左右处理完,所以如果我们缩短消费批次窗口,理论上还可以提高5-6倍的吞吐,如下图3。

图3:新架构下storm处理速度
我们先看一个机器学习的识别结果,如下图4:

图4:机器学习es记录日志
rule_result标签是正则的识别结果,由于当时我们没有添加struts2攻击的正则,但是由ES日志结果可知,机器学习引擎依然检测出了攻击。
介绍了完了架构,回归机器学习本身,下面将介绍如何建立一个web攻击检测的机器学习模型。而一般来讲,应用机器学习解决实际问题分为以下4个步骤:
定义目标问题
收集数据和特征工程
训练模型和评估模型效果
线上应用和持续优化
定义目标问题
核心的目标问题:
二分类问题,预测流量是攻击或者正常
漏报率必须<10%以上(在这里,我们认为漏报比误报问题更严重,误报我们还可以通过第二层的正则引擎去纠正)
模型预测速度必须快,例如knn最近邻这种带排序的算法被我们剔除在外
机器学习应用于信息安全领域,第一道难关就是标签数据的缺乏,得益于我们的ES日志中已有正则打上标签的真实生产流量,所以这里我们决定使用基于监督学习的二分类来建模。监督学习的目的是通过学习许多有标签的样本,然后对新的数据做出预测。当然也有人提出过无监督的思路,建立正常流量模型,不符合模型的都识别为恶意,比如使用聚类分析,本文不做进一步讨论。
没有一个机器学习模型可以解决所有的问题, 我们可以借鉴前人的经验,比如贝叶斯适用垃圾邮件识别,HMM适用语音识别。具体的算法对比可参考https://s3-us-west-2.amazonaws.com/mlsurveys/54.pdf
明确了我们需要达到的目标,下面开始考虑“收集数据和特征工程 ”,也是我们认为模型成败最关键的一步。
收集数据和特征工程
我们写段脚本,分别按天分时间段取ES黑白数据,并将其分开存储,再加上自研waf的告警日志,以及网上收集的poc,至此我们的训练原始材料准备好了 。另外特别需要注意的是:get请求和post请求我们分开提取特征,分开建模,至于为什么请读者自行思考。
一开始本地实验时,我是选用的python的sklearn库,训练样本黑白数据分别为10w+条数据,达到1比1的平衡占比。项目上线的时候,我们采用的是spark mllib来做的。本文为了介绍方便,还是以python+sklean来进行介绍。
再来聊聊“特征工程”。我们认为“特征工程”是机器模型中最重要的一部分,其更像是一门艺术,往往依赖于专家的“直觉”和专业领域经验,更甚者有人调侃机器学习其实就是特征工程。你能相信一个从来不看NBA的人建模出来的NBA总决赛预测结果模型么?
限于篇幅,这里主要介绍我们认为项目中比较重要的“特征工程”的步骤:
特征提炼:
核心需求:从训练数据中提取哪些有效信息,需要这些信息如何组织?
我们观察一下ES日志中攻击语句和正常语句的区别,如下:
攻击语句:flights.ctrip.com/Process/checkinseat/index?tpl_content=&name=test404.php&dir=index/../../../..¤t_dir=tpl
正常语句:flights.ctrip.com/Process/checkinseat/index?tpl_content=hello,world!
明显我们看到攻击语句里面最明显的特征是,含有eval, ../等字符、标点,而正常语句我们看到含有英文逗号,感叹号等等,所以我们可以将例如eval的个数列出来作为一个特征维度。在实际处理中我们忽略了uri,只取value参数中的值来提特征。比如上面的2条语句flights.ctrip.com/Process/checkinseat/index?tpl_content部分都被我们忽略了。
defget_evil_eval(url):
returnlen(re.findall("(eval)",url,re.IGNORECASE))
如果不存在value,例如是敏感目录猜测攻击,那怎么办,我们的做法是分开对待,剔除掉例如flights.ctrip.com等无效数据,取整个uri来提特征。
假设我们规定取5种特征,分别是script,eval,单引号,双引号,左括号的个数,那么上面攻击语句就转换为[0,1,0,0,2]
最后我们得到一个攻击语句的特征是5维的,打上标签label=1 ,正常流量label=0做区分。这样,一个请求就转换成一个1*n的矩阵,m个训练样本就是m*n的输入建模。
但是上线了第一版后,虽然消息队列消费速度大幅提升,识别率也基本都还可以,但我们还是放弃了这种正则匹配语句的特征提取方法,这里说下原因:
这样用正则来提取特征,总会有遗漏的关键词,又会陷入查缺补漏的怪圈
优化特征较麻烦,例如加上某个特征维度后,会增加误报,去掉后又会增加漏报
预测的时候,还是要将请求语句过一遍正则,转化为数字向量特征,降低了引擎效率
我们得到了使用机器学习来做情感二分类的启发,查证了资料1https://github.com/jeonglee/ML后,决定替换掉正则提取特征的方式,采用tfidf来提取特征。
我们认为本质上情感二分类和黑白流量分类是比较相似的问题,前者是给出一句话例如“Tom,you are not a good boy!”来判断是否正面评价,而我们的语句中没那么多正面或负面的情感词,更多的是英文标点和和一些疑似高危词语如select,那我们概念替换一下,高危英文标点是否就像是负面情感词,其他词就像是中性词,从而我们的问题就变成了二分类“中性语句和恶意语句”。
这里简单介绍下tfidf,更详尽的可以参考https://en.wikipedia.org/wiki/Tfidf。
例如我们有1000条get请求语句,第一条语句共计10个单词,其中单引号有3个,from也有3个。1000条语句中有10条语句包含单引号,100条包含from,tfidf计算如下(在进行tfidf计算之前,我们需要对句子中的标点和特殊字符做处理,比如转为string类型,具体参考资料1):


计算结果:单引号的tfidf=0.587 > from的tfidf=0.3318
TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。这里和我们的大脑判断基本一致,单引号的tfidf值对比之下更大,比from更能代表一句话是否是攻击语句。
代码demo如下:

之所以取ngram_range={1,3},是因为我们想保存前后单词间的顺序关系作为特征的一部分,例如前面的“Tom,you are not a good boy!”中的一个维度特征是[not, a , good],然后计算得到这个“集合词”的tfidf 。当然你可以基于char来取特征,具体的参数取值宽度都需要实验来证明哪一种效果最好。至于去停用词,标点怎么转换等等,大家可以参考https://github.com/jeonglee/ML/blob/master/spark/NaiveBayes/src/main/java/WordParser.java,这里就不赘述。
样本数据清洗:
虽然我们已经明确了如何提取特征,建模貌似也ok了,这时我们问自己一个问题:训练数据覆盖率怎么样,原始训练数据的标签是否准确?如果我们本身的训练样本就不纯净,结果一定也不尽如人意。下面说一下我们在样本清洗中做过的工作:
优化已有的检测正则:当打开white.txt和black.txt,我们肉眼观察了一下,发现不少的错误归类,所以说明我们的正则引擎本身就存在优化的需要。
加入动态ip黑名单,收集其攻击日志,加入黑样本。经过我们观察,发现这种持续拿扫描器扫描的ip,其黑流量占比99%以上
关于白样本,我们可以直接按时间段取原始流量作为白样本数据,因为毕竟白样本占镜像流量的99.99%以上
样本去重,相同请求内容语句进行去重
一些加密请求,根据参数名称,从样本中剔除
自建黑词库,放到白样本去中去匹配是否命中词库内容,查找标签明显错误的样本。举个例子,建立一个黑词库[base64_decode, onglcontext, img script, struts2....],然后放到白样本里去查找匹配中的句子,剔除之。其实这种方法可应用的地方很多,例如旅游业的机器人客服,就可以用酒店的关键词去火车票的样本中去清洗数据,我们也是受此启发。
特征清洗大概占我们工作量的60%以上,也是不可避免的持续优化的过程,属于体力活,无法避免。
特征归一化:由于这里我们采取了tfidf,所以这里就没有使用归一化处理了,因为词频tf就带了防止偏向长句子的归一化效果。这里再提一下,如果用第一版正则取特征的方式就必须使用特征归一化,具体原因和归一化介绍请参考http://blog.csdn.net/leiting_imecas/article/details/54986045 。
训练模型和评估模型效果
初步评判sklearn训练模型很简单,这里我们交叉训练下,拿50%的数据训练,50%的数据做测试,看下效果是否符合预期。
如果此时交叉训练的结果不尽如人意,一般原因有3个,且一般是下列第一、二种原因导致偏离预期结果较远,我们认为算法只是锦上添花,特征工程和样本的质量才是准确率高低的关键。
特征提取有问题,这个没办法,完全基于个人特定范围的知识领域经验
训练样本有问题,错误标签较多,或者样本不平衡
算法和选取的训练参数需要优化
前面2个都介绍过了,下面我们讲一下参数如何优化,这里我们介绍使用sklearn里面的GridSearchCV,其基本原理是系统地遍历多种参数组合,通过交叉验证确定最佳效果参数,参考官方使用示例http://scikit-learn.org/dev/modules/generated/sklearn.grid_search.GridSearchCV.html。
交叉训练达到心理预期之后,我们就将训练得到的本地模型存储到硬盘上,方便下次直接load使用。
训练和在线预测的demo代码如下,首先我们将黑白样本存储在trainData.csv,分别存在uri和label标签下,

图5:训练样本数据csv存储格式

此时,如果用已知标签的验证数据来评估我们的机器学习模型,我们推荐使用混淆矩阵作为评判标准,
#expected是标签值,predicted是模型预测的结果
print("Confusionmatrix:\n%s"%metrics.confusion_matrix(expected,predicted))
输出:
Confusion matrix:
[[ 1 0]
[ 4226 65867]]
大概解释下混淆矩阵的结果:
| 真实情况 | 预测结果 | |
| 正例 | 反例 | |
| 正例 | TP,实际为正预测为正 | FN,实际为正预测为负 |
| 反例 | FP,实际为负预测为正 | TN,实际为负预测为负 |
由于此次我们的验证数据集只有1条正常流量,所以我们看到FN为0 。我们更关心恶意流量被识别为正常流量的情况(漏报),我们看到这里漏报达到4226条,如果要计算漏报率,可以使用以下指标
print("Classificationreportforclassifier%s:\n%s\n"%(model,metrics.classification_report(expected,predicted)))
输出:
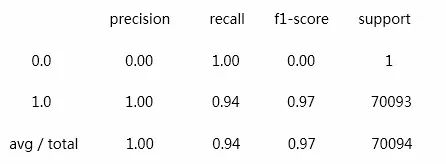
召回率:Recall=TP/ (TP+FN)
准确率:Accuracy=(TP+TN)/ (TP+FP+TN+FN)
精准率:Precision=TP/ (TP+FP) ,
f1-score是召回率和准确率的调和平均数,并假设两者一样重要,计算公式:
f1-score=(2*Recall*Accuracy) / (Recall+Accuracy)
很明显,我们这里的召回率0.94,代表我们的漏报率为6%,勉强属于可接纳的范围内,还需持续优化。
线上应用和持续优化
线上应用,也就是将建好的模型嵌入到我们已有的nile框架中去,且需要设置好一键开关机器学习引擎,还有正则的一键开关,对于某些经常漏报的就直接先进正则引擎了,当然正则个数需要约束,不然又走回了正则检测的死胡同了。后面我们就需要持续的观察输出,不断的自动化补充规则,自动训练新的模型。
参考前面提到的nile框架,目前遇到的最大的问题:我们如何面对遗漏了的攻击流量,是否可接受这部分风险。目前还没有想到一个好的方案。
归根结底,我们还是认为特征提取是对模型准确率影响最大的因素,特征工程是一个脏活累活,花在上面的时间远远大于其他步骤,对工程师的要求更高,往往要求大量的专业知识经验和敏锐的直觉,外加一些“灵感”。可以这样说,好特征即使配上较差的算法或参数,依然可以获得较好的结果。因为好的特征就意味着离现实问题的本质更加接近。另外就缺一个勤勤恳恳洗数据的工程师了。
未来展望
目前我们在机器学习方面的信息安全应用还存在以下可以更进一步的地方:
对非标准的json,xml数据包的判断,因为这些数据中内容长,标点多,且有的是非标准结构,例如json结构体无法顺利拆开,造成预测结果有误差。
加入多分类,可以识别出不同web攻击的类型,从而更好的和hulk结合。
在其他方面的应用,例如随机域名检测,ugc恶意评论,色情图片识别等等,目前这方面我们也已经陆续展开了实践。
将spark mllib库替换为spark ml库。
最后一句话总结,路才刚刚开始。
-
Web
+关注
关注
2文章
1275浏览量
70099 -
安防
+关注
关注
9文章
2269浏览量
63209 -
机器学习
+关注
关注
66文章
8462浏览量
133489
原文标题:机器学习在web攻击检测中的应用实践
文章出处:【微信号:AI_Thinker,微信公众号:人工智能头条】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐






 工商网监
工商网监
评论