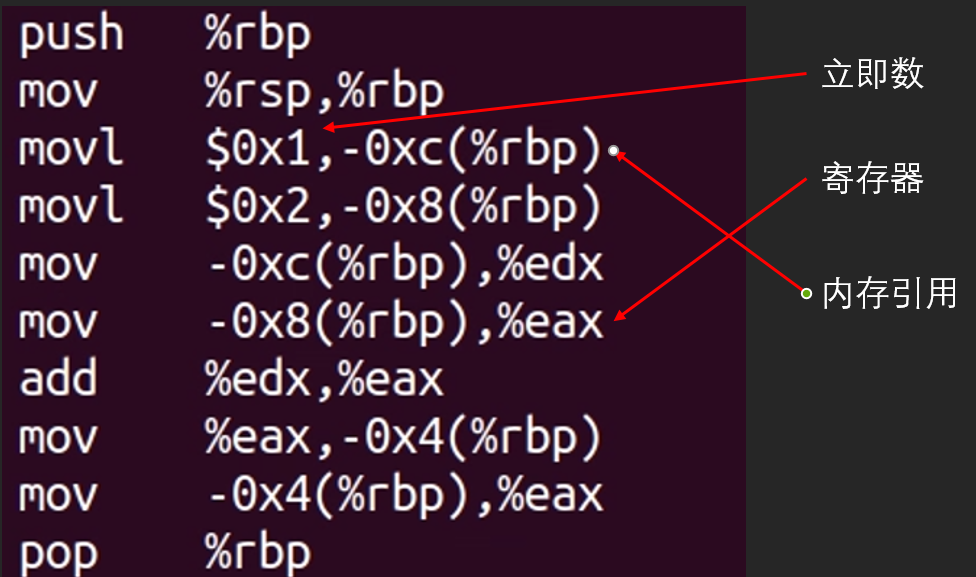
 基于gcc将C语言变量与指令操作数相关联
基于gcc将C语言变量与指令操作数相关联
有时候我们希望在C/C++代码中使用嵌入式汇编,因为C中没有对应的函数或语法可用。比如我最近在ARM上写FIR程序时,需要对最后的结果进行饱和处理,但gcc没有提供ssat这样的函数,于是不得不在C代码中嵌入汇编指令。
1. 入门
在C中嵌入汇编的最大问题是如何将C语言变量与指令操作数相关联。当然,gcc都帮我们想好了。下面是是一个简单例子。
asm(“fsinx %1, %0”:”=f”(result):”f”(angle));
这里我们不需要关注fsinx指令是干啥的;只需要知道这条指令需要两个浮点寄存器作为操作数。作为专职处理C语言的gcc编译器,它是没办法知道fsinx这条汇编指令需要什么样的操作数的,这就要求程序猿告知gcc相关信息,方法就是指令后面的”=f”和”f”,表示这是两个浮点寄存器操作数。这被称为操作数规则(constraint)。规则前面加上”=”表示这是一个输出操作数,否则是输入操作数。constraint后面括号内的是与该寄存器关联的变量。这样gcc就知道如何将这条嵌入式汇编语句转成实际的汇编指令了:
fsinx:汇编指令名
%1, %0:汇编指令操作数
“=f”(result):操作数%0是一个浮点寄存器,与变量result关联(对输出操作数,“关联”的意思就是说gcc执行完这条汇编指令后会把寄存器%0的内容送到变量result中)
“f”(angle):操作数%1是一个浮点寄存器,与变量angle关联(对输入操作数,“关联”的意思是就是说gcc执行这条汇编指令前会先将变量angle的值读取到寄存器%1中)
因此这条嵌入式汇编会转换为至少三条汇编指令(非优化):
将angle变量的值加载到寄存器%1
fsinx汇编指令,源寄存器%1,目标寄存器%0
将寄存器%0的值存储到变量result
当然,在高优化级别下上面的叙述可能不适用;比如源操作数可能本来就已经在某个浮点寄存器中了。
这里我们也看到constraint前加”=”符号的意义:gcc需要知道这个操作数是在执行嵌入汇编前从变量加载到寄存器,还是在执行后从寄存器存储到变量中。
常用的constraints有以下几个(更多细节参见gcc手册):
m 内存操作数
r 寄存器操作数
i 立即数操作数(整数)
f 浮点寄存器操作数
F 立即数操作数(浮点)
从这个栗子也可以看出嵌入式汇编的基本格式:
asm(“汇编指令”:”=输出操作数规则”(关联变量):”输入操作数规则”(关联变量));
输出操作数必须为左值;这个显然。
2. 多个操作数,或没有输出操作数
如果某个指令有多个输入或输出操作数怎么办?例如arm有很多指令是三操作数指令。这个时候用逗号分隔多个规则:
asm(“add %0, %1, %2”:”=r”(sum):”r”(a), “r”(b));
每条操作数规则按顺序对应操作数%0, %1, %2。
对于没有输出操作数的情况,在汇编指令后就没有输出规则,于是就出现两个连续冒号,后跟输入规则。
3. 输入-输出(或读-写)操作数
有时候一个操作数既是输入又是输出,比如x86下的这条指令:
add %eax, %ebx
注意指令使用AT&T格式而不是Intel格式。寄存器ebx同时作为输入操作数和输出操作数。对这样的操作数,在规则前使用”+”字符:
asm("add %1, %0" : "+r"(a) : "r"(b));
对应C语言语句a=a+b。
注意这样的操作数不能使用”=”符号,因为gcc看到”=”符号会认为这是一个单输出操作数,于是在将嵌入汇编转换为真正汇编的时候就不会预先将变量a的值加载到寄存器%0中。
另一个办法是将读-写操作数在逻辑上拆分为两个操作数:
asm(“add %2, %0” : “=r”(a) : “0”(a), “r”(b));
对“逻辑”输入操作数1指定数字规则”0”,表示这个逻辑操作数占用和操作数0一样的“位置”(占用同一个寄存器)。这种方法的特点是可以将两个“逻辑”操作数关联到两个不同的C语言变量上:
asm("add %2, %0" : "=r"(c) : "0"(a), "r"(b));
对应于C程序语句c=a+b。
数字规则仅能用于输入操作数,且必须引用到输出操作数。拿上例来说,数字规则”0”位于输入规则段,且引用到输出操作数0,该数字规则自身占用操作数计数1。
这里要注意,通过同名C语言变量是无法保证两个操作数占用同一“位置”的。比如下面这样的写法是不行的:
(错误写法)asm(“add %2, %0”:”=r”(a):”r”(a), “r”(b));
4. 指定寄存器
有时候我们需要在指令中使用指定的寄存器;典型的栗子是系统调用,必须将系统调用码和参数放在指定寄存器中。为了达到这个目的,我们要在声明变量时使用扩展语法:
register int a asm(“%eax”) = 1; // statement 1
register int b asm(“%ebx”) = 2; // statement 2
asm("add %1, %0" : "+r"(a) : "r"(b)); // statement 3
注意只有在执行汇编指令时能确定a在eax中,b在ebx中,其他时候a和b的存放位置是不可知的。
另外,在这么用的时候要注意,防止statement 2在执行时覆盖了eax。例如statement 2改成下面这句:
register int b asm(“%ebx”) = func();
函数调用约定会将func()的返回值放在eax里,于是破坏了statement 1对a的赋值。这个时候可以先用一条语句将func返回值放在临时变量里:
int t = func();
register int a asm(“%eax”) = 1; // statement 1
register int b asm(“%ebx”) = t; // statement 2
asm("add %1, %0" : "+r"(a) : "r"(b)); // statement 3
5. 隐式改变寄存器
有的汇编指令会隐含修改一些不在指令操作数中的寄存器,为了让gcc知道这个情况,将隐式改变寄存器规则列在输入规则之后。下面是VAX机上的栗子:
asm volatile(“movc3 %0,%1,%2”
: /* no outputs */
:”g”(from),”g”(to),”g”(count)
:”r0”,”r1”,”r2”,”r3”,”r4”,”r5”);
(movc3是一条字符块移动(Move characters)指令)
这里要注意的是输入/输出规则中列出的寄存器不能和隐含改变规则中的寄存器有交叉。比如在上面的栗子里,规则“g”中就不能包含r0-r5。以指定寄存器语法声明的变量,所占用的寄存器也不能和隐含改变规则有交叉。这个应该好理解:隐含改变规则是告诉gcc有额外的寄存器需要照顾,自然不能和输入/输出寄存器有交集。
另外,如果你在指令里显式指定某个寄存器,那么这个寄存器也必须列在隐式改变规则之中(有点绕了哈)。上面我们说过gcc自身是不了解汇编指令的,所以你在指令中显式指定的寄存器,对gcc来说是隐式的,因此必须包含在隐式规则之中。另外,指令中的显式寄存器前需要一个额外的%,比如%%eax。
6. volatile
asm volatile通知gcc你的汇编指令有side effect,千万不要给优化没了,比如上面的栗子。
如果你的指令只是做些计算,那么不需要volatile,让gcc可以优化它;除此以外,无脑给每个asm加上volatile或者是个好办法。
-
寄存器
+关注
关注
31文章
5386浏览量
121527 -
内存
+关注
关注
8文章
3074浏览量
74462 -
C语言
+关注
关注
180文章
7617浏览量
138198 -
GCC
+关注
关注
0文章
109浏览量
24943
原文标题:byeyear: gcc内嵌汇编详解
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
ARM指令集的格式与操作数符号简析
单片机寻找操作数存放单元地址的方法解析





 工商网监
工商网监
评论