 “AI视频通话”产品化的三条路
“AI视频通话”产品化的三条路

“做AI产品经理太难了。”近期脑极体的同事参加了一场开发者大会,一位产品经理向我们坦言:“AI时代,做产品的方法论没变,但以往熟悉的东西几乎都被清零了。”
用户需求被清零了,大模型到底能用来做什么,用户自己是不清楚的,需求是空白的,需求调研、产品定义,就要花费好几个月的时间。
好不容易定义好了,基础模型的一个更新,就有可能将前期所做的工作、功能规划等推倒重来。
“比如GPT-4o出现之后,语音对话的能力是我们完全意想不到的,就又得把产品开发过程再来一遍……”
而纵观一年多来推陈出新的数百个大模型,GPT-4o可以说是产品化程度非常高的一个了。
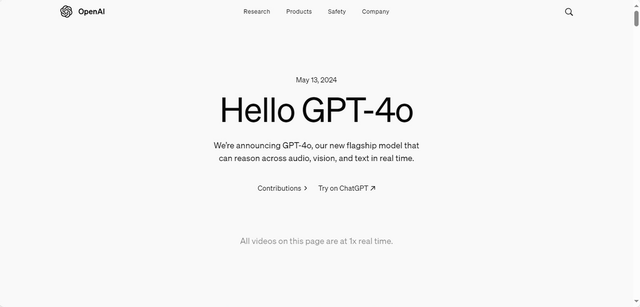
比如OpenAI发布会上展示的“AI视频通话”,使用户与AI进行实时的、跟真人对话一样自然的视频交流。国内模型厂商也很快推出了类似的AI视频通话功能,不少媒体和用户都表示“体验炸裂”。
但半年时间过去,发现在最初的震惊与新鲜感过后,在真正的软件生态里,还是没有看到“AI视频通话”被大规模、高频率地用起来,更别提激活用户的付费欲望了。为什么会这样?
我们就从“AI视频通话”说开去,聊聊AI产品化、商业化到底要经过哪些磨砺。

钻石原矿被开采出来,其实并不璀璨夺目,是经由工匠们的切割打磨,被镶嵌成钻石首饰,包装为“爱情象征”,才走进大众消费市场,价值实现了百倍千倍攀升。
类GPT-4o大模型就类似于原矿,作为“交互天花板”,潜在商业价值很大,但必须经过产品化的精细打磨与包装,才能被大众用户广泛接受,实现其真正的价值和应用潜力。
而基于类GPT-4o所诞生的“AI视频通话”,虽然向产品化迈进了一步,但依然属于原型的基础能力。
尽管OpenAI、智谱等模厂已经针对“AI视频通话”这一应用,打磨了诸如响应速度、具体用例等产品侧的细节,并融入到ChatGPT、智谱清言APP等产品当中。但作为一种软件应用来说,这种与通用场景相结合的落地模式,还是比较粗陋。
首先,需求过于宽泛。
AI视频通话,技术上相当于让AI拥有“眼睛”和“嘴”,具备察言观色、跟真人对话的能力。这很容易就让人想到AI陪伴,人与AI谈天说地、谈情说爱。
直接将AI视频通话能力嫁接在聊天机器人上,本质依然是AI聊天,能力升级,但无法解决chatbot商业价值低的核心问题。
AI视频聊天,用户容错率高,不在乎AI偶尔犯错或出现幻觉,这也意味着对基础模型能力要求不严苛,无法在技术层面拉开差距。曾经的智能音箱大战、智能助手红海,也会在AI视频聊天领域出现,并且由于聊天并不能帮助用户完成具体任务或解决问题,用户还得自己琢磨在视频里跟AI聊什么,没一会儿就只能跟AI面面相觑,难以带来确定性的产品满足和持久粘性,新鲜感过后就会流失。
而一些直接用途,想要普遍应用,也有大量细节仍待填充。
比如基于AI视频通话的无障碍功能,是一个非常直接的落地场景。AI视频通话,可以将设备摄像头作为“眼睛”,帮助人去理解物理世界,这对视障人群岂不是很友好?
但实际上,大模型APP的视频通话功能,是无法直接被视障人群用起来的,还有大量的产品细节需要考虑。比如我们曾体验过实时图像识别,AI只能认出“面前有两张卡”,但哪张是公交卡,哪张是银行卡,是无法准确识别的,这就需要基于视障群体出行接触的高频物体,进行针对性地精调。
而且,在飞机、高铁、地铁等弱网、无网环境下,也要保证视障人群与AI视频通话的实时性,就需要纯端侧运行的多模态大模型,将模型做小、计算效率做高。
产品设计层面,还有大量的细节,还等待着填充,才能转化为用户可以方便使用的产品和服务。
可以看到,没有更细致的产品化,尽管“AI视频通话”这一基础能力很厉害,却不知道能用来干什么,很可能导致技术找不到市场,倒在了产品化变现的黎明到来之前。
这个“至暗时刻”会发生吗?
欣慰的是,我们发现 “AI视频通话”能力,已经开始向行业输送了,意味着这座AI基础能力的“原矿”,终于开始被打磨成晶光四射的钻石。
我们就从“原矿”流向的应用领域,来分享几个“AI视频通话”的产品化方向。

大模型怎么落地?智能体是方向。
智能体怎么服务?+AI视频通话事半功倍。
如今,手机软件承载着我们日常的绝大多数服务,在各个应用中来回跳转、操作是非常繁琐的。
今年以来,荣耀、vivo等厂商都在基于智能体打造一系列创新功能体验,比如“一句话点奶茶”“一句话订餐厅”等。用户只需要向手机助手发出指令,手机智能体会自动理解需求、拆解任务步骤、调取相关功能,一站到底地完成任务。
Agent手机就很好地解决了数字服务链路长、操作繁琐的问题,但新的问题又来了,那就是智能体还需要“看得懂”“能交流”。
举个例子,在外卖小程序下单时,遇到广告是常态,这时候需要智能体agent执行准确的操作,比如“点击关闭”“跳过”等,来推进到下一步。如果智能体无法识别相关内容,必须用户自己动手操作,那整个链路就被打断了,用户体验会非常不好。有跟智能助手通过文字prompt交流的功夫,用户自己就能点开程序完成下单了。
Agent手机+视频通话,就能用户体验更进一步。
比起打字的繁琐、语音尴尬症,在人机对话时,像跟真人面对面交流一样,通过语音对话完成下单,更符合直觉,也更有被服务的舒适感。对话之后,大模型对视频画面进行实时分析,指导智能体来自动执行,整个体验会从头到尾丝滑无感。

目前,国内终端厂商在端侧智能体方面走得是更快的。脑极体在VDC 2024大会上了解到,蓝河操作系统增添了视觉感知能力,让系统像人类一样“听得懂”“看得清”。智能体能够模拟人类的智能,助力操作系统像人一样进行沟通、执行智能任务。
如果说,智能体可以让人成为数字服务的最小参与者,那么在智能体手机中打磨的AI视频通话,则让人机交互朝着更理想、更符合直觉的体验靠近,让数字生活管家走进现实。

将AI视频通话功能集成到垂直应用软件中,可以变成拟人化的垂域专家,提供更专业的服务,解决更具体的问题,从而激活用户的付费意愿和模型API经济。
目前,OpenAI为GPT-4o预设了十几个场景,清言视频通话API上线智谱开放平台时,也列出了智能硬件(VR眼镜)、教育培训AI私教、文旅场景AI向导、具身智能等落地方向。通过将AI视频通话API开放出来,鼓励开发者在产品中集成“AI视频通话”功能。

9月24日,多邻国(Duolingo)在第六届全球分享大会上,推出了 AI 视频通话(Video Call)。Duolingo Max 用户可以与多邻国的角色 Lily(拽姐)进行视频通话,进行个性化的互动练习。在对话中,AI会根据用户的语言水平灵活调整内容。
学习语言最难的就是高频使用环境和开口说话的心理障碍,通过AI视频通话提供实时的对话机会,可以让小白初学者也能自信开口,进行有效联系。据说,多邻国的这一新功能接入了OpenAI的高级语音API功能。

国内头部社交软件Soul,也上线了AI聊天机器人“AI苟蛋”,可以主动跟用户找话题,并且年底将开启AI陪聊机器人的视频通话服务。不同于泛泛聊天,Soul主打的是灵魂交友,平台用户倾向于开展深层交流,探讨深度话题,寻求心灵共鸣。
在这种较为成熟的社区氛围下,用户在使用AI视频通话的预期、内容也是较为明确的,不会出现不知道聊什么的情况。
各行各业都存在大量需要互动的场景,可以跟“AI视频通话”相结合提供拟人化体验。但用户能否由此对应用和AI视频通话产生黏性,还需要行业伙伴把使用门槛降到最低,这不仅需要行业拥有产品开发的能力与意愿,能够洞察缺口与机遇,也需要模厂的生态支持。

从哆啦A梦到阿童木、贾维斯、Her,这些让人类感觉友好温暖的AI,都是拟人化的。也许说明,我们更愿意跟更像人类的AI打交道,而不是冰冷无形的机器。
一位智能机器从业者告诉我们,一开始设计的新车只有虚拟的语音助手,用户上车之后觉得跟空气说话很尴尬,激活率不高,所以设计了一个带有屏幕的车载控件,可以跟车主打招呼、有表情,车主很喜欢跟它对话,逢年过节还会为它买各种装饰物,把它当作用车场景中的家庭一员。
从这个思路看,AI视频通话其实可以被加入各种硬件当中,与用户展开真人一般的对话,从而成为情感共同体,由此衍生的商业空间也非常充裕。
透过AI视频通话,相信大家能够感受到,无论是AI企业或普通大众,对于AI产品化的需求越来越实质。
模型技术只是能力,是原型,而远不到普遍可用的阶段。唯有通过产品化的细致打磨,AI这座商业富矿,才能真正显露出钻石般的光芒。

-
AI
+关注
关注
87文章
30098浏览量
268385
发布评论请先 登录
相关推荐
TIKOOL太酷信息-数字矩阵内部通话系统
AI 大模型行业应用:企业如何走出一条智能化蜕变之路?
THS8136三路10位180 MSPS图形和视频DAC数据表

DigiKey 推出《数字化城市》第 4 季视频系列,聚焦人工智能

聚焦AI技术引领,智象未来全面赋能图片及视频内容生产

HDMI音视频采集与H.264编码⼀体化采集卡LCC260数据手册
具有三条 100mA 通道的低 EMI 汽车 LED驱动器TPS61193-Q1数据表
鸿蒙开发实战【通话管理】
Stability AI与Morph AI共同推出一体化AI视频创作工具
关于ADV7180三路CVBS输入时的使用问题
学习台灯|AI摄像头学习机_支持视频通话方案






 工商网监
工商网监
评论