 将TVM用于移动端常见的ARM GPU,提高移动设备对深度学习的支持能力
将TVM用于移动端常见的ARM GPU,提高移动设备对深度学习的支持能力
编者按:半年前,上海交大陈天奇团队开源了端到端IR堆栈工具TVM,可以帮用户优化深度学习过程中的硬件配置,缓解了当前大多数计算机GPU在面对深度学习时表现出来的性能不足。近日,团队的一名学生郑怜悯带来了项目的新进展,他将TVM用于移动端常见的ARM GPU,提高了移动设备对深度学习的支持能力。
以下是论智对原文的翻译:
随着深度学习不断取得进展,开发者们对在移动设备上的部署神经网络的需求也与日俱增。和我们之前在桌面级GPU上做过的尝试类似,把深度学习框架移植到移动端需要做到这两点:够快的inference速度和合理的能耗。但是,现在的大多数DL框架并不能很好地支持移动端GPU,因为它们和桌面级GPU在架构上存在巨大差异。为了在移动端做深度学习,开发者们往往要对GPU做一些特殊优化,而这类额外工作也加大了对GPU的压力。
TVM是一个端到端的IR堆栈,它可以解决学习过程中的资源分配问题,从而轻松实现硬件优化。在这篇文章中,我们将展示如何用TVM/NNVM为ARM Mali GPU生成高效kernel,并进行端到端编译。在对Mali-T860 MP4的测试中,我们的方法在VGG-16上比Arm Compute Library快了1.4倍,在MobileNet上快了2.2倍。这些提升在图像处理和运算上均有体现。
Mali Midgard GPU
目前,移动领域最常见的3大图形处理器为高通的Adreno、英国PowerVR和ARM的嵌入式图形处理器Mali。我们的测试环境是配有Mali-T860 MP4 GPU的开发板Firefly-RK3399,所以下面我们主要关注Mali T8xx的表现。
架构
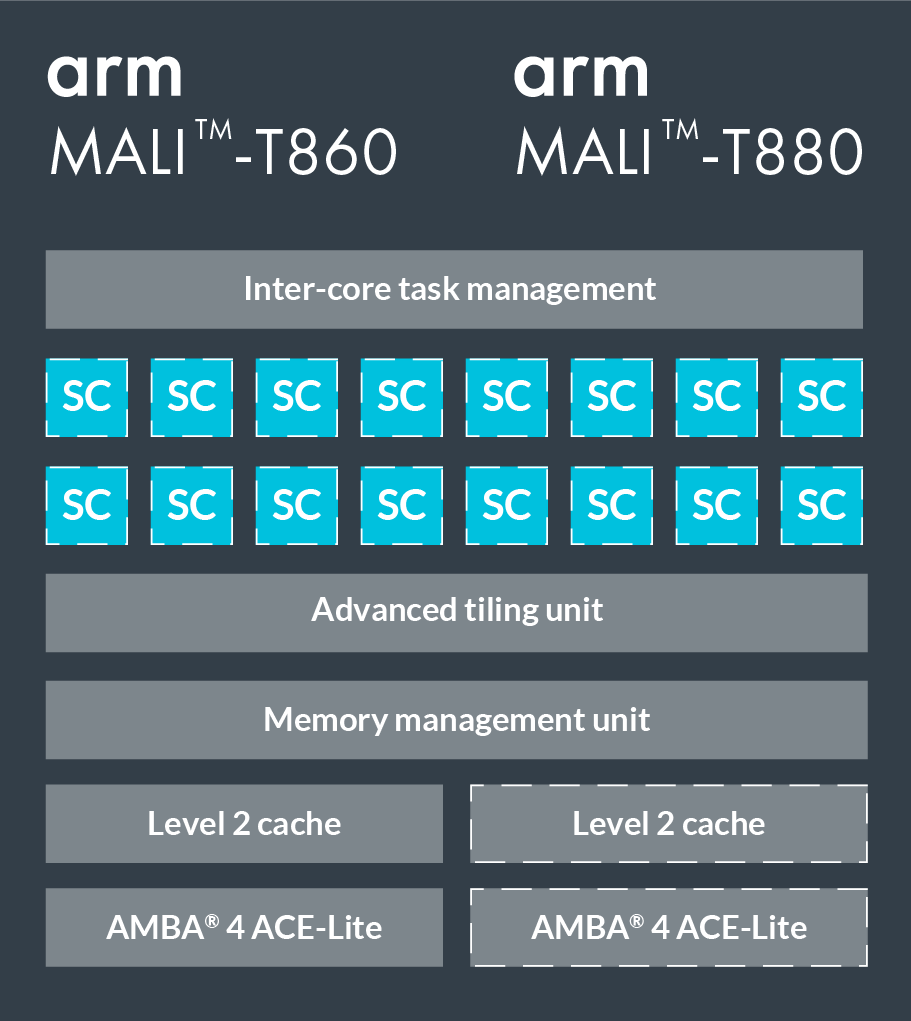
T860和T880是Mali系列的两款高端GPU,下图是具体配置。它们有16个着色器核心(Shader Core),每个核心内包含2—3条运算管道、1条加载/存储管道和1条纹理管道(即Triple Pipeline架构)。其中运算管道中的ALU(算数逻辑单元)又包含4个128-bit的矢量单元和一个标量单元。
我们用OpenCL编写程序。当映射到OpenCL模型时,每个着色器核心会执行一个或多个工作组,它们的上限是并行执行384个线程,通常一个工作组对应一个线程。Mali系列GPU使用的是VLIW架构(超长指令集架构),因此每个指令包含多个操作;同时,它也用了SIMD(单指令流多数据流),所以大多数运算运算指令可以同时执行多个数据流。
和NVIDIA GPU的区别
在用TVM优化GPU前,我们先看一看Mali GPU和NVIDIA GPU的区别:
NVIDIA GPU的存储系统架构一般分为全局内存、共享内存、寄存器三层,在实践中我们通常会把数据复制到共享内存;而Mali GPU只有一个统一的全局内存,它不需要制作副本提升性能,因为这个内存是和CPU共享的,所以CPU和GPU之间也不需要复制;
Mali Midgard GPU基于SIMD设计,所以需要用到矢量;而在NVIDIA CUDA中,GPU的并行处理是通过SIMT实现的,所以它对矢量没有那么高的要求。需要注意的是,Mali Bifrost架构的图形处理器新添加了Quad based vectorization技术,即允许四个线程一起被执行,它也不太需要矢量;
Mali GPU中的每一个线程都有独立的程序计数器,即warp size=1,所以Branch Divergence不是问题。
优化:以卷积层为例
卷积层是许多深度神经网络的核心,也占用了大部分计算资源。所以我们以卷积层为例,谈谈TVM在pack、tile、unroll、向量化中的优化应用。
im2col+GEMM
im2col是卷积计算的一种常用方法,它会把问题转换成一个矩阵,然后调用GEMM完成矩阵乘法运算。这种方法的优点是便于和高度优化的BLAS库结合,缺点是会耗费大量内存。
Spatial Packing
所以我们换了一种方法,先计算卷积,再逐步应用优化技术。以VGG-16中的卷积层为例(如下图所示),inference的batch size=1。

为了提供一个对照组,我们列出了Arm Compute Library的数据。

pack和tile是两个调整内存的常见指令。其中tile是把数据划分成片,使每一片适合共享内存的使用;而pack则是对输入矩阵重新布局(内存对齐),方便我们按顺序读取数据。
我们在输入图像的宽度和filter矩阵的CO维上使用了tile(tvm.compute):
# set tiling factor
VH = 1
VW = VC = 4
# get input shape
_, CI, IH, IW = data.shape
CO, CI, KH, KW = kernel.shape
TH = IH + 2 * H_PAD
TW = IW + 2 * W_PAD
# calc output shape
OH = (IH + 2*H_PAD - KH) // H_STR + 1
OW = (IW + 2*W_PAD - KW) // W_STR + 1
# data shape after packing
dvshape = (N, TH // (VH*H_STRIDE), TW // (VW*W_STRIDE), CI, VH*H_STRIDE+HCAT, VW*W_STRIDE+WCAT)
# kernel shape after packing
kvshape = (CO // VC, CI, KH, KW, VC)
ovshape = (N, CO // VC, OH // VH, OW // VW, VH, VW, VC)
oshape = (N, CO, OH, OW)
# define packing
data_vec = tvm.compute(dvshape, lambda n, h, w, ci, vh, vw:
data_pad[n][ci][h*VH*H_STRIDE+vh][w*VW*W_STRIDE+vw], name='data_vec')
kernel_vec = tvm.compute(kvshape, lambda co, ci, kh, kw, vc:
kernel[co*VC+vc][ci][kh][kw], name='kernel_vec')
# define convolution
ci = tvm.reduce_axis((0, CI), name='ci')
kh = tvm.reduce_axis((0, KH), name='kh')
kw = tvm.reduce_axis((0, KW), name='kw')
conv = tvm.compute(ovshape, lambda n, co, h, w, vh, vw, vc:
tvm.sum(data_vec[n, h, w, ci, vh*H_STRIDE+kh, vw*W_STRIDE+kw].astype(out_dtype) *
kernel_vec[co, ci, kh, kw, vc].astype(out_dtype),
axis=[ci, kh, kw]), name='conv')
# unpack to correct layout
output = tvm.compute(oshape, lambda n, co, h, w:
conv[n][co//VC][h/VH][w//VW][h%VH][w%VW][co%VC],
name='output_unpack', tag='direct_conv_output')
用以下命令检查定义的IR:
print(tvm.lower(s, [data, kernel, output], simple_mode=True))
选择卷积的部分:
produce conv {
for (co, 0, 64) {
for (h, 0, 56) {
for (w, 0, 14) {
for (vw.init, 0, 4) {
for (vc.init, 0, 4) {
conv[((((((((co*56) + h)*14) + w)*4) + vw.init)*4) + vc.init)] = 0.000000f
}
}
for (ci, 0, 256) {
for (kh, 0, 3) {
for (kw, 0, 3) {
for (vw, 0, 4) {
for (vc, 0, 4) {
conv[((((((((co*56) + h)*14) + w)*4) + vw)*4) + vc)] = (conv[((((((((co*56) + h)*14) + w)*4) + vw)*4) + vc)] + (data_vec[(((((((((h*14) + w)*256) + ci)*3) + kh)*6) + kw) + vw)]*kernel_vec[((((((((co*256) + ci)*3) + kh)*3) + kw)*4) + vc)]))
}
}
}
}
}
}
}
}
}
Kernel 1:绑定线程
在TVM中,我们先计算,再计划(schedule),这便于分离算法和实现细节。
如代码所示,我们简单把axes坐标轴对应到GPU线程,之后就能在Mali GPU上跑代码了。
# helper function for binding thread
def tile_and_bind3d(s, tensor, z, y, x, z_factor=2, y_factor=None, x_factor=None):
""" tile and bind 3d """
y_factor = y_factor or z_factor
x_factor = x_factor or y_factor
zo, zi = s[tensor].split(z, z_factor)
yo, yi = s[tensor].split(y, y_factor)
xo, xi = s[tensor].split(x, x_factor)
s[tensor].bind(zo, tvm.thread_axis("blockIdx.z"))
s[tensor].bind(zi, tvm.thread_axis("threadIdx.z"))
s[tensor].bind(yo, tvm.thread_axis("blockIdx.y"))
s[tensor].bind(yi, tvm.thread_axis("threadIdx.y"))
s[tensor].bind(xo, tvm.thread_axis("blockIdx.x"))
s[tensor].bind(xi, tvm.thread_axis("threadIdx.x"))
# set tunable parameter
num_thread = 8
# schedule data packing
_, h, w, ci, vh, vw = s[data_vec].op.axis
tile_and_bind3d(s, data_vec, h, w, ci, 1)
# schedule kernel packing
co, ci, kh, kw, vc = s[kernel_vec].op.axis
tile_and_bind(s, kernel_vec, co, ci, 1)
# schedule conv
_, c, h, w, vh, vw, vc = s[conv].op.axis
kc, kh, kw = s[conv].op.reduce_axis
s[conv].reorder(_, c, h, w, vh, kc, kh, kw, vw, vc)
tile_and_bind3d(s, conv, c, h, w, num_thread, 1, 1)
_, co, oh, ow = s[output].op.axis
tile_and_bind3d(s, output, co, oh, ow, num_thread, 1, 1)
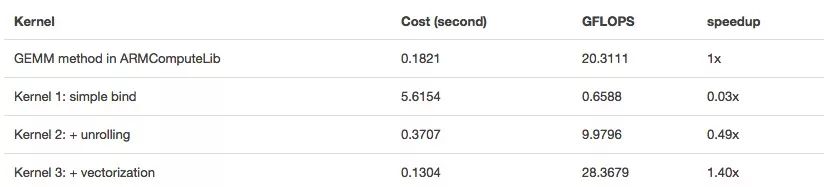
虽然有了这个schedule,我们现在可以运行代码了,但它的性能要求还是相当可怕。

Kernel 2:unroll
循环展开(loop unrolling)是一个常用的优化方法,它能通过减少循环控制指令降低循环本身的开销,同时因为能消除分支以及一些管理归纳变量的代码,它也可以摊销一些分支开销,此外,它还能掩盖读取内存的延迟。在TVM中,你可以调用s.unroll(axis)实现循环展开。
# set tunable parameter
num_thread = 8
# schedule data packing
_, h, w, ci, vh, vw = s[data_vec].op.axis
tile_and_bind3d(s, data_vec, h, w, ci, 1)
"""!! ADD UNROLL HERE !!"""
s[data_vec].unroll(vw)
# schedule kernel packing
co, ci, kh, kw, vc = s[kernel_vec].op.axis
tile_and_bind(s, kernel_vec, co, ci, 1)
"""!! ADD UNROLL HERE !!"""
s[kernel_vec].unroll(kh)
s[kernel_vec].unroll(kw)
s[kernel_vec].unroll(vc)
# schedule conv
_, c, h, w, vh, vw, vc = s[conv].op.axis
kc, kh, kw = s[conv].op.reduce_axis
s[conv].reorder(_, c, h, w, vh, kc, kh, kw, vw, vc)
tile_and_bind3d(s, conv, c, h, w, num_thread, 1, 1)
"""!! ADD UNROLL HERE !!"""
s[conv].unroll(kh)
s[conv].unroll(kw)
s[conv].unroll(vw)
s[conv].unroll(vc)
_, co, oh, ow = s[output].op.axis
tile_and_bind3d(s, output, co, oh, ow, num_thread, 1, 1)

Kernel 3:向量化(vectorization)
如前所述,为了在Mali GPU上实现最佳性能,我们还要把数字转成矢量。
# set tunable parameter
num_thread = 8
# schedule data packing
_, h, w, ci, vh, vw = s[data_vec].op.axis
tile_and_bind3d(s, data_vec, h, w, ci, 1)
# unroll
s[data_vec].unroll(vw)
# schedule kernel packing
co, ci, kh, kw, vc = s[kernel_vec].op.axis
tile_and_bind(s, kernel_vec, co, ci, 1)
# unroll
s[kernel_vec].unroll(kh)
s[kernel_vec].unroll(kw)
"""!! VECTORIZE HERE !!"""
s[kernel_vec].vectorize(vc)
# schedule conv
_, c, h, w, vh, vw, vc = s[conv].op.axis
kc, kh, kw = s[conv].op.reduce_axis
s[conv].reorder(_, c, h, w, vh, kc, kh, kw, vw, vc)
tile_and_bind3d(s, conv, c, h, w, num_thread, 1, 1)
# unroll
s[conv].unroll(kh)
s[conv].unroll(kw)
s[conv].unroll(vw)
"""!! VECTORIZE HERE !!"""
s[conv].vectorize(vc)
_, co, oh, ow = s[output].op.axis
tile_and_bind3d(s, output, co, oh, ow, num_thread, 1, 1)
如何设置可调参数
上文中涉及的一些可调参数是可以被计算出来的,如向量vc,如果是float32,|vc|=128/32=4;如果是float16,则是128/16=8。
但由于运行时间过长,很多时候我们会无法确定最佳值。TVM使用的是网格搜索,所以如果用的是python,而不是OpenCL的话,我们也能快速找到最佳值。
端到端的Benchmark
在这一节中,我们比较了一些流行深度神经网络在不同后端上的综合性能,测试环境是:
Firefly-RK3399 4G
CPU: dual-core Cortex-A72 + quad-core Cortex-A53
GPU: Mali-T860MP4
ArmComputeLibrary : v17.12
MXNet: v1.0.1
Openblas: v0.2.18
我们使用NNVM和TVM进行端到端编译。
性能
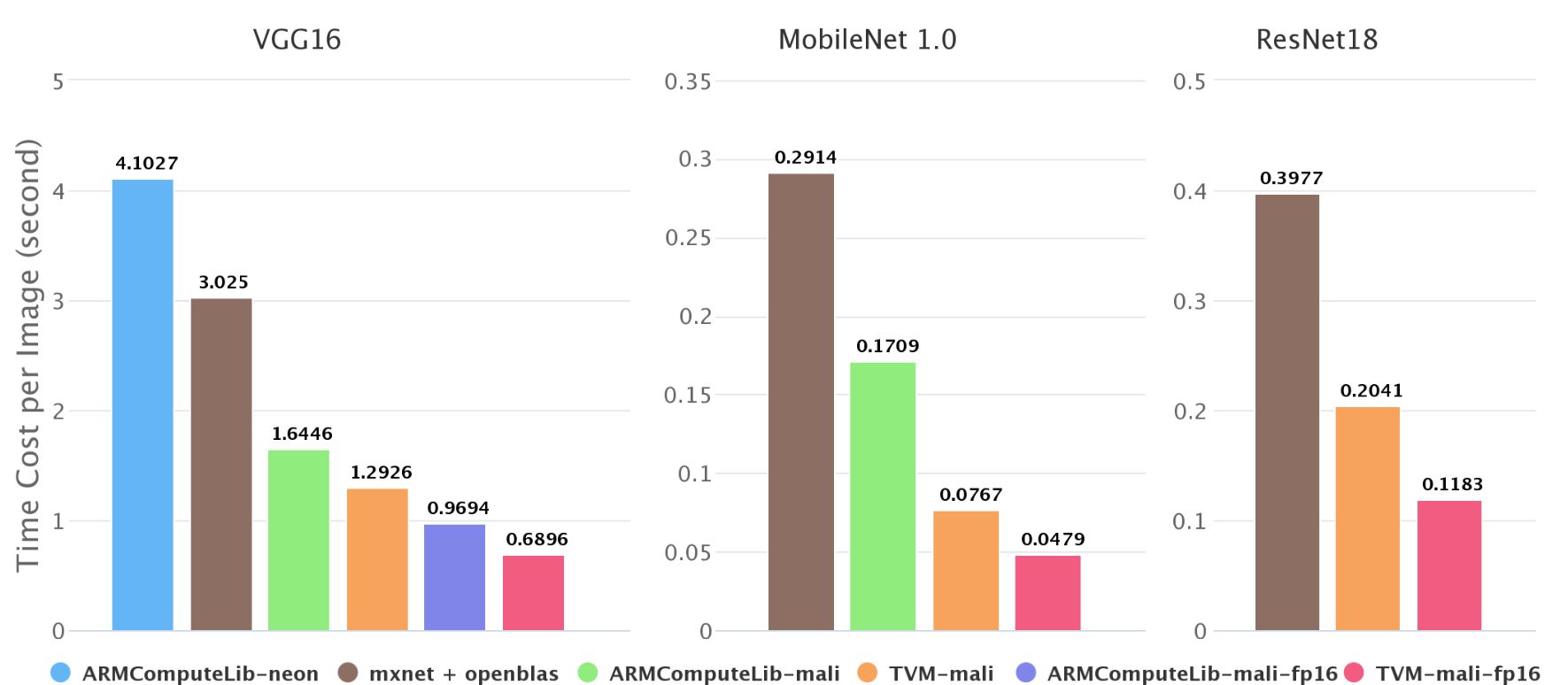
ImageNet上不同后端的inference速度
如上图所示,我们在ImageNet测试了移动端神经网络的inference速度,发现在Firefly-RK3399上,Mali GPU可以比6核big.LITTLE CPU快2—4倍,我们的端到端编译速度比Arm Compute Library快了1.4—2.2倍。在Arm Compute Library中,我们比较了用GEMM计算卷积和直接计算卷积,发现前者速度始终更快,所以在图中只展示了GEMM方法的成果。
上图中也有一些数据缺失,如第二幅图不包含Arm Compute Library上的resnet18。这是因为Arm Compute Library的graph runtime目前不支持跳转连接,并且Neon在上面的实现性能不太好。这也从侧面反映了NNVM软件栈的优势。
半精度性能
深度神经网络对精度要求不高,尤其是对于计算资源捉襟见肘的移动设备,降低精度可以加快神经网络的inference速度。我们还计算了Mali GPU上的半精度浮点数。
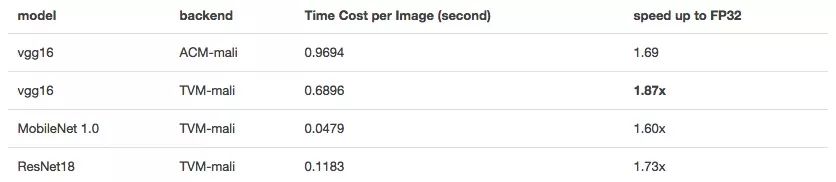
mageNet上FP16的inference速度
从理论上讲,FP16既可以实现双峰计算,又可以将内存消耗减半,从而使速度提高一倍。但是如果涉及较长的向量化和某些参数的微调,它也需要良好的输入形态。
-
ARM
+关注
关注
134文章
9105浏览量
367916 -
gpu
+关注
关注
28文章
4745浏览量
129020 -
深度学习
+关注
关注
73文章
5506浏览量
121259 -
TVM
+关注
关注
0文章
19浏览量
3675
原文标题:上海交大团队:如何用TVM优化ARM架构GPU,在移动端实现快速深度学习
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
移动互联网的发展需要移动电源的支持
移动互联网的发展需要移动电源的支持
三地联动 Qualcomm邀您探索移动应用图像进阶之路
动态分配多任务资源的移动端深度学习框架
TVM整体结构,TVM代码的基本构成
如何实现嵌入式平台与深度学习的智能气象监测仪器的设计
Mali GPU支持tensorflow或者caffe等深度学习模型吗
移动GPU助力智能化 如何评判好的移动GPU?
小米自研开源移动端深度学习框架MACE
小米AI移动端深度学习框架MACE开源了!
TVM学习(三)编译流程






 工商网监
工商网监
评论