 用TensorFlow制作一个图像识别工具的构建步骤解析
用TensorFlow制作一个图像识别工具的构建步骤解析
编者按:本文作者Sara Robinson在Medium上发布了一个有趣的项目,她自制了一款APP,能自动识别歌手Taylor Swift。这与我们之前介绍的寻找威利项目很像。该教程非常详细,有兴趣的同学可以学习一下,动手做一个自己的图像识别工具哦~本文已获作者授权,以下是对原文的编译。
注:由于写作本文时TensorFlow没有Swift库,我用Swift构建了针对我的模型的预测请求的APP。
以下就是我们创建的APP:
TensorFlow物体检测API能让你识别出一张图片中特定物体的位置,这可以应用到许多有趣的程序上。不过我平常拍人比较多,所以就想把这一技术应用到人脸识别上。结果发现模型表现得非常好!也就是上图我创建的Taylor Swift检测器。
本文将列出模型的构建步骤,从收集Taylor Swift的照片到模型的训练:
对图像进行预处理,改变大小、贴标签、将它们分成训练和测试两部分,并修改成Pascal VOC格式;
将图片转化成TFRecords文件以符合物体检测API;
利用MobileNet在谷歌Cloud ML Engine上训练模型;
导出训练好的模型并将其部署到ML Engine上进行服务;
构建一个iOS前端,根据训练好的模型做出预测请求(使用Swift)。
下面是各部分如何结合在一起的架构图:
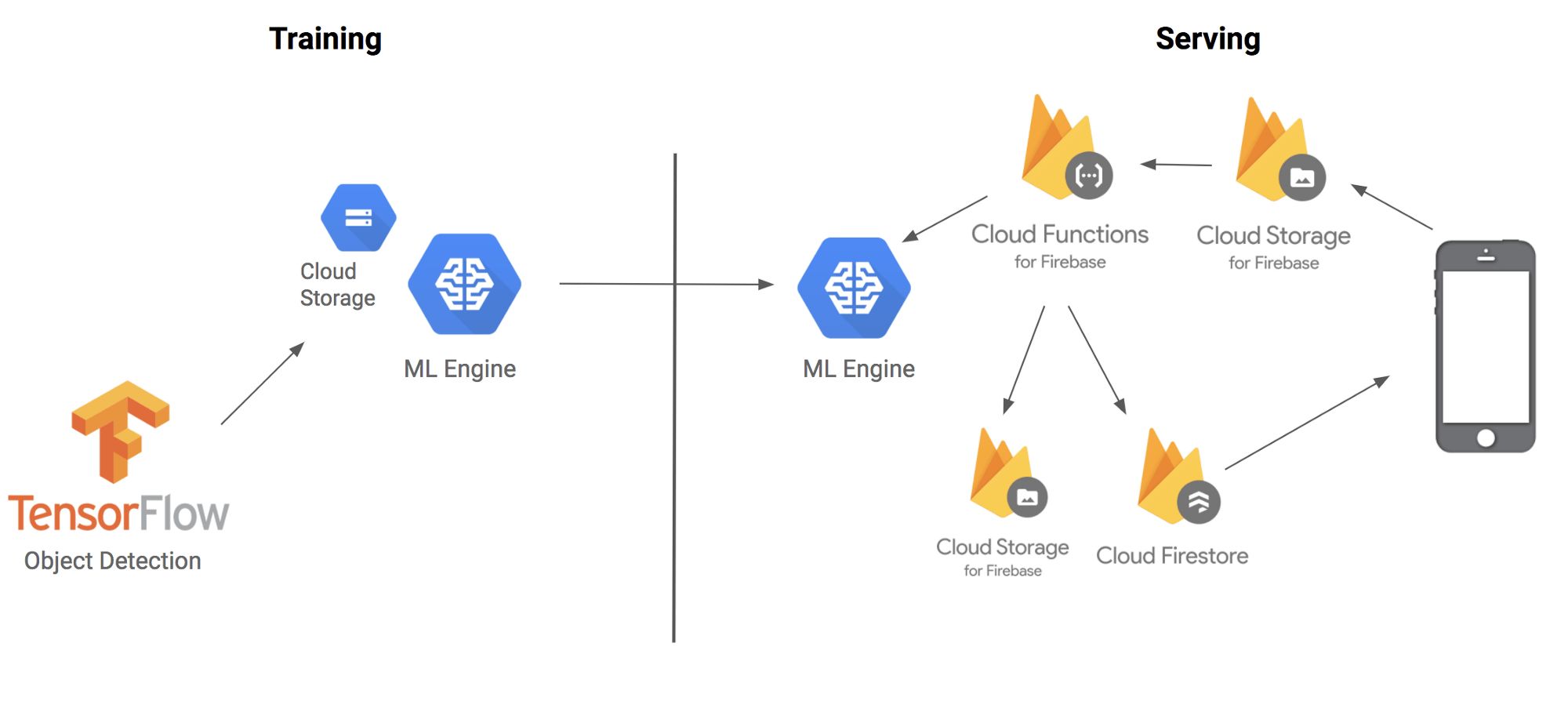
在开始之前,首先要解释一下我们即将用到的技术和术语:TensorFlow物体检测API是一个构建在TensorFlow上的框架,用于识别图像中特定的对象。例如,你可以用很多猫的照片训练它,一旦训练完毕,你可以输入一张猫的图像,它就会输出一个方框列表,认为图像中有一只猫。虽然它的名字中含有API,但是你可以将它更多地想象成用于迁移学习的一套便利的工具。
但是,训练模型识别图像中的对象是个费时费力的活。物体检测最酷的地方就是它支持五个预训练模型的迁移学习(transfer learning),那么什么是迁移学习呢?比如,当儿童学习第一门语言时,他们会接触大量的例子,如果有错就会立刻被纠正过来。例如当孩子们学习识别猫时,他们的父母会指着图片上的猫,并说出“猫”这个词,这种重复增强了他们的脑回路。当它们学习如何识别一只狗时,无需从头开始,这一过程与猫的识别类似,只是学习对象不同。这就是迁移学习的工作原理。
但我没有时间寻找并标记数千个Taylor Swift的图像,但是我可以通过修改最后几个图层、在数百万张图像上训练的模型中提取特征,应用于TSwift的检测。
第一步:预处理图像
首先要感谢Dat Tran写的关于浣熊检测器的博客,地址:https://towardsdatascience.com/how-to-train-your-own-object-detector-with-tensorflows-object-detector-api-bec72ecfe1d9
首先,我从谷歌图片上下载了200张Taylor Swift的照片,这里安利一个Chrome插件:Fatkun Batch Download Image,可以下载所有图片搜索结果。在打标签之前,我把图片分为两类:训练和测试。另外,我写了一个调整图片大小的脚本(https://github.com/sararob/tswift-detection/blob/master/resize.py),确保每张图的宽度不超过600px。
由于检测器会告诉我们图中的对象位置,所以你不能直接把图像和标签作为训练数据。你需要用边框将对象圈出来,以及将表框打上标签(在我们的数据集中,只需要一个标签tswift)。
打边框工具依然使用LabelImg,这是一个基于Python的程序,你只需输入带标签的图像,它就会输出一个xml文件,将每张照片都打上边框同时还有相关标签(不到一上午我就处理好200张图片了)。下面是它如何工作的(标签输入为tswift):
然后LabelImg生成一个xml文件:
现在我有了一张带有边框和标签的图片了,但是我还要把它转换成TensorFlow可接受的方式——一个数据的二进制表示TFRecord。关于这一方法可以在GitHub上查看。要运行我的脚本,你需要先下载一个tensorflow/models,从tensorflow/models/research本地直接运行脚本,带上以下参数(运行两次:一次用于训练数据,一次用于测试数据)
python convert_labels_to_tfrecords.py
--output_path=train.record
--images_dir=path/to/your/training/images/
--labels_dir=path/to/training/label/xml/
第二步:训练检测器
我可以在笔记本电脑上训练这个模型,但是时间会很长,而且占用大量的资源。并且一旦我需要用电脑做别的事,训练就会中断。所以,我选择了云!我们可以利用云来运行多个跨核心的训练,几个小时内就能完成整个工作,并且用Cloud ML engine的速度比GPU还要快。
设置Cloud ML Engine
我准备将所有TFRecord格式的数据上传到云并开始训练。首先,我在谷歌云端控制台中创建了一个项目,并启用了Cloud ML Engine:
然后,我将创建一个云存储bucket来打包模型的所有资源。确保在指定区域进行存储(不要选择多个区域):

我将在这个bucket中/data子目录来放置训练和测试TFRecord的文件:

目标对象检测API还需要一个将标签映射到整数ID的pbtxt文件。由于我们只有一个标签,这个是非常短的:
item {
id: 1
name: 'tswift'
}
添加MobileNet检查点进行迁移学习
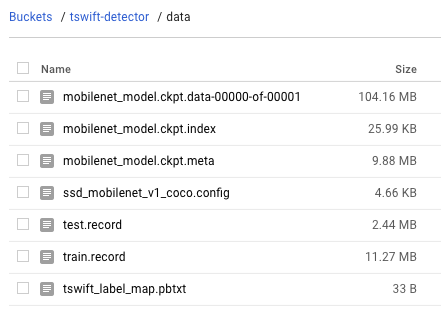
因为我并非从零开始训练这个模型,所以当我运行训练时,我需要指向我将要建立的预训练模型。我选择使用MobileNet模型——它是针对移动设备优化的一系列小模型。虽然我不会直接在移动设备上训练模型,但MobileNet将会快速训练,并允许更快的预测请求。我下载了这个MobileNet检查点用于训练,检查点是一个二进制文件,包含训练过程中特定点的TensorFlow模型的状态。下载并解压缩后,你可以看到它包含的三个文件:

以上所有都要用来训练模型,所以我将它们放在云存储bucket中的同一个data/目录中。
在开始训练之前,还需要添加一个文件。对象检测脚本需要一种方法查找模型的检查点、标签映射和训练数据。我们将用配置文件处理这一点。TF对象检测为五个预训练模型采集了样本配置文件。我们在这里为MobileNet使用一个,并且在云存储bucket的相应路径中更新了所有PATH_TO_BE_CONFIGURED占位符。除了将我的模型连接到云存储中的数据外,此文件还为我的模型配置了几个超参数,如卷积大小、激活函数和步骤。
以下是开始训练之前云存储bucket中我的/data中的所有文件:
我还会在bucket中创建train/和eval/子目录——这是TensorFlow在训练和评估时书写模型检查点文件的地方。
现在已经准备好训练了,通过执行gcloud命令开始。请注意,你需要在本地复制tensorflow/models/research并从该目录运行此训练脚本:
# Run this script from tensorflow/models/research:
gcloud ml-engine jobs submit training ${YOUR_TRAINING_JOB_NAME}
--job-dir=${YOUR_GCS_BUCKET}/train
--packages dist/object_detection-0.1.tar.gz,slim/dist/slim-0.1.tar.gz
--module-name object_detection.train
--region us-central1
--config object_detection/samples/cloud/cloud.yml
--runtime-version=1.4
--
--train_dir=${YOUR_GCS_BUCKET}/train
--pipeline_config_path=${YOUR_GCS_BUCKET}/data/ssd_mobilenet_v1_coco.config
训练的同时,我也开始了评估工作。我会使用之前从未见过的数据来评估模型的准确性:
# Run this script from tensorflow/models/research:
gcloud ml-engine jobs submit training ${YOUR_EVAL_JOB_NAME}
--job-dir=${YOUR_GCS_BUCKET}/train
--packages dist/object_detection-0.1.tar.gz,slim/dist/slim-0.1.tar.gz
--module-name object_detection.eval
--region us-central1
--scale-tier BASIC_GPU
--runtime-version=1.4
--
--checkpoint_dir=${YOUR_GCS_BUCKET}/train
--eval_dir=${YOUR_GCS_BUCKET}/eval
--pipeline_config_path=${YOUR_GCS_BUCKET}/data/ssd_mobilenet_v1_coco.config
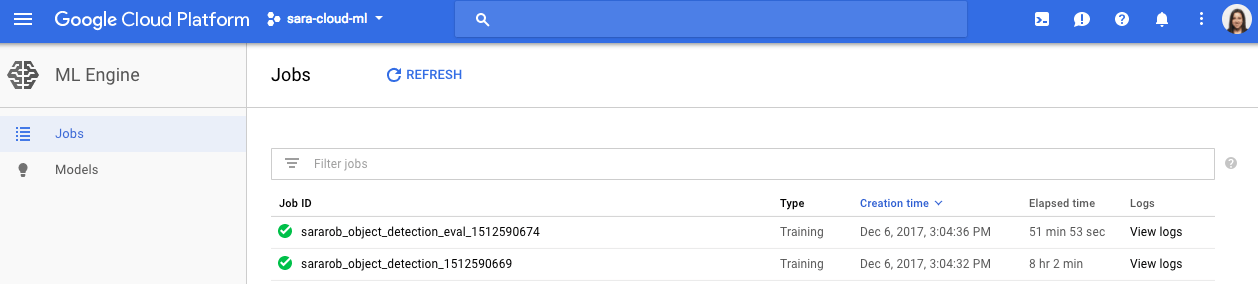
你可以通过在云端控制台导航到ML Engine的“作业”部分来验证您的任务是否正确运行,并检查日志以查找特定作业:
第三步:部署预测模型
为了将模型部署到ML Engine,我需要将模型检查点转换为ProtoBuf。在我的train/bucket中,可以看到从几处保留的检查点文件:

文件的第一行告诉我最新的检查点路径——我应从该检查点本地下载3个文件。每个检查点应该有一个.index,.meta,和.data文件。将它们保存在本地目录中后,我可以使用对象检测的export_inference_graph脚本将它们转换为ProtoBuf。要运行以下脚本,你需要定义MobileNet配置文件的本地路径、训练时下载的模型检查点编号以及要导出的图形目录名称:
# Run this script from tensorflow/models/research:
python object_detection/export_inference_graph.py
--input_type encoded_image_string_tensor
--pipeline_config_path ${LOCAL_PATH_TO_MOBILENET_CONFIG}
--trained_checkpoint_prefix model.ckpt-${CHECKPOINT_NUMBER}
--output_directory ${PATH_TO_YOUR_OUTPUT}.pb
这个脚本运行后,你将会在.pb输出目录中看到一个saved_model/目录。将saved_model.pb文件上传到你的云存储/data目录中(不要担心生成其他文件)。
现在你已经准备好将模型部署到ML Engine上了。首先,用gcloud创建你的模型:
gcloud ml-engine models create tswift_detector
然后,通过将模型指向刚刚上传到云存储的已保存的ProtoBuf来创建第一个模型版本:
gcloud ml-engine versions create v1 --model=tswift_detector --origin=gs://${YOUR_GCS_BUCKET}/data --runtime-version=1.4
模型部署好后,我将用ML Engine的线上预测API生成新的预测图像。
第四步:使用Firebase函数和Swift构建预测客户端
我在Swift中编写了一个iOS客户端来对我的模型进行预测请求。Swift客户端将图像上传到云存储,云存储触发Firebase函数,在Node.js中发起预测请求,并将生成的预测图像和数据保存到云存储和Firebase中。
首先,在我的Swift客户端中,我添加了一个按钮,供用户访问设备的图片库。用户选择照片后,会触发将图像上传到云端存储的操作:
let firestore = Firestore.firestore()
func imagePickerController(_ picker: UIImagePickerController, didFinishPickingMediaWithInfo info: [String : Any]) {
let imageURL = info[UIImagePickerControllerImageURL] as? URL
let imageName = imageURL?.lastPathComponent
let storageRef = storage.reference().child("images").child(imageName!)
storageRef.putFile(from: imageURL!, metadata: nil) { metadata, error in
if let error = error {
print(error)
} else {
print("Photo uploaded successfully!")
// TODO: create a listener for the image's prediction data in Firestore
}
}
}
dismiss(animated: true, completion: nil)
}
接下来,我编写了在上传到云存储时触发的Firebase函数(https://github.com/sararob/tswift-detection/blob/master/firebase/functions/index.js)。下面的代码也包含了我向ML Engine预测API发出请求的函数部分:
function cmlePredict(b64img, callback) {
return new Promise((resolve, reject) => {
google.auth.getApplicationDefault(function (err, authClient, projectId) {
if (err) {
reject(err);
}
if (authClient.createScopedRequired && authClient.createScopedRequired()) {
authClient = authClient.createScoped([
'https://www.googleapis.com/auth/cloud-platform'
]);
}
var ml = google.ml({
version: 'v1'
});
const params = {
auth: authClient,
name: 'projects/sara-cloud-ml/models/tswift_detector',
resource: {
instances: [
{
"inputs": {
"b64": b64img
}
}
]
}
};
ml.projects.predict(params, (err, result) => {
if (err) {
reject(err);
} else {
resolve(result);
}
});
});
});
}
在ML Engine的反应中,我们得到:
detection_boxes:可以用来标出Taylor Swift周围的边框;
detection_scores:为每个检测框架返回一个置信度值,其中只包括分数高于70%的检测;
detection_classes:告诉我们与检测相关的ID。在这种情况下,因为只有一个标签所以该值总为1。
在函数中,如果检测到Taylor,则用detection_boxes在图像中绘制一个边框以及生成置信度分数。然后将新的带有边框的图像保存到云中,将图像的文件路径写入Cloud Firestore,一边在iOS应用程序中读取路径并下载新图像:
const admin = require('firebase-admin');
admin.initializeApp(functions.config().firebase);
const db = admin.firestore();
let outlinedImgPath = `outlined_img/${filePath.slice(7)}`;
let imageRef = db.collection('predicted_images').doc(filePath);
imageRef.set({
image_path: outlinedImgPath,
confidence: confidence
});
bucket.upload('/tmp/path/to/new/image', {destination: outlinedImgPath});
最后,在iOS应用程序中,我们可以监测图像Firestore路径的更新。如果检测到目标,我会下载这张图片并在应用程序中显示这张图以及可信度分数。这个函数将替换上一个代码片段中的注释:
self.firestore.collection("predicted_images").document(imageName!)
.addSnapshotListener { documentSnapshot, error in
if let error = error {
print("error occurred(error)")
} else {
if (documentSnapshot?.exists)! {
let imageData = (documentSnapshot?.data())
self.visualizePrediction(imgData: imageData)
} else {
print("waiting for prediction data...")
}
}
}
好了!现在我们有一款Taylor Swift检测器了!注意,由于模型只用了140张图像进行训练,所以准确度不够高,可能会把其他人误认为是Taylor。但是,如果有时间的话,我会收集更多贴有标签的图片,并更新模型,发布到应用商店里。
-
图像识别
+关注
关注
9文章
520浏览量
38267 -
SWIFT
+关注
关注
0文章
116浏览量
23798 -
tensorflow
+关注
关注
13文章
329浏览量
60527
原文标题:教程帖:用TensorFlow自制Taylor Swift识别器
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
使用Python卷积神经网络(CNN)进行图像识别的基本步骤
基于DSP的快速纸币图像识别技术研究
【瑞芯微RK1808计算棒试用申请】图像识别以及芯片评测
研发干货丨基于OK3399-C平台android系统下实现图像识别

基于TensorFlow和Keras的图像识别






 工商网监
工商网监
评论