 可编程交换机如何无缝卸载集体操作
可编程交换机如何无缝卸载集体操作
*本文系SDNLAB编译自Juniper技术专家兼高级工程总监Sharada Yeluri博客
在本文中,Juniper技术专家兼高级工程总监Sharada Yeluri深入研究了 AI/ML 训练/推理中使用的集体操作,并讨论如何将其中一些功能卸载到网络交换机上,以减少拥塞并提高结构的性能。最后,Sharada Yeluri 以Juniper 的 Trio 架构为例,展示了可编程交换机如何无缝卸载集体操作。
什么是“集体操作”?
在由众多通过互联结构相连的处理节点(如GPU)构成的并行/分布式计算系统中,“集体操作”是指涉及一组处理节点间通信的一系列操作,用于执行协调性的任务。这些任务可能包括将数据从一个节点分发给所有节点、将所有节点的数据收集到一个节点、聚合所有节点之间的数据等。
深度学习框架支持库,可实现 GPU 组之间的集体通信。Nvidia的集体通信库(NCCL)针对其GPU架构高效地实现了集体操作。当一个模型在一组GPU之间进行分区时,NCCL负责管理它们之间的所有通信。
下面是常用的集体操作:
Reduce:从所有节点聚合数据(求和或平均)并将结果发送给其中一个节点。
AllReduce:聚合所有节点的数据,并将结果发送回所有节点。
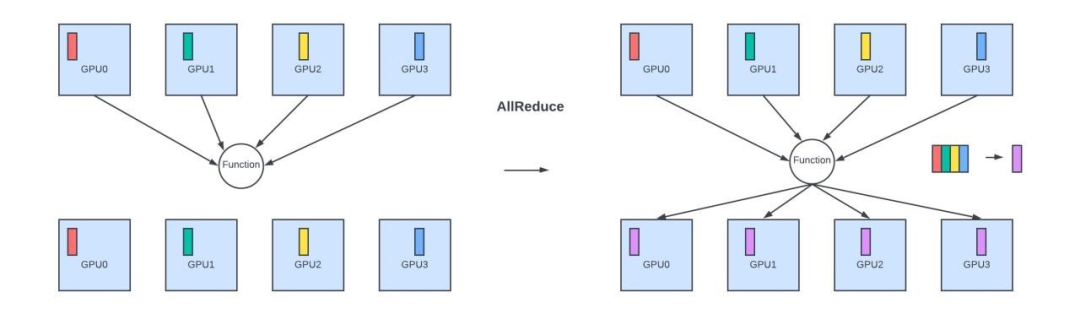
AllReduce
ReduceScatter:聚合所有节点的数据,并将结果(每个节点获得结果的唯一子集)分发到所有节点。
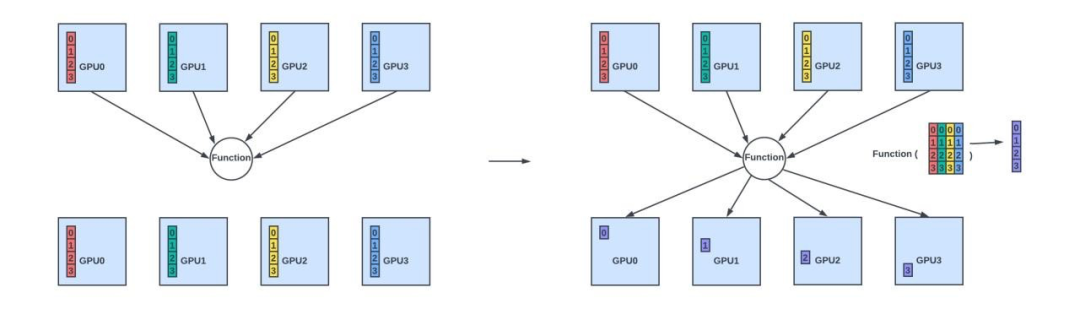
ReduceScatter
广播:将数据从一个节点发送到组中的所有其他节点。
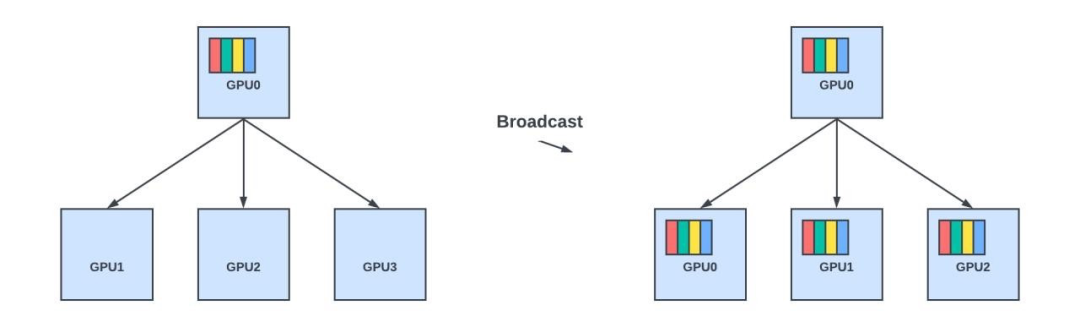
广播
AllGather:收集数据的不同部分,并将其分发给所有节点。
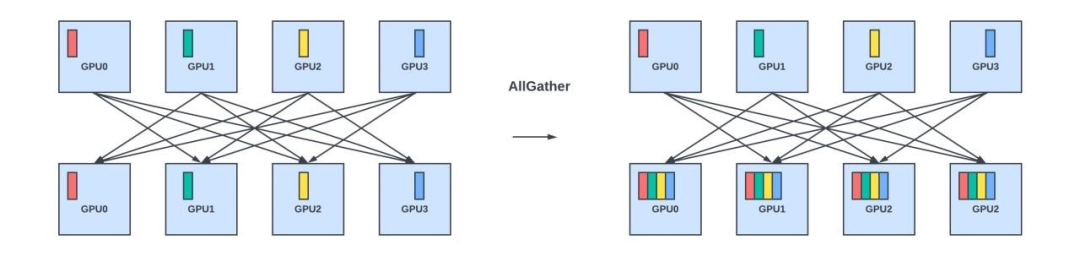
Scatter:将一个节点的不同值分发到所有节点。
AlltoAll:将所有节点的数据分发到所有节点。
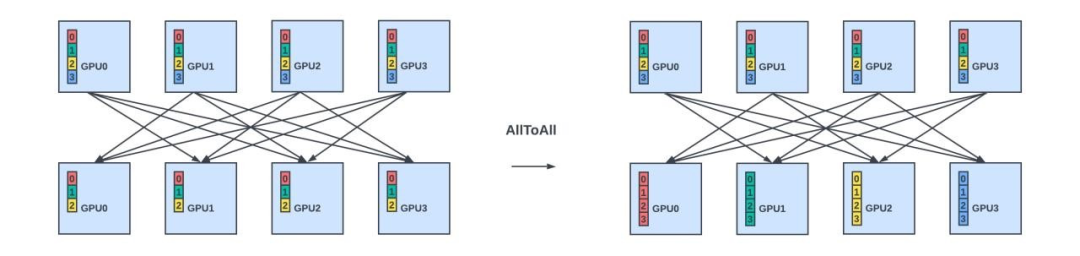
有些集体操作可以通过使用集体操作的组合来实现。例如,AllReduce可以实现为先执行ReduceScatter操作,然后再执行AllGather操作。
AI/ML 框架中的集体操作
NCCL 实现了多种集体操作算法,包括环形(Ring)、树形(Tree)以及双二叉树(Double Binary Trees)等,根据数据大小、涉及的 GPU 数量和网络拓扑自动选择最为高效的算法。这些算法旨在优化集体操作中的数据传输。
例如,在使用AllReduce集体操作进行梯度聚合时,梯度可以按照环形模式从一个 GPU 发送到另一个 GPU,其中每个GPU都会将其从上一个GPU接收到的梯度与其本地计算出的梯度进行聚合,然后再将结果发送给下一个GPU。这个过程很慢,因为梯度聚合是按顺序完成的,最终的结果也会按顺序在环形拓扑中传回到所有 GPU。
在AllReduce集体操作中,GPU也可以排列为二叉树结构。在这个结构中,每个叶节点将其存储的所有参数的梯度发送到其父节点,父节点则会将接收到的梯度与来自其兄弟叶节点的对应梯度进行求和。此过程以递归方式继续,直到所有梯度在树的根节点处聚合。在根节点拥有所有梯度的总和后,必须将聚合梯度发送回该树中的所有节点,以更新其模型参数的本地副本。根节点首先将聚合梯度发送给其子节点,子节点再依次传递给它们的子节点,如此递归进行,直到所有节点都收到了更新后的梯度。
下图展示了7个GPU以二叉树的形式排列以进行梯度聚合。假设这些 GPU 是连接到不同叶交换机和主干交换机的大型网络拓扑的一部分。该图还显示了 GPU 之间梯度聚合的流量模式。在网络中,这些交换机是被动设备,负责转发GPU之间的通信结果。
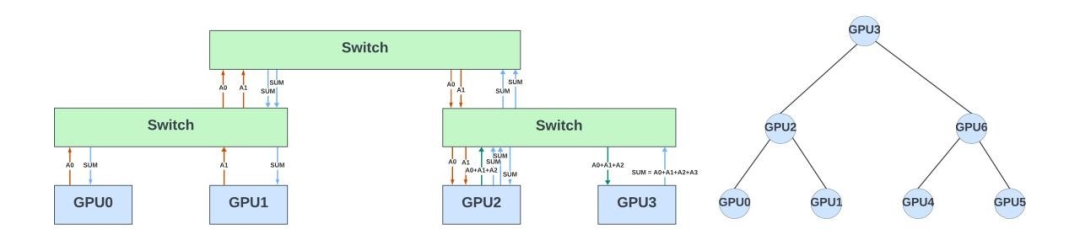
梯度聚合流量(仅显示 4 个 GPU)
集体操作的卸载
如果网络交换机可以帮助卸载部分或全部的集体操作,结果会怎样?在这个例子中,每个交换机可以对从属于AllReduce集体操作的 GPU 接收到的梯度进行部分求和,并将结果传递给下一层级的交换机。最终的结果将广播给该集体内的所有GPU。
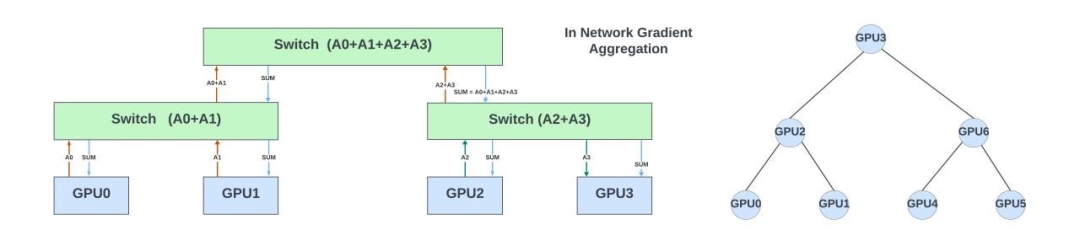
上图展示了网内聚合如何加速梯度聚合过程:通过减少数据跳转次数(从而降低延迟)和减轻网络流量。
这样做可以减少此集体操作的延迟和网络拥塞。它还可以在训练期间卸载 GPU 计算资源以专注于更重要的任务。同样,AllGather和Broadcast这两种集体操作也能从在网络交换机中卸载任务中获益。
Nvidia 在其 InfiniBand 和 NVLink 交换机中通过 SHARP(可扩展层次聚合和归约协议)支持此功能。SHARP的主要目标是在网络内部直接卸载并加速复杂的集体操作,减少需要在网络上传输的数据量,从而降低整体的通信时间。SHARP是一个专有的协议,仅与Nvidia的InfiniBand/ NVLink交换机兼容。它在Nvidia的 AI 堆栈中无缝运作。
深度学习框架,如TensorFlow和PyTorch,通常依赖于MPI(消息传递接口)或NCCL来进行集体操作。Nvidia 确保这些框架能够利用SHARP来获得网络内计算的性能优势。然而,Nvidia 并未公开发布SHARPv3集体操作前后性能改进的具体对比结果。不过,一些关于早期SHARP版本的文章显示,使用SHARP后,训练性能得到了17%-20%的提升。
以太网结构和在网集体操作
在使用 ROCEv2 进行 GPU间通信的以太网结构,目前尚未有任何针对在网集体操作 (INC) 的开放标准。超以太网联盟(UEC)正在开发一种新的传输协议 (UET) 及其配套的INC。一旦标准成熟,这项技术有可能被交换机和AI框架采纳。然而,从任何标准发布到其原生部署在网络设备硬件中,通常会有3-4年的滞后期。并且,要对硬件进行这些功能的优化,往往需要经历几代产品的发展周期。
在数据平面交换机中执行INC需要硬件对各种操作的支持。
解析新协议/数据包格式,以确定数据包是否是集体操作的一部分。
能够深入查看数据包并提取所有有效载荷进行处理。
能够对有效载荷进行操作,并跨多个数据包累积结果。这需要支持各种浮点/整数格式的算术运算,而以太网交换机通常不具备这些功能。
能够从内存中读取累积的结果,创建新的数据包并将其发送出去。
能够处理拥塞并为集合操作流量维护QoS,特别是在芯片中发生多个并行集合操作时。
能够从网络或链路错误中恢复,并在集体操作因网络故障、链路问题或落后的GPU而导致失败时,通知终端主机。
有几种方法可以实现上述的集体操作。
在交换机硬件中直接实现原生支持始终是最高效的方式。然而,在交换机制造商考虑添加此类功能之前,相关标准和技术规范需要进一步成熟和完善。若这些交换机旨在满足广泛的应用需求,则额外的芯片面积和成本可能会成为其在AI/ML应用之外推广的阻碍。
另一种方法是将集体操作卸载到连接到交换机的协处理器上。这些协处理器可以包含 CPU 核心,通过在其上运行的软件来实现集体操作。或者,它们可以是具有集体处理原生功能的FPGA/ASIC。协处理器通常只处理一部分WAN带宽,以保持较低的成本。这种做法可以让以太网交换机保持轻量化和能效,同时使数据中心能够选择性地在某些交换机上卸载集体操作。
这些交换机能灵活地解析新报头和有效载荷。此外,由于几乎不需要硬件变更,可编程交换机能够迅速实现新标准,并具备支持多种集体操作协议的能力。然而,这些交换机的带宽往往较低(通常为常规交换机的5到10倍),因此对于构建大型网络结构来说,成本效益不高。尽管如此,这些交换机可以作为主高带宽交换机的协处理器,协助卸载集体操作和其他处理任务。
在后文中,将以Juniper 的 Trio 架构(用于 MX 系列路由器/交换机)为例,解释如何在具有灵活数据包处理引擎的可编程交换机中实现集体操作。这部分内容主要基于MIT研究人员与瞻博网络合作发表的SIGCOMM论文。
使用 Trio 进行在网计算
Trio 概述
Trio6拥有1.6Tbps的带宽。其查找子系统包含多个包处理引擎 (PPE) 和加速器,用于执行哈希/记录、锁定和过滤器等特殊功能。通过使用高带宽交叉开关(cross bar),PPE 可与加速器和内存子系统进行通信。
每个 PPE 都是一个 256 位宽的 VLIW 微码引擎。它具有 8-stage执行pipeline,可以同时支持多个线程(20+)。PPE遵循桶式 pipeline架构,这意味着线程在任何时候只能处于单个 pipeline阶段。这种设计简化了旁路逻辑,创造出一个在面积和功耗上更优的优化方案。PPE 针对更高的总吞吐量进行了优化。每个微码指令可以控制多个算术逻辑单元(ALU)、支持多种操作数选择方式、结果路由以及复杂的多路分支,从而实现了丰富的包处理功能。
当数据包到达时,前大约 200B 会被发送到一个空闲的 PPE 线程进行处理。如果需要更深入地检查数据包,PPE 线程还可以从数据包尾部读取额外字节。此功能对于集体操作至关重要,因为操作数(梯度、参数)往往超出前 200 个字节并占据了整个数据包有效负载。
哈希引擎(加速器)包含多个哈希表,PPE 可以在其中插入、查找或删除条目。哈希记录存储在 DataMemory 中,可以由 PPE 修改。
内存子系统包含用于包处理结构的DataMemory和用于延迟带宽缓冲的包缓冲区。DataMemory前面有一个大型片上内存。片上内存被划分为两部分:一部分作为DataMemory地址空间的扩展,另一部分作为DataMemory访问的大缓存。这两部分之间的划分是可变的。
数据包处理涉及许多读取-修改-写入操作。有时,多个 PPE 可以访问同一位置以更新其内容。一种简单的方法是赋予每个线程对内存位置的完全所有权,直到其读取-修改-写入操作完成。但是,这样做效率低下,可能会大大降低性能。在 Trio 中,PPE 将读取-修改-写入操作卸载到内存子系统。内存子系统包含多个读取-修改-写入引擎(每个引擎处理特定的地址子集),这些引擎可以在每个周期处理这些请求(8字节)。当多个请求到达特定引擎的某个内存位置时,引擎会按顺序处理这些请求,从而确保更新的一致性。
该架构还允许通过读取数据内存的内容、使用 PPE 处理附加适当的报头、将新数据包写入数据包缓冲区,并将其排队发送,从而创建新报文。因此,Trio架构具备了实现网络内集体操作所需的所有关键组件。
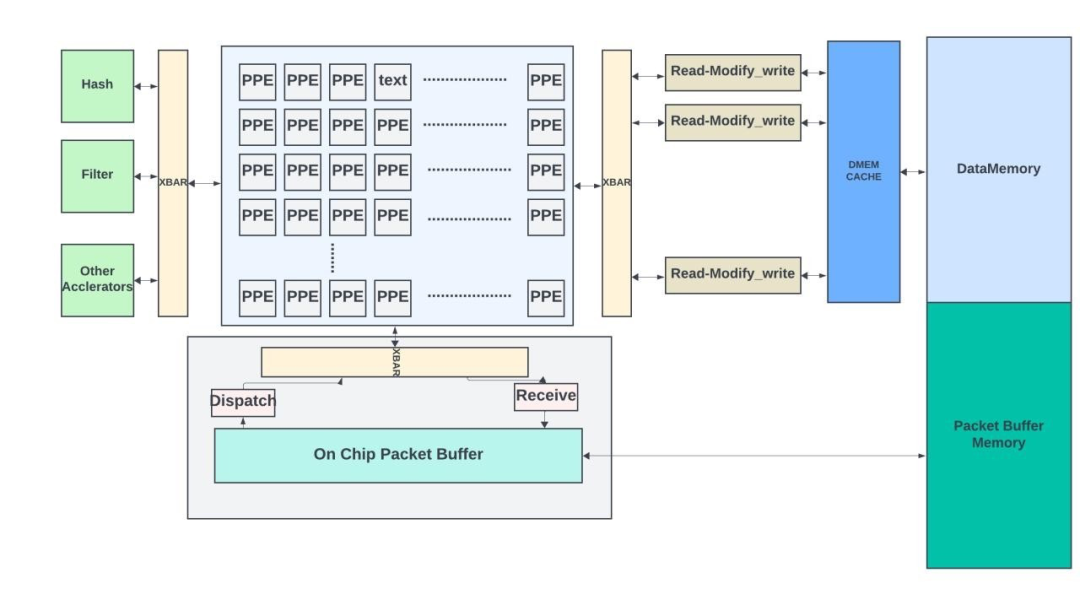
Trio PFE
这种架构的优点在于,交换机中的任何处理都不是硬编码的。它具有灵活性,可以支持和解析任何新协议(UEC或自定义协议)。
网内聚合流程
本节介绍了论文中使用的网内聚合流程。
首先,需要定义集体数据包的报头(通常在 UDP 层下)和数据包格式。在 SIGCOMM 论文中,作者创建了一个名为 Trio-ML 的自定义报头。识别聚合线程、源/目标GPU、梯度块以及块中梯度数量的足够信息。ML 框架通常允许插件来支持自定义通信协议。
在训练开始前,控制平面在作业配置时在哈希表中创建作业记录,并一直持续到作业完成。这些记录包含了参与作业的所有源(GPU)的信息,正在被聚合的区块数量(梯度的子集),以及如何创建响应数据包的信息(包括数据包的目的地等)。
当作业/块的第一个数据包到达时,PPE线程会在哈希表中创建一个块记录。这个记录追踪集体操作的状态(在本例是梯度聚合),包括记录哪些源(源GPU)尚未交付梯度,以及指向DataMemory中聚合缓冲区的指针。一旦块聚合完成,这个块记录就会被移除。
当数据包到达 PPE 线程时,它会解析报头并在哈希表中查找作业/块 ID。如果块记录不存在,它会创建记录并在 DataMemory 中为该块分配一个聚合缓冲区。如果块记录已经存在,则执行读取-修改-写入以将当前数据包的梯度聚合到聚合缓冲区。如果这是最后一个需要聚合梯度的源(块记录指示所有源的状态),则生成响应数据包,将其写入数据包缓冲存储器,并将其排入排队子系统。之后清理块记录。
训练结束后,系统(在控制平面)可以清理作业记录以释放分配的空间。
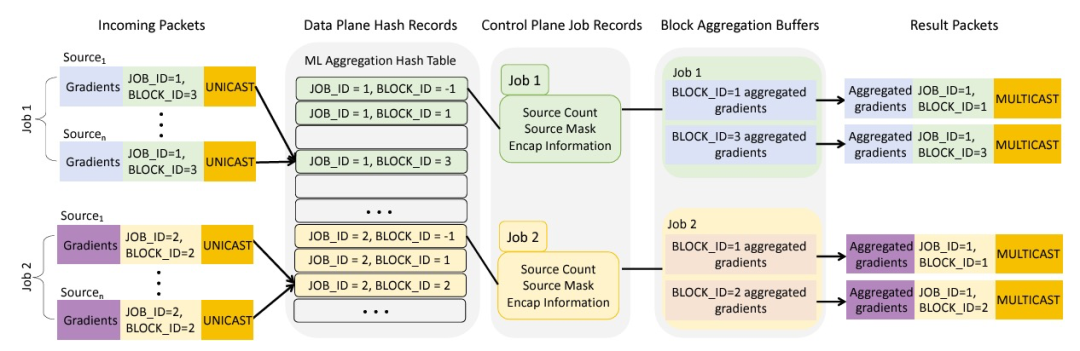
网络内聚合流程(饮用自 SIGCOMM 2022 Juniper/MIT 论文)
在一个小型设置(使用六台A100 GPU服务器和图像识别中使用的小型DNN模型)中的结果显示,在训练过程中性能提高了1.8倍。这是一个概念验证(POC)设计。
虽然使用数据包处理引擎(或网络处理器)的网络交换机在交换机内部实现集体操作方面提供了极大的灵活性,但这些交换机并不像使用固定pipeline数据包处理的浅/深缓冲交换机那样具有高端口密度。此外,由于数据包处理预算有限,在网络集体操作中花费的时间越多,数据包处理性能就越低。
解决此问题的一种方法是将这些可编程交换机作为协处理器,连接到常规的高带宽交换机上,并使用这些交换机的部分 WAN 带宽与协处理器进行通信,以处理集体操作。
在构建支持可编程交换机进行网内集体操作的架构时,没有一种万能的解决方案。这取决于集群大小、正在训练的模型类型以及要卸载的集体操作。
总结
在本文中,作者解释了深度学习/通用人工智能训练中使用的集体操作,以及网络设备如何帮助卸载这些操作。在网计算的争论已经存在了十多年,但尚未在业界引起足够的关注。
然而,随着最近大语言模型和通用人工智能模型训练工作负载的激增,以及 GPU 的稀缺性和高成本,任何在网络中进行的卸载都将直接转化为公有云和数据中心显著的成本优化与效能提升。Nvidia 已经在其 InfiniBand 和 NVLink 交换机中原生支持此功能。随着 UEC 联盟致力于标准化 INC,这些操作进入高带宽以太网交换机只是时间问题。与此同时,可编程网络设备可能会单独使用或作为协处理器来卸载训练工作负载中的集体操作。
总体而言,随着从公有云到边缘计算等各个领域的 AI/ML 工作负载呈指数级增长,交换机/路由器将开始发挥重要作用,不仅可以尽可能快地传输数据,还可以卸载某些操作以提高性能并降低成本。
-
gpu
+关注
关注
28文章
4731浏览量
128906 -
交换机
+关注
关注
21文章
2638浏览量
99559 -
AI
+关注
关注
87文章
30789浏览量
268925 -
深度学习
+关注
关注
73文章
5500浏览量
121121
原文标题:可编程交换机如何卸载 AI 训练中的集体操作?
文章出处:【微信号:SDNLAB,微信公众号:SDNLAB】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
接入层交换机、汇聚层交换机和核心层交换机的区别
与思科惠普竞争 瞻博发布核心SDN交换机
工业控制交换机和工业交换机的区别
英特尔展示P4可编程以太网交换机,采用光学引擎一体封装
Intel展示Barefoot Networks可编程以太网交换机技术 具备高达12.8Tbps的吞吐量
核心交换机、汇聚交换机与普通交换机的区别介绍
家庭交换机怎么安装_交换机网速是平分的吗

什么是网络交换机?网络交换机的分类标准
核心交换机、汇聚交换机、接入交换机之间的对比分析
SD-Fabric:端到端可编程数据平面






 工商网监
工商网监
评论