 端到端InfiniBand网络解决LLM训练瓶颈
端到端InfiniBand网络解决LLM训练瓶颈

ChatGPT对技术的影响引发了对人工智能未来的预测,尤其是多模态技术的关注。OpenAI推出了具有突破性的多模态模型GPT-4,使各个领域取得了显著的发展。 这些AI进步是通过大规模模型训练实现的,这需要大量的计算资源和高速数据传输网络。端到端InfiniBand(IB)网络作为高性能计算和AI模型训练的理想选择,发挥着重要作用。在本文中,我们将深入探讨大型语言模型(LLM)训练的概念,并探索端到端InfiniBand网络在解决LLM训练瓶颈方面的必要性。
大型语言模型(LLM)和ChatGPT之间是否存在联系
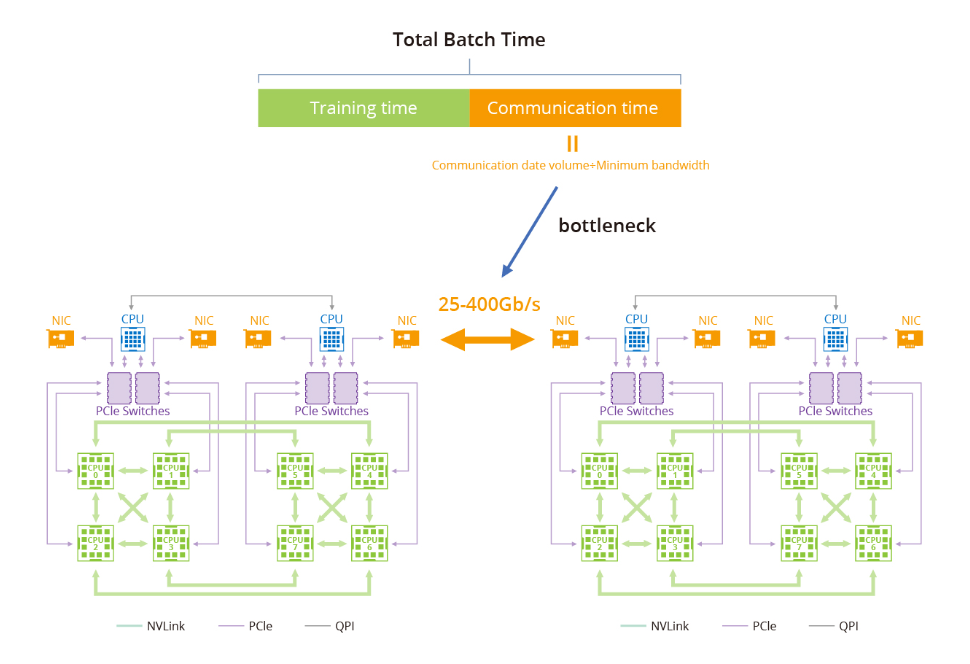
训练大型语言模型(LLM)面临的瓶颈主要与GPU计算集群内的数据传输和通信有关。随着大型语言模型的增长,对高速可靠网络的需求变得至关重要。例如,具有1.75万亿参数的GPT-3的模型无法在单机上训练,而是严重依赖于GPU集群。主要瓶颈在于在训练集群中高效地在节点之间传输数据。
阶段1:环形全约减
一种常用的GPU通信算法是环形全约减,其中GPU形成一个环,使数据在环内流动。每个GPU都有一个左邻和一个右邻,数据只向右邻发送,从左邻接收。该算法包括两个步骤:散射-约减和全收集。在散射-约减步骤中,GPU交换数据以获得最终结果的一个块。在全收集步骤中,GPU交换这些块,以确保所有GPU都具有完整的最终结果。
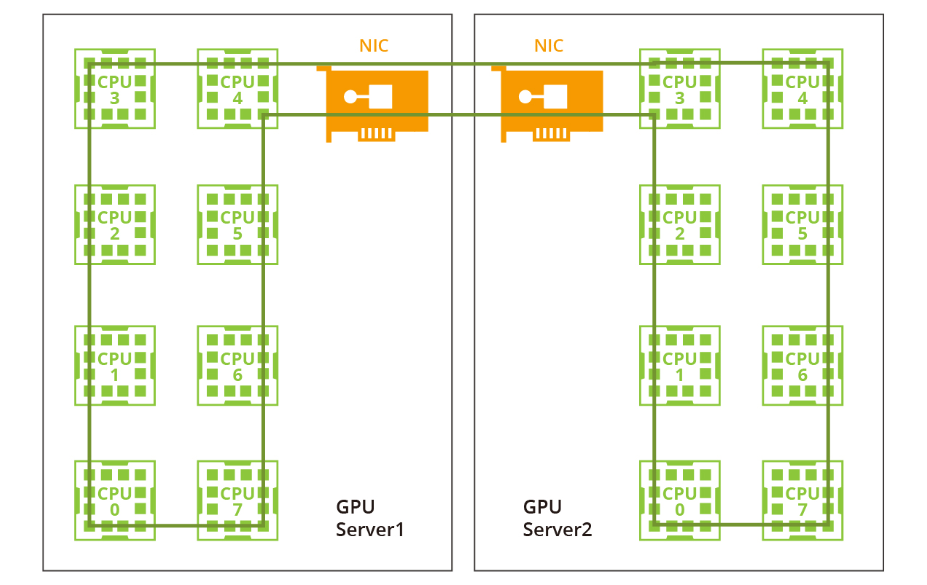
阶段2:双阶段环形
过去由于带宽有限且没有NVLink或RDMA技术,一个大型环对于单机和多机分布已经足够。然而,随着NVLink在单机内的引入,相同的方法不再适用。网络带宽远低于NVLink的带宽,因此采用一个大环将大幅降低NVLink的效率到网络的水平。此外,在当前的多网卡环境中,仅利用一个环无法充分利用多个网卡。因此,建议采用双阶段环方法来解决这些问题。 在双阶段环形场景中,数据同步发生在单台机器内的GPU之间,利用了NVLink的高带宽优势。随后,跨多台机器的GPU使用多个网卡建立多个环形,以同步来自不同段的数据。最后,单台机器内的GPU再次进行同步,完成所有GPU之间的数据同步。值得注意的是,NVIDIA集体通信库(NCCL)在这个过程中发挥了关键作用。
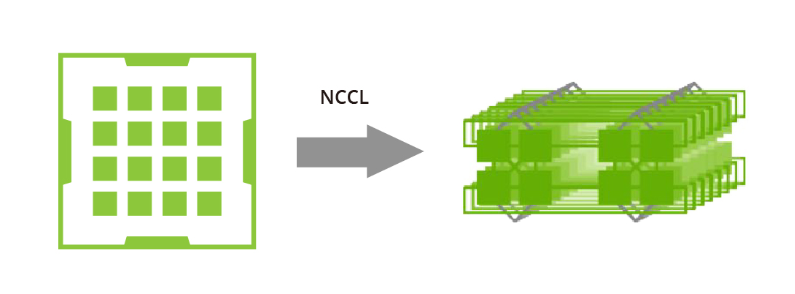
NVIDIA集体通信库(NCCL)包括针对NVIDIA GPU和网络进行优化的多GPU和多节点通信例程。NCCL为全收集、全约减、广播、约减、约减散开和点对点发送和接收操作提供高效的基本操作。这些例程经过优化,以实现高带宽和低延迟,利用节点内和NVIDIA Mellanox网络通过PCIe和NVLink高速互连。
通过解决数据传输和通信中的瓶颈问题,GPU计算集群的进步以及利用NCCL等工具的使用有助于克服大型语言模型训练中的挑战,为AI研究和开发进一步的突破铺平了道路。
端到端InfiniBand网络解决方案如何提供帮助
在大型模型训练中,以太网在传输速率和延迟方面存在不足。相比之下,端到端InfiniBand网络提供了高性能计算解决方案,能够提供高达400 Gbps的传输速率和微秒级的延迟。因此,InfiniBand已成为大规模模型训练的理想选择。
数据冗余和错误纠正机制
端到端InfiniBand网络的一个关键优势是其对数据冗余和错误纠正机制的支持,确保可靠的数据传输。在大规模模型训练中,由于处理的数据量巨大,传输错误或数据丢失会对训练过程产生不利影响,这一点尤为重要。通过利用InfiniBand的强大功能,可以较大程度地减少由于数据传输问题引起的中断或故障。
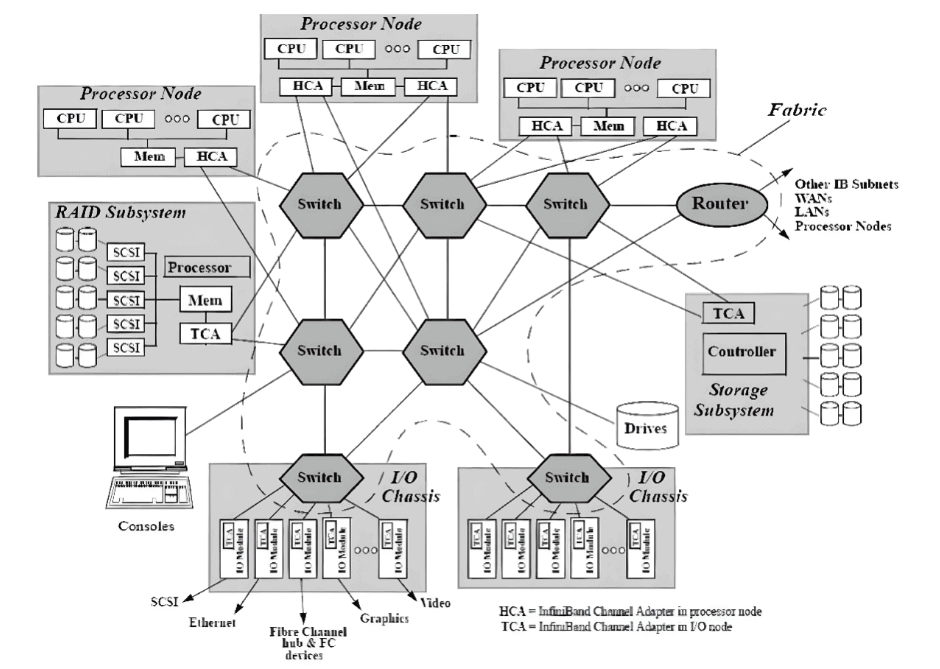
本地子网的配置和维护
在InfiniBand互连协议中,每个节点都配备有一个主机通道适配器(HCA),负责与主机设备建立和维护链接。交换机具有多个端口,用于在端口之间进行数据包转发,从而实现子网内的高效数据传输。 子网管理器(SM)在配置和维护本地子网方面发挥着关键作用,每个InfiniBand设备上都有子网管理器数据包(SMP)和子网管理器代理(SMA)提供支持。子网管理器(SM)发现和初始化网络,为所有设备分配唯一标识符,确定最小传输单元(MTU),并根据选择的路由算法生成交换机的路由表。它还定期扫描子网,检测拓扑变化,并相应调整网络配置。
基于信用的流量控制
与其他网络通信协议相比,InfiniBand网络提供更高的带宽、更低的延迟和更大的可扩展性。此外,InfiniBand采用基于信用的流量控制,发送节点确保不会传输超过接收缓冲区中可用信用数量的数据到连接的另一端。这消除类似TCP窗口算法的数据包丢失机制的需求,使InfiniBand网络能够以较低延迟和CPU使用率实现较高数据传输速率。
远程直接内存访问(RDMA)技术
InfiniBand利用远程直接内存访问(RDMA)技术,实现应用程序之间在网络上直接进行数据传输,无需涉及操作系统。这种零拷贝传输方法显著减少了两端CPU资源的消耗,使应用程序能够直接从内存中读取消息。降低的CPU开销提升了网络快速传输数据的能力,并使应用程序更高效地接收数据。 总体而言,端到端InfiniBand网络为大型模型训练提供了显著优势,包括高带宽、低延迟、数据冗余和错误纠正机制。通过利用InfiniBand的能力,研究人员可以克服性能限制,增强系统管理,并加速大规模语言模型的训练。
-
InfiniBand
+关注
关注
1文章
31浏览量
9591 -
ChatGPT
+关注
关注
31文章
1607浏览量
10422 -
大模型
+关注
关注
2文章
3857浏览量
5290
原文标题:InfiniBand:突破大模型训练性能瓶颈
文章出处:【微信号:AI_Architect,微信公众号:智能计算芯世界】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
InfiniBand 连接现在和未来
语音端到端加密方案
为WiMAX构建端到端的网络架构
基于WiMAX接入技术的端到端网络架构
端到端的自动驾驶研发系统介绍
我国正式启动了5G网络切片端到端总体架构标准研制工作
基于深度神经网络的端到端图像压缩方法

英伟达三大AI法宝:CUDA、Nvlink、InfiniBand

理想汽车自动驾驶端到端模型实现

连接视觉语言大模型与端到端自动驾驶

准确性超Moshi和GLM-4-Voice,端到端语音双工模型Freeze-Omni


如何训练好自动驾驶端到端模型?




评论