 介绍目标检测工具Faster R-CNN,包括它的构造及实现原理
介绍目标检测工具Faster R-CNN,包括它的构造及实现原理
编者按:tryo.labs是一家专注于机器学习和自然语言处理的技术支持公司,在本篇文章中,公司的研究人员介绍了他们在研究过程中所使用的先进目标检测工具Faster R-CNN,包括它的构造及实现原理。
之前,我们介绍了目标物体检测(object detection)是什么以及它是如何用于深度学习的。去年,我们决定研究Faster R-CNN。通过阅读原论文以及相关的参考文献,我们对其工作原理及如何部署已经有了清晰的了解。
最终,我们将Faster R-CNN安装到Luminoth上,Luminoth是基于TensorFlow的计算机视觉工具包,我们在公开数据科学大会(ODSC)的欧洲和西部会场上分享了这一成果,并收到了很多关注。
基于我们研发Luminoth中的收获以及分享成果,我们认为应当把研究所得记录到博客中,以飨读者。
背景
Faster R-CNN最初是在NIPS 2015上发表的,后来又经过多次修改。Faster R-CNN是Ross Girshick团队推出的R-CNN的第三次迭代版本。
2014年,在第一篇R-CNN的论文Rich feature hierarchies for accurate object detection and semantic segmentation中,研究人员利用一种名为选择性搜索(selective search)的算法提出一种可能的感兴趣区域(RoI)和一个标准的卷积神经网络来区分和调整它们。2015年初,R-CNN进化成为Fast R-CNN,其中一种名为兴趣区域池化(RoI Pooling)的技术能够共享耗能巨大的计算力,并且让模型变得更快。最后他们提出了Faster R-CNN,是第一个完全可微分的模型。
结构
Faster R-CNN的结构十分复杂,因为它有好几个移动部分。我们首先对Faster R-CNN做大致介绍,然后对每个组成部分进行详细解读。
问题是围绕一幅图像,从中我们想要得到:
边界框的列表
每个边界框的标签
每个标签和边界框的概率
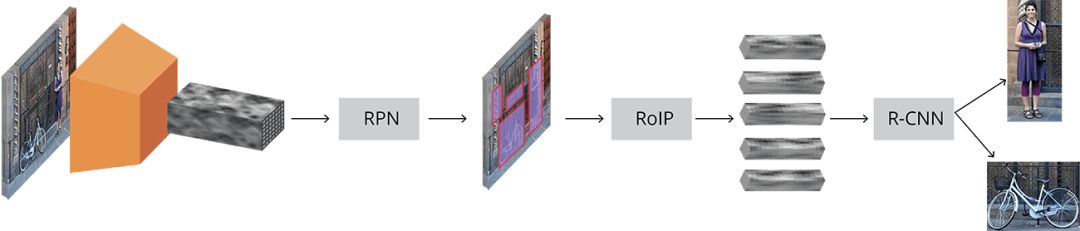
Faster R-CNN完整示意图
输入的图像用高度×宽度×深度的张量(多维数组)表示,在传输到中间层之前,先经过一个预训练的CNN,最终生成卷积特征映射。我们将这一映射作为下一部分的特征提取器。
这一技术在迁移学习中还是很常见的,尤其是利用在大规模数据库上训练的网络权重,来训练小规模数据库上的分类器。
接着,我们得到了Region Proposal Network(RPN),利用CNN计算出的特征,使用RPN找到既定数量的区域(边框线),其中可能包含目标对象。
也许用深度学习做目标检测最难的部分就是生成一个长度可变的边界框列表。对深度神经网络进行建模时,最后一个block通常是一个固定大小的张量输出(除使用循环神经网络以外)。例如,在图像分类中,输出的是一个(N,)的张量,N代表类别的数量,其中的位置i处的每个标量包含该图像被标位labeli的概率。
在RPN中可以使用anchors解决可变长度的问题:在原始图像中统一放置固定大小的参考边界框,与直接检测物体的位置不同,我们将问题分为两部分。对每个anchor,我们会想:
这个anchor是否含有相关目标对象?
如何调整这个anchor才能让它更好地适应相关对象?
听起来可能有点迷惑,接下来我们将深入探讨这个问题。
在原始图像中得到可能的相关对象及其位置的列表后,问题就更直接了。利用CNN提取的特征和包含相关对象的边界框,应用RoI pooling,将与相关对象对应的特征提取出一个新的向量。
最后是R-CNN模块,它利用这些信息来:
将边界框里的内容分类(或标记成“背景”标签丢弃它)
调整边界框的坐标,使其更适合目标对象
虽然描述得比较粗略,但这基本上是Faster R-CNN的工作流程。接下来,我们将详细介绍每一部分的架构、损失函数以及训练过程。
基本网络(Base Network)
就像我们之前提到的,第一步是利用一个为分类任务预先训练过的CNN(比如ImageNet)和中间层的输出。对于有机器学习背景的人来说,这听上去挺简单的。但是关键一点是要理解它是如何工作的,以及为什么会这样工作。同时还要让中间层的输出可视化。
目前没有公认的最好的网络架构。最早的R-CNN使用了在ImageNet上预训练的ZF和VGG,但从那以后,有许多权重不同的网络。例如,MobileNet是一种小型网络,优化后高效的网络体系结构能加快运行速度,它有将近3.3M的参数,而152层的ResNet(对,你没看错就是152层)有大约60M参数。最近,像DenseNet这样的新架构既改善了结果,又减少了参数数量。
VGG
在比较孰优孰劣之前,让我们先用标准的VGG-16为例来理解他们都是怎样工作的。
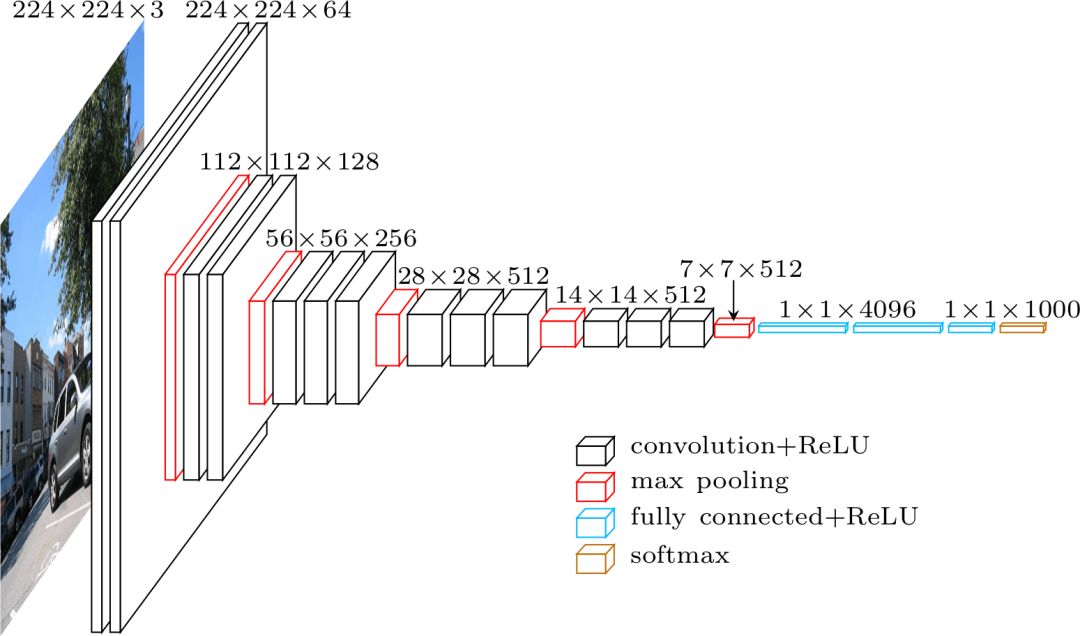
VGG架构
VGG这个名字来源于2014年ImageNet ILSVRC比赛中的一组选手,其中的Karen Simonyan和Andrew Zisserman发表了一篇名为Very Deep Convolutional Networks for Large-Scale Image Recognition的论文。若以现在的标准来看,这已经不是“very deep”的网络了,但在当时,它比通常使用的网络层数增加了一倍多,并且开始了“deeper→more capacity→better”的波动(当可以训练的时候)。
使用VGG分类时,输入的是224×224×3的张量(即224×224像素的RGB图像)。由于网络的最后一个模块使用完全连接层(FC)而不是卷积,这需要一个固定长度的输入。通常将最后一个卷积层的输出平坦化,在使用FC层之前得到第一次命中的张量。
由于我们要使用中间卷积层的输出,所以输入的大小不用特别考虑。至少,在这个模块中不用担心,因为只使用了卷积层。让我们继续详细介绍,决定到底要使用哪个卷积层。论文中并未指明要使用的图层,但在实际安装过程中,你可以看到它们用了conv5/conv5_1的输出。
每个卷积层都会从之前的信息中生成抽象的东西。第一层图层通常学习图像中的边缘线,第二层找出边缘内的图形,以学习更复杂的形状等。最终我们得到了卷积特征向量,它的空间维度比原始图像小得多,但是更深。特征映射的宽度和高度由于卷积层之间的池化而降低,同时由于卷积层学习的过滤器数量增多导致映射的深度增加。
图像到卷积特征映射
在深度上,卷积特征映射已经对图像的所有信息进行编码,同时保持其相对于原始图像编码的“物体”的位置。例如,如果图像的左上角有一个红色正方形,并且卷积层激活了它,那么该红色正方形的信息仍然位于卷积特征映射的左上角。
VGG vs ResNet
目前,ResNet架构大多已经取代了VGG作为特征提取的基础网络,Faster R-CNN的三位合作者(Kaiming He,Shaoqing Ren和Jian Sun)也是ResNet原始论文Deep Residual Learning for Image Recognition的共同作者。
相对于VGG,ResNet的明显优势在与它更大,因此它有更大能力去了解需要什么。这对分类任务来说是正确的,同时对目标物体检测也是如此。
此外,ResNet让使用残差网络和批量归一化来训练深度模型变得简单,这在VGG发布之初并未出现。
Anchors
既然我们有了处理过的图像,则需要找到proposals,即用于分类的兴趣区域(RoI)。上文中提到,anchors是解决可变长度问题的方法,但是没有详细讲解。
我们的目标是在图像中找到边界框,它们呈矩形,有不同的尺寸和长宽比。想像一下,我们事先知道图像中有两个对象,若要解决的话,第一个立即想到的方案是训练一个返回八个值的网络:xmin、ymin、xmax、ymax元组各两个,以确定每个目标物体的边界框位置。这种方法有一些非常基础的问题。例如,图像的尺寸和长宽比可能不同,训练预测原始坐标的良好模型可能会变得非常复杂。另外,模型可能会生成无效的预测:当预测xmin和xmax的值时,我们需要保证xmin<xmax。
最终,事实证明通过学习预测参考框的偏移量,可以更简单地预测边界框的位置。我们取xcenter,ycenter,宽度,高度,学习预测Δxcenter、Δycenter、Δwidth、Δheight,这些值可以将参考框调整得符合我们的需要。
Anchors是固定的边界框,它们遍布整个图像,具有不同的大小和比例,这些尺寸在第一次预测目标对象位置的时候用作参考。
由于我们是用的是尺寸为convwidth×convheight×convdepth的卷积特征映射,于是可以在convwidth×convheight中的每个点创造一组anchors。即使anchors是基于卷积特征映射,理解这一点也是非常重要的,最终的anchors可以显示原始图像。
由于我们只有卷积层和池化层,特征映射的维度在原始图像中是成比例的。用数学方法表示,即如果图像是w×h,特征映射就是w/r×h/r,这里的r被称为subsampling ratio。如果我们把特征映射的每个空间位置定义一个anchor,那么最终的图像将会是由分散的r像素组成的一群anchors。在VGG中,r=16.
原始图像的anchor中心
为了更好的选择anchors,我们通常会定义一组尺寸(例如64px,128px,256px)和一组边框的宽高比(例如0.5,1,1.5),并且将所有可能的尺寸和比例加以组合。

左:anchors,中:单点的anchor,右:所有anchors
Region Proposal Network
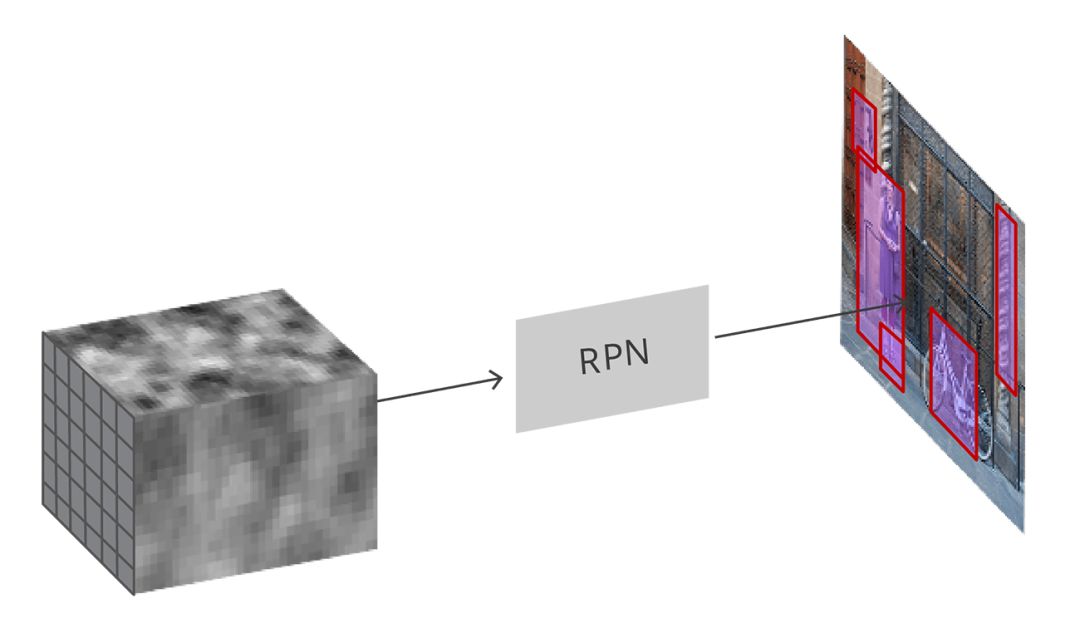
输入卷积特征映射,RPN在图像上生成proposals
正如之前所提到的,将所有参考框(anchors)输入RPN中,输出一组目标的proposals,每个anchors会有两个不同的输出。
第一个输出是anchor中是目标对象的概率,可称为“目标性分数”(objectness score)。注意,RPN不关心目标物体的类别,它只能分辨目标与背景。我们将用这个分数过滤掉不佳的预测,为第二阶段做准备。第二个输出是边界框回归,它的作用是调整anchors,让它们更好地圈住目标物体。
在完全卷积的环境中,RPN的安装十分高效,利用基础网络返回的卷积特征映射作为输入。首先,我们有一个拥有512个通道和3×3大小的核的卷积层,然后利用1×1的核及一个带有两平行通道的卷积层,其中它的通道数量取决于每个点的anchors数量。
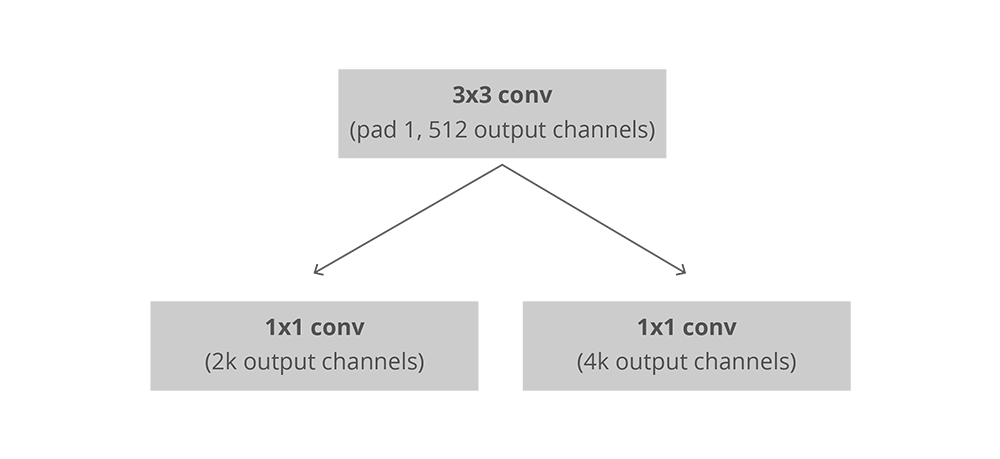
RPN中卷积的安装,k是anchors的数量
对于分类层,每个anchor输出两个预测:它为背景的分数(不是目标物)以及它为前景的分数(实际的目标物)。
对于回归函数,或者边界框的调整层,我们输出四个预测值:Δxcenter、Δycenter、Δwidth、Δheight,这些会应用到anchors上生成最终的proposals。
利用最终的proposals坐标和它们的“目标性分数”,就能得到目标物体最佳的proposals。
训练,目标和损失函数
RPN能做出两种预测:二元分类问题和边界框回归调整。
在训练时,我们将所有的anchors分成两类。其中交并比(Intersection over Union,IoU)的值大于0.5、与标准目标物体重合的anchors被认为是“前景”(foreground),那些不与目标物体重合、或者IoU的值小于0.1的被认为是“背景”(background)。
然后,我们对anchors随机采样256个样本,同时保证前景和背景anchors的比例不变。
接着,RPN用上述样本进行计算,利用二元交叉熵计算出分类器的损失函数。然后用样本中的前景anchors计算回归函数。在计算回归函数的目标时,我们用前景的anchor和最近的目标物体计算能将anchor变为目标物体的正确的Δ。
除了用简单的L1或者L2损失函数纠正回归函数的错误,论文中还建议用Smooth L1损失函数。Smooth L1与L1基本相同,但是当L1的错误足够小(用一确定的值σ表示),它就被认为是接近正确的,损失就会以更快的速度消失。
但是用动态群组(dynamic batches)会有一些困难。即使我们尝试保持两种anchors之间比例的平衡,也无法完美地做到这一点。根据图像中真实目标物体的位置以及anchors的尺寸和比例,有可能最终没有位于前景的anchors。在这种情况下,我们转而使用IoU值最大的anchors来确定正确边框的位置。这与理想情况相差较远。
后处理
非极大抑制
由于anchors经常重合,因此proposals最终也会在同意目标物体上重叠。为了解决这一问题,我们用简单的“非极大抑制”(NMS)算法。NMS通过分数和迭代筛选边界框并生成一个proposals的列表,放弃IoU大于某个特定阈值的proposals,保留分数较高的proposals。
虽然看起来简单,但要谨慎制定IoU的阈值。定的太低,最终可能会找不到正确的proposals;定的太高,最后可能会留下太多proposals。该值常用的数字是0.6。
Proposal选择
应用了NMS后,我们留下了前N个proposals。在论文中,N=2000,但是即使把数字换成50也有可能得到相当不错的结果。
独立应用程序(Standalone application)
RPN可以单独使用,无需第二个阶段的模型。在只有一类对象的问题中,目标物体的概率可用作最终的类别概率。这是因为在这种情况下,“前景”=“单一类别”,“背景”=“多种类别”。
在机器学习问题中,人脸检测和文本检测这种可以从RPN独立应用程序中受益的案例是非常流行的,但目前仍存在很多挑战。
仅使用RPN的优点之一是在训练和预测中的速度都有所提高。由于RPN是一个非常简单、并且只是用卷积层的网络,预测时间要比其他分类网络更快。
兴趣区域池化(RoI Pooling)
RPN阶段之后,我们得到一堆没有分类的proposals。接下来要解决的问题是,如何将这些边界框分到正确的类别中去。
最简单的方法是将每个proposals裁剪,然后通过预训练的基础网络。接着,使用提取出的特征输入到一般的分类其中。但是想要处理2000个proposals,这样的效率未免太低了。
这时,Faster R-CNN可以通过重新使用现有的卷及特征映射解决或者缓解这一问题。这是利用RoI池化对每个proposals进行固定大小的特征提取完成的。R-CNN需要固定尺寸的特征映射,以便将它们分成固定数量的类别。
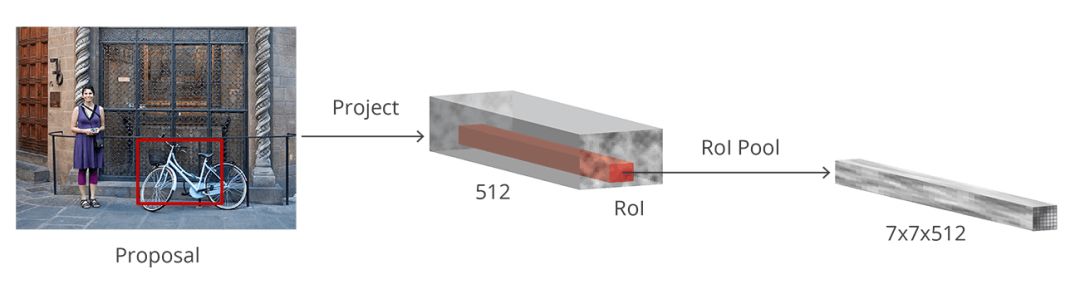
ROI池化
另外一种更简单的方法,包括Luminoth的Faster R-CNN也在用的,是用每个proposals来裁剪卷积特征映射,然后用双线性插值将裁剪后的映射调整为14×14×convdepth的固定大小。裁剪之后,用2×2的最大池得到最终7×7×convdepth的特征映射。
基于区域的卷积神经网络(R-CNN)
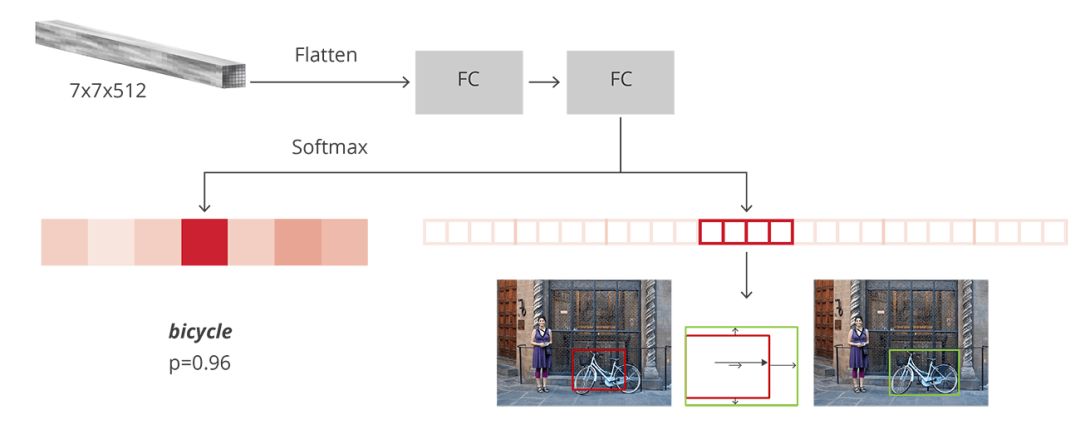
R-CNN是达到Faster R-CNN的最后一个阶段。在从图像中获取卷积特征映射后,利用它来获得目标物体的proposals,并最终通过RoI池化为每个proposals提取特征,最后我们需要对这些特征进行分类。R-CNN要模仿CNN分类的最后阶段,其中一个完全连接层输出每个对象可能的类别的分数。
R-CNN有两个不同的目的:
将proposals分到其中一类,另外还有一个“背景类”,用于删除错误的proposals
根据预测的类别更好地调整proposals的边界框
在最初的Faster R-CNN论文中,R-CNN将特征映射应用于每个proposal,“压平”(flatten)后使用ReLU和两个4096大小的完全连接层将其激活。
然后,它为每个不同的目标物体使用两个不同的完全连接层:
拥有N+1个单位的完全连接层,整理N是类别的总数,多出来的1表示背景
拥有4N个单位的完全连接层。想进行回归预测,所以需要对N个可能的类别进行Δxcenter、Δycenter、Δwidth、Δheight四个值的预测
R-CNN的结构
训练和目标
R-CNN的目标与RPN的目标几乎相同,但考虑到不同类别,我们计算了proposals和标准边界框之间的IoU。
那些大于0.5的proposals被认为是正确的边框,而分数在0.1和0.5之间的proposals被标记为“背景”。与我们在为RPN组装目标时所做的相反,我们忽略了没有交集的proposals。这是因为在这个阶段,我们假设这里的proposals很好,而且想要解决更难的案例。当然,所有这些可以调整的超参数可以更好地适合目标物的种类。
边界框回归的目标试计算proposals与其相应的标准框架之间的偏移量,而且这里仅针对那些基于IoU阈值分配了类别的proposals。
我们随机抽样了一个尺寸为64的迷你群组,其中有高达25%的前景proposals,75%的背景。
按照我们对RPNs损失做的那样,对于全部所选出的proposals,分类器的损失现在是一个多类交叉熵损失;对于那25%的前景proposals,用Smooth L1损失。由于为了边框回归的R-CNN完全连接网络的输出对每种类别只有一个预测,所以在获得这种损失时不需小心。在计算损失时,我们只要考虑正确的类别即可。
后处理
与RPN相似,我们最终又得到了一堆已分类的目标对象,在返回他们之前需要进行进一步处理。
为了调整边框,我们需要考虑哪类是proposals最可能属于的边框。同时要忽略那些最有可能是背景的proposals。
在得到最终的目标物体之后,我们用基于分类的NMS删除北京。这是通过将目标对象按类别进行分组,然后按概率对其进行排序,然后再将NMS应用于每个独立组。
对于最后的目标物体列表,我们也可以为每个类别设置一个概率阈值和对象数量的限制。
训练
在原论文中,Faster R-CNN的训练经历了多个步骤,每个步骤都是独立的,在最终进行全面训练之前合并了所有训练的权重。从那时起,人们发现进行端到端的联合训练结果更好。
把模型结合后,我们可以得到四个不同的损失,两个用于RPN,两个用于R-CNN。在RPN和R-CNN上游客训练的图层,我们也有可以训练(微调)或不能训练的基础网络。
基础网络的训练取决于我们想要学习的对象的性质和可用的计算能力。如果我们想要检测与原始数据集相似的目标对象,那么除了将所有方法都试一遍,也没什么好方法了。另一方面,训练基础网络是很费时费力的,因为要适应全部的梯度。
四种不同的损失用加权进行组合,这是因为我们可能像给分类器比回归更多的损失,或者给R-CNN比RPN更多的权重。
除了正则损失外,我么也有归一化损失。对一些层使用L2正则化,这取决于正在使用的基础网络以及是否经过训练。
我们用随机梯度下降的动量进行训练,动量设置为0.9。你可以轻松地训练更快的R-CNN和其他优化,不会遇到任何大问题。
学习速度开始为0.001,后来经过5万次迭代后降到0.0001。这通常是最重要的超参数之一。当我们用Luminoth进行训练时,通常用默认值开始训练,然后再慢慢调整。
评估
评估过程使用标准的平均精度均值进行判断(mAP),并将IoU的值设定在特定范围。mAP是源于信息检索的一种标准,经常用于计算排名和目标检测问题中的错误。当你漏了某一边界框、检测到不存在或者多次检测到同一物体时,mAP就会进行惩罚。
结论
现在你应该了解R-CNN的工作原理了吧,如果还想深入了解,可以探究一下Luminoth的实现。
Faster R-CNN证明了,在新的深度学习革命开始的时候,可以用同样的原理来解决复杂的计算机视觉问题。目前正在建立的新模型不仅能用于目标物体检测,还能用于语义分割、3D物体检测等等。有的借鉴了RPN,有的借鉴了R-CNN,有的二者皆有。这就是为什么我们要搞清楚他们的工作原理,以解决未来将面对的难题。
-
目标检测
+关注
关注
0文章
209浏览量
15605 -
vgg
+关注
关注
1文章
11浏览量
5193
原文标题:目标检测技术之Faster R-CNN详解
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于深度学习的目标检测算法解析
基于YOLOX目标检测算法的改进
深度卷积神经网络在目标检测中的进展
什么是Mask R-CNN?Mask R-CNN的工作原理
手把手教你操作Faster R-CNN和Mask R-CNN

基于改进Faster R-CNN的目标检测方法
迅速了解目标检测的基本方法并尝试理解每个模型的技术细节
用于实例分割的Mask R-CNN框架
PyTorch教程14.8之基于区域的CNN(R-CNN)

PyTorch教程-14.8。基于区域的 CNN (R-CNN)







 工商网监
工商网监
评论