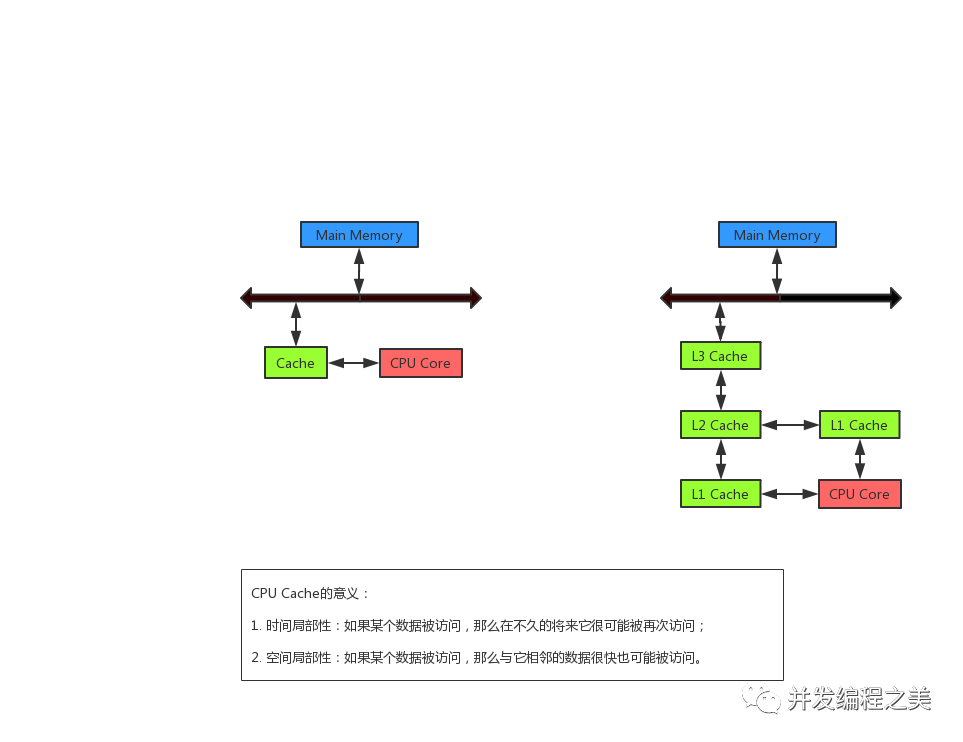
 异构计算下缓存一致性的重要性
异构计算下缓存一致性的重要性

作者:张景涛
问题起源
这个问题来源于华为海思鲲鹏处理器首席架构师兼昇腾AI处理器架构师夏晶在知乎上发出的灵魂之问。
问题初答
在众多回复中,李博杰同学的回答被认为质量最高。他首先将缓存一致性分为两个主要场景:一是主机内CPU与设备间的一致性;二是跨主机的一致性。
对于第一个场景(主机内CPU与设备间),李博杰同学明确指出缓存一致性的重要性,并以在微软研究院实习期间的一个项目为例,说明了使用FPGA将内存连接到PCIe的bar空间上,导致Linux系统启动时间从3秒延长到30分钟,速度降低了600倍。这一现象揭示了PCIe不支持缓存一致性,CPU直接访问设备内存时只能是非缓存型(uncacheable)的。[注:在分析耗时时,除了缓存一致性外,还应考虑PCIe与内存带宽的差异]
在第一种场景中,他还对比了同步和异步远程访问的差异,但原文并未明确指出主机内CPU和设备间一致性的具体优势。
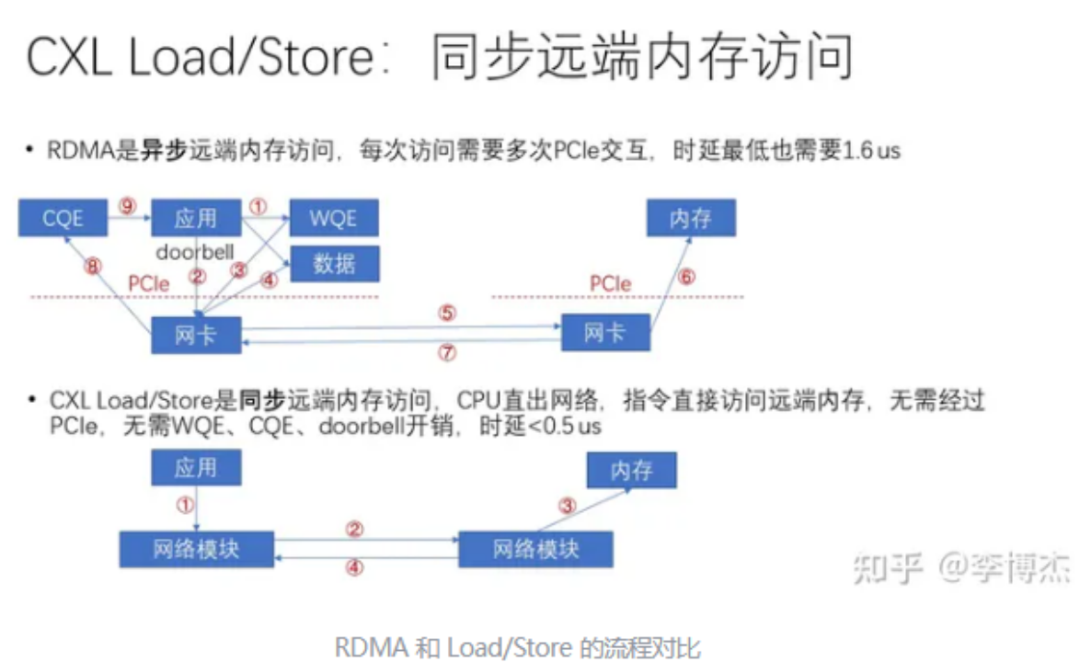
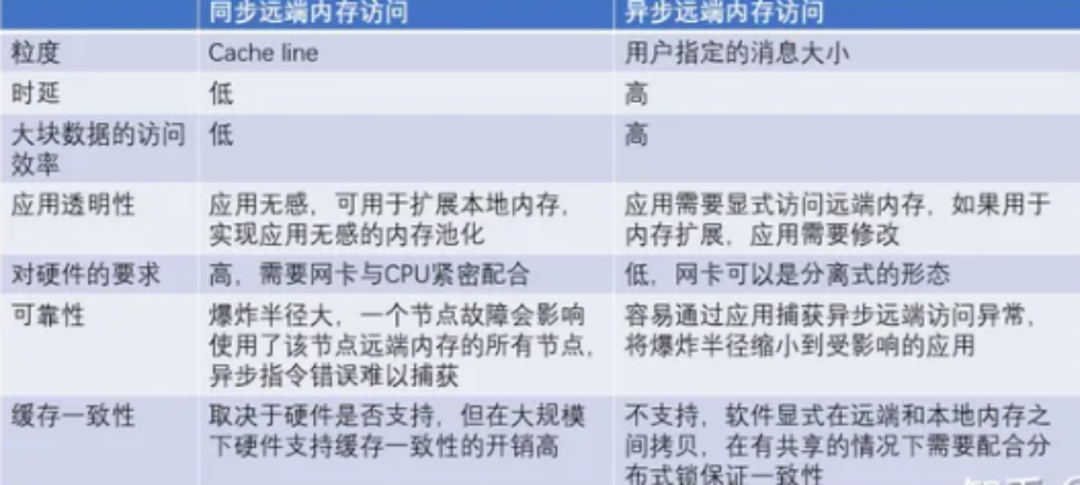
对于第二个场景(跨主机),跨主机的缓存一致性(CC)存在较大争议。一方面,大规模分布式一致性的实现难度大,是学术界长期未解的问题。另一方面,许多人对应用场景的理解并不清晰。
例如,在内存池化方面,许多人认为可以利用其他机器的空闲内存来提高集群的内存利用率,这种情况下不需要跨主机的CC,仅需Load/Store操作和主机内的CC。因为借用的内存仅由一台机器使用,出借方和其他机器均无需访问。
理想情况下,内存池化可以由多台机器共享内存,并支持跨主机的CC。这将带来诸多好处,如简化编程、减少数据拷贝、提高内存利用率。然而,现实中如何存储庞大的共享者列表(sharer list)?如何降低缓存失效(Cache invalidation)的高开销?尽管原文中提出了一些可行方案,例如扩大缓存粒度、将共享列表数据结构改为链表或分布式存储、控制共享者数量,甚至使用租约概念替代共享者列表,但最有效的方法还是与业务结合,因为业务最清楚同步时机和共享数据的使用情况。
最后,李博杰同学指出,跨主机的CC主要应用于Web服务、大数据、存储等领域。目前,他尚未想到在AI和高性能计算(HPC)领域中的应用,因为AI和HPC通常采用集合通信(collective operations),embedding也有逻辑上中心化的参数服务器(parameter server)来存储,对多机共享内存数据的需求似乎不大。
深入思考
针对夏晶老师的问题,笔者在实际工作中也有类似的疑问。在异构计算场景下(尤其是主机内CPU与设备之间),缓存一致性究竟能带来多大的价值?尽管使用CXL等声称支持缓存一致性的总线可以将数据访问延迟从PCIe的约500纳秒降低到50纳秒,实现了数量级的优化,但在仔细分析延迟后可以得出明确结论:直接的延迟优化主要是由于协议各层的优化带来的,而缓存一致性对延迟的优化效果缺乏量化数据支持。直到看到论文《CC-NIC: a Cache-Coherent Interface to the NIC》,许多疑问才得以解答。
在这篇论文中,作者利用X86 CPU UPI接口提供的缓存一致性实现了一个NIC设备,从而验证了缓存一致性对网卡的具体影响。
传统的PCIE接口设备
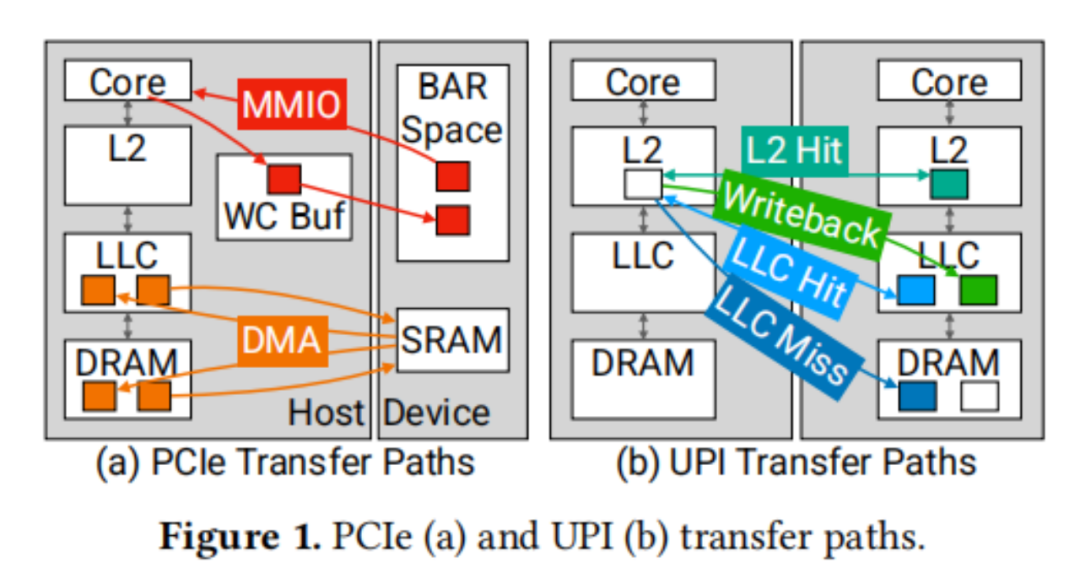
PCIe接口为设备与主机之间提供了一种非对称的通信方式。图1a展示了两种传输机制:MMIO和DMA,分别由主机和设备发起。主机对NIC的读写操作通过内存映射输入/输出(MMIO)实现。设备将内存区域映射到主机的地址空间,这些区域被设置为不可缓存(UC)或写组合(WC)内存类型。这样,主机可以对设备执行加载和存储操作,这些操作通过PCIe读写事务来执行。然而,UC和WC内存类型并不保证缓存一致性或在缓存层次结构中的操作。因此,CPU必须通过PCIe往返行程来加载数据,导致较高的访问延迟。在ICX CPU平台上,针对Intel E810 NIC的测试显示,中位数的MMIO读延迟分别为982纳秒(对于8字节数据)和1026纳秒(对于64字节AVX512数据)。而PCIe设备则通过直接内存访问(DMA)来读取和写入主机内存。DMA操作的缓冲区大小通常比64B的MMIO写组合缓冲区要大得多(例如,4KB),并且通常访问标准写回主机内存。尽管传统PCIe NIC不公开DMA延迟的统计数据,但预计其往返延迟与MMIO相当,大约在1微秒左右。
PCIe的特性和性能对主机-NIC接口的性能提出了挑战。具体来说,存在以下三个问题:首先,由于PCIe不是一致性互连,因此必须通过显式的PCIe事务来通信或更新本地数据结构。其次,PCIe操作的高延迟意味着减少互连遍历的次数对于实现低延迟的数据包传输至关重要。最后,通过PCIe进行的数据和元数据写入对CPU来说在吞吐量和高延迟停顿方面代价高昂。这些问题共同定义了PCIe接口的性能权衡。理想的设计目标是实现高数据包吞吐量、低延迟和高CPU效率,但PCIe的限制使得我们无法同时达到这三个目标。
当前的PCIe NIC设计通常优先考虑CPU效率和吞吐量,而牺牲一定的延迟。数据结构通常位于主机本地,并通过显式的PCIe事务来通知更新。主机在本地内存中维护数据包缓冲区和描述符环,以减少对数据结构访问和更新的CPU开销。在传输过程中,主机将TX数据包和TX描述符写入本地内存,并通过MMIO写入设备端维护的队列尾部寄存器。这种设计带来了一种权衡:在MMIO上最小化数据传输,但代价是增加了对主机内存中描述符和数据包的额外互连往返读取。
支持缓存一致性接口
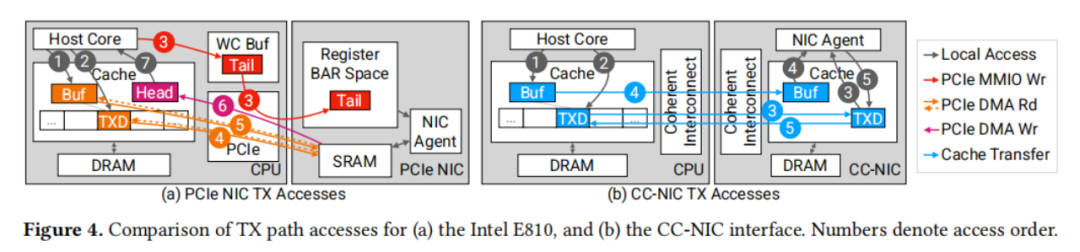
一致性互连技术,如UPI(Universal Platform Interface)和CXL(Compute Express Link),与CPU的内存数据路径紧密集成,提供了与PCIe根本不同的接口特性。如图1b所示,跨互连的访问可以针对DRAM和缓存进行。一致性协议管理着共享缓存的状态,确保在访问内存时,数据能够传输到本地缓存。这些协议要求写入者在写入之前获得缓存行的独占控制权,并使任何远程缓存中的副本失效。同时,它们也允许多个缓存共享对同一行的读取访问,并能够在缓存之间转发数据。总的来说,一致性互连提供了一种新的信号和数据结构共享形式,不受PCIe读写接口的限制。
与PCIe的非对称接口不同,一致性互连提供了一个对称的接口,消除了MMIO和DMA操作之间的权衡。然而,跨互连的传输性能受到缓存的存在和一致性状态的影响,这在延迟、内存控制器请求、协议元数据的开销以及往返时间方面都有所体现。在一致性互连的上下文中,对缓存行状态和缓存行为的控制手段有限,这为实现NIC数据结构带来了机遇和挑战。
文章指出了实现一致性互连NIC(CC-NIC)时需要考虑的三个设计因素:
1、一致性接口信令和共享数据结构:PCIe NIC通常使用MMIO机制来处理数据和元数据的DMA传输以及TX通知。这导致了在接收信号后,通过DMA检索TX元数据时需要多进行一轮互连往返。而缓存一致性通过硬件执行通知:当远程端执行写入操作时,一致性协议会自动使任何本地缓存的副本失效,并在随后的访问中获取新值。此外,一致性互连还允许在主机和NIC之间使用共享数据结构,从而实现共享缓冲池的管理。
2、数据传输机制和定位选择:一致性互连提供了多种数据传输机制。CC-NIC可以选择将写回内存作为目标,除了缓存绕过数据路径,还可以将数据结构定位在主机或NIC上,为CC-NIC提供了多种传输选项。跨互连的数据传输和缓存状态转换还取决于对象的当前缓存驻留情况、可能的预取以及由先前访问引起的缓存状态。因此,小型对象(如信号和描述符元数据)对布局非常敏感。
3、缓存管理:一致性协议在互连上交换缓存行的所有权。因此,远程访问可能导致在后续的本地访问时需要进行额外的通信。这对于生产者-消费者工作负载尤其成问题。例如,在典型的TX路径中,元数据和数据从主机传输到NIC,随后NIC执行数据传输,而数据不再被NIC需要。在一致性互连的上下文中,保留数据包缓冲区或描述符在NIC端的缓存中是没有帮助的;它为随后的主机访问增加了开销,因为这些访问将不得不执行远程缓存使失效操作。这表明,为了最小化开销,需要选择性地使缓存数据失效,这在典型的x86平台上是不受支持的,或者需要重新设计数据结构以避免这种访问模式。
CC-NIC设计
利用缓存一致性减少软件开销
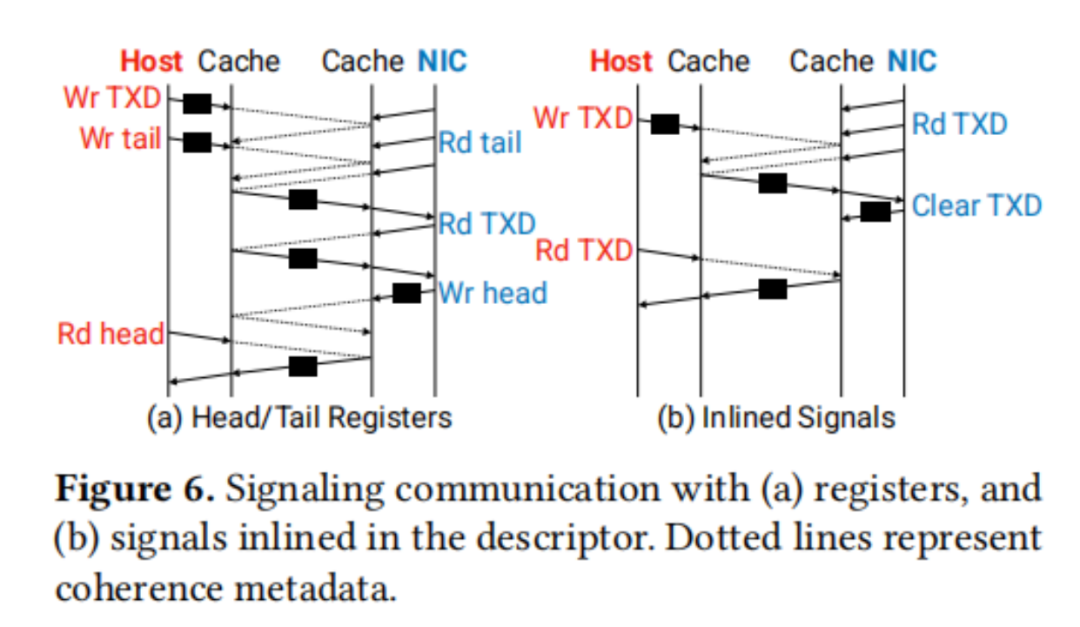
缓存一致性互连提供了一种底层硬件机制,它通过缓存状态的转换来传输数据并信令新数据的可用性。这种方法避免了传统基于软件的信令方式,即通过头部和尾部索引寄存器进行信令。在一致性缓存互连网络(CC-NIC)中,采用了描述符内联信号的方法,通过一个标志来指示描述符是否已经准备好供消费或处于空闲状态。
将信号与描述符集成在一起的设计,消除了对每个信号单独进行缓存行传输的需要,从而节省了跨socket缓存行访问的延迟,如图6所示。在传输过程中,NIC不再需要轮询包含队列尾部索引的寄存器,而是直接轮询环中的下一个描述符。描述符的元数据中包含了一个就绪标志,主机在写入描述符的其他字段后会设置这个标志。一旦这个标志被设置,NIC就能够在同一访问中接收到信号和描述符的内容,实现了事件驱动的处理方式。
为了进一步优化信令通信,一个一致性的NIC专用集成电路(ASIC)可以直接处理一致性协议消息。在这种设计中,设备不是通过缓存轮询抽象来访问描述符,而是直接响应通过互连接收到的snoop消息。将一致性消息作为信号进行处理,避免了在存在大量队列计数时,基于软件的轮询所面临的可扩展性限制。这种设计不仅提高了效率,还增强了系统的扩展性和性能。
元数据传输的理想数据路径

由于一致性互连可能从DRAM或多个缓存层次结构检索数据,我们测量每种传输情况的性能,以了解信号通信的性能影响。图7显示了在Ice Lake (ICX)和Sapphire Rapids (SPR)服务器平台上,对齐的64B对象在各种缓存状态下的中位数访问延迟。我们发现,访问远程未缓存的DRAM大约是本地DRAM访问延迟的两倍。访问远程L2缓存中的数据更快:在SPR上为171纳秒,在ICX上为114纳秒,对于在远程socket上托管的内存(rh情况),对于在本地socket上托管的内存(lh)则略高。
在这些情况下,远程CPU已将其L2缓存中的一行写入并保留在M(修改)状态,然后本地读取器访问该地址。当远程L2缓存中存在M状态对象时,它不能存在于任何其他L2缓存中,因此总是本地L2缺失。对于reader homed的内存,读者的L2缺失导致除了向写入者的缓存请求远程请求外,还导致推测性内存读取。这种推测性读取是不需要的,并且当对象是reader-homed时,会增加总线利用率并降低性能,因为增加了不必要的流量。无论homing如何,远程L2访问都比远程DRAM访问更快,表明缓存到缓存传输实现了最佳延迟。CC-NIC在其设计中应用了这些观察结果。CC-NIC将元数据结构放置在writer-homed的内存中:TX描述符环位于主机上,RX环位于NIC home的内存中。它通过使用定期缓存访问而不是针对内存的目标非时间存储来增强缓存到缓存传输的可能性。然而,NIC接口的工作集大小影响性能,预取访问也是如此。
确定最优的内存数据布局
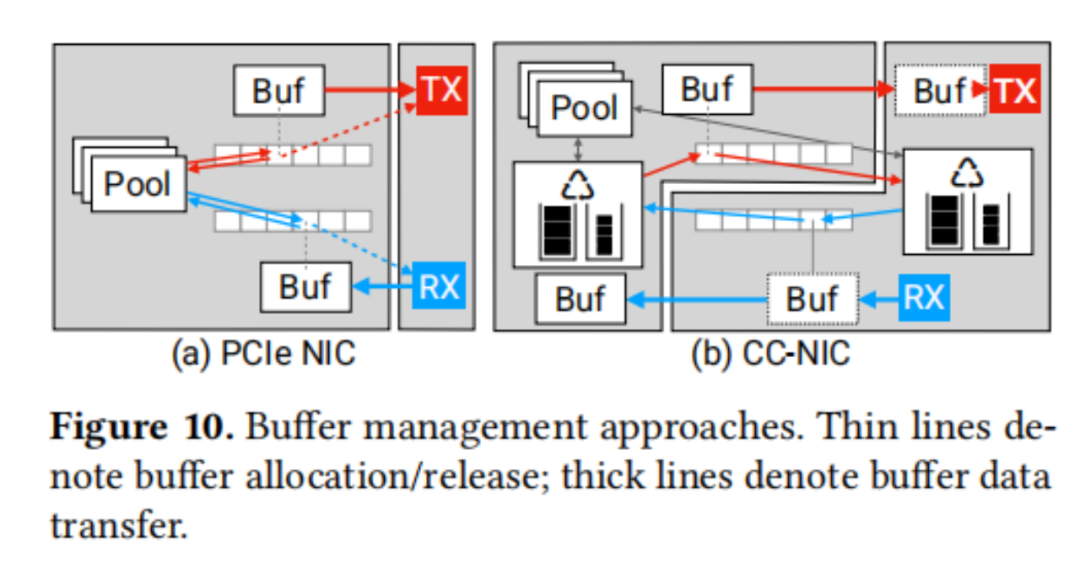
NIC元数据,如描述符和信号,展示了每个描述符由一方写入并由另一方读取的生产者-消费者访问模式。例如,TXDs由主机写入,RXDs由NIC写入。性能取决于缓存行的访问模式,因为这决定了为确保一致性所必需的协议通信。
在典型的PCIe NIC接口中,RX缓冲区由主机在NIC实际接收数据包之前分配并发布到RX描述符。这使得在分配缓冲区到RX描述符时无法应用对RX数据包突发的知识。CC-NIC通过利用缓存一致性共享缓冲区管理来克服这个问题。缓存一致性允许主机和NIC同时访问缓冲池数据结构,而没有与同时进行的PCIe DMA和CPU访问(例如,缺乏原子操作)相关的限制。共享缓冲池结构允许NIC在传输后将TX缓冲区释放回池。同样,NIC可以根据需求分配RX缓冲区并将它们的地址写入RX描述符环。这导致了一个对称的设计,避免了额外的队列来释放已完成的TX数据包缓冲区和发布空白的RX数据包缓冲区。最后共享缓冲区管理使CC-NIC的缓冲区分配和描述符布局优化成为可能。图10比较了CC-NIC的缓冲区管理设计与传统PCIe NIC的设计。
权衡高带宽和低延迟需求
使用内联信号时,主机和NIC直接轮询描述符环内存而不是单独的寄存器。这导致在写入和轮询一系列小于64B缓存行大小的描述符时,缓存行在socket之间抖动,增加了延迟。缓存对齐的描述符通过避免抖动来实现低延迟,但会浪费大量空间(例如,64B中的48B)。为了平衡这些因素,CC-NIC实现了一个优化的解决方案:它将多达4个16B描述符打包到一个缓存行中,未使用的条目清零,并使用每个缓存行一个信号。如果消费者在中间遇到一个空白描述符,它将跳过到下一个缓存行以轮询后续的描述符组。这在高吞吐量情况下避免了浪费空间,同时在低吞吐量、非批处理的情况下避免了抖动。通过每个描述符组使用一个信号,CC-NIC应用批处理来充分利用每个描述符缓存行。
量化评估
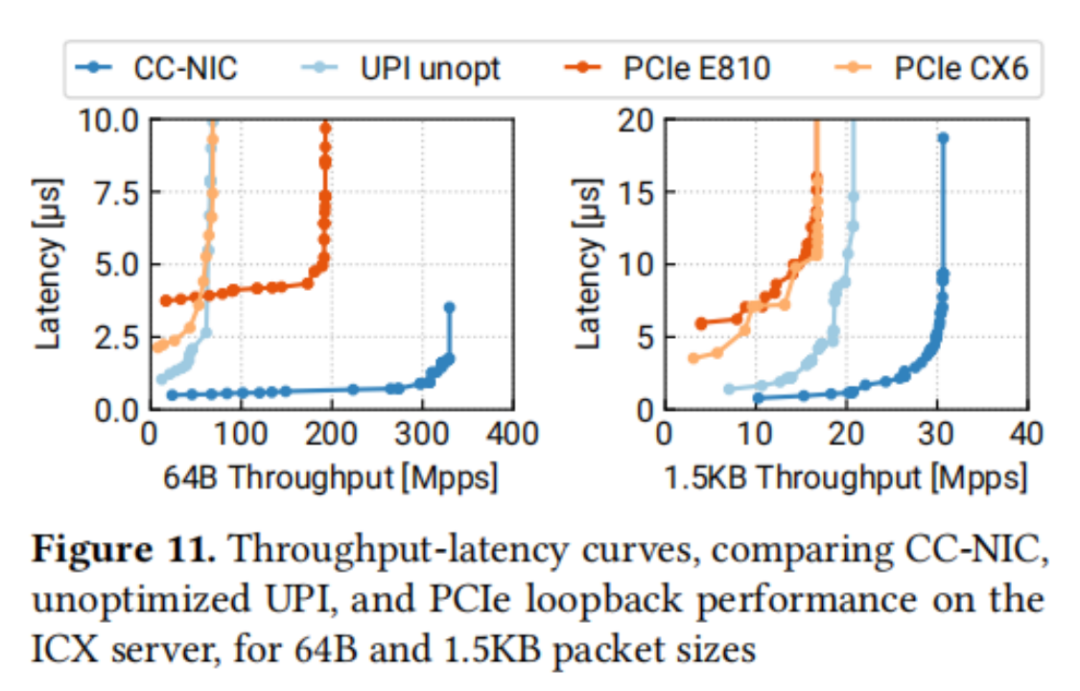
图11显示了在ICX服务器上的四种主机-NIC接口的比较:CX6和E810 PCIe NIC,以及在UPI上实现的E810接口的简单实现,以及CC-NIC。这些结果表明,CC-NIC在延迟改进和高于PCIe的吞吐量方面展现了巨大优势。CC-NIC的最小延迟比CX6和E810分别低77%和86%。CC-NIC还实现了比E810和CX6高1.7倍和4.3倍的峰值包速率。对于1.5KB数据包,CC-NIC观察到的比PCIe NIC高1.8倍的数据吞吐量。
总结分析
CC-NIC设计的核心内容除了使用支持缓存一致性的总线接口外,以下几个关键内容对整体性能的提升至关重要:
1、内联信号:将通知功能内联到描述符环,对于64B数据包,内联信号将最小延迟减少了37%,并将最大包速率提高了1.3倍。
2、描述符布局:由于UPI缓存传输的64B粒度以及内联信号所需的直接描述符轮询,内存布局显著影响性能。通过将每个描述符缓存对齐(填充)实现低延迟,避免了抖动。将单个16B描述符打包到一个缓存行中通过2.9倍提高了吞吐量。优化的描述符布局在每个缓存行中结合了一个单一的信号和一组描述符。这种布局在匹配最佳最小延迟的同时,实现了3.0倍的吞吐量提升。
3、批处理:批处理对于吞吐量至关重要,对于PCIe NIC,TX批处理允许使用一个MMIO门铃提交多个数据包,更大的批处理尺寸减少了MMIO操作的速率。对于CC-NIC,TX批处理允许在单个缓存行内传输多个描述符。主机端RX批处理主要影响描述符环和缓冲区池上的访问模式,决定了缓冲区是单独还是批量处理。
我的回答
结合上述分析,对本文最初提出的问题(本地CPU和设备互联场景)的回答是:
缓存一致性互连技术为挂接的外部设备提供了实现高性能的可能性,但它的应用并不局限于作为传统接口的简单替代。要充分利用缓存一致性的优势,需要对CPU与外部设备之间的交互机制进行彻底的重构。在这个重构过程中,需要深入考虑几个方面来最大化缓存一致性的收益,比如内联信号通知机制、优化的数据和描述符布局以及批处理机制等。只有通过这样的软硬件融合优化,才能实现一个高效、可扩展和吞吐延迟均衡的系统。
-
处理器
+关注
关注
68文章
20344浏览量
255360 -
cpu
+关注
关注
68文章
11337浏览量
226009 -
缓存
+关注
关注
1文章
248浏览量
27828 -
异构计算
+关注
关注
2文章
112浏览量
17247
原文标题:在异构计算场景下,缓存一致性究竟能带来多大的价值?
文章出处:【微信号:SDNLAB,微信公众号:SDNLAB】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
介绍ARM存储一致性模型的相关知识
如何解决数据库与缓存一致性

一致性规划研究
加速器一致性接口
Cache一致性协议优化研究
自主驾驶系统将使用缓存一致性互连IP和非一致性互连IP

介绍下cpu缓存一致性(MESI协议)
使用CCIX进行高速缓存一致性主机到FPGA接口的评估


Redis缓存与Mysql如何保证一致性?

深入理解数据备份的关键原则:应用一致性与崩溃一致性的区别




评论