 FPGA中有状态表项的存储与管理
FPGA中有状态表项的存储与管理

编 者 按
一篇2014年的论文:《CACHE FOR FLOW CONTENT: SOLUTION TODEPENDENT PACKET PROCESSING IN FPGA》,主要讲述在FPGA中有状态表项的存储与管理。感兴趣的可以阅读原文。
报文的依赖性
在CPU中,存在一种“write-read miss”的场景,即新的数据还未写回就要去读存储器,导致数据依赖。
在FPGA与ASIC中报文的流水线处理中,也存在报文的依赖性问题。在流水线结构中,每个报文占据固定的时间周期数,处理时牵涉到对表项的读和写。下图为例:
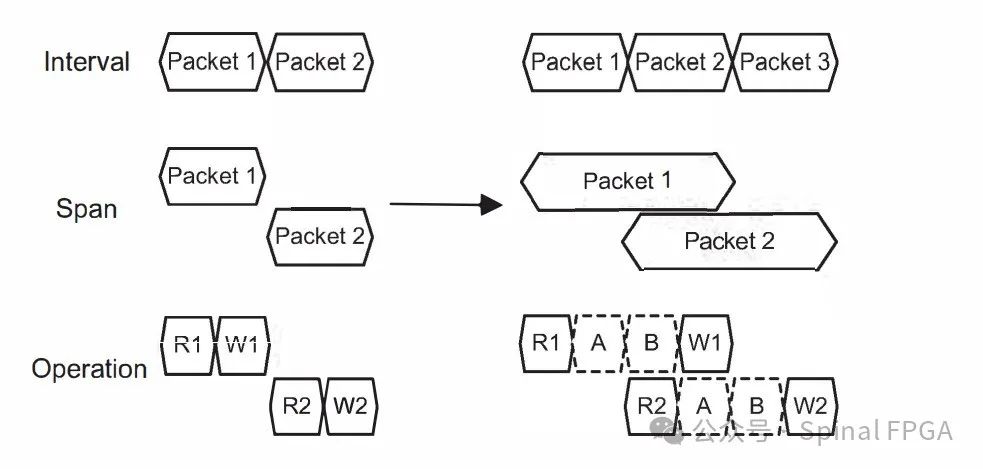
理想情况下应为左图,packet1的写操作从时钟周期的角度来讲发生在packet2的读操作之前,如此两个报文之间即使存在相互依赖性也没有任何影响。
然而随着操作变得复杂,可能导致到图右的状态,即Packet2的读请求发生在Packet1的写请求之前,如果packet2和packet1之间存在依赖性,则此时将会发生功能型的错误:
常见的依赖解决方法&劣势
第一种最简单的方法就是碰撞预防:

通过插入空拍来避免数据挨的太近,当然坏处就是带宽的浪费,自然下下之策。
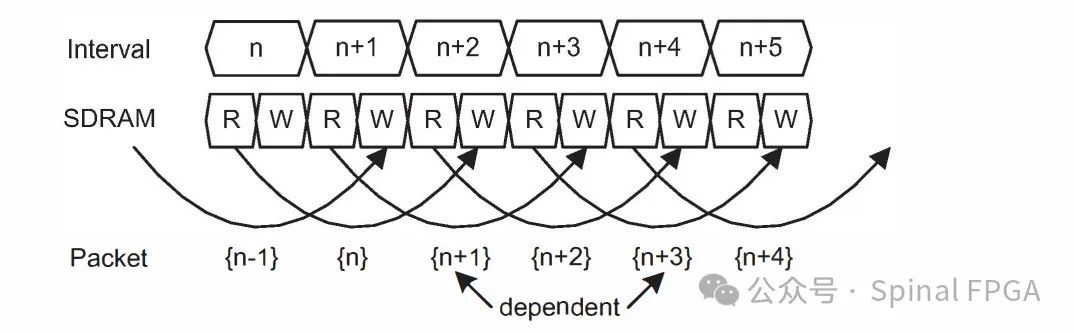
第二种方法即碰撞补偿。碰撞补偿允许数据以背靠背的形式呈现,当数据冲突将要发生时,相同数据流的信息将会被合并处理:
如上图所示,假定包处理的跨度为三个报文,当一个数据包n到达时,其会与n+1、n+2进行比较,如果n依赖于n+1或者n+2,则其信息将会合并到n+1或者n+2中进行处理,n将会被禁用。这种方式对于所有的信息都由数据包本身携带是没有问题的,但如果有些信息是由流当前状态、数据包信息、中间结果一些列所决定的那么久不太适用。考虑下面的例子:
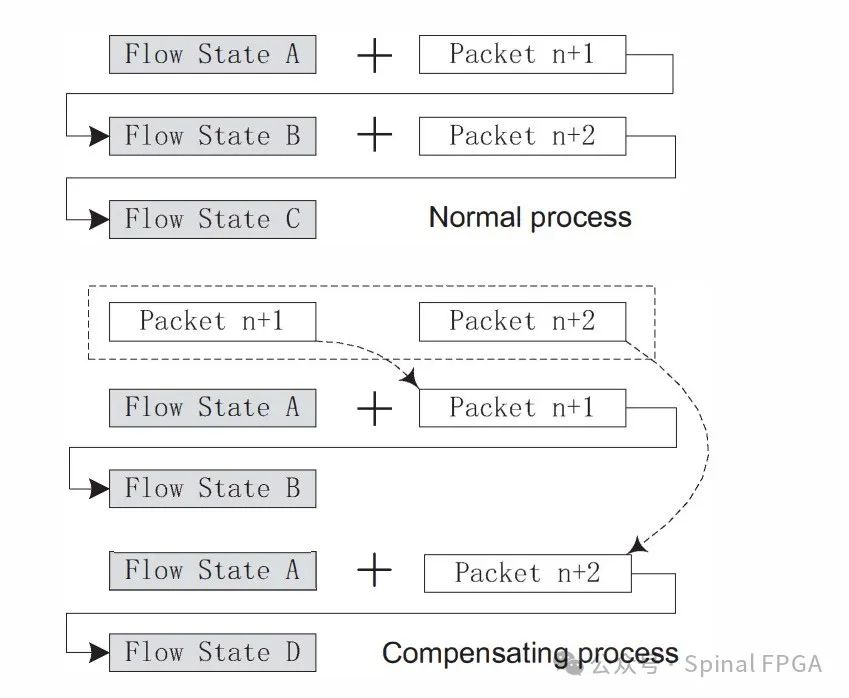
正常情况下会进入Flow StateC、在进行合并后将无法进入到StateC。
第三种方法就是CPU Cache的概念。
CFC
在CFC中,Cache基于流的关键信息作索引(如五元祖哈希)
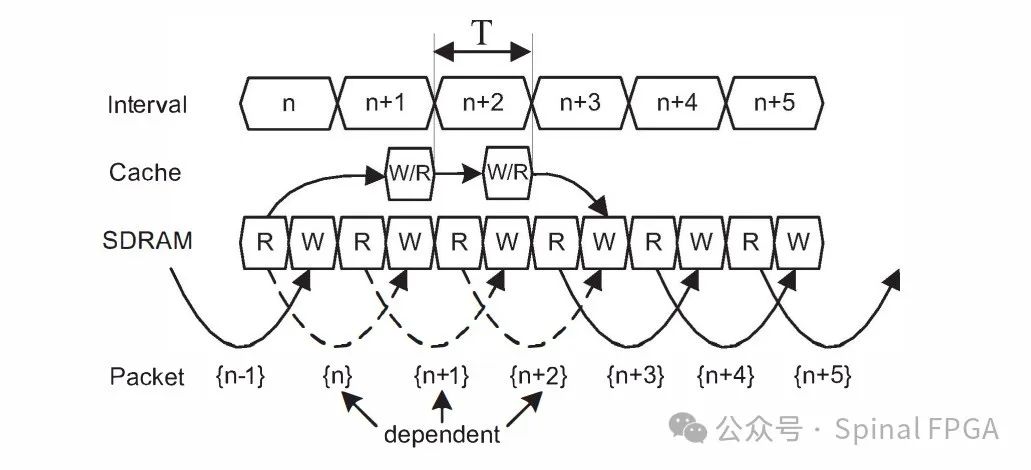
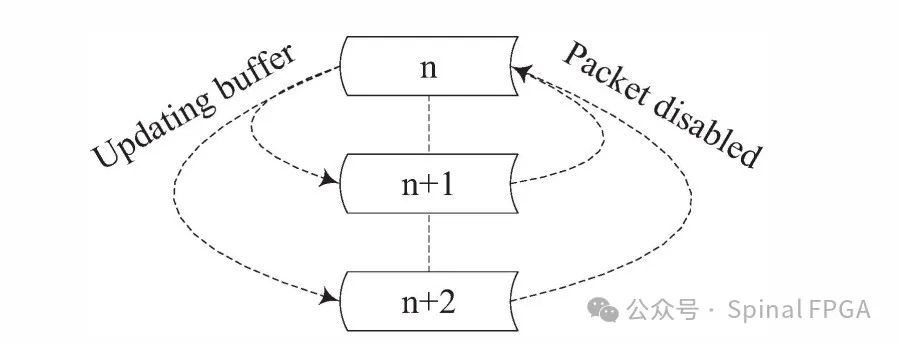
上图中n、n+1、n+2存在依赖关系,n、n+1的写操作将会被写入到Cache中。
这里有一点需要注意的是对于任何一个报文而言,其从数据Cache读出到数据写回的时钟数不应超过报文在流水线中占据的时钟周期数T(如果超过了则意味着一个报文无法在时钟周期T内完成数据的处理)。
这里的Cache可以认为是一个深度为1的全关联Cache。对于Cache的容量的考虑可以参考下图:
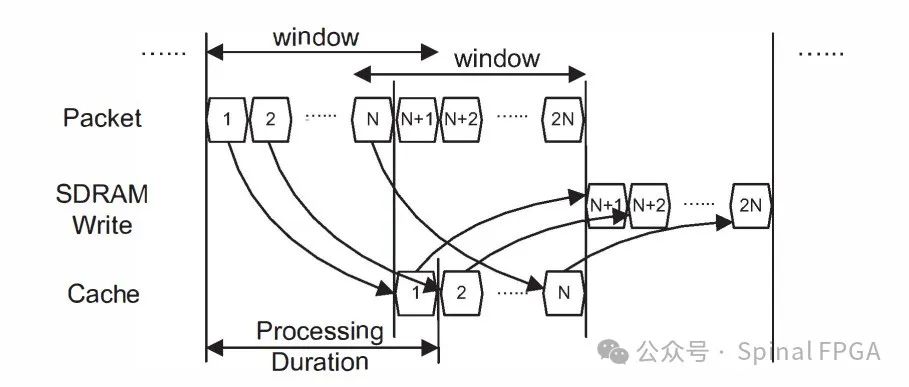
指定一个窗口,其跨度为一个数据包从进入处理到写回的周期,窗口随着数据包滑动。上图中窗口的宽度为N+1个数据包(数据包1的状态写回发生在数据包N+1处),则上图中需要的缓存数即为N。
每个缓存的组织形式如下所示:

Content为Cache的主要内容,用于存储流的相关信息。Tag和Validity为辅助信息。Tag可以为流的hash值。通过hash比较判断是否存在匹配。Validity则用于标识该条流是否有效。
对于Cache中每个cache entry的维护,可以采用如下策略。为每个entry维护一个计数器。计数器的初始值为0,标识无效,其他值则有效。当一个entry被建立使用时,其计数器值设置为N,此后每进入一个数据包值就减1,直到为0,标志其无效,将其数据写回SDRAM。但如果来了一个命中该entry的数据,那么其计数器值将直接恢复为N。如此,对于任何一个到来的数据报文,其都可以找到一个匹配的entry或者一个空的entry来进行缓存(其实这里的替换策略就是LRU)。
-
FPGA
+关注
关注
1664文章
22508浏览量
639427 -
asic
+关注
关注
34文章
1278浏览量
124964 -
存储器
+关注
关注
39文章
7758浏览量
172227 -
流水线
+关注
关注
0文章
128浏览量
27276
原文标题:论文学习——CFC:Cache For Flow Content
文章出处:【微信号:Spinal FPGA,微信公众号:Spinal FPGA】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
状态机编程实例-状态表法
![基于有限<b class='flag-5'>状态</b>机[8]的DSR路由<b class='flag-5'>表项</b>设计实现方法](https://file.elecfans.com/web1/M00/C7/EF/o4YBAF9uGXCARuZCAACLqxbTmxM551.png)
基于FPGA的视频图形显示系统的DDR3多端口存储管理设计
ACPI高级电源管理的电力状态
MCU低功耗状态表模式介绍
求助,同步二进制减法计数器的状态表该怎么画?
TCAM表项管理算法研究
TCAM路由表项管理算法优化研究
高速数据存储管理设计和基于FPGA高速图像数据的存储及显示设计
基于有限状态机的FPGA DSR路由表项设计和实现方法
FPGA:状态机简述

linux 中 ACPI 电源管理 G 状态、S 状态、D 状态、C 状态、P 状态

hash算法在FPGA中的实现(3)



评论