 FPGA和ASIC在大模型推理加速中的应用
FPGA和ASIC在大模型推理加速中的应用

今天我们再来看一篇论文。
随着现在AI的快速发展,使用FPGA和ASIC进行推理加速的研究也越来越多,从目前的市场来说,有些公司已经有了专门做推理的ASIC,像Groq的LPU,专门针对大语言模型的推理做了优化,因此相比GPU这种通过计算平台,功耗更低、延迟更小,但应用场景比较单一,在图像/视频方向就没有优势了。
整个AI的工业界,使用FPGA的目前还比较少,但学术界其实一直在用FPGA做很多的尝试,比如通过简化矩阵运算,使FPGA可以更好的发挥其优势。
今天看的这篇论文,是一篇关于FPGA和ASIC在大模型推理加速和优化方向的综述,我们看下目前的研究进展。
Introduction
Transformer模型在自然语言处理(NLP)、计算机视觉和语音识别等多个领域都取得了显著的成就。特别是,这些模型在机器翻译、文本分类、图像分类和目标检测等任务中表现出色。Transformer模型需要比传统神经网络(如循环神经网络、长短期记忆网络和卷积神经网络)更多的参数和计算操作。例如,Transformer-B模型包含1.1亿参数,执行21.78亿次浮点运算,而Vision Transformer (ViT)-B模型包含8600万参数,执行16.85亿次浮点运算。
GPU的局限性:
尽管GPU在加速大型深度学习模型方面发挥了主要作用,但它们的高功耗限制了在边缘环境中的适用性。因此,大多数大型深度学习模型在GPU服务器环境中处理,给数据中心带来了沉重的负担。
FPGA和ASIC的优势:
FPGA和ASIC在并行处理、设计灵活性和功耗效率方面具有优势,被用作各种深度学习模型的专用加速平台。通过压缩和设计优化技术,可以优化FPGA和ASIC上的加速器性能,如吞吐量和功耗效率。
该论文对FPGA和ASIC基于Transformer的加速器的最新发展进行全面回顾,探索适合于FPGA/ASIC的模型压缩技术,以及对最新的FPGA和ASIC加速器的性能进行比较。
研究背景
论文中这部分内容比较长,对Transformer模型和Vision Transformer (ViT)模型的进行了详细介绍,包括它们的基本组件、不同的模型变体以及它们在计算上的特点,包含了很多理论部分,有兴趣的读者可以看原文,我只总结一下大概的内容。
Transformer模型主要由编码器(Encoder)和解码器(Decoder)组成。编码器处理输入序列生成上下文向量,而解码器使用编码器的上下文向量和前一步的输出标记来生成下一步的标记。编码器和解码器的核心操作模块包括多头自注意力(MHSA)和前馈网络(FFN)。通过MHSA,Transformer能够训练 token 之间的全局上下文信息,从而实现高精度。基于Transformer架构的也有不同的模型,如BERT、GPT等,他们的预训练和微调方法也均有不同。这些模型在不同的NLP任务中表现出色,但大型模型如GPT-3由于参数众多,难以在FPGA或ASIC上实现。
Vision Transformer (ViT)是针对计算机视觉任务提出的Transformer模型,主要用于图像分类。与原始Transformer架构不同,ViT只使用编码器,并且在编码器之前进行LayerNorm操作。ViT通过将输入图像分割成固定大小的patches,然后通过线性投影生成Transformer输入tokens。ViT的编码器操作和图像分类任务的执行方式也有详细说明。基于ViT架构也有多种模型变体,如DeiT、Swin Transformer和TNT,这些模型通过不同的方式改进了ViT,例如通过知识蒸馏、层次结构和窗口机制、以及改进的patch嵌入方法来提高性能。
Transformer模型压缩
要想在FPGA/ASIC上应用Transformer,肯定需要对模型进行改进,要让算法对硬件实现更加的友好。目前有常用的方式:
量化(Quantization):
量化是将模型的参数和激活值从通常的32位浮点数转换为低精度数据格式(如INT8或INT4)的过程。这样做可以有效减少内存需求,同时加快计算速度并降低功耗。比如线性量化的过程,并通过量化感知训练(QAT)或后训练量化(PTQ)来恢复因量化而可能损失的准确性。还可以通过优化权重和激活值的量化策略来实现高压缩比和最小的准确性损失。
剪枝(Pruning):
剪枝是通过识别并移除模型中不重要的参数来减少模型大小的方法。剪枝可以基于不同的粒度,如细粒度、标记剪枝、头部剪枝和块剪枝。结构化剪枝(如标记、头部和块剪枝)会改变模型结构,而无结构化剪枝(如细粒度剪枝)则保留了模型结构,但可能导致内存利用效率低下。合理的Pruning可以在内存效率和准确性之间找到平衡点来实现SOTA性能。
硬件友好的全整数算法(Hardware-friendly fully-integer algorithm):
Transformer模型中的非线性操作(如Softmax和GeLU)需要高精度的浮点运算,这在FPGA或ASIC硬件上难以高效实现。为了解决这个问题,研究者们提出了一些近似算法和量化技术,以便在硬件上以整数形式处理这些非线性函数,从而减少对浮点运算的需求。
硬件加速器设计优化
在这一节,论文中详细探讨了针对FPGA和ASIC平台的Transformer模型加速器的各种优化技术。其实这一节的内容跟上一节是一个道理,都是在讲如何让大模型算法更好的适应FPGA/ASIC的平台。论文中也是花了很大的篇幅对每一个优化方法做了详细分析,这里我也只是总结一下论文中使用到的优化方法,具体的内容还是建议有兴趣的读者看原文。
稀疏性(Sparsity)
计算优化(Computing Optimization)
内存优化(Memory Optimization)
硬件资源优化(Hardware Resource Optimization)
芯片面积优化(Chip Area Optimization)
软硬件协同设计(Hardware-Software Co-design)
这些优化技术都可以帮助提高加速器的性能,降低功耗,并实现更高效的Transformer模型推理。
性能比较
这一部分主要是对基于FPGA和ASIC的Transformer加速器的性能进行了分析和比较。
FPGA加速器性能比较:
下面这个表,展示了不同的加速器模型使用在数据格式、工作频率、功耗、吞吐量(GOPS)、推理速度(FPS)以及所使用的FPGA资源(如DSP、LUT、FF和BRAM)的统计。
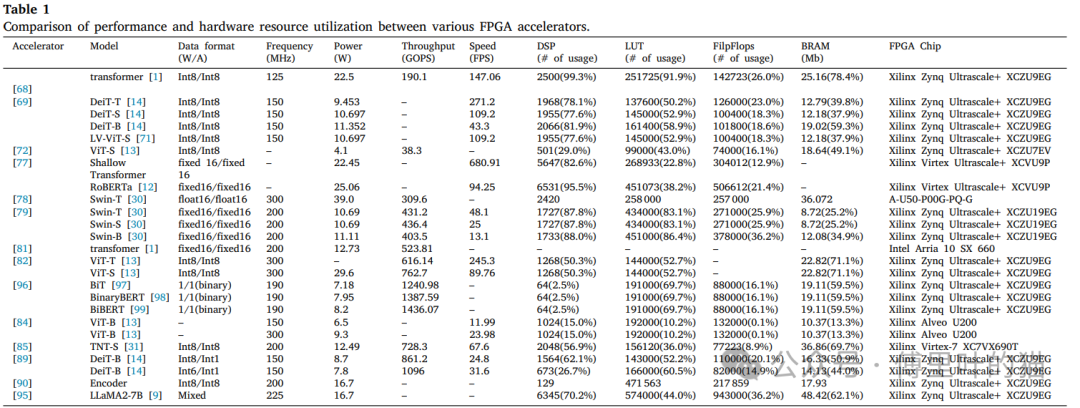
对于基于FPGA的加速器,分析的这些指标都是FPGA芯片的关键资源。
可以看到,这些模型其实都有各自的优势和劣势,某些设计可能在吞吐量上有优势,而其他设计可能在能效比或推理速度上有优势。
ASIC加速器性能比较:
下面这个表是不同模式在数据格式、工作频率、制造工艺、芯片面积、功耗、吞吐量以及片上内存大小的统计。
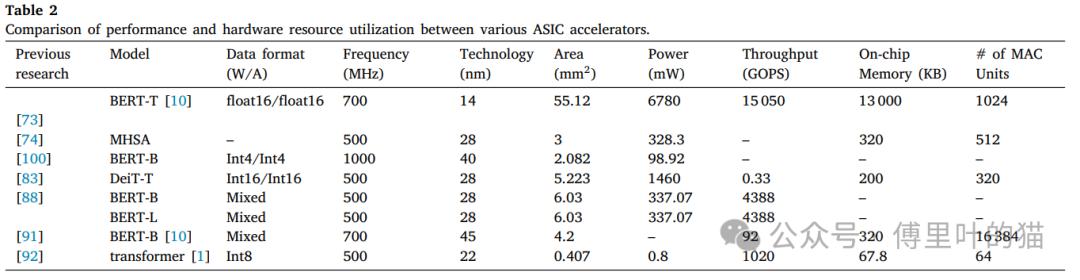
对于ASIC加速器,性能比较则侧重于诸如芯片面积和技术节点等ASIC设计的关键指标。这些因素影响着ASIC芯片的成本、能耗以及计算效率。
Further work
在前面的几节中,论文中调研了不同模型在FPGA/ASIC上的性能比较,本节作者提出了当前FPGA和ASIC基Transformer加速器研究的一些潜在方向和未来趋势。
复杂任务的加速器:
除了传统的分类任务外,检测和分割等更复杂的任务对计算能力的要求更高。学术界正在探索如何通过剪枝和优化来降低这些任务所需的能量消耗。
异构计算平台:
异构平台也是目前非常火的一个方向,如何将CPU、GPU、FPGA和ASIC集成到一个平台上,以利用每种处理器的优势。这种异构架构可以提高吞吐量,降低延迟,并提高能源效率。
混合网络性能提升:
结合卷积神经网络(CNN)和Transformer的混合网络正在受到关注。
调度算法和通信协议:
为了充分利用异构计算平台的潜力,需要开发高效的调度算法和通信协议,优化处理器之间的数据流,减少瓶颈,提高整体性能。
硬件-软件协同设计:
软硬件协同设计方法可以进一步优化Transformer模型的加速。通过迭代模拟和优化,可以找到最佳的硬件和软件配置,以实现最低的延迟和最高的能效。
新应用和模型的开发:
随着新技术的发展,如扩散模型和LLM,需要开发新的应用和模型来利用这些技术。这可能涉及到开发新的硬件加速器,以支持这些模型的特定计算需求。
其实论文中讲了这么多,我最关心的还是商业的部署,GPU的功耗就决定了它的应用场景不会特别广,像边缘计算设备,基本告别那种大功耗的GPU,FPGA/ASIC在这方面就会显得有优势。但目前来看,除了上面提到的LPU,现在ASIC已经在很多场景使用用于做一些“小模型”的推理任务,像现在比较火的AI PC,AI手机,都是在端侧运行参数量较小的大模型,但FPGA在AI 端侧的应用还任重而道远。
-
FPGA
+关注
关注
1664文章
22559浏览量
640550 -
asic
+关注
关注
34文章
1281浏览量
125068 -
AI
+关注
关注
91文章
41920浏览量
303002 -
深度学习
+关注
关注
73文章
5614浏览量
124731 -
大模型
+关注
关注
2文章
3861浏览量
5290
原文标题:FPGA/ASIC在AI推理加速中的研究
文章出处:【微信号:傅里叶的猫,微信公众号:傅里叶的猫】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
GPU、FPGA和ASIC鏖战AI推理
到底什么是ASIC和FPGA?
大模型推理显存和计算量估计方法研究

好奇~!谷歌的 Edge TPU 专用 ASIC 旨在将机器学习推理能力引入边缘设备
压缩模型会加速推理吗?
FPGA_ASIC-MAC在FPGA中的高效实现

如何加速大语言模型推理
Neuchips展示大模型推理ASIC芯片
中国电提出大模型推理加速新范式Falcon




评论