 浪潮信息AI存储性能测试的领先之道
浪潮信息AI存储性能测试的领先之道

MLCommons,一个致力于推动全球 AI系统发展的顶级工程联盟,汇聚了包括谷歌、斯坦福大学在内的众多顶尖企业和研究机构。作为该联盟的创始成员之一,浪潮信息自2020年起便积极参与其中,共同探索AI技术的无限可能。近日,在MLCommons的子项目MLPerf Storage v1.0性能基准评测中,浪潮信息再度展现了在AI存储领域的卓越实力。
MLPerf Storage v1.0评测旨在全方位考量AI系统在端、边、云等场景下的训练、推理、存储及安全性能。此次评估分为封闭赛道和公开赛道两大类别。浪潮信息此次选择了封闭赛道,要求严格遵循既定配置和代码规范,以确保所有提交结果的公平性和可比性,在既定规则下更能客观真实地展现产品的实际能力。公开赛道允许在基准测试和存储系统配置方面有更多的灵活性,以展示对AI/ML社区有益的新方法或新功能。
MLPerf Storage v1.0工具是一个开源工具,可以从Github平台下载。该工具允许所有厂商加入Storage社区,发表见解,提出发现的问题和改进意见。在此次测试中,浪潮信息率先发现了测试负载CosmoFlow模型提交规则标准的问题(GPU利用率实际达不到90%)。通过多次横向交流和社区沟通,浪潮信息得到了Micron、NVIDIA等多家厂商的积极响应,最终推动了社区对CosmoFlow模型提交规则的修改(GPU利用率要求降至70%)。这一举措不仅体现了浪潮信息在测试过程中的积极参与,也展示了其作为国内参与该社区工具构建的先驱厂商的实力。
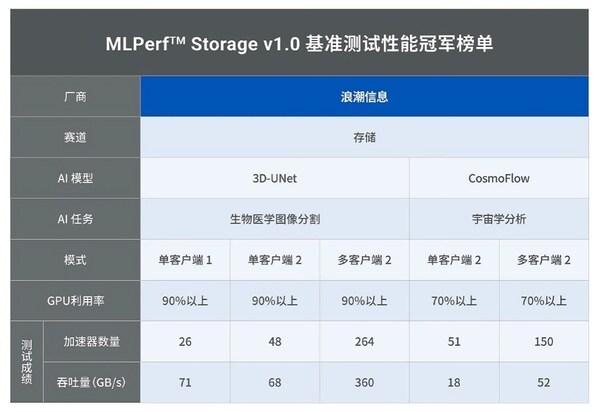
值得一提的是,MLPerf Storage v1.0评估采用了三种具有代表性的测试模型,分别是图像分割领域的3D-UNet模型(平均文件大小146M,采用NPZ格式)、HPC领域的CosmoFlow模型(平均文件大小2.2M,采用TFRecord格式)以及图像分类领域的ResNet50模型(平均文件大小百KB,采用TFRecord格式)。这些测试模型的选择,不仅全面覆盖了AI应用的主要场景,也确保了评估结果的客观性和准确性。
核心概念
模拟加速器:通过引入非真实的GPU/TPU等加速器,为测试者提供了一个无需实际硬件加速器的测试环境,旨在降测试成本、保证公平性的同时,提升测试效率。(本次社区提供模拟加速器H和模拟加速器A)。
加速器利用率(Accelerator Utilization ,AU):衡量模拟加速器在基准测试过程中利用效率的关键指标,其计算公式为:

主机节点(Host Node):即客户端,是运行MLPerf存储基准代码的机器,类似于AI训练集群中搭载GPU的计算服务器。主机节点的性能与配置对存储系统的测试结果具有重要影响。
提交规则
MLPerf Storage的提交规则旨在确保测试结果的统一性和可比性。主要规则包括:
前置条件(单主机提交规则):所有提交结果必须满足AU在3D-UNet和ResNet50上达到90%,在CosmoFlow上达到70%及以上。同时,禁止使用主机节点缓存。
多主机提交规则:在多主机测试环境中,每个主机节点的模拟加速器数量必须一致,且所有主机的测试运行参数也必须保持一致。
从 MLPerf Storage的基本概念和提交规则来看,社区致力于通过统一标准和减少变量来确保测试结果的统一、公正和可评估性。然而,在实际测试中,仍存在两个难以统一的影响因素:一是存储架构的多样性,涵盖集中式、分布式及云端等多种形态;二是存算节点配置非标准化,如主机与存储节点配置不统一。这些因素的共同作用下,使得单一的测试指标难以全面反映各厂商存储系统在AI场景下的适配程度。性能,无疑是AI存储的一大关键需求。浪潮信息在MLPerf Storage v1.0基准测试中取得5项性能全球第一,单节点性能达到120GB/s,充分展示了在AI存储性能测试领域的领先优势。然而,若仅将存储带宽作为评估标准,采用如Vdbench、FIO等专业存储测试软件即可满足需求,无需借助MLPerf Storage这类针对AI场景的基准测试工具。事实上,AI对存储的需求远不止于产品性能本身,而是要求整体解决方案能够高度适配AI应用场景。那么,如何科学衡量一套存储系统是否适合AI场景呢?基于MLPerf Storage的提交规则,我们不妨回归AI存储的本质——即最大限度提升客户端资源利用,减少资源浪费,以支撑更多的GPU计算。
MLPerf Storage的核心要求聚焦于两大要素:一是加速器利用率(AU)需达到90%或70%以上;二是“最大加速卡数”,即在固定AU阈值下,存储系统所能支撑的单节点最大加速卡数及多节点下每个客户端的最大加速卡数。这里的“最大”不仅意味着带宽要高,同时要求时延要低。在计算节点提供固定网络带宽的条件下,时延的降低意味着在相同时间内能够供给的数据量增多,从而支持更多的加速卡。

在客户端与存储侧网络连接带宽一定的情况下,单次IO时延的降低将直接导致每秒钟能够提供的文件数量增多,进而提升客户端实际表现的带宽。由于主机节点提供的网络带宽存在理论上限,因此,在存储集群吞吐量略大于客户端网络总带宽的情况下,既要确保AU在90%以上,又要尽可能跑满每个客户端的理论带宽,以实现最佳存储性能。
然而,在实际应用中,由于软硬件开销的存在,客户端网络往往难以完全跑满。因此,在AU达到90%的条件下,尽可能提高主机节点带宽的利用率,成为最大化计算资源、避免网络资源浪费的关键。这实际上就涉及到了主机节点网络利用率的计算,其公式为:

鉴于各厂商解决方案中主机节点连接存储节点的网络理论带宽是固定的,我们可以将所有厂商的解决方案归一化到网络利用率这一指标上,从而在不考虑存算配置差异的情况下,对各厂商解决方案的表现进行客观分析。以3D-UNet加速器H多客户端下的测试结果为例,通过整理各厂商的测试结果,我们得到了该模型下的网络利用率数据:
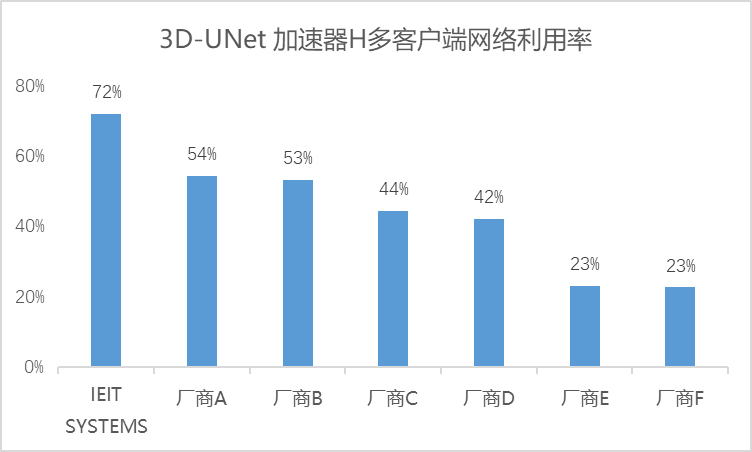
从结果来看,在AU达到90%以上时,浪潮信息本次提交的解决方案在网络利用效率方面表现出色,达到了72%,相比之下,其他供应商的解决方案整体网络利用率仅维持在50%左右,这直接导致了大量网络资源的闲置。尤其在客户端配置双网卡情境下,实际利用率仅为50%左右,意味着整套方案实质上浪费了近乎一整张网卡资源,大大增加了总体成本。若在大模型训练的万卡集群下,仅网卡资源的浪费就高达数千万级别,更不必说设备扩容所引发的算力利用率下降、连接线增加、运维复杂度提升等连锁成本效应。对于本就成本高昂的AI基础设施(AI Infra)而言,任何可以削减的开支都显得尤为关键。此时,不同存储解决方案下的网络利用率便成为衡量成本效益的核心指标——网络利用率越高,成本支出越低,算力潜能得以更充分释放,存储与AI应用场景的契合度也越高。通过AI存储基准测试展现存储对整个计算集群的支撑能力,这也是符合MLPerf Stortage作为AI测试基准,为ML/AI模型开发者选择存储解决方案提供权威参考的创立初衷。
进一步以3D-UNet加速器H单客户端测试为例,我们发现,即便在单客户端场景下,存储集群的总带宽依然超越了单客户端的带宽需求。浪潮信息的单客户端网络利用率依然保持在70%以上,实现了对双网卡资源的最大化利用。
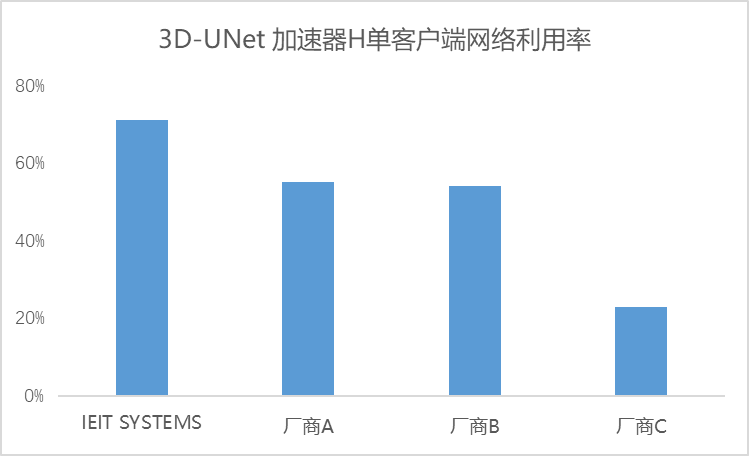
综上所述,无论是单客户端还是多客户端环境,浪潮信息均能在AU超过90%的同时,维持70%以上的网络利用率,与AI应用场景保持了高度的适配性。
浪潮信息与AI场景的紧密契合,主要归因于两大核心优势。一是产品场景化定制,紧密围绕客户需求,从实际应用出发,提升产品性能,打造真正贴合AI需求的存储产品;二是成熟的AI场景解决方案能力,精准平衡客户需求、资源分配与成本控制,通过优化解决方案与配置,为AI场景构建坚实的数据支撑平台。
解读MLPerf Storage这一AI存储评测标准,其核心在于检验各厂商解决方案在保持加速器利用率90%以上的前提下,能否在性能与资源利用之间找到最佳平衡点。测试结果显示,在相同AU条件下,浪潮信息能够进一步提升网络利用率,有效减少AI Infra的资源浪费。此次权威评测不仅验证了浪潮信息存储在AI场景下整体解决方案的实力,更彰显了其新产品完全满足AI应用对存储严苛要求的能力,展现出强大的市场竞争力。对于客户而言,浪潮信息凭借定制化产品开发模式和成熟的存储解决方案能力,提供AI存储的最优解,为产业AI化(AI+)提供坚实的数据存储底座。
-
存储
+关注
关注
13文章
4929浏览量
90375 -
浪潮
+关注
关注
1文章
491浏览量
25498 -
AI
+关注
关注
91文章
41885浏览量
302994 -
MLPerf
+关注
关注
0文章
37浏览量
991
原文标题:MLPerf™ Storage v1.0深度解析:浪潮信息AI存储性能测试的领先之道
文章出处:【微信号:inspurstorage,微信公众号:浪潮存储】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
浪潮信息MLPerf单机系统测试:7项性能第一
MLPerf训练性能测试榜单发布,浪潮信息刷新多项纪录
音乐分离AI模型研发成功,浪潮信息以AI算力服务助力

合肥大唐存储与KeyarchOS完成浪潮信息澎湃技术兼容性认证

智慧有数 浪潮信息发布生成式AI存储解决方案
浪潮信息澎湃认证:浪潮分布式存储携手博雅云OneSRM SMP存储管理平台完成兼容性认证

浪潮信息NF5468服务器LLaMA训练性能
浪潮信息澎湃认证:浪潮信息集中式存储携手达梦数据库管理系统V8完成兼容性认证

浪潮信息澎湃认证:浪潮信息集中式存储携手仪电云i-stack云操作系统软件完成兼容性认证

浪潮信息发布AS13000G7-N系列分布式全闪存储
CCF-TCIST走进浪潮信息 共话AI时代存储创新

浪潮信息推出AIGC存储解决方案
长擎安全操作系统24与浪潮信息HF/AS存储系列成功兼容
浪潮信息AS13000G7荣获MLPerf™ AI存储基准测试五项性能全球第一



评论