 基于块层的组成“bio层”的详细解析
基于块层的组成“bio层”的详细解析
操作系统比如Linux关键的价值之一,就是为具体的设备提供了抽象接口。虽然后来出现了各种其它抽象模型比如“网络设备”和“位图显示(bitmap display)”,但是最初的“字符设备”和“块设备”两种类型的设备抽象依然地位显赫。近几年持久化内存(persistent memory)炙手可热,[与非易失性存储NVRAM概念不同, persistent memory强调以内存访问方式读写持久存储,完全不同与块设备层], 但在将来很长一段时间内,块设备接口仍然是持久存储(persistent storage)的主角。这两篇文章的目的就是去揭开这位主角的面纱。
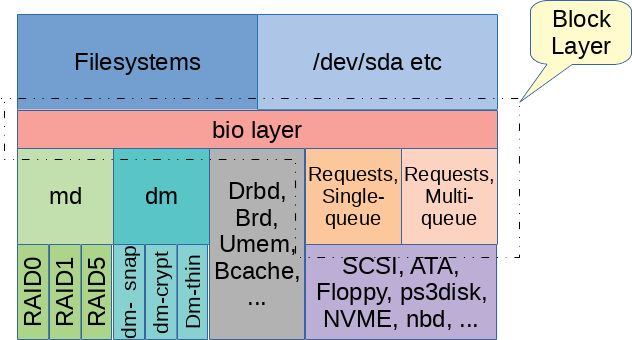
术语“块层”常指Linux内核中非常重要的一部分 - 这部分实现了应用程序和文件系统访问存储设备的接口。 块层是由哪些代码组成的呢? 这个问题没有准确的答案。一个最简单的答案是在"block"子目录下的所有源码。这些代码又可被看作两层,这两层之间紧密联系但有明显的区别。我知道这两个子层次还没有公认的命名,因此这里就称作“bio层”和“request 层”吧。本文将带我们先了解"bio层",而在下一篇文章中讨论“request层”。
块层之上
在深挖bio层之前,很有必要先了解点背景知识,看看块层之上的天地。这里“之上”意思是靠近用户空间(the top),远离硬件(the bottom),包括所有使用块层服务的代码。
通常,我们可以通过/dev目录下的块设备文件来访问块设备,在内核中块设备文件会映射到一个有S_IFBLK标记的inode。这些inode有点像符号链接,本身不代表一个块设备,而是一个指向块设备的指针。更细地说,inode结构体的i_bdev域会指向一个代表目标设备的struct block_device对象。 struct block_device包含一个指向第二个inode的域:block_device->bd_inode, 这个inode会在块设备IO中起作用,而/dev目录下的inode只是一个指针而已。
第二个inode所起的主要作用(实现代码主要在fs/block_dev.c, fs/buffer.c,等)就是提供page cache。如果设备文件打开时没有加O_DIRECT标志,与inode关联的page cache用来缓存预读数据,或缓存写数据直到回写(writeback)过程将脏页刷到块设备上。如果用了O_DIRECT,读和写绕过page cache直接向块设备发请求。相似地,当一个块设备格式化并挂载成文件系统时,读和写操作通常会直接作用在块设备上 [作者写错了?],尽管一些文件系统(尤其是ext*家族)能够访问相同的page cache(过去称为buffer cache)来管理一些文件系统数据。
open()另一个与块设备相关的标志是O_EXCL。块设备有个简单的劝告锁(advisory-locking)模型,每个块设备最多只能有个“持有者”(holder)。在激活一个块设备时,[激活泛指驱动一个块设备的过程,包括向内核添加代表块设备的对象,注册请求队列等],可用blkdev_get()函数为块设备指定一个"持有者"。[ blkdev_get()的原型: int blkdev_get(struct block_device *bdev, fmode_t mode, void *holder), holder可以是一个文件系统的超级块, 也可以是一个挂载点等]。一旦块设备有了“持有者”,随后再试图激活该设备就会失败。通常在挂载时,文件系统会为块设备指定一个“持有者”,来保证互斥使用块设备。当一个应用程序试图以O_EXCL方式打开块设备时,内核会新建一个struct file对象并把它作为块设备的“持有者”,假如这个块设备作为文件系统已经被挂载,打开操作就会失败。如果open()操作成功并且还没有关上,尝试挂载操作就会阻塞。但是,如果块设备不是以O_EXCL打开的,那么O_EXCL就不能阻止块设备被同时打开,O_EXCL只是便于应用程序测试块设备是否正在使用中。
无论以什么方式访问块设备,主要接口都是发送读写请求,或其它特殊请求比如discard操作, 最终接收处理结果。bio层就是要提供这样的服务。
bio层
Linux中块设备用struct gendisk表示,即 一个通用磁盘 (generic disk)。这个结构体也没包含太多信息,主要起承上启下的作用,上承文件系统,下启块层。往上层走,一个gendisk对象会关联到block_device对象,如我们上文所述,block_device对象被链接到/dev目录下的inode中。如果一个物理块设备包含多个分区,也就说有个分区表,那么这个gendisk对象就对应多个block_device对象。其中,有一个block_device对象代表着整个物理磁盘gendisk,而其它block_device各代表gendisk中的一个分区。
struct bio是bio层一个重要的数据结构,用来表示来自block_device对象的读写请求,以及各种其它的控制类请求,然后把这些请求传达到驱动层。一个bio对象包括的信息有目标设备,设备地址空间上的偏移量,请求类型(通常是读或写),读写大小,和用来存放数据的内存区域。在Linux 4.14之前,bio对象是用block_device来表示目标设备的。而现在bio对象包含一个指向gendisk结构体的指针和分区号,这些可通过bio_set_dev()函数设置。这样做突出了gendisk结构体的核心地位,更自然一些。
一个bio一旦构造好,上层代码就可以调用generic_make_request()或submit_bio()提交给bio层处理。[submit_bio()只是generic_make_request()的一个简单封装]。 通常,上层代码不会等待请求处理完成,而是把请求放到块设备队列上就返回了。generic_make_request()有时可能阻塞一小会,比如在等待内存分配的时候,这样想可能更容易理解,它也许要等待一些已经在队列上的请求处理完成,然后腾出空间。如果bi_opf域上设置了REQ_NOWAIT标志,generic_make_request()在任何情况下都不应该阻塞,而应该把这个bio的返回状态设置成BLK_STS_AGAIN或BLK_STS_NOTSUPP,然后立即返回。截至写作时,这个功能还没有完全实现。
bio层和request层间的接口需要设备驱动调用blk_queue_make_request()来注册一个make_request_fn()函数,这样generic_make_request()就可以通过回调这个函数来处理提交个这个块设备的bio请求了。make_request_fn()函数负责如何处理bio请求,当IO请求完成时,调用bio_endio()设置bi_status域的状态来表示请求是否处理成功,并回调保存在bio结构体里的bi_end_io函数。
除了上述对bio请求的简单处理,bio层最有意思的两个功能就是:避免递归调用(recursion avoidance)和队列激活(queue plugging)。
避免递归(recursion avoidance)
在存储方案里,经常用到"md" [mutiple device] (软RAID就是md的一个实例)和"dm" [device mapper] (用于multipath和LVM2)这两种虚拟设备,也常叫做栈式设备,由多个块设备按树的形式组织起来,它们会沿着设备树往下一层一层对bio请求作修改和传递。如果采用递归的简单的实现,在设备树很深的情况下,会占用大量的内核栈空间。很久以前 (Linux 2.6.22),这个问题时不时会发生,在使用一些本身就因递归调用占用大量内核栈空间的文件系统时,情况更加糟糕。
为了避免递归,generic_make_request()会进行检测,如果发现递归,就不会把bio请求发送到下一层设备上。这种情况下,generic_make_request()会把bio请求放到进程内部的一个队列上(currect->bio_list, struct task_struct的一个域), 等到上一次的bio请求处理完以后,然后再提交这一层的请求。由于generic_make_request()不会阻塞以等待bio处理完成,即使延迟一会再处理请求都是没问题的。
通常,这个避免递归的方法都工作得很完美,但有时候可能发生死锁。理解死锁如何发生的关键就是上文我们对bio提交方式的观察: 当递归发生时,bio要排队等待之前已经提交的bio处理完成。如果要等的bio一直在current->bio_list队列上而得不到处理,它就会一直等下去。
引起bio互相等待而产生死锁的原因,不太容易发现,通常都是在测试中发现的,而不是分析代码发现的。以bio拆分 (bio split)为例,当一个bio的目标设备在大小或对齐上有限制时,make_request_fn()可能会把bio拆成两部分,然后再分别处理。bio层提供了两个函数(bio_split()和bio_chain()),使得bio拆分很容易,但是bio拆分需要给第二个bio结构体分配空间。在块层代码里分配内存要特别小心,尤其当内存紧张时,Linux在回收内存时,需要把脏页通过块层写出去。如果在内存写出的时候,又需要分配内存,那就麻烦了。一个标准的机制就是使用mempool,为一个某种关键目的预留一些内存。从mempool分配内存需要等待其它mempool的使用者归还一些内存,而不用等待整个内存回收算法完成。当使用mempool分配bio内存时,这种等待可能会导致generic_make_request()死锁。
社区已经有多次尝试提供一个简单的方式来避免死锁。一个是引入了"bioset" 进程,你可以用ps命令在电脑上查看。这个机制主要关注的就是解决上面描述的死锁问题,为每一个分配bio的"mempool"分配一个"rescuer"线程。如果发现bio分配不出来,所有在currect->bio_list的bio就会被取下来,交个相应的bioset线程来处理。这个方法相当复杂,导致创建了很多bioset线程,但是大多时候派不上用场,只是为了解决一个特殊的死锁情况,代价太高了。通常,死锁跟bio拆分有关系,但是它们不总是要等待mempool分配。[最后这句话,有些突兀]
最新的内核通常不会创建bioset线程了,而只是在几种个别情况下才会创建。Linux 4.11内核,引入了另一个解决方案,对generic_make_request()做了改动,好处是更通用,代价小,但是却对驱动程序提出了一点要求。主要的要求是在发生bio拆分时,其中一个bio要直接提交给generic_make_request()来安排最合适的时间处理,另一个bio可以用任何合适的方式处理,这样generic_make_request()就有了更强的控制力。 根据bio在提交时在设备栈中的深度,对bio进行排序后,总是先处理更低层设备的bio, 再处理较高层设备的bio。这个简单的策略避免了所有恼人的死锁问题。
块队列激活(queue plugging)
存储设备处理单个IO请求的代价通常挺高的,因此提高处理效率的一个办法就是把多个请求聚集起来,然后做一次批量提交。对于慢速设备来说,队列上积攒的请求通常会多一些,那么做批处理的机会就多。但是,对于快速设备,或经常处于空闲状态的慢速设备来说,做批处理的机会就显然少了很多。为了解决这个问题,Linux块层提出了一个机制叫"plugging"。[plugging, 即堵上塞子,队列就像水池,请求就像水,堵上塞子就可以蓄水了]
原来,plugging仅仅在队列为空的时候才使用。在向一个空队列提交请求前,这个队列就会被“堵塞”上一会时间,好让请求积蓄起来,暂时不往底层设备提交。文件系统提交的bio就会排起队来,以便做批处理。文件系统可以主动请求,或着定时器周期性超时,来拔开塞子。我们预期的是在一定时间内聚集一批请求,然后在一点延迟后就开始真正处理IO,而不是一直聚积特别多的请求。从Linux 2.6.30开始,有了一个新的plugging机制,把积蓄请求的对象,从面向每个设备,改成了面向每个进程。这个改进在多处理器上扩张性很好。
当文件系统,或其它块设备的使用者在提交请求时,通常会在调用generic_make_request()前后加上blk_start_plug()和blk_finish_plug()。 blk_start_plug()会初始化一个struct blk_plug结构体,让current->plug指向它,这个结构体里面包含一个请求列表(我们会在下一篇文章细说这个)。因为这个请求列表是每个进程就有一个,所以在往列表里添加请求时不用上锁。如果可以更高效率的处理请求,make_request_fn()就会把bio添加到这个列表上。
当blk_finish_plug()被调用时,或调用schedule()进行进程切换时(比如,等待mutex锁,等待内存分配等),保存在current->plug列表上的所有请求就要往底层设备提交,就是说进程不能身负IO请求去睡觉。
调用schedule()进行进程切换时,积蓄的bio会被全部处理,这个事实意为着bio处理的延迟只会发生在新的bio请求不断产生期间。假如进程因等待要进入睡眠,那么积蓄起来的bio就会被立即处理。这样可以避免出现循环等待的问题,试想一个进程在等待一个bio请求处理完成而进入睡眠,但是这个bio请求还在plug列表上并没有下发给底层设备。
像这样进程级别的plugging机制,主要的好处一是相关性最强的bio会更容易聚集起来,以便批量处理,二是这样很大程度上减少了队列锁的竞争。如果没有进程级别的plugging处理,那么每一个bio请求到来时,都要进行一次spinlock或原子操作。有了这样的机制,每一个进程就有一个bio列表,把进程bio列表往设备队列里合并时,只需要上一次锁就够了。
bio层及以下(bio layer and below)
总之,bio层不是很复杂,它将IO请求以bio结构体的方式直接传递给相应的make_request_fn() [具体的实现有通用块层的blk_queue_bio(), DM设备的dm_make_request(), MD设备的md_make_request()]。bio层实现了各种通用的函数,来帮助设备驱动层处理bio拆分,scheduling the sub-bios [不会翻译这个,意思应该是安排拆分后的bio如何处理], "plugging"请求等。 bio层也会做一些简单操作,比如更新/proc/vmstat中的pgpgin和pgpgout的计数,然后把IO请求的大部分操作交给下一层处理 [request层]。
有时候,bio层的下一层就是最终的驱动,比如说DRBD(The Distributed Replicated Block Device)或 BRD (a RAM based block device). 更常见的下一层有MD和DM提供这种虚拟设备的中间层。不可或缺的一层,就是除bio层之外剩下的部分了,我称之为"request 层",这将是我们在下一篇讨论的话题。
-
Linux
+关注
关注
87文章
11324浏览量
209927
原文标题:块层介绍 第一篇: bio层
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
4层板手动布线问题
AUTOSAR基础软件层是由哪些部分组成的
EPA功能块及用户层技术研究
深度剖析基于块层的组成“request层”
电缆外护层的结构组成是怎样的,它的作用是什么
pcb板各层画什么?丝印层 机械层 阻焊层 助焊层 信号层 钻孔数据层作用详解
块设备层的数据结构 page/request和bio的关系
Linux块层架构介绍 块层IO流程与块层IO调度器详解
技术资讯 I PCB 阻焊层与助焊层的区别






 工商网监
工商网监
评论