 简单分享3种运维工具体系
简单分享3种运维工具体系
运维流程管理工具
发布变更流程管理工具:做为系统接口与其他角色的工作衔接。并提供审批环节控制发布变更的风险。流程管理工具并不负责具体的业务操作的执行,只是作为单据系统跟踪流程和确保闭环。
告警和突发管理工具:体现业务受损的告警自动建单管理。人工确认之后升级为突发单。通过建单管理告警和突发确保流程的闭环,以及每次故障都能够总结出经验,并未度量业务的可用性提供KPI。
运维发布变更工具
版本管理工具(数据库):所有的发布应该以版本管理为起点。研发给的版本包先入版本管理工具,再从版本管理工具分发到现网发布。杜绝 rsync 一台服务器发布另外一台的做法。
配置管理工具(数据库):版本加配置等于现网每台机器的状态。最粗粒度的配置管理是到 IP 级别,相当于对机器做资产管理,分组到不同的业务,模块和大区等业务概念上。细粒度一点会管理到进程以及进程的相关的配置。
配置和版本下发工具:把指定的版本,结合配置好的配置下发到现网的机器上。不同的版本和配置方式需要完全不同的下发方式。以 ssh/fabric 为代表的下发方式是以脚本为中心的。以 puppet/chef 为代表的下发方式是以配置为中心的。
现网状态同步工具:为了规避现网状态漂移,与管理工具内的记录不一致。需要有一个工具定时上报现网的实际状况。
服务调度工具:发布变更经常需要一个串行的流程,先做A模块,再做B模块。很多机器的时候,需要把能并发的操作并发执行,不能并发的操作确保串行执行。同时很多发布变更流程需要操作管理范围外的服务,比如云端的DNS服务器记录等。这就需要有一个服务调度工具统一调度配置和版本下发工具,流程单据工具,以及其他系统的API接口共同组装成一个流程。
资源管理和隔离工具:以xen/kvm为代表的工具让运维可以更灵活的切割资源。比如虚拟机的快速起停,ip在idc内的漂移等。以 lxc/docker 为代表的工具让运维可以进一步的切割资源到进程级别。资源隔离代理的细粒度的资源控制可以获得更好的资源利用率,以及更容易进行可伸缩的资源配置。
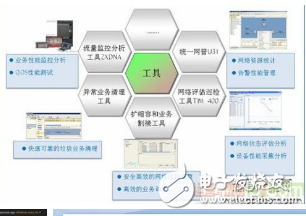
发布变更统一界面:包装所有的下层工具,提供简单的界面完成标准化的发布变更操作。
运维监控告警工具
采集工具:一般是采集日志文件,也可以是定时轮询 DB 或者其他系统的接口。流行的开源方案是 logstash。
收集工具:采集工具上报给收集工具。或者由开发直接修改代码上报指标给收集工具。流程的开源方案还是 logstash。
统计入库工具:上报可能是每次调用就上报一次,统计工具负责统计出一分钟内的次数。上报也可能是每5秒上报一次数值,统计工具负责统计出一分钟内的最大值。统计工具的存在是为了上报的方便。流行的开源方案是 statsd,也有大公司基于 storm 来做二次开发的。
时间序列数据库:所有定时指标会落地到数据库里。监控告警所需要的数据库需要能够支撑非常大的数据量,但是并没有很严格的 ACID 要求。
运维事件数据库:记录所有的告警。包括从其他系统获得告警,以及对现网的所有变更操作记录。这些数据用于支撑告警的原因定位。
指标异常检测工具:基于数学模型发现指标是否与过去的稳定模式背离,而推测出现网状态的变化。
拨测工具:定时 PING 或者 HTTP GET,模拟实际用户发现服务是否中断,产生告警。同时也产生指标上报给收集系统。拨测又分为本地拨测,和远程拨测。本地拨测可以用于发现磁盘只读等本机告警。远程拨测可以模拟用户的地理分布,把网络的链路状况也包含在拨测覆盖的范围内。
告警收敛工具:综合所有来源的告警,进行频率收敛,根源分析。统一汇总成报告催促人工修复。
告警自动修复工具:接受告警进行自动化的处理。帮运维完成固定的故障机下架退库等操作。或者在业务本身没有做高可用的情况下,做故障机替换,ip漂移等现网修复操作,一定程度地提高业务可用性。
告警通知工具:重要的告警需要升级为电话。需要有高可用的电话,短信,微信等通知接口。
监控告警统一界面:屏蔽下层各种工具,提供统一的agent安装,指标采集设置,指标曲线展示,告警查询的界面。一个地方知道现网的所有的问题。
-
数据库
+关注
关注
7文章
3794浏览量
64355
原文标题:浅谈运维工具体系
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
网管员的手机有妙用:一键报障与工单运维IT系统
老男孩Linux运维培训教程
运维工程师的两种日常
干货:设计DevOps运维服务体系的详细思路和设计步骤
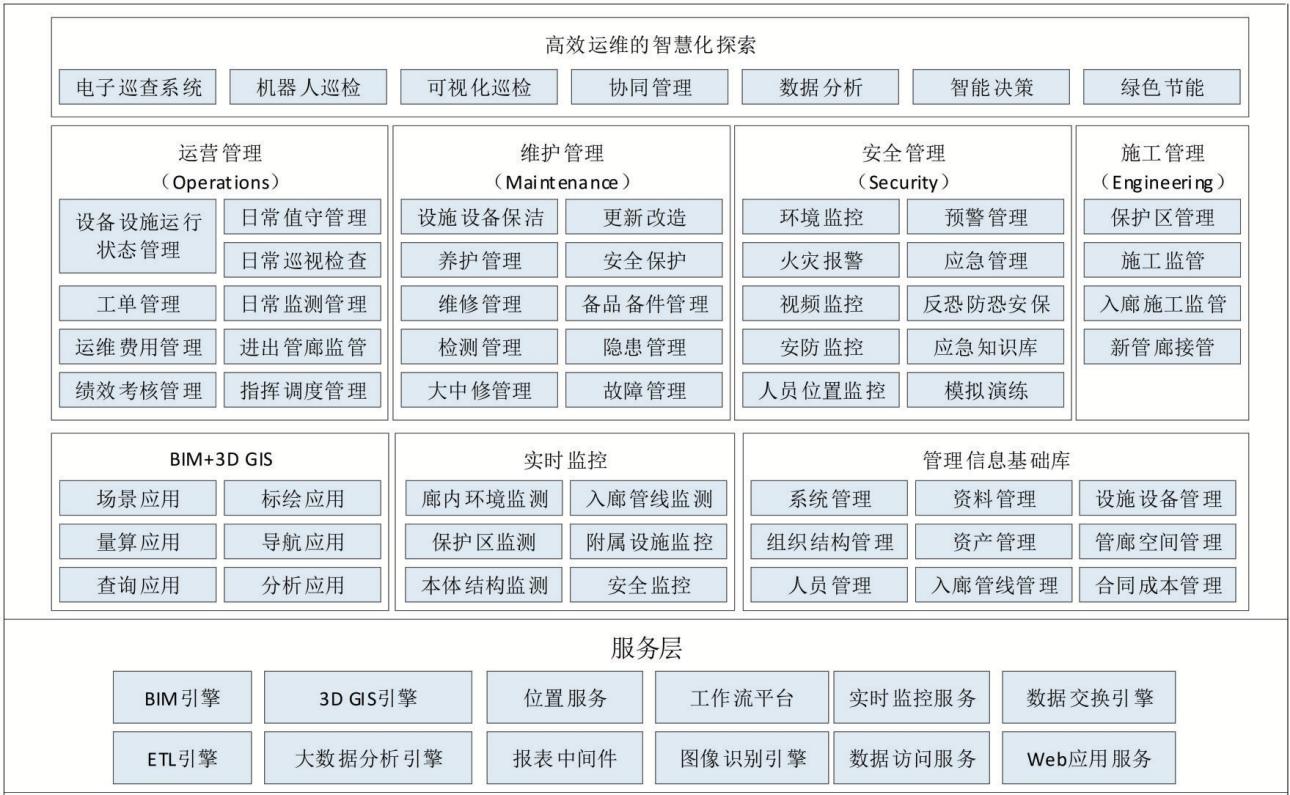
浅谈城市综合管廊智慧配电运维管理平台体系架构
Agith:openEuler 运维变更观测工具





 工商网监
工商网监
评论