 揭秘JDQ限流架构:实时数据链路的多维动态带宽管控
揭秘JDQ限流架构:实时数据链路的多维动态带宽管控
作者:京东零售 饶璐
1、背景
在数字化转型的浪潮席卷之下,大数据和云计算技术已成为企业创新和发展的关键驱动力。尤其是以京东为代表的电商平台为例,其日常运营中持续生成海量数据,涵盖实时交易记录、点击曝光统计及用户行为轨迹等,这些数据对精准业务决策、深化用户体验优化等方面具有重要意义。然而,随着业务版图的快速扩张,特别是在618、双11等年度大促盛宴中,数据流量呈现井喷式增长,给数据系统带来前所未有的压力。
在此情境下,尽管Apache Kafka凭借其卓越的高吞吐能力与低延迟特性,成为了企业处理实时数据流的首选,但面对当今降本增效的宏观趋势,企业急需在不增加过多资源负担的前提下,实现效能的最大化。特别是针对网络带宽这一宝贵资源,如何在海量数据与复杂业务场景交织的挑战中,实施更加精细、高效且智能的流量限速控制策略,以确保消息中间件服务能够持续提供高可用性与高稳定性,成为了企业技术团队亟需攻克的难关。
JDQ 是基于 Apache 基金会开源的 Kafka 消息队列,深入打造的具备高吞吐、低延迟、高可靠性的实时流式消息中间件框架,可应用于数据管道、实时数仓、数据分析、等多种场景,是京东统一的实时数据总线。京东JDQ团队结合降本增效的行业趋势,针对开源Kafka在限流技术方面的不足和局限性进行了深入研究,并在此基础上进行了创新性优化,开发出支持多维度、动态以及优先级等限流功能的JDQ带宽管控限流架构。本文将针对Kafka限流存在的问题,以及JDQ限流架构进行深入介绍。
2、Kafka 限流
2.1 限流概述
在服务器日常运营中,限流是一种自我保护机制,用于避免突发和异常的数据流入流出量徒增对系统造成的冲击。这种情况尤其常见于电商促销高峰期,此时某些特定的主题(topics)可能会经历流量激增,导致过多的占用Broker带宽资源和磁盘I/O资源。如果不加以控制,这不仅会影响其他客户端的正常读写操作,还会干扰集群内部的主从同步过程,给整个集群带来巨大的压力。当集群承受过大的压力,不仅可能导致服务过载,甚至可能引发系统崩溃。部分节点的故障雪崩,最终会波及到集群内所有业务的正常运行。因此,通过精细化的限流策略,我们能够有效维护集群的稳定运作,保障业务的连续性和服务质量。
2.2 原生 Kafka 限流机制
Kafka 原生的限流机制是配额优先级限流机制,kafka提供两个配额配置参数,三种粒度来进行限流管理:
两个配置参数:(可以动态调整)
(1)producer_byte_rate:生产者单位时间(每秒)内最高允许发送到单台broker的字节数。
(2)consumer_byte_rate:消费者单位时间(每秒)内最高允许从单台broker拉取的字节数。
三种粒度:
(1)user(认证方式)
(2)client.id(客户端标识)
(3)user + client.id
user只能在集群中开启身份认证鉴权的情况下使用,在每个broker的ProduceRequest和FetchRequest中携带的client/user客户端身份标识,进行对应的限流。
Kafka 为user、client-id以及 (user+client-id)这三种粒度定义配额配置,同时支持设定默认值,具体的配额可以覆盖默认配额,配额配置参数都是写入zookeeper的 /config 路径下,其中user 以及 (user+client-id)的配置是写入 /config/users 下,而client-id是直接写入 /config/clients 下,可以设置所有的user或者所有的clients默认配额,如果有指定user或者指定clients则会覆盖默认值。这些覆盖可以及时被服务监听,无需滚动重启整个集群也能够动态更新这些参数配置。
如果同时配置了多粒度的参数,限流优先级从高到低如下:
/config/users/< user >/clients/< client-id > 指定的 user+client-id的配置值 那么优先级最高; /config/users/< user >/clients/< default > 指定user配置+clients的默认值 /config/users/< user > 单独的user粒度,指定user /config/users/< default >/clients/< client-id > user的默认值+指定client-id /config/users/< default >/clients/< default > user的默认值+默认的client-id /config/users/< default > 单独的user的粒度,所有user的默认值 /config/clients/< client-id > 单独的client-id粒度,指定client-id /config/clients/< default > 单独的client-id粒度,所有client的默认值,优先级最低
如果同时集群下存在多种配额配置参数,以优先级高的配额配置为准。
举一个例子解释限流优先级:如果指定一个user,userA设定他的producer_byte_rate为10M/s,同时该集群上还为所有user的都配置了默认producer_byte_rate为50M/s,以及为默认值下还设置了client-id粒度的配额;此时如果那user认证的生成程序向集群生产,生产速率的配额,应该以user指定为准,即为10M/s。(第3级优先于第5级)
限流算法:
我们假设当前实际速率是O,T是预设的user限流速率值(可以根据实际情况配置),而W表示某一段时间范围,我们希望在W时间内O能够下降到T以下(如果O本来就比T小,则什么都不用做),那么broker端就需要延缓等待一段时间后再响应请求。如果假设这段时间是X,那么以下等式成立:
O * W = (W + X) * T
由此得出X = (O - T) / T * W。这就是Kafka用于计算限流等待时间的公式。当然在具体实现时,Kafka提供了两个参数来共同计算W:W = quota.window.num * quota.window.size.seconds。前者表示取样的时间窗口个数,后者表示时间窗口大小。
超额处理:
消息队列本身的功能是削峰填谷,在有突发流量的时候,流量很容易超过配额。此时,机器层面一般是有能力处理流量的,如果直接拒绝流量,就会导致消息投递失败,客户端请求异常。所以,在限流后,Kafka的处理方式是延时回包,通过加大单次请求的耗时,整体上降低集群的吞吐。因为正常状态下,客户端和服务端的连接数是稳定的,如果提升单次处理请求的耗时,集群整体流量就会相应下降。增加的耗时时长就是使用上述的限流算法计算的。
2.3 Kafka限流举例
Kafka限流是各个粒度对于broker-topic请求下的限流,依赖于这个broker上承担了多少个分区的 leader 分布,下述两个例子具体说明:(以生产请求为例,特定user只设置了user的生产配额)
eg1:假设存在topic1,有3个分区,每个分区有2个副本,具体的副本分区如下图,其中分区色块为粉红色的是leader节点
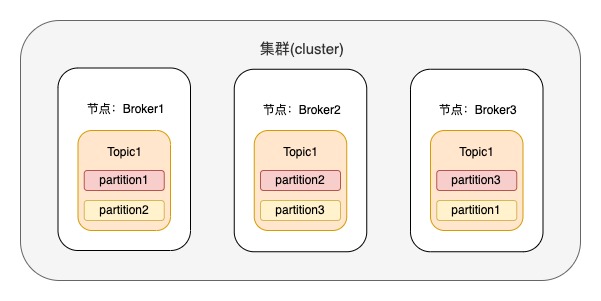
当user1 对 topic1 授予了producer的权限,user1的单机生产限流配额 producer_byte_rate 为10M/s,那使用user通过认证的生产客户端可以往topic1里的每个分区生产数据,那么每个分区的峰值流量都为10M/s;超过10M/s将会用触发限流机制,根据限流算法计算出一个等待时长,来延缓下一个生产请求的发出。
eg2:假设存在topic2,有3个分区,每个分区有2个副本,具体的副本分区如下图,其中分区色块为粉红色的是leader节点
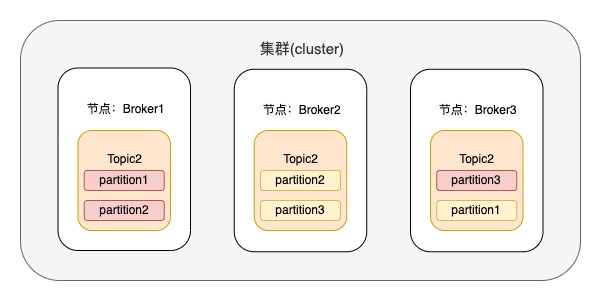
当user1 对 topic2 授予了producer的权限,user2的单机生产限流配额 producer_byte_rate 为10M/s,那使用user通过认证的生产客户端可以往topic1里的每个分区生产数据,那么分区1,2共享限流为10M/s;分区3的限流为10M/s;同样;当分区1和分区2累加的每秒生产的字节数超过了10M/s,或者分区3每秒生产的字节数超过了10M/s,触发限流机制。
2.4 Kafka限流机制的局限性分析
2.4.1 Broker-Topic维度限流的固有缺陷:节点故障leader切换引发的速率波动
从2.3的两个例子中,不难发现,如果Kafka集群的某个Topic Leader在发生故障切换时,会对生产与消费速率产生的间接影响,暴露了现有限流机制的一个短板。在标准配置下,生产者消费者的吞吐量分配与分区Leader的物理分布密切相关。
具体而言,假设一Topic拥有m个分区,初始分布于n个活跃Broker之上,每个Broker承载m/n个分区的Leader。消费者对于该Topic的限速配额设定为 s MB/s,理论上可实现总吞吐量 s*n MB/s。然而,一旦某Broker遭遇故障,Leader角色将重新分配至剩余 n-1 个Broker,尽管整体分区数保持不变,但限速原则却按s*(n-1) MB/s重新计算,导致吞吐量骤减。这一现象表示Kafka限流算法在适应动态故障场景时的脆弱性,用户需承受非预期的消费速率下降及潜在的数据积压风险。
2.4.2 缺乏单机限流机制与实时弹性调节能力
根据2.2所述,Kafka 现行限流机制聚焦于 User-Client 层面,忽视了单机 Broker 的容量限制,从而在面对这个 broker 下的user的生产/消费的总速率超过单机硬件限制的理论带宽上限的情况时,只能手动向下调整平台上与 broker 有关的生产者,消费者的配额参数,而 Kafka 集群本身并不会做出什么相应的限流举动,任由过载状态持续影响所有业务,直至触发网络拥塞或数据丢失。同时,Kafka 限流机制高度依赖于预先设定的业务系统限流配额,无法依据实时网络状况或 Broker 负载动态调整对应的生产消费配额,削弱了系统的弹性和响应性。
2.4.3 资源分配非最优与业务优先级处理缺失
当前限流技术在自动化处理业务重要性等级方面存在短板,未能充分考虑到不同业务场景的独特性。特别是在资源竞争激烈的环境中,该技术未能针对不同业务的关键程度做出有效区分。当达到限流阈值时,所有业务均遭受无差别的限制,忽视了高优先级服务的特殊需求。这种粗放式的处理方式,不仅无法满足特定业务场景的个性化需求,还可能阻塞关键业务流程或降低用户体验,进而引发用户的不满和投诉。在当前强调成本控制和效率提升的大环境下,迫切需要一种解决方案,能够在资源紧张时优先保障高优先级业务,通过错峰生产/消费模式,实现资源的合理配置和高效利用,以实现最大价值。
综上所述,开源Kafka在限流技术方面存在一些不足之处,包括但不限于:
•维度单一:限流策略过于粗放,未能覆盖分区级别或单Broker层级的精细化控制;
•缺乏实时弹性:依赖预设限流配额,无法根据实时业务情况进行动态自动调整。
•未区分业务优先级:未能根据业务的重要性和紧急性进行差异化处理,影响了流量资源的最优配置。
上述分析为Kafka限流机制的改进指明了方向,促使我们探索更为先进且灵活的限流策略,以应对复杂多变的生产环境。
3、JDQ限流核心架构
3.1 JDQ限流模型
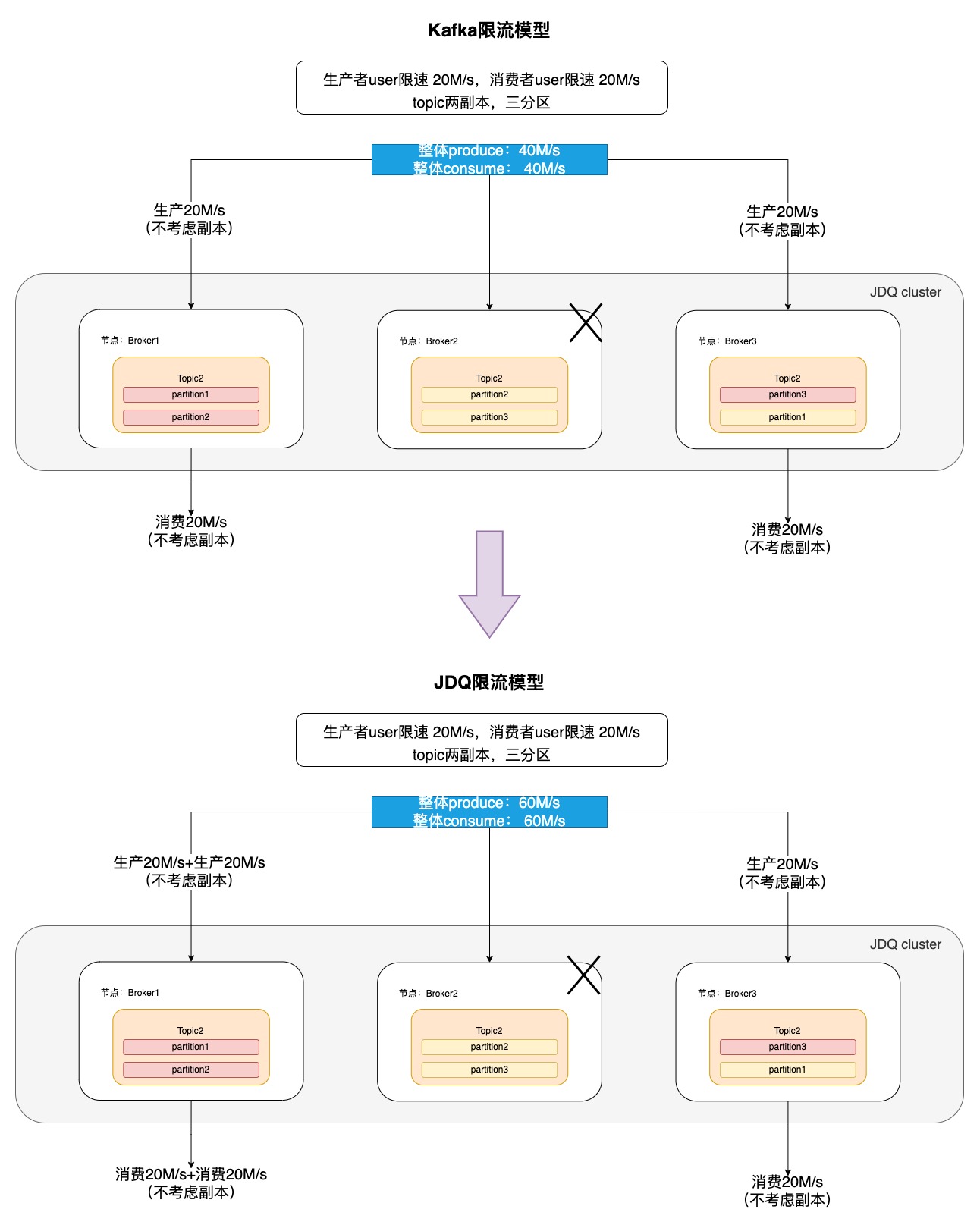
其中:分区色块为粉红色的是leader节点,“X”为故障节点
3.2 多维度的精细化限流粒度
如上述限流模型所示,在Kafka的基础上,JDQ平台支持更精细化粒度限流,即分区级别限流,可以让生产消费的吞吐量都不受故障节点影响而降低。
核心逻辑为:在 Controller 发起的元数据更新请求中,记录下来 Broker 上每个 Topic 对应的 leader 数量,在计算消费等待时长时,会让消费限速配额 consumer_byte_rate * 该 Topic 在分区 Leader 数量,从而实现不论 Topic 的分区 Leader 分布在几台机器上,消费者或者生产者的总速率都能保持不变
具体而言,假设一Topic拥有m个分区,初始分布于n个活跃Broker之上,每个Broker承载m/n个分区的Leader。生产者/消费者对于该Topic的限速配额设定为 s MB/s,理论上可实现总吞吐量 s*n MB/s。然而,一旦某Broker遭遇故障,Leader角色将重新分配至剩余 n-1 个Broker,但是整体分区数保持不变,原限流机制的理论总吞吐为 s*(n-1) MB/s, 但改造后的限流原则在节点故障前后均用 s*m MB/s计算,使得速率恒定为 配额*分区数,进而解决机器故障是对生产/消费的吞吐量的影响。
3.3 单机限流和分级动态弹性限流
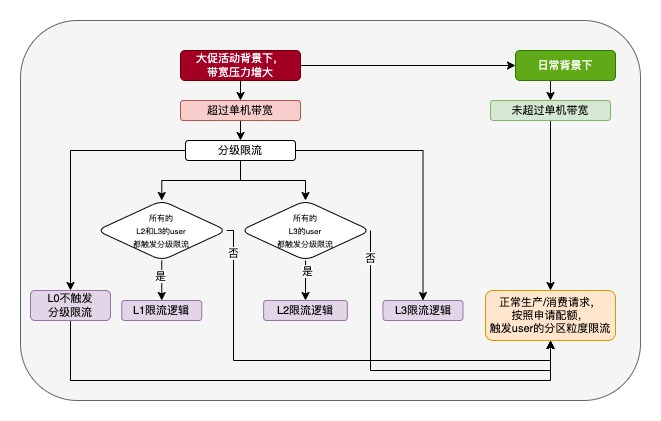
其图中,L1、L2、L3的限流逻辑为,根据为每个等级下分配的被分级限流时不同的带宽配额(可动态改配),以及分区粒度的限流算法进行计算等待时间,使对应等级的业务进行限流;
这一架构的核心在于引入单机带宽使用阈值,以及重要性等级机制(在分区限流的基础上),为不同等级(L0,L1,L2,L3)的生产者/消费者(即业务系统)分配差异化的限流带宽配额。这些参数可以支持动态配置地传入Kafka集群服务端,使得集群能够实时根据单机带宽使用情况,自动、弹性地调整对各个重要性等级业务系统的限流与恢复策略。具体来说,当单机带宽使用超过预设阈值时,Kafka集群将依据重要性等级从低到高,分级实施限流措施,确保高重要性业务系统得到优先保障。反之,当带宽使用回落到安全范围内时,系统将自动恢复限流,保障业务系统的顺畅运行。
此架构能够有效地应对带宽使用的潮汐变化,实现对不同重要性等级业务系统的精准限流与恢复,实现带宽资源错峰使用的智能化管理,确保重要性较高的业务系统能够得到优先保障,最大程度的减少资源有限的情况下,因带宽过载而可能造成的损失。此外,还显著降低现有技术中人为参与调整业务系统流量配额所耗费的人力成本,避免了人为误操作的风险。同时,其可配置参数的高度可扩展性和灵活性使得用户可以根据实际业务需求和网络状况,动态调整重要性等级、单机带宽过载阈值以及限流配额等参数,确保该限流机制在不同环境和场景下都能表现出卓越的性能和适应性。这一限流架构不仅提升了Kafka集群的带宽管理效率,发挥有限资源的最大价值,也增强了业务系统的稳定性和可靠性。
4、实际应用效果
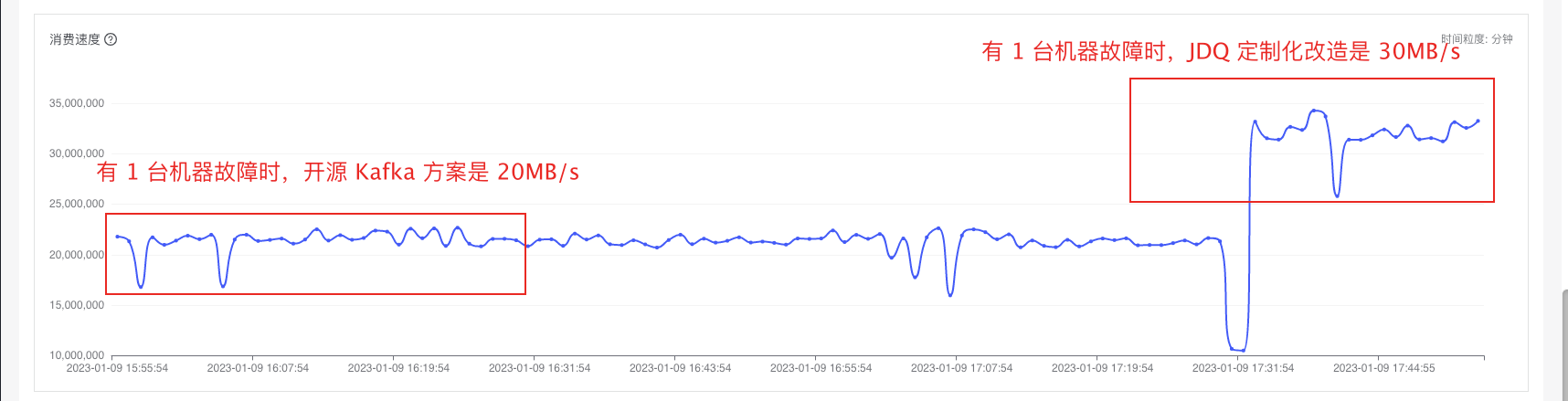
具体实例1:(验证分区限流)三台机器分别为同一个topic的三个分区的leader,经过我们分区粒度的限流后,就算存在有一台机器故障时(停掉服务模拟故障),切换leader之后,消费者的总速率应该为30M/s
原限流逻辑:
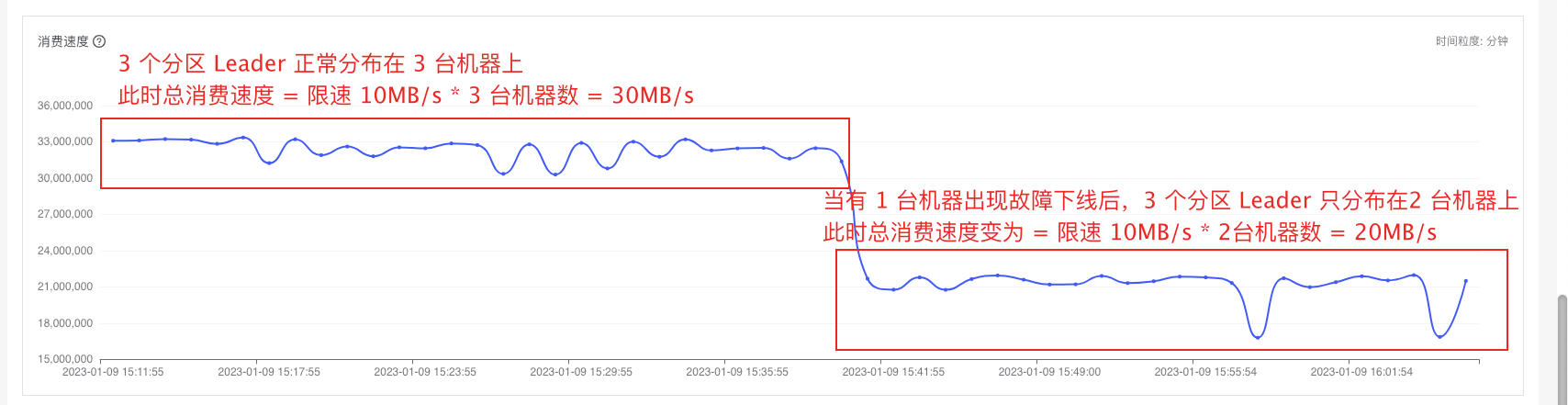
改造分区限流逻辑:
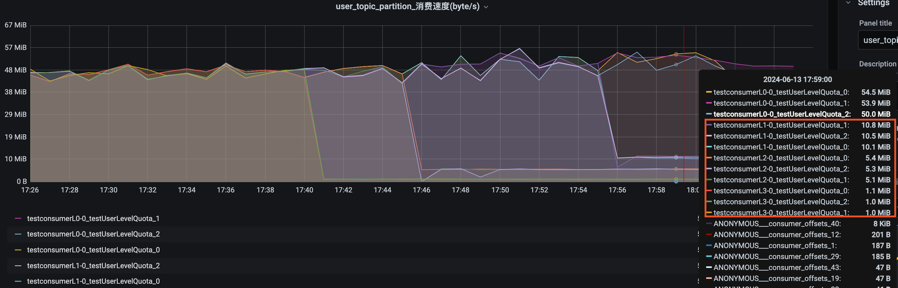
具体实例2:(验证单机和分级限流)以消费请求为例,JDQ的限流策略是如何在大促洪峰流量出现时,保证资源优先分配给高等级的任务呢?以消费为例,当机器单机流出配额带宽为50M/s时 (单机配额较低,模拟数据洪峰达到机器带宽上限),对应的分级限流的差异化流出带宽配额为L1-10M/s、L2-5M/s、L3-1M/s。启动L0、 L1、 L2、 L3四个不同的等级业务系统的消费程序,正常的消费时分区速率在50M/s 以上,触发逐级限流时的测试结果如下图,L3立即限流至1M/s,L2隔段时间限流至5M/s,L1再隔段限流至10M/s,L0不限流,按照等级由低到高逐级进行限流,对重要性等级高的系统优先分配带宽,优化了带宽资源分配,错峰消费。
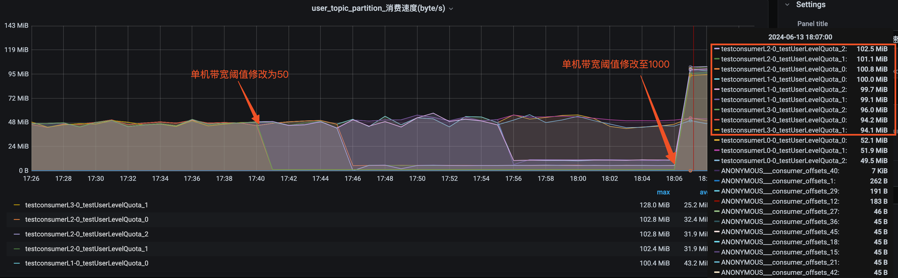
具体实例3:(验证弹性限流)在实例2的基础上,将机器单机流出配额带宽动态修改至1000(模拟数据洪峰已过),可以看到所有的就正常全力消费,不被限制,符合弹性根据潮汐值进行限流
5、未来限流优化方向
在未来的Kafka限流技术研发方向上,我们将计划针对以下几个方面进行优化和创新:
•多形式多粒度的限流粒度:未来优化将着眼于更多形式的限流,比如根据QPS限流,更细粒度的限流,如消息类型的限流,从而更好地满足多样化的业务需求和资源分配策略。
•基于容器化的带宽弹性伸缩:进一步探索JDQ与容器技术的深度融合,实现集群的按需弹性伸缩。用户限速带宽可以根据平时的实际使用率自动调整,确保资源的高效利用与成本控制,同时提升系统的整体响应能力和弹性。
•智能化限流规划与研发:为了进一步降低运维复杂度,提升系统可靠性,未来将加大投入于智能化限流方案的研发,实现限流策略的自动优化,减少人为干预,提升运维效率。
综上所述,JDQ的未来限流优化将紧密围绕用户需求与技术前沿,致力于打造一个既能应对高并发挑战,又能在成本控制,资源管理以及运维层面实现智能化、自动化的实时数据处理平台。
6、结语
我们来自实时平台研发部JDQ团队,我们将继续致力于 Kafka 限流技术的优化与创新,探索更多前沿技术,以进一步提升 Kafka 的稳定性和效率。
同时,我们也将加强与业界的交流与合作,共同推动 Kafka 技术的发展与应用,为大数据时代的数字化转型贡献更多力量。
审核编辑 黄宇
-
数字化
+关注
关注
8文章
8708浏览量
61726 -
数据链
+关注
关注
2文章
39浏览量
15782 -
大数据
+关注
关注
64文章
8882浏览量
137396
发布评论请先 登录
相关推荐
固定带宽与动态带宽的区别
调试PCIE链路动态均衡介绍
上位机实时数据处理技术 上位机在智能制造中的应用
RNN在实时数据分析中的应用
PCIE数据链路层架构解析
实时数据与数字孪生的关系
实时数据处理的边缘计算应用
大数据实时链路备战——数据双流高保真压测

IR615如何实现VPN链路备份?
IG网关产品实现链路备份的方法
OpenAI推出ChatGPT实时数据分析新功能
[招聘] 【通信】【天津七一二】【公司直招】【技术负责人】数据链 物理层 网络层 自组网 架构 算法 天线等方向
示波器带宽与探头带宽的关系揭秘

应用方案:实时数据加密
卫星数据链开发平台设计方案:522-基于AD9988的四通道1G带宽卫星数据链开发平台






 工商网监
工商网监
评论