 使用OpenVINO Model Server在哪吒开发板上部署模型
使用OpenVINO Model Server在哪吒开发板上部署模型
作者:
指导:
颜国进 英特尔边缘计算创新大使
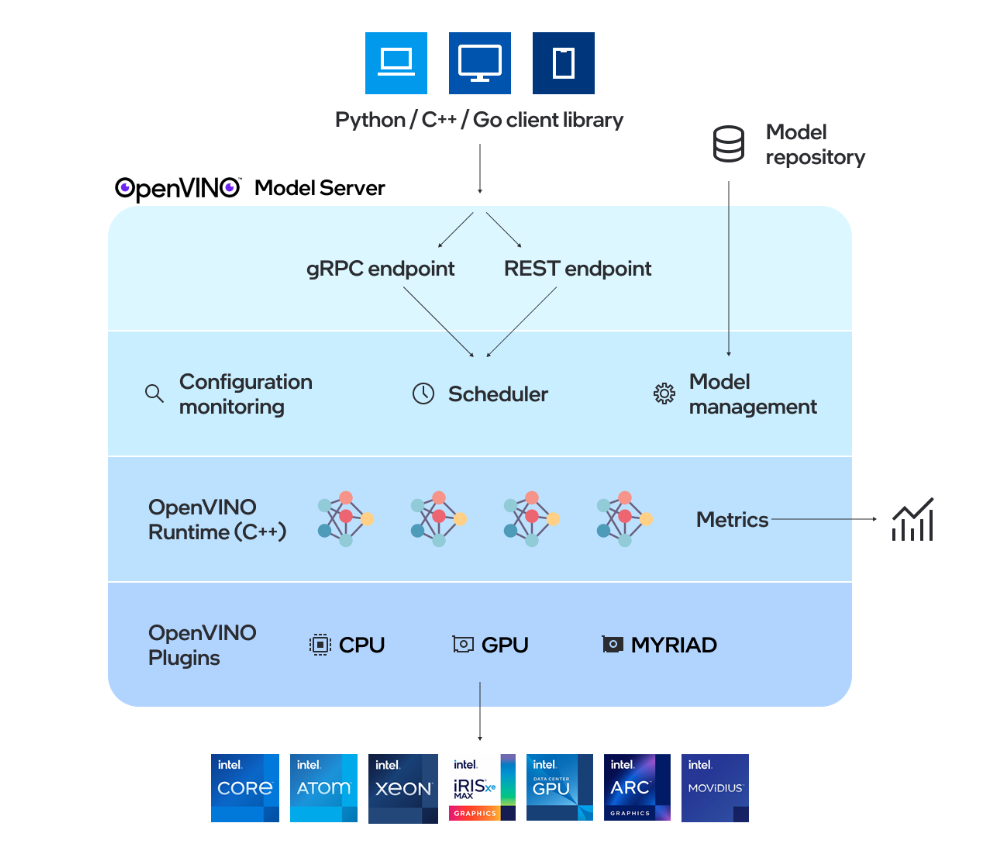
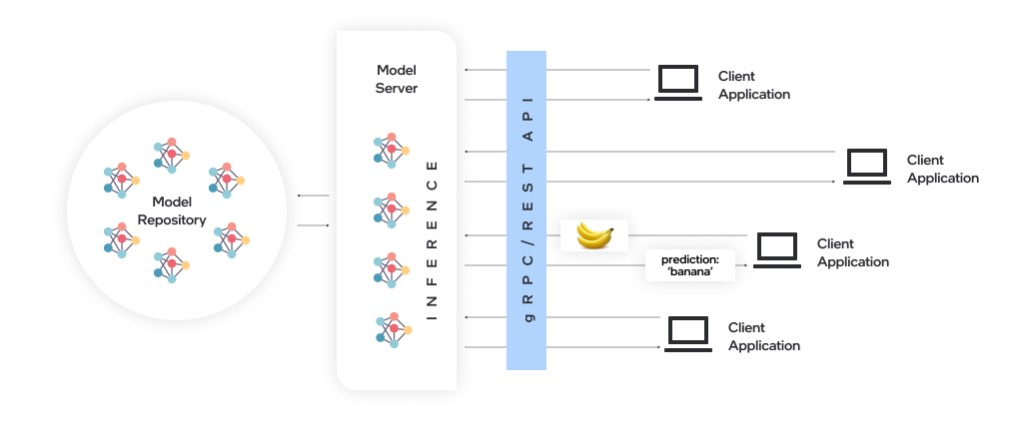
1OpenVINO Model Server介绍
OpenVINO Model Server(OVMS)是一个高性能的模型部署系统,使用C++实现,并在Intel架构上的部署进行了优化,使用OpenVINO 进行推理,推理服务通过gPRC或REST API提供,使得部署新算法、AI实验变得简单。OVMS可以在Docker容器、裸机、Kuberntes环境中运行,这里我使用的是Docker容器。
2哪吒开发板Docker安装
Ubuntu22.04上的Docker安装可以参照官方文档:
https://docs.docker.com/engine/install/
首先安装依赖:
sudo apt update sudo apt install ca-certificates curl
然后添加Docker的GPG密钥,如果你的网络可以正常访问Docker可以通过下面的命令添加APT源:
sudo install -m 0755 -d /etc/apt/keyrings sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc sudo chmod a+r /etc/apt/keyrings/docker.asc echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu $(. /etc/os-release && echo "$VERSION_CODENAME") stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null sudo apt update
如果无法正常访问,就需要换成国内镜像源,这里以阿里源为例:
sudo curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add - sudo add-apt-repository "deb [arch=$(dpkg --print-architecture)] https://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable" sudo apt update
之后就可以通过apt安装Docker,命令如下:
sudo apt install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
安装后可以通过以下命令验证是否安装成功:
sudo docker --version sudo docker run hello-world
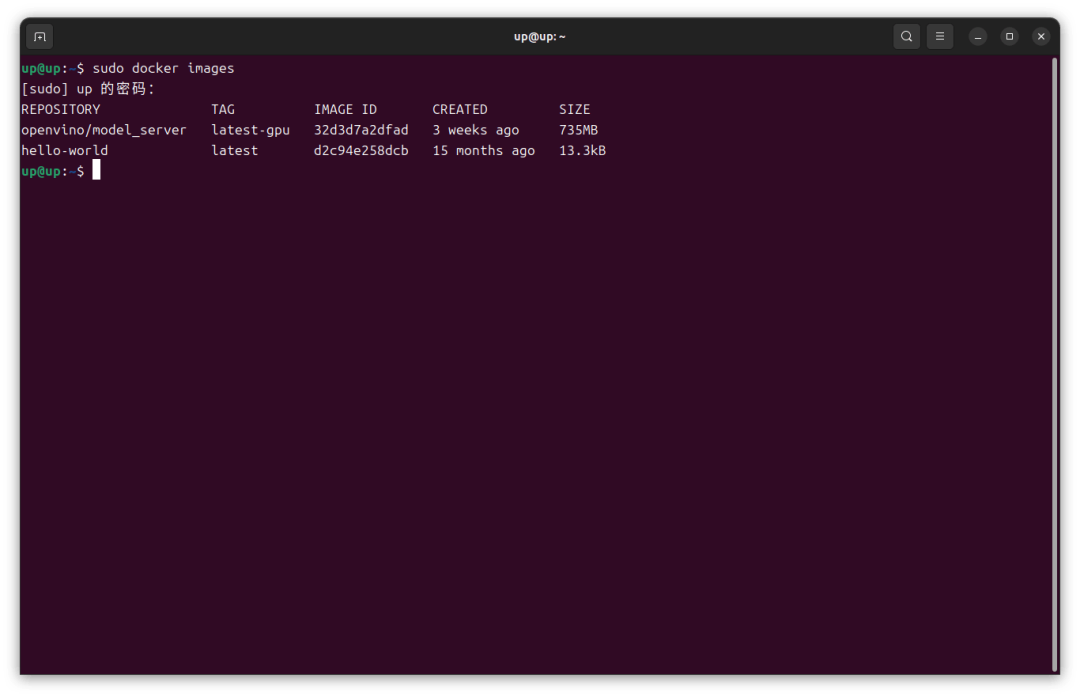
3拉取OpenVINOModel Server镜像
各个版本的镜像可以在OpenVINO 的Docker Hub上找到,我拉取了一个最新的带有GPU环境的镜像:
https://hub.docker.com/r/openvino/model_server/tags
sudo docker pull openvino/model_server:latest-gpu sudo docker images
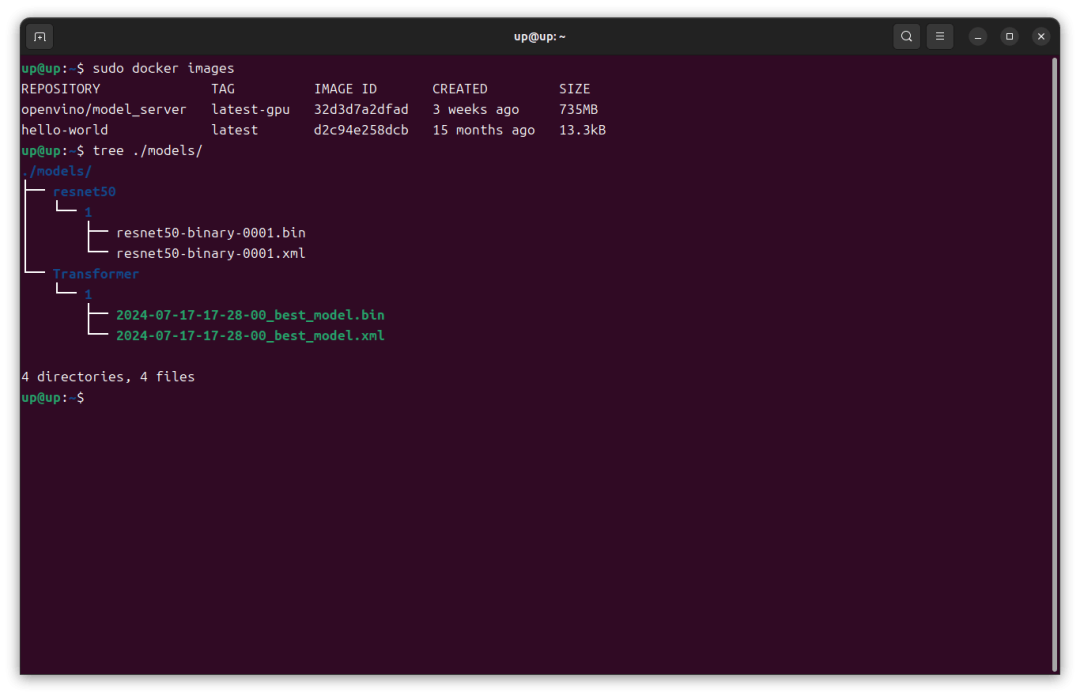
4准备模型
首先在哪吒开发板上新建一个models文件夹,文件夹的结构如下,这里我在models文件夹下存放了resnet50和Transformer两个模型,版本都为1,模型为OpenVINO IR格式。
5启动OpenVINO Model Server容器
在哪吒开发板上启动带有iGPU环境的OpenVINO Model Server容器命令如下:
sudo docker run -it --device=/dev/dri --group-add=$(stat -c "%g" /dev/dri/render* | head -n 1) -d -u $(id -u) -v $(pwd)/models:/models -p 9000:9000 openvino/model_server:latest-gpu --model_name Transformer --model_path /models/Transformer --port 9000 --target_device GPU
各个参数的含义可在官方文档查看:https://docs.openvino.ai/2024/ovms_docs_parameters.html
容器启动后可以通过以下命令查看容器ID、状态信息等。
sudo docker ps
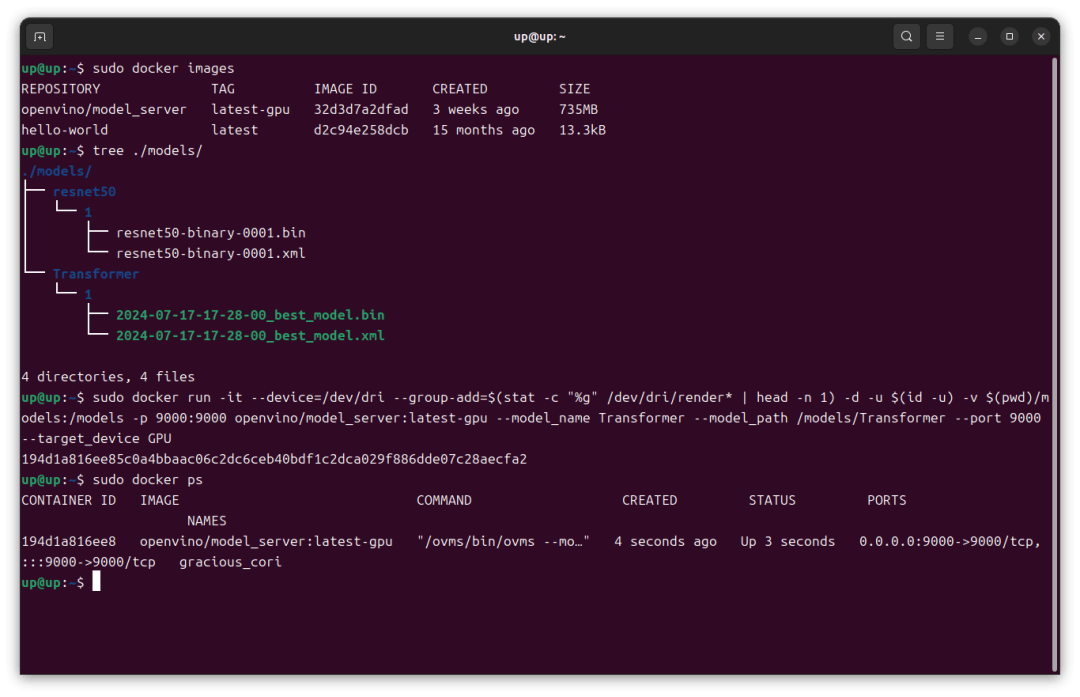
这样Transformer模型就通过OpenVINO Model Server部署在了哪吒开发板上。
6请求推理服务
接下来通过gRPC API访问推理服务,以python为例,首先安装ovmsclient包。
pip install ovmsclient
请求推理的代码如下,这里在局域网的另一台机器上请求哪吒开发板上的推理服务,10.0.70.164为哪吒开发板的ip地址。
import os import time import numpy as np import pandas as pd from ovmsclient import make_grpc_client client = make_grpc_client("10.0.70.164:9000") sum_time = 0 root_dir = './data/' filelist = os.listdir(root_dir) for file in filelist: start_time = time.perf_counter() sample = pd.read_csv(root_dir + file)['ForceValue'].values inputs = sample.reshape(1, -1).astype(np.float32) output = client.predict({"input": inputs}, "Transformer") end_time = time.perf_counter() sum_time += end_time - start_time result_index = np.argmax(output[0], axis=0) print('Infer results: ', result_index, ' Infer time: ', (end_time - start_time) * 1000, 'ms') print('Average time: ', sum_time / len(filelist) * 1000, 'ms')
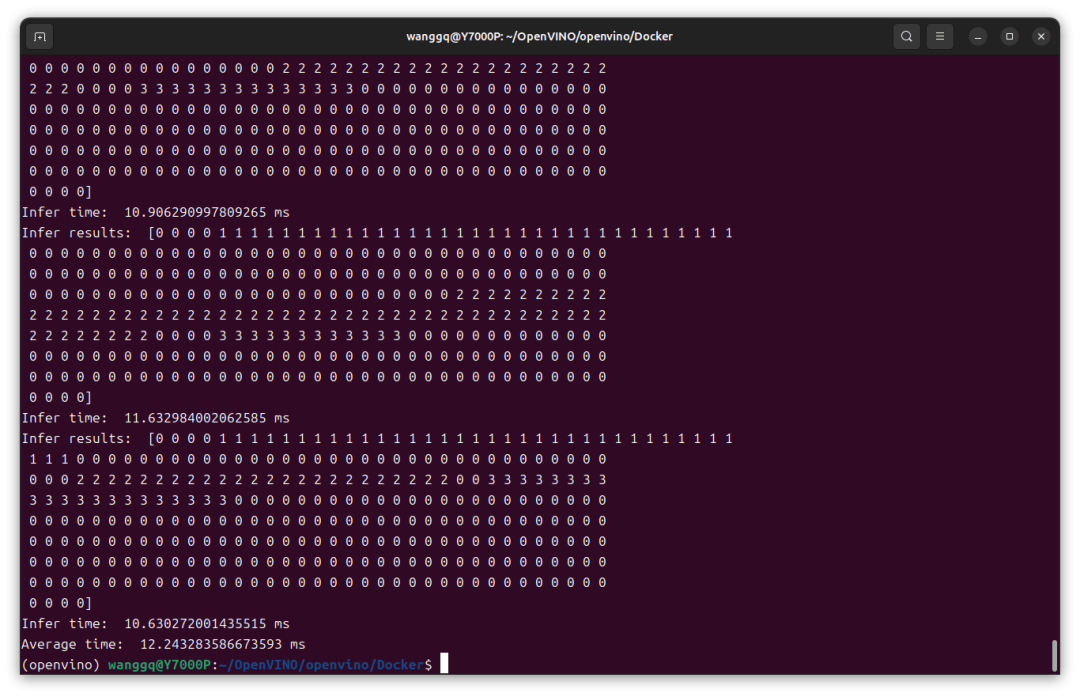
推理结果成功返回,平均推理时间12ms,如果换成更稳定的以太网速度应该会更快。
7总结
以上就是在哪吒开发板上使用OpenVINO(C++)推理模型,并通过OpenVINO Model Server进行模型部署的过程,可以看出OpenVINO的使用还是比较方便、简洁的,推理速度也很快。
-
英特尔
+关注
关注
61文章
9978浏览量
171889 -
开发板
+关注
关注
25文章
5068浏览量
97625 -
模型
+关注
关注
1文章
3254浏览量
48895 -
Docker
+关注
关注
0文章
472浏览量
11866 -
OpenVINO
+关注
关注
0文章
93浏览量
210
原文标题:使用 OpenVINO™ Model Server 在哪吒开发板上部署模型|开发者实战
文章出处:【微信号:英特尔物联网,微信公众号:英特尔物联网】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
LabVIEW+OpenVINO在CPU上部署新冠肺炎检测模型实战(含源码)
如何使用OpenVINO C++ API部署FastSAM模型
介绍在STM32cubeIDE上部署AI模型的系列教程
在AI爱克斯开发板上用OpenVINO™加速YOLOv8分类模型

在AI爱克斯开发板上用OpenVINO™加速YOLOv8目标检测模型

AI爱克斯开发板上使用OpenVINO加速YOLOv8目标检测模型

在AI爱克斯开发板上用OpenVINO™加速YOLOv8-seg实例分割模型
在AI爱克斯开发板上用OpenVINO™加速YOLOv8-seg实例分割模型
基于OpenVINO C# API部署RT-DETR模型
NNCF压缩与量化YOLOv8模型与OpenVINO部署测试
OpenVINO™ 赋能千元级『哪吒』AI开发套件大语言模型 | 开发者实战

使用OpenVINO C++在哪吒开发板上推理Transformer模型

OpenVINO™ C++ 在哪吒开发板上推理 Transformer 模型|开发者实战

基于哪吒开发板部署YOLOv8模型






 工商网监
工商网监
评论