 商汤联合提出基于FPGA的Winograd算法:改善FPGA上的CNN性能 降低算法复杂度
商汤联合提出基于FPGA的Winograd算法:改善FPGA上的CNN性能 降低算法复杂度
商汤科技算法平台团队和北京大学高能效实验室联合提出一种基于 FPGA 的快速 Winograd 算法,可以大幅降低算法复杂度,改善 FPGA 上的 CNN 性能。早在2016年,论文中的实验使用了当时最优的多种 CNN 架构,已经实现了 FPGA 加速之下的最优性能和能耗。
摘要
近年来,卷积神经网络(CNN)越来越广泛地应用于计算机视觉任务。FPGA 因其高性能、低能耗和可重配置性成为 CNN 的有效硬件加速器而备受关注。但是,之前基于传统卷积算法的 FPGA 解决方案通常受限于 FPGA 的计算能力(如 DSP 的数量)。本论文展示了快速的 Winograd 算法,该算法可以大幅降低算法复杂度,改善 FPGA 上的 CNN 性能。我们首先提出了一种新型架构在 FPGA 上实现 Winograd 算法。我们的设计利用行缓冲结构(line buffer structure)来高效重用不同 tile 的特征图数据。我们还高效架构 Winograd PE 引擎,通过并行化启动多个 PE。同时存在复杂的设计空间有待探索。我们提出一种分析模型,用于预测资源使用情况、推断性能。我们使用该模型指导快速的设计空间探索。实验使用了当前最优的 CNN,结果表明其实现了在 FPGA 上的最优性能和能耗。我们在 Xilinx ZCU102 平台上达到了卷积层平均处理速度 1006.4 GOP/s,整体 AlexNet 处理速度 854.6 GOP/s,卷积层平均处理速度 3044.7 GOP/s,整体 VGG16 的处理速度 2940.7 GOP/s。
引言
深度卷积神经网络(CNN)在多个计算机视觉任务上取得了优秀的性能,包括图像分类、目标检测和语义分割 [1, 2]。CNN 的高准确率是以极大的计算复杂度为代价的,因为它需要对特征图中的所有区域进行综合评估 [3, 4]。为了解决如此巨大的计算压力,研究者使用 GPU、FPGA 和 ASIC 等硬件加速器来加速 CNN [5–17]。其中,FPGA 因其高性能、低能耗和可重配置性成为有效解决方案。更重要的是,使用 C 或 C++的高级综合(High Level Synthesis,HLS)大幅降低了 FPGA 的编程障碍,并提高了生产效率 [18–20]。
CNN 通常包含多个层,每一层的输出特征图是下一层的输入特征图。之前的研究发现当前最优 CNN 的计算主要由卷积层主导 [6, 7]。使用传统的卷积算法,则输出特征图中的每个元素要经多步乘积累加运算进行单独计算。尽管之前使用传统卷积算法的 FPGA 解决方案取得初步成功 [5–9, 11],但是如果算法更加高效,该解决方案的效率可能会更高。本文展示了使用 Winograd 算法的卷积算法 [21] 如何大幅降低算法复杂度,改善 FPGA 上的 CNN 性能。使用 Winograd 算法,利用元素之间的结构相似性生成输出特征图中的一列元素。这减少了乘法运算的数量,从而降低算法复杂度。研究证明快速的 Winograd 算法适合为具备小型滤波器的 CNN 推导高效算法 [16]。
更重要的是,CNN 的当前趋势是带有小型滤波器的深度拓扑。例如,Alexnet 的所有卷积层(除了第一层)都使用 3 × 3 和 5 × 5 滤波器 [3];VGG16 仅使用 3 × 3 滤波器 [22]。这为使用 Winograd 算法高效实现 CNN 创造了机会。但是,尽管在 FPGA 上使用 Winograd 算法很有吸引力,但仍然存在一些问题。首先,设计不仅要最小化内存带宽要求,而且要匹配计算引擎与内存吞吐量。其次,在 FPGA 上映射 Winograd 算法时存在很大的设计空间。很难推断哪些设计会改善性能,抑或损害性能。
本文设计了一种行缓冲结构为 Winograd 算法缓存特征图。这允许不同的 tile 在卷积运算进行时重用数据。Winograd 算法的计算涉及通用矩阵乘法(GEMM)和元素级乘法(EWMM)的混合矩阵变换。然后,我们设计了一种高效的 Winograd PE,并通过并行化启动多个 PE。最后,我们开发分析模型用于评估资源使用情况,并预测性能。我们使用这些模型探索设计空间,确定最优的设计参数。
本文的贡献如下:
提出一种架构,可在 FPGA 上使用 Winograd 算法高效实现 CNN。该架构把行缓冲结构、通用和元素级矩阵乘法用于 Winograd PE 和 PE 并行化。
开发出分析性的资源和性能模型,并使用该模型探索设计空间,确定最优参数。
使用当前最优的 CNN(如 AlexNet 和 VGG16)对该技术进行严格验证。
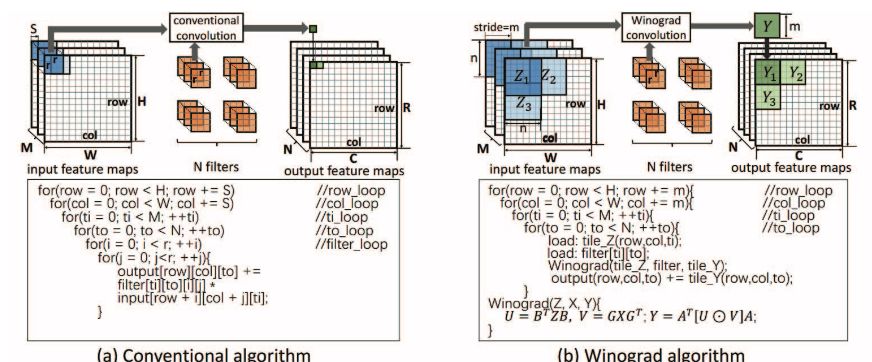
图 1:传统卷积算法和 Winograd 卷积算法的对比。我们假设 Winograd 算法的步幅 S 为 1。
架构设计
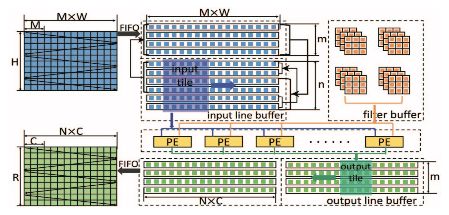
图 2:架构图示
图 2 表示在 FPGA 上基于 Winograd 算法的卷积层架构。研究者在相邻 tile 的特征图中确定数据重用机会。最后,自然而然地实现了行缓冲。输入特征图 (M) 有多个通道,如图 1 所示。行缓冲的每一行都存储所有通道中同样的一行。Winograd PE 从行缓冲中获取数据。具体来说,给出一个 n×n 输入 tile,Winograd PE 将生成一个 m × m 输出 tile。研究者通过并行化多个通道的处理来启动 PE 阵列。最后,使用双缓冲(double buffer)重叠数据迁移和计算。所有输入数据(如输入特征图、滤波器)最初都存储在外部存储器中。输入和输出特征图通过 FIFO 被迁移至 FPGA。但是,滤波器的大小随着网络深度增加而显著扩大。将所有滤波器加载到片上存储器(on-chip memory)中是不切实际的。在本论文的设计中,研究者将输入和输出通道分成多组。每个组仅包含一部分滤波器。研究者在需要时按组加载滤波器。为方便陈述,下文中假设只有一组。
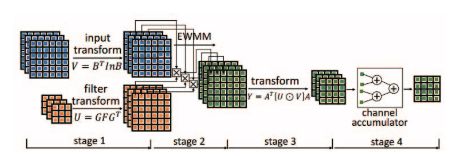
图 3:Winograd PE 设计图示
自动工具流程
研究者设计了一个自动工具流程将 CNN 自动映射至 FPGA,如图 5 所示。该流程包括设计空间探索引擎(DSEE)。研究者使用 Caffe prototxt 来描述 CNN 的结构 [24]。FPGA 配置参数包括内存带宽、DSP 数量、逻辑单元和片上内存容量。DSEE 的输出是最优解 {n, Tm, Tn}。在步骤 2 中,基于最优解,研究者开发了代码生成引擎(CGE),可自动生成 Winograd 卷积函数。该函数描述整个加速器结构,包括行缓冲、缓冲管理和 Winograd PE。生成的实现是 HLS 兼容的 C 代码。编译指令如内存分区因素、循环展开因素 Tn Tm 以及 FIFO 接口被插入函数中。步骤 3 中,研究者使用 Xilinx HLS 工具将代码合成为寄存器传输级别。最后,研究者使用 Xilinx SDSoC(软件定义片上系统)工具链来生成比特流。
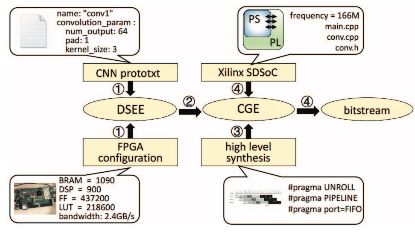
图 4:自动工具流程
实验评估

表 1:设计参数
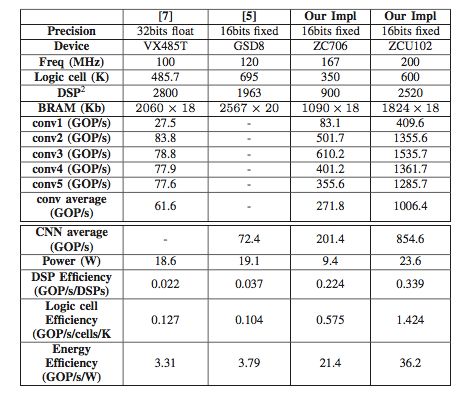
表 2:Alexnet 的性能对比
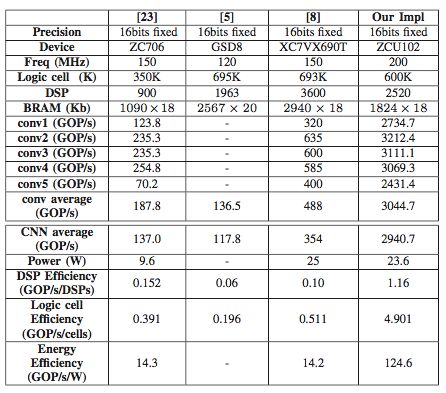
表 3:VGG 的性能对比
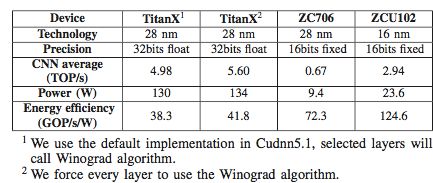
表 4:GPU 平台对比
-
FPGA
+关注
关注
1629文章
21729浏览量
602968 -
算法
+关注
关注
23文章
4607浏览量
92826 -
cnn
+关注
关注
3文章
352浏览量
22203 -
商汤科技
+关注
关注
8文章
508浏览量
36083
原文标题:商汤联合提出基于FPGA的快速Winograd算法:实现FPGA之上最优的CNN表现与能耗
文章出处:【微信号:SenseTime2017,微信公众号:商汤科技SenseTime】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于纹理复杂度的快速帧内预测算法
如何降低LMS算法的计算复杂度,加快程序在DSP上运行的速度,实现DSP?
求一种基于802.16d的低复杂度的帧同步和定时同步联合算法

图像复杂度对信息隐藏性能影响分析
降低FBMC-OQAM峰均值比的低复杂度PTS算法
基于移动音频带宽扩展算法计算复杂度优化
基于I帧复杂度的初始量化参数(QP)选择算法
虚拟MIMO中低复杂度功率分配算法
常见机器学习算法的计算复杂度
算法时空复杂度分析实用指南(上)
算法时空复杂度分析实用指南(下)





 工商网监
工商网监
评论