 存算一体技术的分类
存算一体技术的分类
近年间,云计算与人工智能技术的蓬勃兴起,计算中心面临着数据效率低、能耗大等核心挑战,这促使学术界和工业界重新聚焦。
开宗明义,定义先行。
首先,我们先来了解一下什么是存算一体:
存算一体是通过在存储器中嵌入计算能力,实现数据存储与计算的紧密结合。其技术不仅能够显著提升计算效率,还能大幅降低能耗。
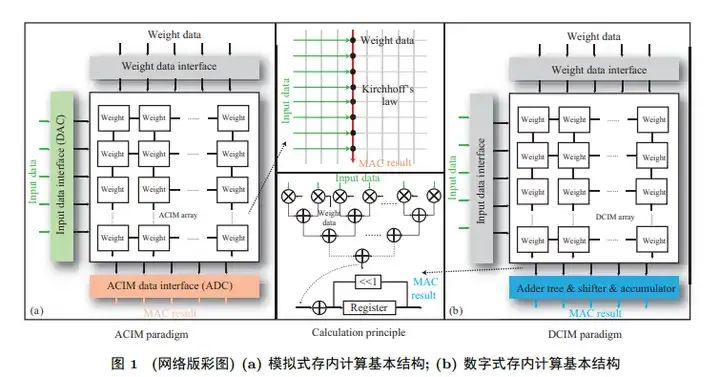
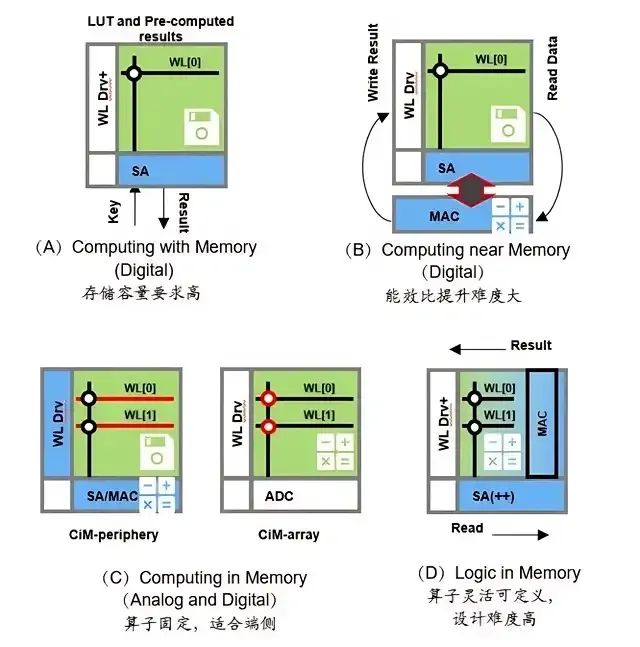
紧接着,存算一体技术分为三类:近存计算(Processing Near Memory, PNM)、存内处理(Processing In Memory, PIM)和存内计算(Computing In Memory, CIM)。
近存计算:不改变计算单元和存储单元本身设计功能,采用先进的封装方式及合理的硬件布局和结构优化,增强二者间通信宽带,增大传输速率。
存内处理:侧重于将计算过程尽可能地嵌入到存储器内部,这种方法的能效比通常较高,但计算精度可能受限。另一种思路是在存储器内部集成额外的计算单元,以支持高精度计算。
存内计算:存储单元与计算单元完全融合,无独立计算单元,通过存储器颗粒上嵌入算法,由存储器芯片内部的存储单元完成计算操作。
 图源:Google
图源:Google
事实上,存算一体的概念由来已久。早在1969年,斯坦福研究所的Kautz等人提出了存算一体计算机的概念。其受限于当时的芯片制造技术和算力需求的匮乏,那时存算一体仅仅停留在理论研究阶段,并未得到实际应用。
因此,后续研究人员在芯片电路结构、计算架构与系统应用等方面开展了一系列研究。但受限于电路设计复杂度与工艺难度,后续的大部分研究本质上实现的是 “近存计算”,其与存内计算最大的区别是,近存计算仍然需把数据从内存中读取出来之后再就近进行计算,计算的结果再存储到内存当中。
与此同时,存算一体技术的核心在于将数据存储与计算融合在同个芯片的同片区之中,从而彻底消除冯诺依曼计算架构的瓶颈;将通过存储器内部进行数据处理或计算,此技术能够大幅减少数据在计算与存储之间的传输时间,提升整体性能。
尤其,在冯诺伊曼架构中,计算单元与内存是两个分离的单元。计算单元根据指令从内存中读取数据,在计算单元中完成计算和处理,完成后再将数据存回内存。
然而,整个过程中,存储器与处理器之间数据交换通路窄,以及由此引发的高能耗形成两大难题,在存储与计算之间筑起一道“存储墙”。能耗方面,大部分能耗在数据搬运过程中产生,数据搬运功耗是计算功耗的1000倍。而数据搬运速度方面,AI运算需1PB/s,但DRAM 40GB-1TB/s 都远达不到要求。
 存算一体技术的分类
存算一体技术的分类
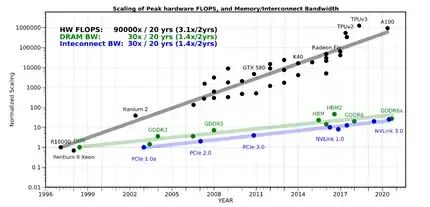
过去数载,处理器性能以每年大约55%的速度提升,而相比之下,内存性能的提升则显著放缓,其年增长率仅约为10%。这种长期存在的性能发展不均衡现象,导致当前存储系统的访问速度相较于处理器的计算能力出现了显著的滞后现象。
目前,在传统计算机的设定里,存储模块是为计算服务的,因此设计上会考虑存储与计算的分离与优先级。但如今,存储和计算不得不整体考虑,以最佳的配合方式为数据采集、传输和处理服务。
其中,虽然多核(例如CPU)/众核(例如GPU)并行加速技术也能提升算力,但在后摩尔时代,存储带宽制约了计算系统的有效带宽,芯片算力增长步履维艰。从处理单元外的存储器提取数据,搬运时间往往是运算时间的成百上千倍,整个过程的无用能耗大概在60%-90%之间,能效非常低,“存储墙”成为了数据计算应用的一大障碍。
其次,存内计算和存内逻辑,即存算一体技术直接利用存储器进行数据处理或计算,从而把数据存储与计算融合在同一个芯片的同一片区之中,从而彻底消除冯诺依曼计算架构瓶颈,以便适用于深度学习神经网络这种大数据量大规模并行的应用场景。
 算力发展速度远超存储
算力发展速度远超存储
显然,存算一体技术的演进轨迹导向了计算精度的提升、算力输出的增强及能效比优化的高阶,以此映射出该技术内进步逻辑的必然走向。
前移至感知端,向 “极致低功耗” 迈进:面向可穿戴设备、物联网设备等端侧市场,打造超低功耗、超低成本的解决方案。当前感知芯片采集到的模拟信号依赖模数转换器转换成数字,信号再通过智能处理器进行处理,速度慢、功耗高。
后移至边缘端/云端,向 “极致大算力”迈进:面向边缘端/云端服务器、数据中 心与自动驾驶等场景,利用存算一体芯片大规模并行运算的特点,打造超大算力解决方案。当前的边缘端/云端处理器大多基于 GPU 平台,而 GPU 仍然受 “存储墙” 限制,存在巨大的数据通信开销,导致其实际算力不到标称算力的 10%。据分析, 以 ChatGPT 为代表的主流大模型的基本组成单元 Transformer 中约有 90% 以上的运算为大规模矩阵运算,可以基于存算一体阵列高效完成。
协同异构架构与异构集成,实现合力突围:异构架构将不同计算架构、不同功能的硬件单元进行融合,充分发挥各自的优势,弥补各自的不足,以实现系统更高的性能。例如,单一的数字存算一体架构或模拟存算一体架构在精度、能效、面积、成本等指标上各有优劣,采用单一架构难以兼具各项性能。
驱动 EDA 设计工具与应用工具链开发:随着存算一体芯片 从 0 到 1 的突破,已验证了其在 AI 应用中的发展潜力与市场前景,进而吸引上下游企业的加入,催生相应的自动化 EDA 设计工具、开发环境、仿真器、编译工具与智能算法的协同发展,缩短芯片的研发周期与应用开发周期,进而推动开源与标准生态的建立与繁荣,形成良性循环,加速存算一体芯片的规模化量产与应用。
综上所述,当前的存算一体芯片研究集中在单点技术,且在器件、电路、架构、EDA工具及系统应用等方面仍然存在诸多技术待解决。
另外,从技术的角度,存算一体芯片未来的研究将围 绕新型器件优化、低功耗数模混合电路设计、高性能异构芯片架构、先进集成与封装、工具链开发等。
-
处理器
+关注
关注
68文章
19155浏览量
229035 -
存储器
+关注
关注
38文章
7447浏览量
163579 -
算力
+关注
关注
1文章
925浏览量
14731 -
存算一体
+关注
关注
0文章
100浏览量
4287
原文标题:打破算力极限,存算一体技术并驾齐驱
文章出处:【微信号:奇普乐芯片技术,微信公众号:奇普乐芯片技术】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
存算一体大算力AI芯片将逐渐走向落地应用
比存算一体更进一步,“感存算一体化”前景如何?
探索存内计算—基于 SRAM 的存内计算与基于 MRAM 的存算一体的探究


知存科技数模混合存算一体AI芯片专利解析







 工商网监
工商网监
评论