 介绍基于不确定的语法条件生成类似Java的强类型程序
介绍基于不确定的语法条件生成类似Java的强类型程序
已经有不少使用神经网络生成程序的研究,但目前的工作基本上都基于严格的语义(semantic)限制。Rice大学的研究人员Vijayaraghavan Murali等将在ICLR 2018上做口头报告,介绍他们的新研究,基于不确定的语法(syntactic)条件生成类似Java的强类型程序。
AML
对于程序生成而言,Java还是有些复杂。因此研究人员对Java做了一些简化,设计了一门新的语言AML。AML刻画了Java类语言的API使用的精髓。
AML使用有限的API数据类型的集合,类型同样是由API方法名称(包括constructor)指定的有限集合。方法a的类型签名用(τ1, ..., τk) -> τ0表示。

AML语法
其中,c表示变量,x、x1……表示变量,let用于变量绑定。
训练数据
训练数据为标注过的程序:
{(X1, Prog1), (X2, Prog2), ...
其中,Prog1、Prog2……为AML程序。X1、X2为标签。训练之后,模型将根据标签生成程序,因此标签应当包含关于代码的信息。
具体是哪些信息呢?
首先,AML主要是基于API调用设计的语言,因此API调用是重要的信息。
其次,AML脱胎于Java这一静态类型语言,因此类型也是重要的信息。
理论上,给定关键的API调用和类型,就可以生成程序。但实际上模型还没有这么智能,有时还需要一些额外的信息,一些关键词。
因此,标签共分3类:
X调用
X类型
X关键词
其中,关键词主要是根据类型和调用方法的命名CamelCase切分所得。例如,readLine会被切分为2个关键词read和line。
草图
如前一节所述,训练数据为标签(X)和AML程序(Prog)。然而,研究人员并没有直接学习标签和程序间的关系。因为,程序包含一些低层的信息,这些信息其实无关紧要,并不需要学习。比如,具体的变量命名,替换一下,并不会影响程序的语义(λ演算中的α-等价)。因此,需要将程序再转换一下,转换成某种刻画程序的高层结构和形状(控制结构、API调用顺序、参数类型、返回值类型)的表示。基于这一思路,研究人员将程序中的一些低层信息(变量命名、基本操作)抽象掉,从而将程序转化为草图(Sketch),并基于标签学习草图上的概率分布。之后,再使用组合方法将草图具体化为类型安全的AML程序(通过类型引导的随机搜索过程)。

Prog、X、Y的贝叶斯网络
其中,Yi= α(Progi),Y(草图)的语法如下:
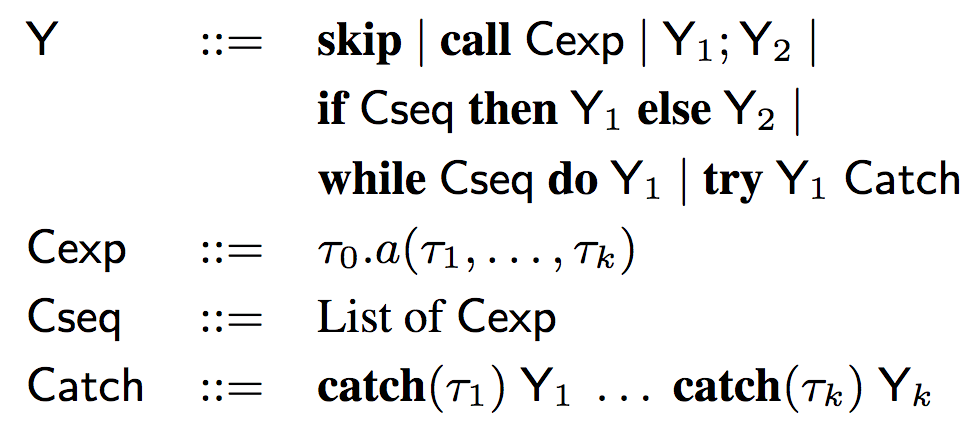
可以看到,草图的语法和AML的语法类似,抽象掉了其中的变量名称(x、x1等),保留了控制结构、类型信息和API调用。
对比草图的语法和AML的语法,α函数(从程序中抽象出草图的操作)的定义也就不言自明了:

GED
如前所述,模型将基于草图进行学习:
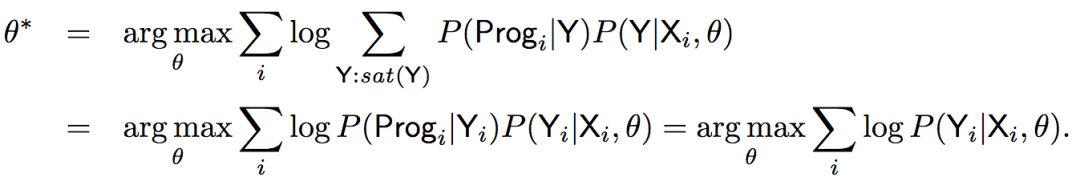
上式表明,最终我们需要计算:
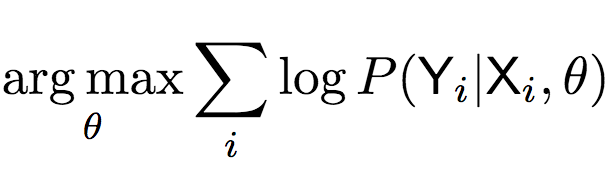
为了计算上式,研究人员提出了高斯编码-解码器(Gaussian Encoder-Decoder)(简称GED)模型,引入了一个潜向量Z,以随机连接标签和草图:
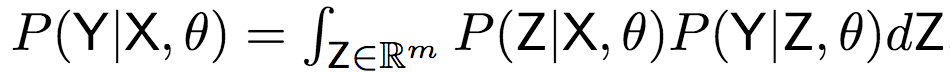
下面我们以编码X调用为例,说明编码器具体是如何工作的。
首先,将X调用的每个元素X调用,i转换成one-hot向量表示,记为X'调用,i。然后,通过下式编码X'调用,i

XCalls,i即X调用,i
其中,h为神经隐藏单元的数量,Wh∈ R|调用| x h、bh∈ Rh、Wd∈ Rh x d、bd∈ Rd为网络的权重和偏置,可通过训练学习。
基于f,可以计算P(X | Z,θ)
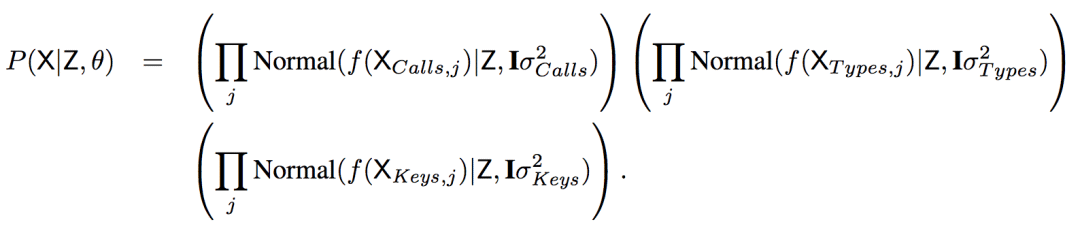
也就是说,X编码后的值从以Z为中心的高维正态分布取样。
P(X | Z,θ)的计算需要编码,P(Y | Z,θ)的计算与之相反,需要解码。
草图Y可以看成一个树形结构。
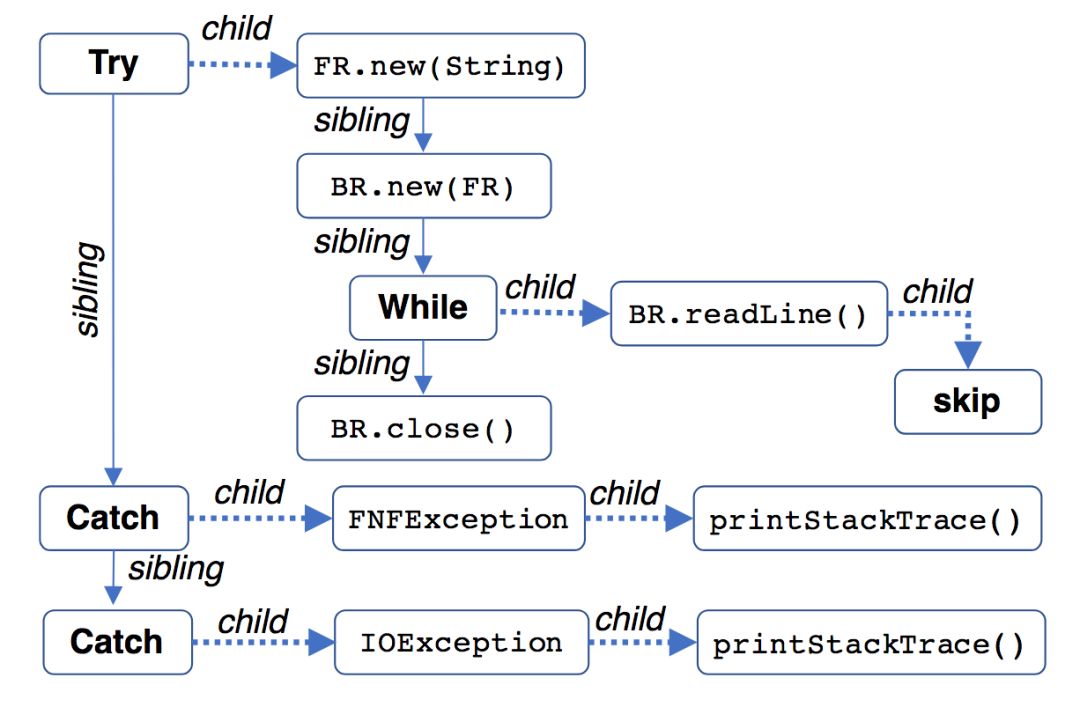
研究人员采用了自顶向下的搜索方法,从树形的顶端,一路往下,递归地计算输出分布yi。“一路往下”的“路”,研究人员称为生产路径(production path)。生产路径定义为有序对的序列<(v1, e1), (v2, e2), ..., (vk, ek)>,其中,vi为草图中的节点(即语法中的项),ei为连接vi与vi+1的边的类型。具体而言,边包括两种类型:sibling(兄弟姊妹,上图中的实线)和child(子女,上图中的虚线)。
比如,上图中有4条生产路径:
(try,c), (FR.new(String),s), (BR.new(FR),s), (while,c), (BR.readLine(),c), (skip,·)
(try,c), (FR.new(String),s), (BR.new(FR),s), (while,s), (BR.close(),·)
(try,s), (catch,c), (FNFException,c), (T.printStackTrace(),·)
(try,s), (catch,s), (catch,c), (IOException,c), (T.printStackTrace(),·)
其中,·表示路径的终结。另外,为了简明,以上路径均省略了(root,c),用s和c表示sibling和child,并缩写了部分类名。
给定Z和某条生产路径上的序列Yi= <(v1,e1), ..., (vi,ei)>,为了简化计算,假定路径中的下一个节点仅仅取决于Z和Yi,从而解码器只需使用单个推理步骤即可计算概率P(vi+1| Yi,Z)。具体而言,解码器使用了两个循环神经网络,一个用于c边,一个用于s边。
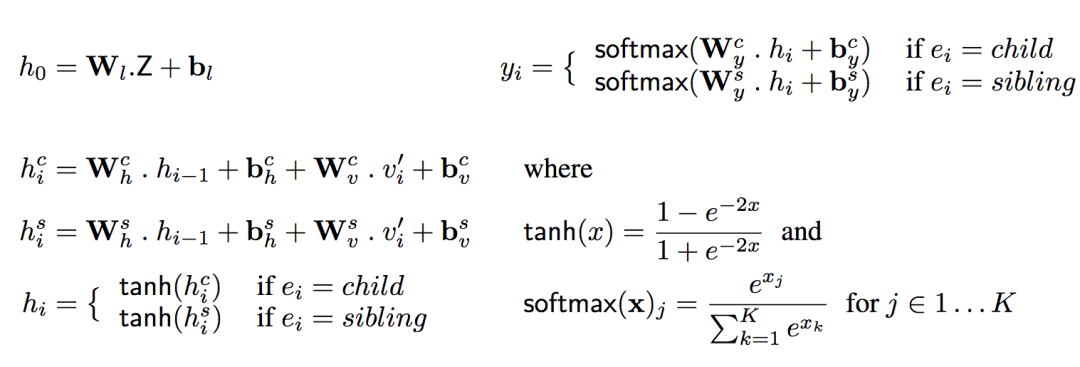
其中,v'i为vi转换成的one-hot向量。h为解码器的隐藏单元数目,|G|为解码器的输出词汇。Whe、bhe为解码器的隐藏状态权重和偏置矩阵,Wve、bve为输入权重和偏置矩阵,Wye、bye为输出权重和偏置矩阵(e为边的类型)。Wl和bl是“提升”权重和偏置,将d维向量Z提升到解码器的高维隐藏空间h。
可视化
研究人员可视化了32维潜向量空间的聚类。研究人员从测试数据中得到标签X,然后从P(Z | X)取样潜向量Z,进而从P(Y | Z)取样草图Y。接着使用t-SNE降维Z到2维,然后基于Y中的API使用标注每个点。下图显示了这一2维空间,每个标签对应不同的颜色。
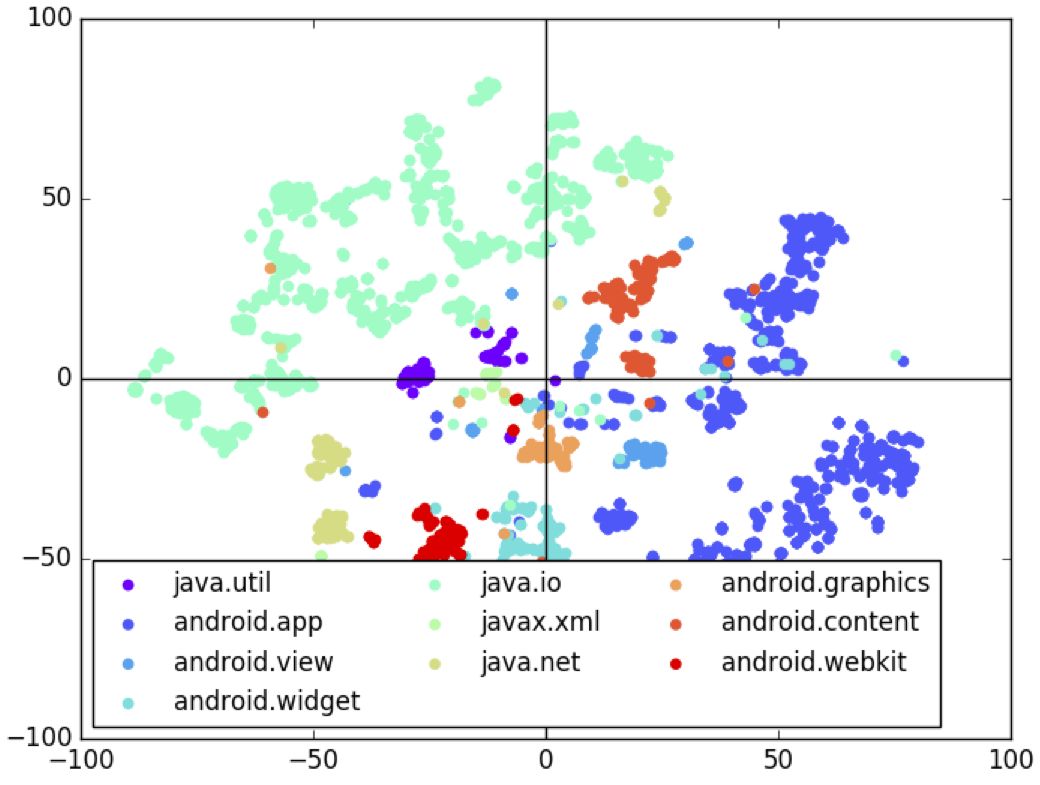
从上图我们可以很明显地看到,模型很好地根据API的不同学习了潜空间的聚类。
定量测试
研究人员基于1500个Android应用(收集自网络),进行了测试。研究人员使用JADX反编译这1500个Android应用安装文件(APK)到1亿行源代码,并从中提取出了15万Java方法。随后,研究人员将这15万Java方法转换成了AML程序。然后,从AML程序中提取出草图Y和X调用、X类型、X关键词,供模型训练。其中,分别随机选择了1万个AML程序,作为验证集和测试集。
理论上来说,验证生成程序的正确性需要验证程序的所有输入对应的输出符合预期。然而,这是一个不可判定问题。因此,研究人员转而使用一些间接的标准进行衡量。
期望AST
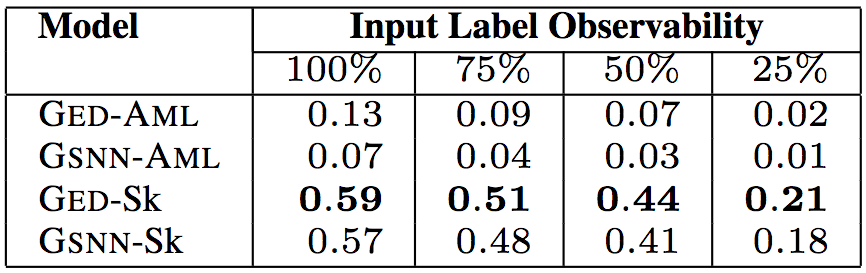
API调用顺序的相似程度(具体而言,研究人员使用了平均最小Jaccard距离)
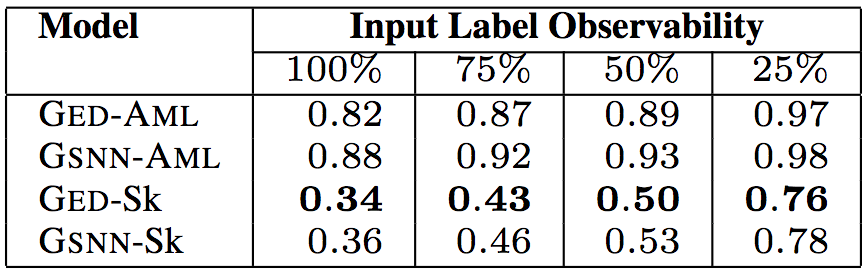
API调用方法的相似程度(同样基于平均最小Jaccard距离)
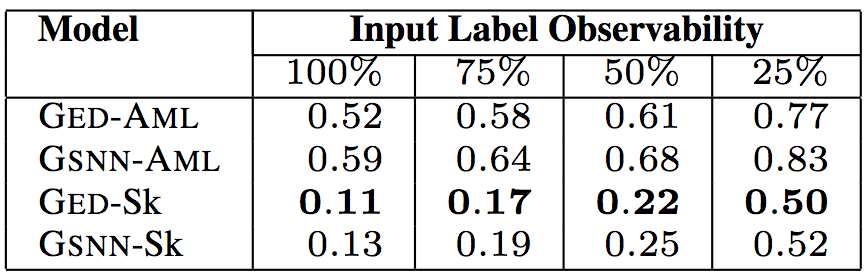
语句数目
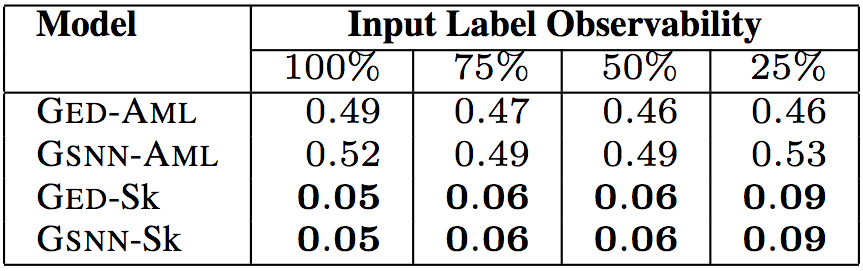
控制结构数目(例如,分支、循环、try-catch)数
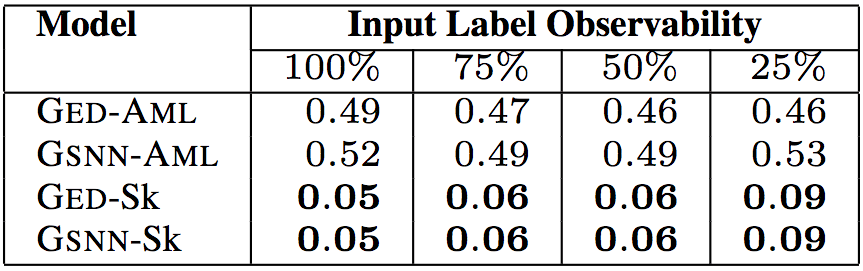
上面5张表格中,“Input Label Observability”(输入标签可观察性)表示测试数据提供的输入标签(API调用、类型、关键词)的信息比例。研究人员试验了75%、50%、25%的可观察性,相应的中位数分别为9、6、2。这样,研究人员可以评估给定少量关于代码的信息时,模型的预测能力。
下表显示了在50%可观察性下,模型在未见数据上的表现。
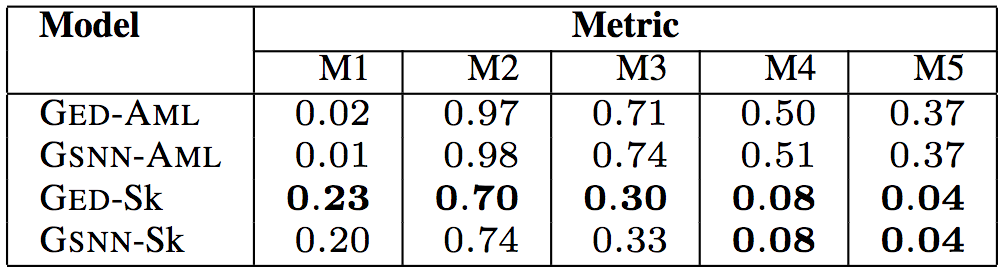
以上6个表格中,“Model”(模型)一列中,GED为研究人员所用的模型,GSNN(高斯随机神经网络)为当前最先进的条件生成式模型(Sohn等在2015年提出)。为了验证草图学习的有效性,研究人员进行了消融测试。带-Sk后缀的为基于草图学习的模型,带-AML后缀的为直接基于程序进行学习的模型。
测试结果表明,研究人员提出的模型GED-Sk表现最优,超过了当前的最先进模型GSNN。另外,GSNN-Sk的表现也不错,而直接基于程序进行学习的模型表现很糟糕。这说明草图学习是条件程序生成的关键。
定性测试
除了定量测试之外,研究人员也进行了定性测试。
文件读写
研究人员希望Bayou能生成一个写入文件的程序。想想看,如果你希望指示Bayou生成写入文件的程序,你会给出怎么样的提示呢?最低限度的提示,应该是两个关键词,write、file,或者,甚至仅仅是一个类型FileWriter。Bayou还没有这么智能,但它的表现已经相当抢眼了。研究人员给Bayou的输入仅仅是一个类型和一个关键词,几乎就是最低限度的信息了:
X类型= {FileWriter}
X调用= {write}
X关键词= {}
Bayou生成了如下的程序(选取自top-5):
BufferedWriter bw;
FileWriter fw;
try {
fw = newFileWriter($String, $boolean);
bw = newBufferedWriter(fw);
bw.write($String);
bw.newLine();
bw.flush();
bw.close();
} catch (IOException _e) {
}
注意,尽管输入只提供了FileWriter类型,程序使用了BufferedWriter,因为在Java中,文件读写经常基于buffer。Bayou自行学习到了这一点。另外,Bayou也正确地在关闭文件前清空了buffer。
Android对话框
研究人员希望生成一个程序,设定Android对话框的标题和信息。这次研究人员给定的输入已经到了最低限度:
X类型= {}
X调用= {}
X关键词= {android, dialog, set, title, message}
生成的程序如下:
Builder builder2;
Builder builder1;
AlertDialog alertDialog;
Builder builder4;
Builder builder3;
builder1 = newBuilder($Context);
builder2 = builder1.setTitle($String);
builder3 = builder2.setMessage($String);
builder4 = builder3.setNeutralButton($String,
$OnClickListener);
alertDialog = builder4.show();
虽然输入信息中没有指定,Bayou很智能地使用了帮助类AlertDialog.Builder。另外,Bayou还额外给对话框加上了一个按钮,这是因为Bayou学习到Android对话框经常配备一个按钮(通常用于关闭对话框)。
预览拍摄
最后一个例子是生成预览拍摄效果的程序。这次给定的输入可以说是极简了:
X类型= {}
X调用= {startPreview}
X关键词= {}
Bayou生成的程序:
parameters = $Camera.getParameters();
parameters.setPreviewSize($int, $int);
parameters.setRecordingHint($boolean);
$Camera.setParameters(parameters);
$Camera.startPreview();
这个例子充分体现了Bayou的智能之处。首先,Bayou自动识别出startPreview属于camera API。其次,Bayou在开始预览前,首先获取了相机参数,然后设定了预览显示尺寸。这正是Android camera API文档的推荐做法!
实现细节
研究人员将整个系统命名为Bayou,该系统由两部分组成,基于TensorFlow构建的GED,以及基于Eclipse IDE构建的草图抽象和组合具体化。
研究人员基于网格搜索进行交叉验证,选择表现最优的模型。
超参数设定如下:
编码器:调用64单元、类型32单元、关键词64单元。
解码器:128单元。
32维潜向量空间。
mini-batch尺寸:50。
Adam优化,学习率0.0006。
epoch:50。
整个模型的训练大约需要10小时(AWS p2.xlarge、K80、12G Ram)
结语
这是首个使用神经网络基于不确定的条件生成程序的研究。未来的IDE可能基于类似的模型提供极为智能的代码补全。
-
神经网络
+关注
关注
42文章
4772浏览量
100800 -
JAVA
+关注
关注
19文章
2969浏览量
104780
原文标题:莱斯大学新研究:神经草图学习,根据条件生成程序
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Java入门基础知识了解
N4373C:了解测量不确定度的规范和程序
测量误差和测量不确定度
浅谈Java编程学习 Java基础语法注意项
JAVA教程之JSP基础语法的详细资料说明

面向对象程序设计 - 课内实验1(Java语言概述)
Java的基础语法





 工商网监
工商网监
评论