 从产业落地以及学术创新两种视角出发,探索后深度学习时代的新挑战
从产业落地以及学术创新两种视角出发,探索后深度学习时代的新挑战
编者按:在工业界大量资源的投入下,大数据、大规模GPU集群带来了深度学习在计算机视觉领域的全面产业落地,在很多竞赛中甚至取得远超学术界的成绩。在AI领域的各个顶级会议上,越来越多的优秀工作也来自于Google、Facebook、BAT等巨头或者一些新锐创业公司。
值得注意的是,工业界目前的主要进展和应用落地,很大程度上依赖于高成本的有监督深度学习。而在很多实际场景中,存在数据获取成本过高、甚至无法获取的问题。因此,在数据不足的情况下,如何使用弱监督、乃至无监督的方式进行学习,这既是学术界中大家广泛关注的问题,其实也是工业界面临的新挑战。
商汤科技研发总监、中山大学教授林倞,将从产业落地以及学术创新两种视角出发,带领大家一起探索“后深度学习时代”的新挑战。
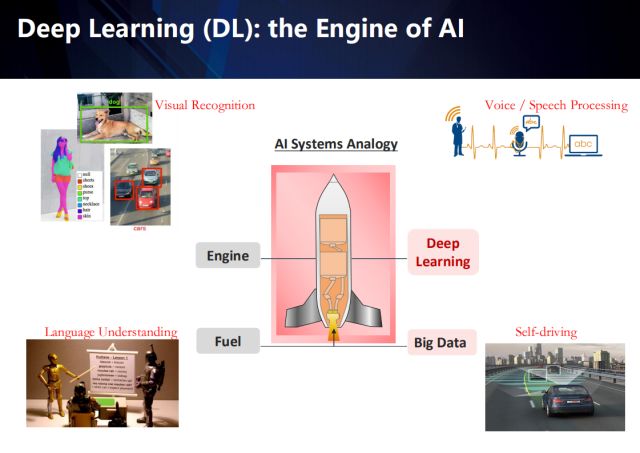
如果把AI系统比作为一架火箭,那么大数据就是它的燃料,深度学习则是它的引擎。随着大数据以及GPU算力的加持,深度学习在很多领域都取得了突破性的进展,例如视觉图像理解、属性识别、物体检测、自然语言处理、乃至自动驾驶。当然了,垂直化应用场景才是AI技术落地不可或缺的因素,这其实也是在工业界做研究的最大优势——从真实的需求引导技术的发展,而学术界的科研往往基于一些不太实际的假设。
基于视觉的图像理解,是从有标注的数据学习出AI算法,以实现相应的视觉识别任务,左上角展示了视觉图像理解中的物体检测以及属性识别应用。

而值得注意的是,深度学习在计算机视觉领域的成功应用,很大程度上依赖于有监督的数据,这意味着大量的完全标注的干净数据(例如人脸识别领域的数据)。然而,这样的数据意味着非常高昂的成本。在真实的场景中,经常存在的是弱监督或者从互联网上获取的数据(例如网络社交媒体的数据),以及无标注或者标注有噪声的数据(例如智慧城市以及自动驾驶等应用中采集到的数据)。
LeCun教授曾用右图的蛋糕,来形容有监督学习、无监督学习、以及强化学习之间的区别,这里借用来说明这三种数据的区别:完全标注的干净数据就像蛋糕上的金箔樱桃,甜美却昂贵;而弱标注或互联网爬取的数据,就像蛋糕上的奶油,还算甜但也可获取;而无标注的或者标注有噪声的数据,不太甜但成本较低。

在本次报告中,我将首先介绍深度学习如何应用于视觉理解,接下来会从三个方面介绍最新的深度学习范式:
以丰富多源的弱监督信息来辅助学习
算法自驱动、具有高性价比(性能/监督信息成本)的自主学习
无监督领域自适应学习
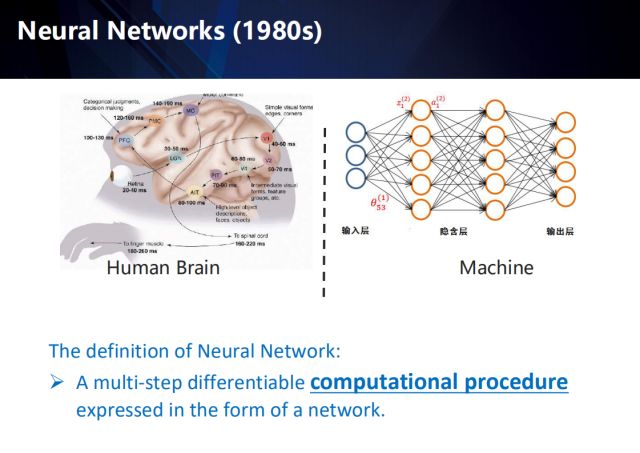
首先介绍一下深度学习的基本概念,深度学习被定义为最终以网络形式呈现的、涵盖了多个步骤的、可微分的计算过程。而说起深度学习,就要从上世纪80年代的神经网络开始讲起。神经网络其命名的初衷,是向人脑中的神经网络致敬。那么人脑中是如何处理视觉信号呢?
首先,视网膜输入视觉信号,经过LGN外膝体,到达视觉皮层V1—V5,其中V1对边缘和角点敏感,V2捕捉运动信息, V4对part物件敏感,例如人的眼睛、胳膊等,最后到达AIT,来处理高层信息:脸、物体等。送到PFC决策层,最后由MC发出指令。所以人脑处理视觉信号是一个从浅层到深层的过程,而在此过程中,并不是一个单一的处理,它还具备时序性,也就是说它在处理每个信号时,都是利用了之前的时序信息的。
深度神经网络的形式和计算过程与人脑有很大的不同,不过它的发明的确是受到了神经信号处理的启发,例如经典的感知机模型其实是对神经元最基本概念的模拟。右上展示了1980年发明的多层感知机。

从1980年代的多层感知机到2010年的卷积神经网络,它经历了一个层数由少至多、层级由浅至深的过程,通过解决网络梯度消失以及泛化不好的问题,以及数据及GPU的加持,它终于实现了一个一站式的端到端的网络。
自2010年起,深度学习方法取得了远超传统机器学习方法的成绩,尤其随着训练数据集的不断扩展,传统方法迅速触碰到精度天花板,相比之下,深度方法的预测精度则不断提升。这里总结了这一波深度学习技术革新的几个关键点,包括新的网络优化方法,如ReLu,Batch Normally,Skip Connection等;从数学/知识驱动到数据驱动的研究思路的转变;分治优化逐渐过渡到联合端到端联合优化;从避免过拟合学习到避免欠拟合学习;大量的开源代码和初始化模型的涌现。
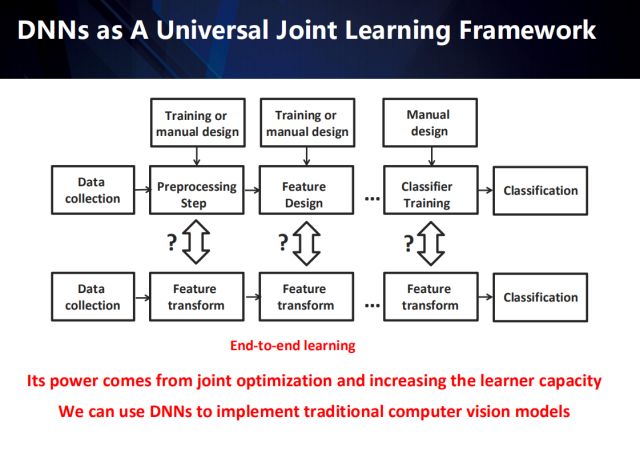
传统的模式识别任务,大致可总结为几个独立的步骤:包括数据采集、数据预处理、特征提取、分类器训练以及最终的分类。其中,数据预处理器和特征提取器的设计都是以经验为驱动的。而深度学习通过将预处理、特征提取以及分类训练任务融合,因此衍生出了一个,具有更强表示能力的端到端的特征转换网络。
在传统模式识别方法到深度方法的演变过程中,我们越来越体会到学习的重要性,而特征学习也已进化成一个端到端的学习系统,传统方法中的预处理已不是必须手段,而被融入端到端的系统中。似乎特征学习影响着一切模式识别任务的性能,然而,我们却忽视了数据收集和评估的重要性。
接下来我们举例说明传统方法是如何演化为深度方法的。
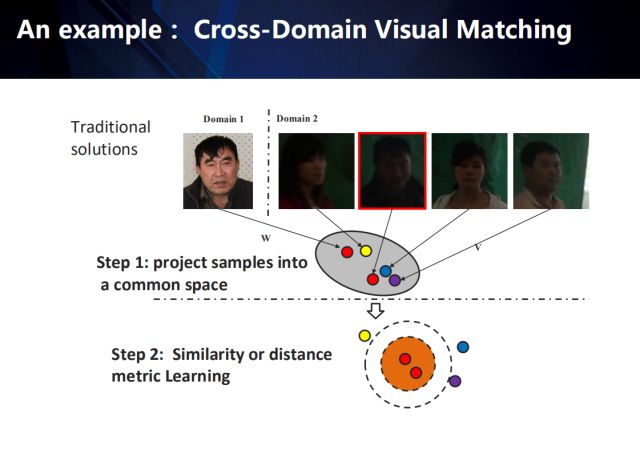
以跨领域视觉匹配任务(从领域2的数据中匹配到给定的领域1中的目标)为例,传统的方法一般会包含以下两个步骤:
首先,将来自于不同领域的样本投影到一个公共的特征空间 (特征学习);
然后,采用相似性或距离度量学习的方式,学习到一种距离度量,来表征这个公共空间上特征之间的相似性 (相似性度量学习)。
那么如何将这种相似性的度量整合到深度神经网络中,并进行端到端的学习呢?
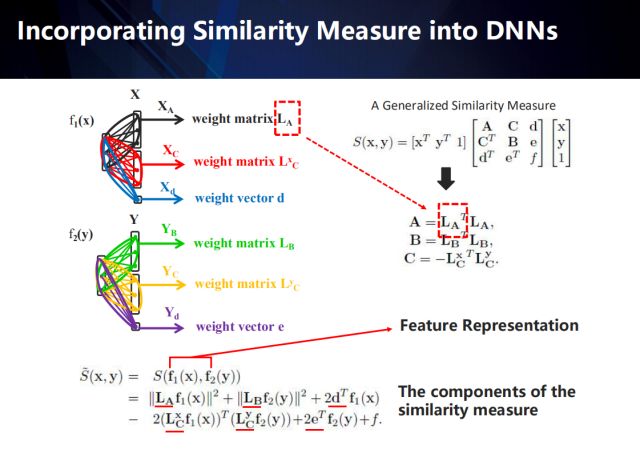
如何把相似性度量融合到特征提取中去?
以右上公式表示的相似性度量方法为例 (度量模型的提出和推导请参加相关论文),我们可以将该度量模型分解后融入到神经网络中——将原来的全连接网络表示成成若干个与度量模型相匹配的结构化网络。再通过误差反向传导,可以将度量模型与卷积特征进行联合学习、统一优化。详细过程如下:
右上公式中, A矩阵为x样本所在领域中样本间的自相关矩阵,半正定; B矩阵表示y样本所在领域中样本间的自相关矩阵,半正定;C矩阵则是两个领域样本间的相关矩阵。
展开后我们可以发现,其组成成分除了网络从不同域提取到的特征外,还包含6个不同的表达距离度量模型的变量(每个域包含2个矩阵和1个向量)。图中左上部分显示了我们将分解后的距离度量变量融入到神经网络中的过程——结构化的网络模型。
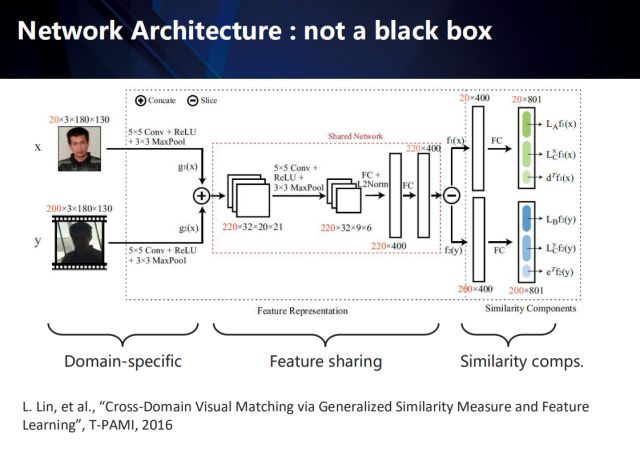
由此看来,深度网络并不是完全的黑盒子,通过引入领域知识和结构化模型,是可以具备一定的宏观解释性的。
以跨域视觉匹配算法为例,其内部可归纳为三个部分:域独有层、特征共享层、以及相似度量。
整个端到端的网络如图所示,其每个部分都具有可解释性。
在域独有层,该网络为不同域的数据提取该域的独有特征;
在特征共享层,我们首先将不同域的特征融合,再将融合后的特征投影到共有空间下,再反向拆解出各自域在该共有空间下的特征;
最终通过相似性度量得到不同域样本间的匹配相似度。
相关的工作发表在T-PAMI 2016上,该模型在当时很多领域取得了state-of-the-arts的效果。

我们的验证基准包括的几个主要任务:年龄人脸验证、跨摄像头的行人再识别、素描画与照片间的匹配、以及静态图片与静态视频间的匹配。
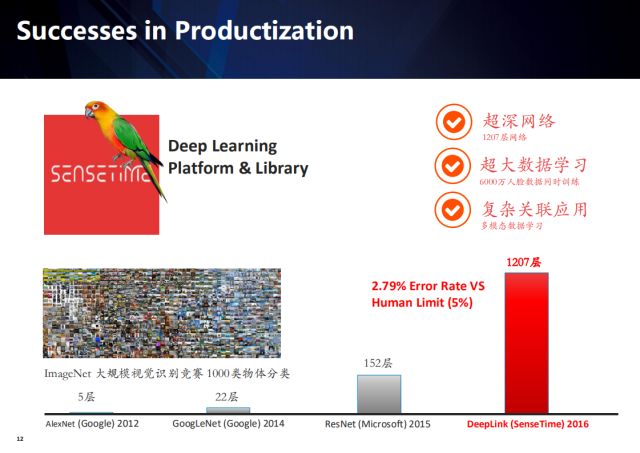
相比较之下,在公司做深度学习则充分发挥了海量计算资源和充足数据量的优势,学术界精心设计的算法优势很容易被工程化的能力抵消。
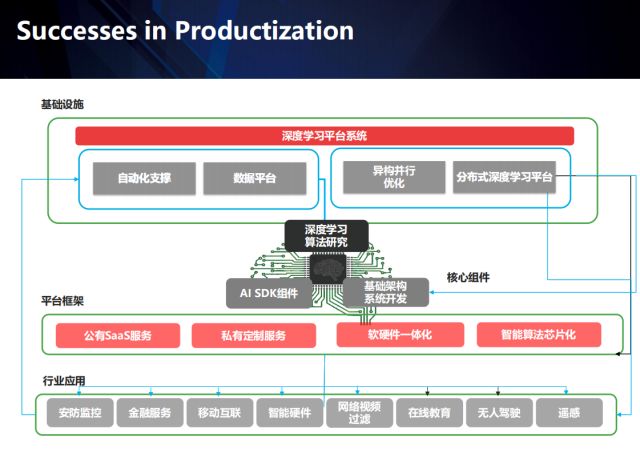
此外,区别于学术界只关注算法本身的模式,在工业界做产品,则涉及到大量的环节,不同的场景会衍生出不同的问题,此时通过应用场景形成数据闭环成为关键。商汤投入了大量资源建设基础平台、工程化团队,通过深入各个垂直领域、积攒行业数据、建立行业壁垒,目前正在从AI平台公司逐渐向AI产品公司过渡。

在工业界大量资源的投入下,大数据、大规模GPU集群带来了深度学习在计算机视觉领域的全面产业落地,在很多竞赛中甚至取得远超学术界的成绩。值得注意的是,工业界的这些进展的取得,是依赖于大量的全监督数据的,而在很多实际场景中,存在数据获取成本过高、甚至无法获取的问题。2012年以来,深度学习技术的高速发展并且在图像、语音等各个领域的取得了大量的成功应用,如果把这5年看成是一个新的技术时代, 那么在“后深度学习”时代,我们更应该关注哪些方向呢?
我在这个报告中给出一些想法——介绍3个新的深度学习范式:
以丰富多源的弱监督信息来辅助学习
算法自驱动、成本效益较高的自主学习
无监督领域自适应学习
Learning with Weak and Rich Supervisions

首先来介绍如何以丰富多源的弱监督信息来辅助学习。

由于网页形式的多样化,从互联网上获取的数据时常具备多种类型的标签,然而却不能保证标签的准确性, 往往存在标签噪声 。因此,这类数据可以看作具备丰富多源的弱监督信息。那么,我们考虑通过学习多个源的弱监督信息,来对标签进行更正。
将大量的数据连同带有小量噪声的标签,一起送入深度卷积神经网络,检测其中的标签噪声并进行更正。例如,右图展示了,通过融合图像数据以及对应的文本描述,来辅助对标签进行更正。
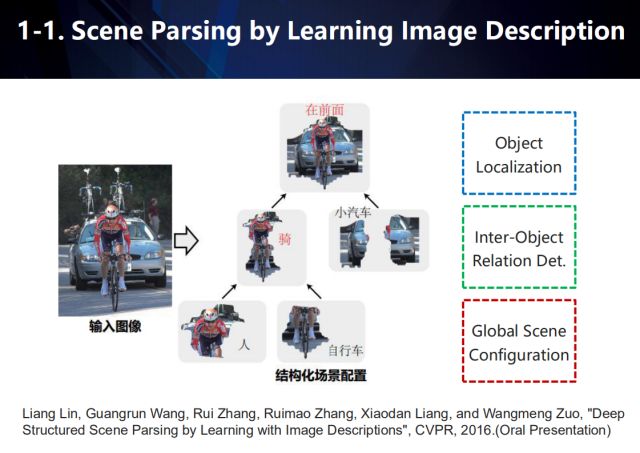
在场景解析任务中,我们通过学习图像的描述来解析场景。如图所示,利用物体定位来获取场景中具有显著性语义的物体,然后根据物体间的交互关系构建结构化场景配置。
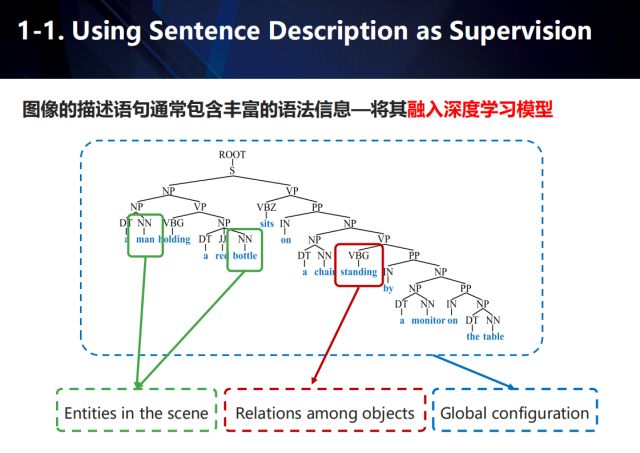
而图像的描述语句通常包含丰富的语法信息,如果能将这些信息融入深度学习模型,那么可以将其看作一种辅助的监督手段。以对图像描述这一应用为例,如图所示,我们用绿色框表示场景中出现的实体,红色框表示实体之间的关系,而蓝色框表示场景的全局配置结构。
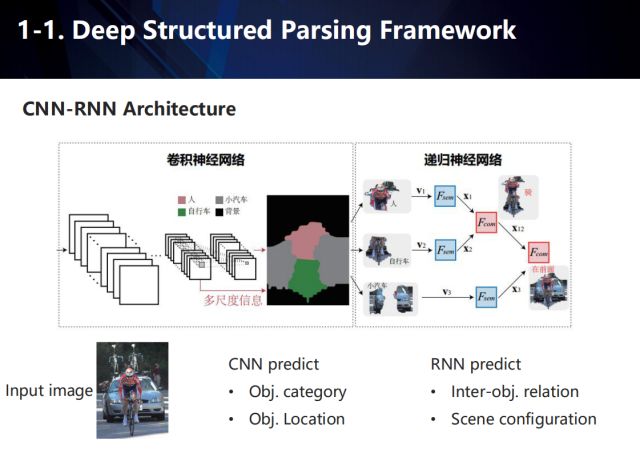
基于上述所说,我们提出了一个端到端的,结合卷积神经网络和递归神经网络的,深度结构化场景解析框架。输入的图片经过卷积神经网络后,会为每个语义类别产生得分图以及每个像素的特征表达,然后根据这些得分图对每个像素进行分类,并将同类别的像素聚合到一起,最终获取场景内v个目标的特征表达。然后将这v个目标的特征送入到递归神经网络中,并映射到某个语义空间,提取语义以预测物体间的交互关系。其训练过程如下:
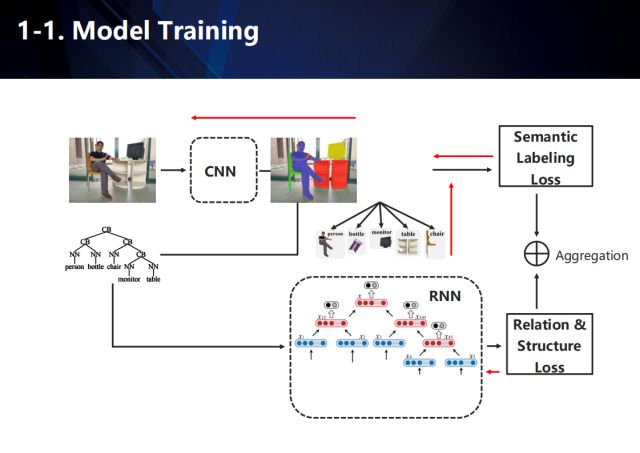
整个网络学习的目标包含两个,一个是卷积神经网络部分中的场景语义标注信息,另一个则是递归神经网络部分中的结构化解析结果。在训练的过程中,由于图像数据缺乏对应的场景结构化信息,我们需要对其进行估计,来训练卷积神经网络和递归循环神经网络。
简单来说,本工作的重点在于得到以下两个目标:(1)语义标注信息,包括定位语义实体的位置和确定语义实体之间的互动关系,(2)得到语义实体中的继承结构。
在本论文中采用的CNN-RNN联合结构,与单一RNN方法不同之处在于模型预测了子节点和父节点之间的关系。其中,对于语义标注,我们采用CNN模型为每一个实体类生成特征表达,并将临近的像素分组并对同类别使用同一标签。利用CNN生成的特征,我们设计RNN模型来生成图像理解树来预测物体之间的关系和继承结构,其中包括四个部分,语义映射(单层全连接层),融合(两个子节点结合生成一个父节点),类别器(其中一个子网络,用于确定两个节点之间的关系,并利用父节点的特征作为输入),打分器(另外一个子网络,衡量两个节点的置信度)。
本方法在学习过程中有两个输入,一个是图像,另外一个图像对应的解析句子,将图像输入CNN,得到图像的实体类特征表达,同时利用语义解析生成树方法将句子分解成语义树,并将图像得到的实体类与语义生成树一同输入到RNN网络中,利用图像的语义标注与关联结构树进行训练,从而得到预期的结果。

语义分割和场景结构化解析在PSACALVOC 2012 和SYSU-Scene 评测集上的实验结果展示如图。
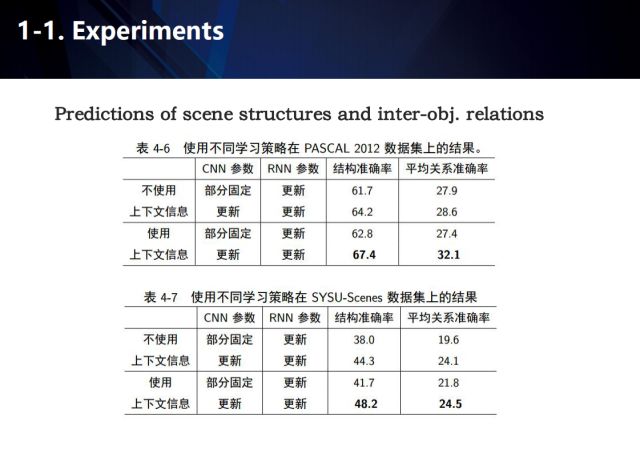
这里给出了使用不同的学习策略在PASCAL2012数据集上的结果,可以看出上下文信息被证明是一种有效的辅助手段。
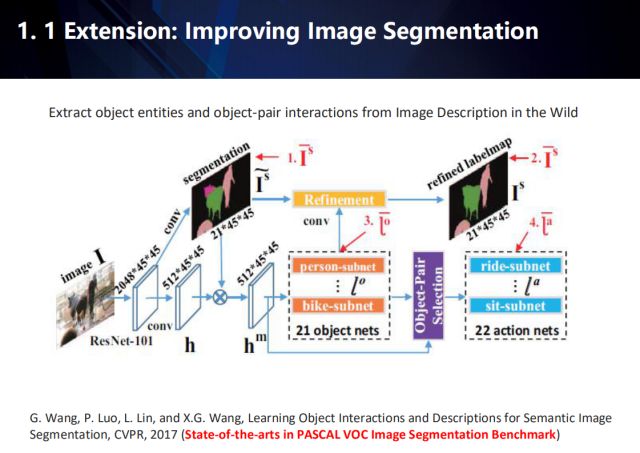
还可以扩展到图像语义分割领域。这一工作发表在CVPR2017,目前在PASCAL VOC数据集上做到了state-of-the-arts。
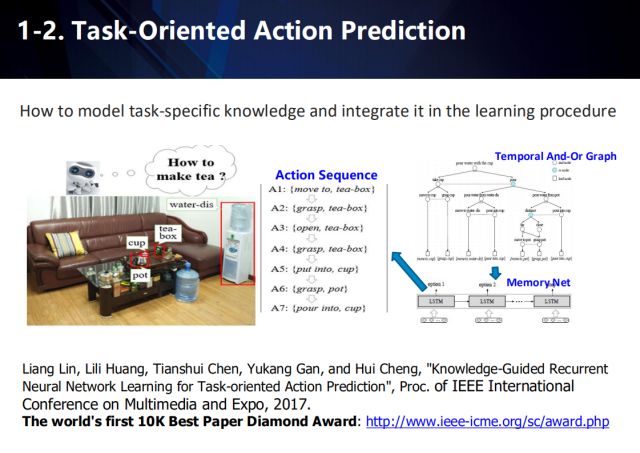
此外,在面向任务的动作预测中, 同样可以采用弱监督学习的方式来解决需要大量标注信息的问题。这一工作获得了The World’s First 10K Best Paper Diamond Award by ICME 2017.
这项工作首次提出了任务导向型的动作预测问题,即如何在特定场景下,自动地生成能完成指定任务的动作序列,并针对该问题进行了数据采集。在这篇论文中,作者提出使用长短期记忆神经网络(LSTM)进行动作预测,并提出了多阶段的训练方法。为了解决学习过程中标注样本不足的问题,该工作在第一阶段采取时域与或图模型(And-Or Graph, AOG)自动地生成动作序列集合进行数据增强,在下一阶段利用增强后的数据训练动作预测网络。具体步骤如下。
1)为了对任务知识建模,该文引入时域与或图(And-Or Graph, AOG)模型表达任务。AOG由四部分组成:表示任务的根节点,非终端节点集合,终端节点集合和权重分布集合。非终端节点包括与节点和或节点。其中,与节点表示将该节点的动作分解为有时序关系的子动作,或节点则表示可以完成该节点动作的不同方式,并根据概率分布P选择其中一个子节点。终端节点包括跟该任务相关的原子动作。
2)由于AOG定义时存在的时序依赖关系,该论文利用深度优先遍历的方法遍历每个节点,同时利用与或图长短期记忆模型(AOG-LSTM)预测该节点的支路选择。
3)由于原子动作序列非常强的时序依赖关系,该论文同样设计了一个LSTM(即Action-LSTM)时序地预测每个时刻的原子动作。具体地,原子动作Ai由一个原生动作以及一个相关物体组成,可表示为Ai=(ai, oi)。为了降低模型复杂性和预测空间的多变性,该论文假设原生动作和相关物体的预测是独立的,并分别进行预测。
Progressive and Cost-effective Learning

接着介绍一下自驱动、成本效益较高的学习方式。
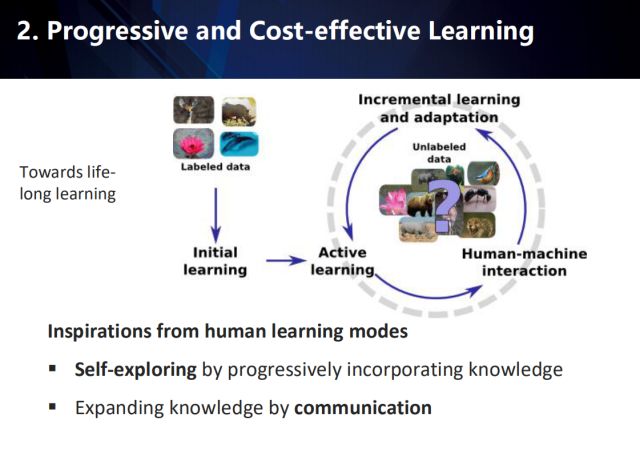
这类方法受到人类学习模式的一些启发:一是在逐步整合学习到的知识中自我探索,二是在交流的过程中不断扩充知识,以达到终生学习的目的。如上图所示,在学习的初期,利用已有的标注数据进行初始化学习,然后在大量未标注的数据中不断按照人机协同方式进行样本挖掘,以增量地学习模型和适配未标注数据。

在自我驱动、低成本高效益的学习方式中,课程学习和自步学习是一种有效的思路。
课程学习的基本思想,是由深度学习的开创者之一,YoshuaBengio教授团队于2009年的ICML会议上提出;而在2014年,由LuJiang等人提出了自步学习的公理化构造条件,并说明了针对不同的应用,可根据该公理化准则延伸出各种实用的课程学习方案。这些方法首先从任务中的简单方面学习,来获取简单可靠的知识;然后逐渐地增加难度,来过渡到学习更复杂、更专业的知识,以完成对复杂事物的认知。

在目标检测任务中,采用大量无标注、或者部分标注的数据进行训练,尽管充满挑战,但仍然是实际视觉任务中成本效益较高的方式。对于这一挑战,往往采用主动学习的方式来解决。而目前提出的主动学习方法,往往会利用最新的检测器,根据一个信度阈值,来寻找检测器难以区分的复杂样例。通过对这些样例进行主动标注,进而优化检测器的性能。然而,这些主动学习的方法,却忽视了余下大量的简单样例。
那么,如何既考虑到少量的复杂样例,又充分利用到大量的简单样例呢?
我们提出了一种主动样本挖掘(ASM)框架,如上图所示。对于大量未标注的检测数据,我们采用最新的检测器进行检测,并将检测结果按照信度排序。对于信度高的检测结果,我们直接将检测结果作为其未标注信息;而对于少量的信度低的检测结果,我们采用主动学习的方式来进行标注。最后,利用这些数据来优化检测器性能。
具体来说,我们采用两套不同的样本挖掘方案策略函数:一个用于高置信度样本的自动伪标注阶段,另一组用于低置信度样本的人工标注阶段。我们进一步地引入了动态选择函数,以无缝地确定上述哪个阶段用于更新未标注样本的标签。在这种方式下,我们的自监督过程和主动学习过程可以相互协作和无缝切换,进行样本挖掘。此外,自监督的过程还考虑了主动学习过程的指导和反馈,使其更适合大规模下物体检测的需要。具体来说,我们引进两个课程:自监督学习课程 (Self-Supervised learning Curriculum, SSC) 和主动学习课程 (Active Learning Curriculum, ALC)。SSC 用于表示一组具有高预测置信度,能控制对无标签样本的自动伪标注,而 ALC 用于表示很具有代表性,适合约束需要人工标注的样本。值得注意的是,在训练阶段,SSC 以逐渐从简单到复杂的方式,选择伪标签样本进行网络再训练。相比之下,ALC 间歇地将人工标注的样本,按照从复杂到简单的方式,添加到训练中。因此,我们认为 SSC 和 ALC 是对偶课程,彼此互补。通过主动学习过程来更新,这两个对偶课程能够有效地指导两种完全不同的学习模式,来挖掘海量无标签样本。使得我们的模型在提高了分类器对噪声样本或离群点的鲁棒性同时,也提高了检测的精度。

Interpretation:上面优化公式由(W,Y,V,U)组成,其中W指代模型参数(物体检测器的参数,我们的文章里面是Faster RCNN或者RFCN)。Y指代在自动标注下的物体检测器产生的proposal的伪标注类别。V={v_i}^N_{i=1}指代自步学习过程(self-paced learning,在上式中为self-supervised process)下对每个proposal训练实例的经验损失权重,v_i取值为 [0,1)的一个连续值m维向量(m为类别数目)。U={u_i}^N_{i=1}指代主动学习下对每个训练实例的经验损失权重,u_i取值为一个{0,1}二值标量。
W是我们想要学习的参数,其余Y,V,U都可以看成是为了学习W而要推断的隐变量。后两个为权重隐变量,基于选择函数(selector)作用于每个样本训练损失。具体来说,W的优化基于经验损失的加权和。因此,在每次优化W之前,我们必须要知道Y (由于经验损失为判别误差,没有自步学习过程下的给与的伪标注(Y),所有数据都只能利用AL的人工标注,整个方法退化为全监督学习) 。同时在优化W和Y之前,我们必须要知道U和V的值(知道每一个u_i和v_i的取值,才能决定哪些训练实例的y值需要人工标注(自主学习AL),那些需要机器自动推断 (自监督过程SS)。);同时,知道每一个u_i和v_i,才能基于选择器(selector)推断出经验误差的训练权重)。给定样本i基于u_i和v_i的值域以及选择器可以看出,u_i=1>v_i^{j}对应样本会被选择为主动学习的人工标注对象,u_i=0<=v_i^{j}时对应样本会得到自动标注。

于是,问题落在如何推断U和V这两个权重隐变量集合身上。容易看出U和V要联合推断,而如何选择U和V则由每个训练实例的经验损失以及其对于各自的控制函数(f_SS, f_AL)决定。f_SS的具体解释可以参考自步课程学习(self-paced curriculum learning),简单的理解就是优先选择训练损失较小的样本进行学习,这表现为训练损失越小赋予的权重越大。随着lambda变大(优化过程中,lambda和gamma都会逐渐变大),训练会开始接纳具有更大训练误差的样本。f_AL相反,主动学习一开始会从训练误差较大的样本(样本误差比较小的会被置零,从而被选择为自监督过程并且得到自动标注)中选择并进行人工标注。随着gamma增大,主动学习会开始接纳更小的误差的样本。
模型函数 f_SS代表了一种贪心的自监督的策略。它大大地节省了人工标注量,但是对于累计预测误差造成的语义恶化无能为力。并且,f_SS极大依赖于初始参数 W。由于模型函数 f_AL存在,我们可以有效地克服这些缺点。f_AL选择样本给用户进行后处理,通过f_AL获得的人工标注被认为是可靠的,这种过程应该持续到训练结束。值得一提的是,通过 f_SS进行的伪标注只有在训练迭代中是可靠的,并且应该被适当的调整来引导每个阶段更鲁棒的网络参数的学习。实际上,f_SS和f_AL是同时作用与每一个样本的,这会等价于一个minimax的优化问题。
另一方面,U和V在推断时需要考虑前一阶段已经由主动学习中的人手工标记好的信息。我们利用之前的人手工标记好的信息,定义了两个基于U和V的取值约束,称为“对偶课程”(Dual Curricula)。该约束项将被自主学习选过的训练样本,如该样本属于m个类别之中的一类,我们将其为u和v值设定为1;如该样本不在m个类别之中,我们将其u和v值设定为0。这意味着我们的训练框架可以容纳新类别的发掘,同时不会让新类别影响检测器的训练。V^{lambda}_{i}和U^^{lambda}_{i}只基于之前AL选择后的结果分别对u和v值进行约束。
形象来说,我们采用两套不同的样本挖掘方案策略函数:一个用于高置信度样本的自动伪标注模式,另一组用于低置信度样本的人工标注模式。我们进一步地引入了动态选择函数,以无缝地确定上述哪个阶段用于更新未标注样本的标签。在这种方式下,我们的自监督过程和主动学习过程可以相互协作和无缝切换,进行样本挖掘。此外,自监督的过程还考虑了主动学习过程的指导和反馈,使其更适合大规模下物体检测的需要。具体来说,我们引进两个课程:自监督学习课程 (Self-Supervised learning Curriculum, SSC) 和主动学习课程 (Active Learning Curriculum, ALC)。SSC 用于表示一组具有高预测置信度,能控制对无标签样本的自动伪标注,而 ALC 用于表示很具有代表性,适合约束需要人工标注的样本。值得注意的是,在训练阶段,SSC 以逐渐从简单到复杂的方式,选择伪标签样本进行网络再训练。相比之下,ALC 间歇地将人工标注的样本,按照从复杂到简单的方式,添加到训练中。因此,我们认为 SSC 和 ALC 是对偶课程,彼此互补。通过主动学习过程来更新,这两个对偶课程能够有效地指导两种完全不同的学习模式,来挖掘海量无标签样本。使得我们的模型在提高了分类器对噪声样本或离群点的鲁棒性同时,也提高了检测的精度。

基于u和v的联合推断构成了一个可基于训练实例分解的minmax优化问题。对于每一个训练实例u和v,我们证明了在满足一定条件下,该推断具有基于上式表达的闭式解 (具体考究这个有点复杂,可以参考我们的文章)。大概意思是,在考虑训练实例i的类别经验误差和的时候,大于第一个阈值会u_i值会收敛为1 (大括号里面第一种情况)。由于v^{j}_i<1,我们知道该实例会被选作人工标注。另一方面,在类别经验误差和小于另一个阈值(大括号第二行第一个不等式)时,u_i值会收敛为0。由于v^{j}_i>=0,我们知道该实例会被选作机器自动标注,同时根据误差大小,相应赋予不同的权重。当误差越大,自动标注越有可能出错,于是自动赋予权重越小。在大于某一值域(大括号第二行第二个不等式)下,v和u都会同时为零,这意味着该样本不参与本轮训练。
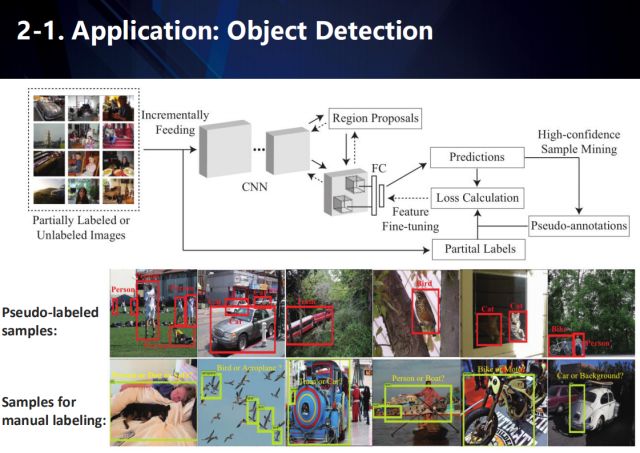
上图展示了提出的框架(ASM)在目标检测中的应用。

在PASCALVOC2007/2012结果中,我们的方法仅仅利用大约30~40%左右的标注数据,就能达到state-of-the-arts的检测性能。

如何利用大量原始视频学习
类似的策略可以应用在人体分割任务中,我们利用人体检测器、和无监督的分割方法,从大量的原始视频(来自YouTube)中生成人体掩膜。这些掩膜信息可以作为分割网络的标注信息。同时,结合分割网络输出的信度图,对人体检测器提取的候选区域结果进行修正,以生成更好的人体掩膜。
Unsupervised Domain Adaptation

为了适配不同领域数据间的分布,解决目标任务缺乏数据标注的难题,我们将探索无监督领域自适应学习方法,包括单数据源领域自适应、以及多数据源领域自适应。
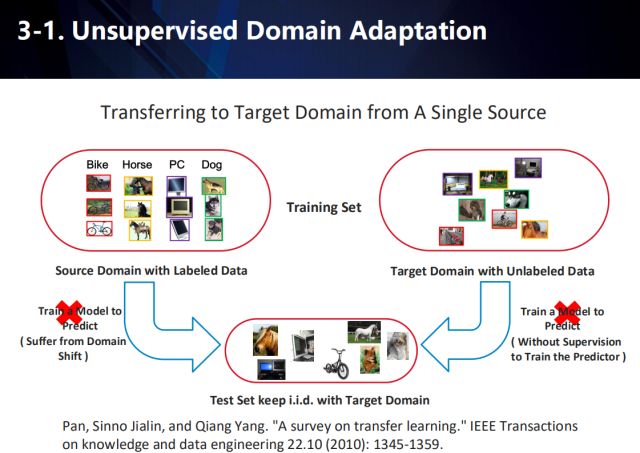
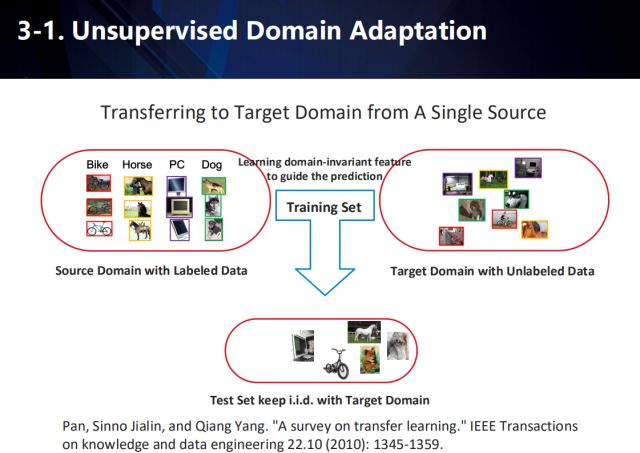
单数据源领域自适应
在应用场景中,往往存在某一领域的可用数据过少,而其他类似领域的可用数据充足,因此,衍生出了一系列迁移学习的方式,以做到跨领域的自适应。例如,在图示的任务中,源域的数据一般是带有标注信息的,而目标域的数据不仅与源域中的数据含有不同的分布,往往还没有标注信息。因此,通过将学习到的知识从源域迁移到目标域,来提高算法在目标域数据上的性能。
因此,需要联合有标注的源域数据和无标注的目标域数据,来学习一个与域无关的特征,来进行最终在目标域上的预测。
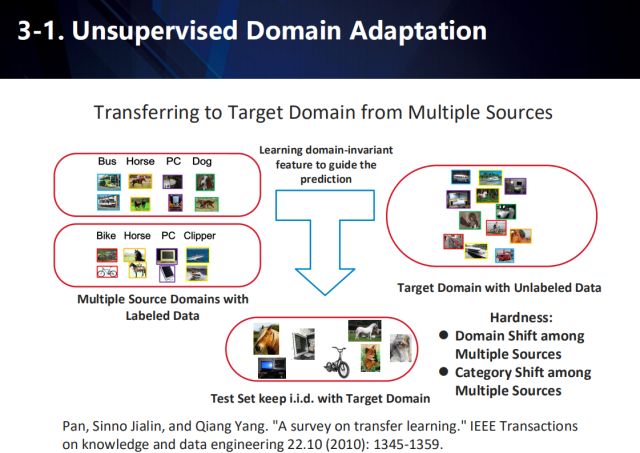
多数据源领域自适应
而对于从多数据源向目标域迁移学习的情况,将更加复杂,需要考虑:1.多种源域数据本身之间具有偏差 2.多种源域数据间类别存在偏差。
因此我们提出了一种名为“鸡尾酒”的网络,以解决将知识从多种源域的数据向目标域的数据中迁移的问题。
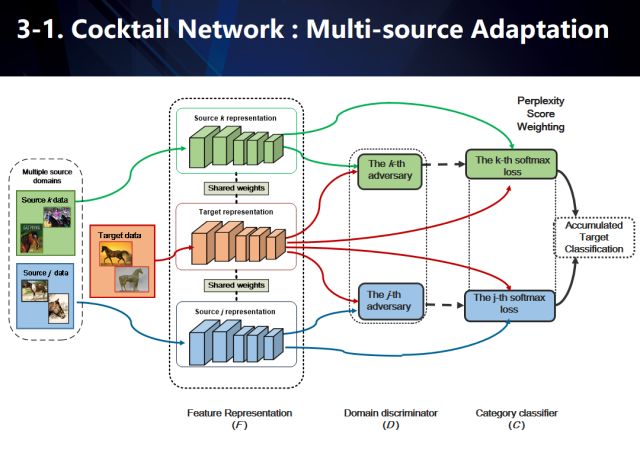
“鸡尾酒”网络
鸡尾酒网络用于学习基于多源域(我们的图示仅简化地展示了j,k两个源域)下的域不变特征(domaininvariantfeature)。在具体数据流中,我们利用共享特征网络对所有源域以及目标域进行特征建模,然后利用多路对抗域适应技术(基于单路对抗域适应(adversarial domainadaptation)下的扩展,对抗域适应的共享特征网络对应于生成对抗学习(GAN)里面的生成器),每个源域分别与目标域进行两两组合对抗学习域不变特征。同时每个源域也分别进行监督学习,训练基于不同源类别下的多个softmax分类器。注意到,基于对抗学习的建模,我们在得到共享特征网络的同时,也可以得到多个源分别和目标域对抗的判别器。这些判别器在对于每一个目标域的数据,都可以给出该数据分别与每一个源域之间的混淆度(perplexityscore)。因此,对于每一个来自目标域的数据,我们首先利用不同源下的softmax分类器给出其多个分类结果。然后,基于每一个类别,我们找到包含该类别的所有源域softmax分类概率,再基于这些源域与目标域的混淆度,对分类概率取加权平均得到每个类别的分数。简而言之就是,越跟目标域相识的源域混淆度会更高,意味着其分类结果更可信从而具有更高的加权权值。
需要注意的是,我们并没有直接作用于所有softmax分类器上反而是基于每个类别分别进行加权平均处理。这是因为在我们的假设下,每个源的类别不一定共享,从而softmax结果不能简单相加。当然,我们的方法也适用于所有源共享类别的情况,这样我们的公式会等价于直接将softmax分类结果进行加权相加。
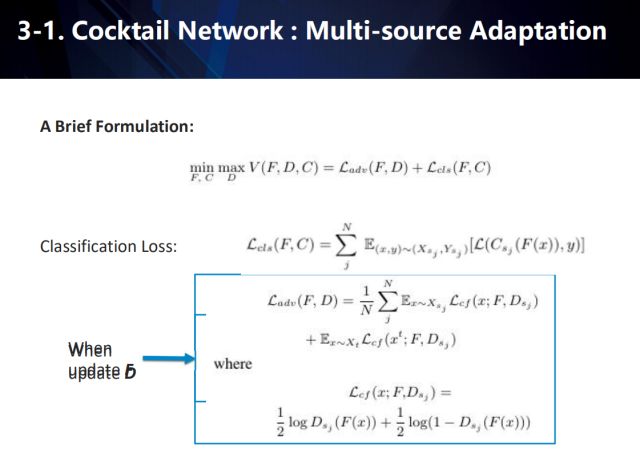
其中,L_adv 是对抗损失,当训练判别器时用传统的GAN loss,当训练feature extractor时用confusion loss。L_cls是多源域(multiple source domains)分类损失,C为多源域softmax分类器。N是source的数目,s_j 代表第j个source,C_{s_j}代表第j个source的softmax 分类器 (用C来表示全部source的分类输出),D_{s_j}代表第j个source跟target对抗的判别器 (用D来表示全部的对抗结果),F为feature extractor。

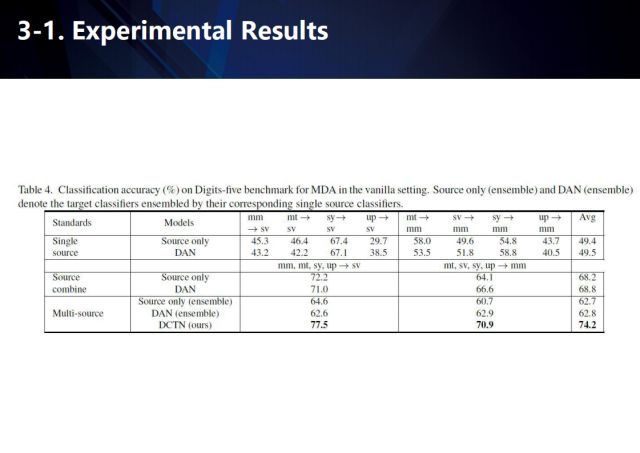
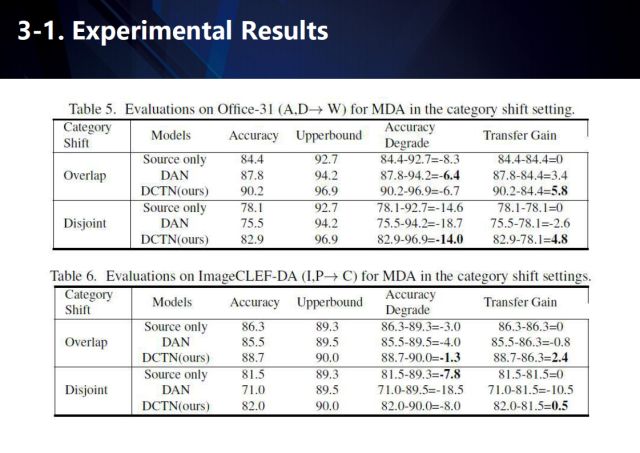
我们分别在Office-31、ImageCLEF-DA、Digit-five数据集上进行了测评,我们的方法取得了很好的结果。

-
AI
+关注
关注
87文章
30728浏览量
268892 -
大数据
+关注
关注
64文章
8882浏览量
137403 -
深度学习
+关注
关注
73文章
5500浏览量
121113
原文标题:后深度学习时代:弱监督学习、自主学习与自适应学习如何用于视觉理解
文章出处:【微信号:AI_Thinker,微信公众号:人工智能头条】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
国产深度学习框架的挑战和机会
两种典型的电池供电电路的设计方案
《AI for Science:人工智能驱动科学创新》第一章人工智能驱动的科学创新学习心得
2017全国深度学习技术应用大会
Nanopi深度学习之路(1)深度学习框架分析
labview深度学习检测药品两类缺陷
从储能、阻抗两种不同视角解析电容去耦原理

深度学习的三种基本结构及原理详解
深度学习时代的新主宰:可微编程






 工商网监
工商网监
评论