 连接视觉语言大模型与端到端自动驾驶
连接视觉语言大模型与端到端自动驾驶
连接视觉语言大模型与端到端自动驾驶
端到端自动驾驶在大规模驾驶数据上训练,展现出很强的决策规划能力,但是面对复杂罕见的驾驶场景,依然存在局限性,这是因为端到端模型缺乏常识知识和逻辑思维。而视觉语言多模态大模型(LargeVision-Language Models,LVLM),例如GPT-4O,已经展现出极强的视觉理解能力和分析能力,可以很好的与端到端模型互为补充,充当驾驶决策的“大脑”。
基于这个思路,我们提出了一种连接视觉语言多模态大模型和端到端模型的智驾系统 Senna,针对端到端模型鲁棒性差,泛化性弱问题,行业首创“大模型高维驾驶决策-端到端低维轨迹规划”的新驾驶范式,打造“大模型 +端到端”的下一代架构,实现安全,高效,拟人的智能驾驶。经多个数据集上的大量实验证明Senna 具有业界最优的多模态+端到端规划性能,展现出强大的跨场景泛化性和可迁移能力。
概述
端到端自动驾驶在大规模驾驶数据上训练,展现出很强的决策规划能力,但是面对复杂罕见的驾驶场景,依然存在局限性,这是因为端到端模型缺乏常识知识和逻辑思维。而视觉语言多模态大模型(Large Vision-Language Models,LVLM),例如GPT-4O,已经展现出极强的视觉理解能力和分析能力,可以很好的与端到端模型互为补充,充当驾驶决策的“大脑”。基于这个思路,我们提出了一种连接视觉语言多模态大模型和端到端模型的智驾系统Senna,针对端到端模型鲁棒性差,泛化性弱问题,行业首创“大模型高维驾驶决策-端到端低维轨迹规划”的新驾驶范式,打造“大模型+端到端”的下一代架构,实现安全,高效,拟人的智能驾驶。经多个数据集上的大量实验证明,Senna具有业界最优的多模态+端到端规划性能,展现出强大的跨场景泛化性和可迁移能力。
Senna解决的研究问题
此前基于大模型的自动驾驶方案,往往将大模型直接作为端到端模型,即直接用大模型预测规划轨迹或者控制信号,但是大模型并不擅长预测精准的数值,因此这种方案并不一定是最优解。此前神经学的研究表明,人脑在做细致决策时,层次化的高维决策模块和低维执行模块组成的系统起到了关键的作用。例如,当想要左转的驾驶员看到红绿灯由红变绿,大脑中首先会思考,现在红绿灯变绿了,因此我可以加速启动通过路口。然后再通过“打转向灯”,“踩油门”等一系列动作完成通过路口这个目标。基于上述观察,Senna主要尝试探索和解决三个问题:
(1)如何有效地结合多模态大模型和端到端自动驾驶模型?

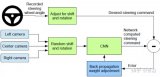
Senna采用解耦的行为决策-轨迹规划思路,多模态大模型在大规模驾驶数据上微调,以提升其对驾驶场景的理解能力,并采用自然语言输出高维决策指令,然后端到端模型基于大模型提供的决策指令,生成具体的规划轨迹。一方面,使用大模型预测语言化的决策指令,可以最大利用其在语言任务上预训练的知识和常识,生成合理的决策,并且避免预测精确数字效果欠佳的缺陷;另一方面,端到端模型更擅长精确的轨迹预测,将高维决策的任务解耦,可以降低端到端模型学习的难度,提升其轨迹规划的精确度。
(2)如何设计一个面向驾驶任务的多模态大模型?
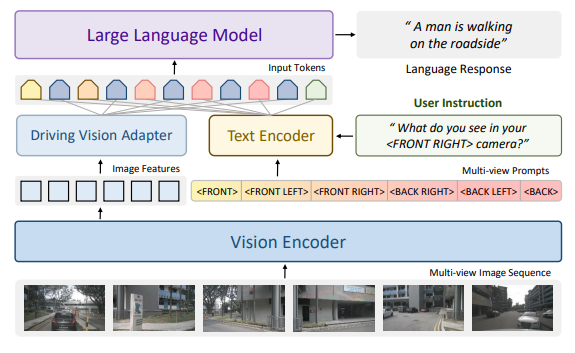
驾驶依赖于准确的空间感知,目前常见的多模态大模型没有针对多图输入进行专门优化,此前针对驾驶任务的大模型或者仅支持前视输入,缺乏完整的空间感知,存在安全隐患;或者支持多图输入,但是并没有进行细致的设计,或针对其有效性进行验证。
为了解决这些问题,我们提出了Senna,Senna包含两个模块,一个驾驶多模态大模型 (Senna-VLM) 和一个端到端模型(Senna-E2E),相比于通用的多模态大模型,Senna-VLM针对驾驶任务做出如下设计:首先,针对驾驶的大模型需要支持多图从而可以输入环视和多帧的信息,这对于准确的驾驶场景理解和安全非常重要。最初,我们尝试简单基于LLaVA-1.5模型加入环视多图输入,但是效果并不符合预期。在LLaVA中,一张图像需要占用576个token,6张图则需要占用3456个token,这几乎要接近最大输入长度,导致图像信息占用的token数量过多。因此Senna-VLM对图像编码器输出的图像token做进一步特征压缩,并设计了针对环视多图的prompt,使得Senna可以区分不同视角的图像特征并建立空间理解能力。
(3)如何有效地训练面向驾驶任务的多模态大模型?
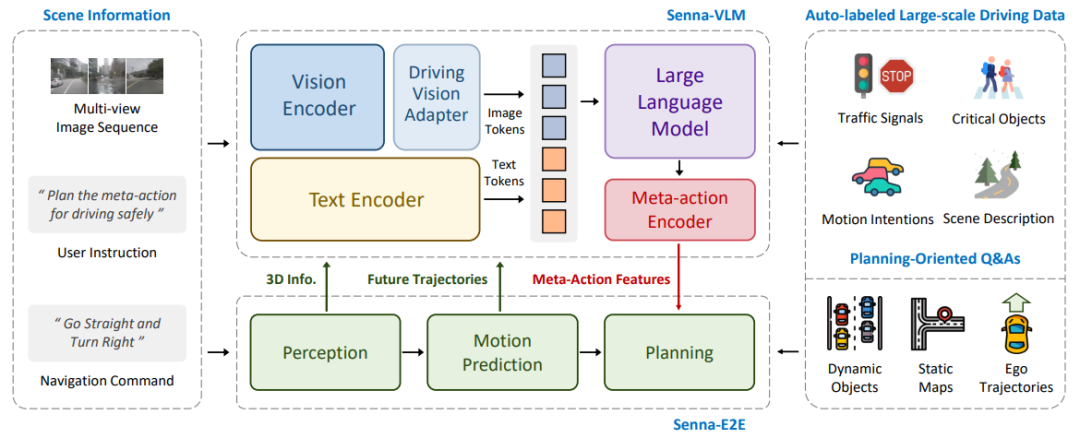
在有了适合驾驶任务的模型设计后,有效地训练LVLM是最后一步。这部分包括两方面的内容,数据和训练策略。在数据方面,此前工作提出了一些策略,但是很多并不是针对规划服务,例如检测和grouding。另外,很多数据依赖于人工标注,这限制了数据的大规模生产。在本文中,我们首次验证了不同类型的问答数据在驾驶规划中的重要性。具体来说,我们引入了一系列面向规划的问答数据,旨在增强Senna对驾驶场景中与规划相关的线索的理解,最终实现更准确的规划。这些问答数据包括驾驶场景描述、交通参与者的运动意图预测、交通信号检测、高维决策规划等。我们的数据策略可以完全通过自动化流程实现大规模生产。至于训练策略,大多数现有方法采用通用数据预训练,然后针对驾驶任务微调。然而,我们的实验结果表明,这可能不是最佳选择。我们为 Senna-VLM 提出了一种三阶段训练策略,包括混合数据预训练、驾驶通用微调和驾驶决策微调。实验结果表明,我们提出的三阶段训练策略可以实现最佳的规划性能。
Senna的关键创新
在模型层面,Senna提出层次化的规划策略,可以充分利用大模型的常识知识和逻辑推理能力,生成准确的决策指令,并通过端到端模型生成具体的轨迹。另外,Senna设计了针对环视和多图的策略,通过图像token压缩和精心设计的环视prompt,有效提高了多模态大模型对驾驶场景的理解。
在数据方面,我们设计了多种可以大规模自动标注的面向规划的驾驶问答数据,包括场景描述、交通参与者行为预测、交通信号识别以及自车决策等。这些问答数据对于Senna生成准确的决策起到了关键作用。
在训练层面,我们提出三阶段的大模型训练策略,不仅提升了Senna在驾驶场景的表现,且有效保留了其常识知识而不至于出现模式坍塌的问题。
Senna的实验及应用效果
基于多个数据集上的大量实验表明Senna 实现了state-of-the-art的规划性能。实验结果的亮点在于,通过使用在大规模数据集上预训练的权重并进行微调,Senna 实现了显著的性能提升,与没有预训练的模型相比,平均规划误差大幅降低了27.12% ,碰撞率降低了33.33%,这些结果验证了 Senna 提出的结构化的决策规划策略、模型结构设计和训练策略的有效性。Senna强大的跨场景泛化性和可迁移能力,展现出成为下一代通用智驾大模型的潜力。
未来探索方向
Senna初步探索并验证了基于语言化的决策将大模型和端到端模型结合的可行性。下一步,我们将利用更精细的语言决策,并基于决策信息以可控的方式实现个性化的轨迹规划,并在可解释性、闭环验证等方面进一步探索优化。相信Senna将会激发行业在该领域的进一步研究和突破。
-
智能驾驶
+关注
关注
3文章
2505浏览量
48734 -
自动驾驶
+关注
关注
784文章
13784浏览量
166375 -
大模型
+关注
关注
2文章
2423浏览量
2637
原文标题:下一代“多模态大模型+端到端”架构Senna:开创智驾决策规划全新范式
文章出处:【微信号:horizonrobotics,微信公众号:地平线HorizonRobotics】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
自动驾驶真的会来吗?
自动驾驶系统要完成哪些计算机视觉任务?
基于视觉的slam自动驾驶
端到端的自动驾驶研发系统介绍
端到端自动驾驶到底是什么?

佐思汽研发布《2024年端到端自动驾驶研究报告》

理想汽车加速自动驾驶布局,成立“端到端”实体组织

Mobileye端到端自动驾驶解决方案的深度解析






 工商网监
工商网监
评论