 PolarDB-MySQL引擎层的索引前缀压缩能力的技术实现和效果
PolarDB-MySQL引擎层的索引前缀压缩能力的技术实现和效果
在 PolarDB 中, 通过轻量级压缩的实现, 可以实现减少数据大小的同时, 性能有一定程度的提升. 如何实现的呢?
背景
近几年互联网行业的降本增效浪潮愈演愈烈, 如数据压缩、分级存储等技术成为了数据库产品(在技术层面上)实现降本的核心手段。作为一款云原生数据库,PolarDB 会面向大量行业、场景、需求不同的云用户,同样有必要且已经支持了这些能力。PolarDB 在全链路多个层级上实现了并正逐步商业化数据压缩能力, 如整形、字符串、BLOB 等数据格式类型的压缩,数据列字典压缩、二级索引前缀压缩,存储层的数据块软/硬件压缩等。
首先要提到的必然是 MySQL 官方原生的两种压缩能力:表压缩和透明页压缩。这两种压缩能力由于或这或那的各种原因,在实际线上业务中并没有被广泛仍可和使用。例如前者在 Buffer pool 中存在两个版本数据且有较为复杂的融合逻辑,后者需要文件系统支持 punch hole 只能对带宽压缩而没有优化 IOPS,两者只采用限定的相对开销较高的通用块压缩算法等。它们的实测表现也导致传统 MySQL 用户在印象里常觉得压缩会牺牲不少性能并带来较多复杂度。
事实上,在通用块压缩的基础上,如果可以引入更细致的轻量级压缩, 甚至在压缩后的数据上直接进行计算, 那么可以在实现数据压缩的同时又保证甚至提升性能。并且,在计存分离架构下,远程 I/O 时延更长,如果可以通过压缩减少数据大小, 从而减少 I/O, 压缩带来的收益相比于本地盘就更加明显。
由 MySQL 向外扩展来看,针对:(1)动态(update-in-place)或静态(append-only)数据;(2)行存或列存组织组织(数据同质性不同);(3)有序链或无序堆组织的数据(数据局部性不同)等不同情况,能适用的压缩方法也是不同的,并且压缩能获得的效果会有很大差异。因此,对于 PolarDB-MySQL 来说,除了官方的两种原生压缩能力,通过轻量级压缩方法实现页内/行级压缩(这也是 Oracle、SQL Server、DB2 等企业级数据库的标准能力),也是重要发展路径。
PolarDB 前缀压缩
本文就主要介绍 PolarDB-MySQL 引擎层的索引前缀压缩能力(Index Prefix Compression)的技术实现和效果。
通过建立索引结构可以提升数据检索的性能,代价是额外的写放大和维护索引结构的存储空间。OLTP 中为了支持多种访问路径,比较常见的情况是在一个表上建立非常多的索引,这就导致索引在数据库整体存储空间中占了很大比例。索引存储占到 50% 以上的实例并不少见,这些实例通常在单表会有几十个二级索引。
由于索引的 key 部分数据存在有序性,因此对索引 key 部分进行前缀压缩往往可以取得不错的压缩效果。如果用户的数据表中存在较多的索引(如一些做sass的用户),索引数据量相对整体数据量的占比不低,此时前缀压缩的收益其实十分可观。
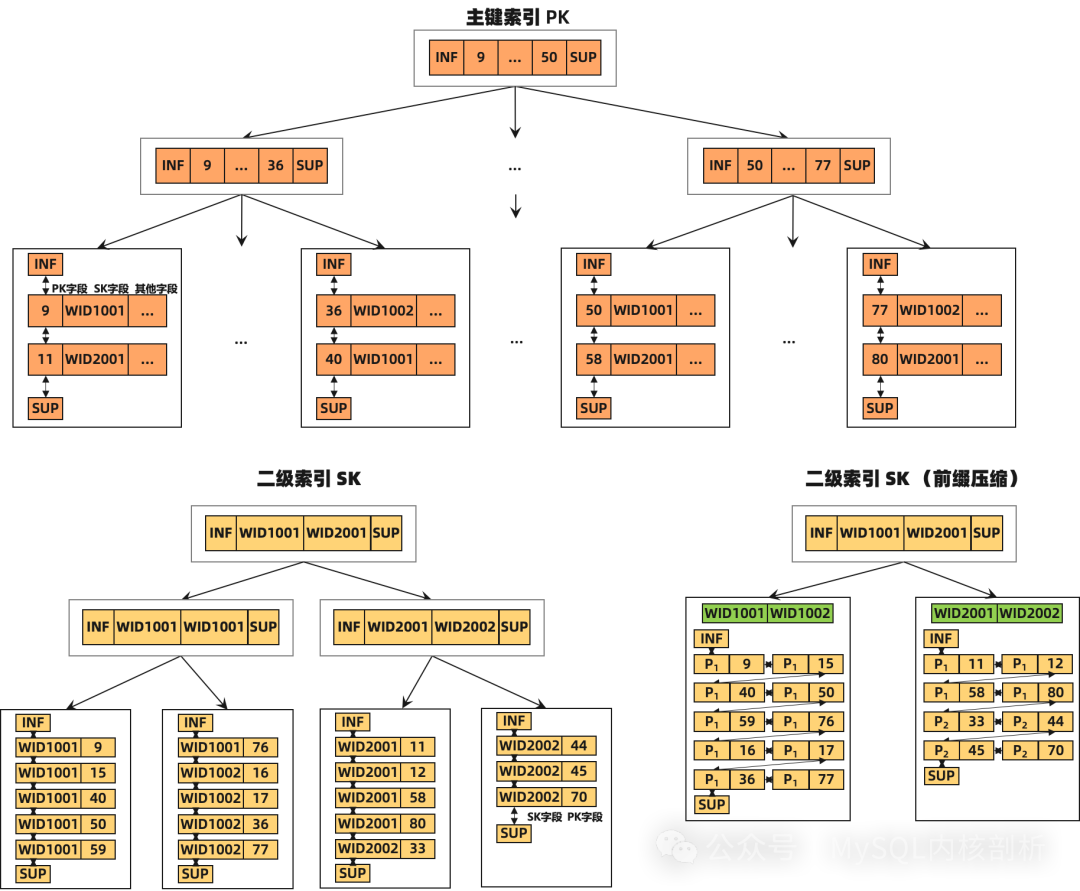
我们先简单了解一下 InnoDB 的索引结构,对于主键 record,首先是所有主键 key 的字段列、再是非 key 数据的字段列;而二级索引 record,则先是对应二级索引 key 的字段列、再是主键 key 的字段列。
值得一提的是,部分商业数据库在实现 non-unique index 时,一般会将相同的二级索引对应的主键索引聚集存放, 这样二级索引 key 部分的数据只需要存一份(Duplicate Key Removal)。而在 InnoDB 中的实现较为简单, 每个二级索引 record 为重复的二级索引 key 字段加不同主键 key,这加剧了 InnoDB 索引数据膨胀的问题。
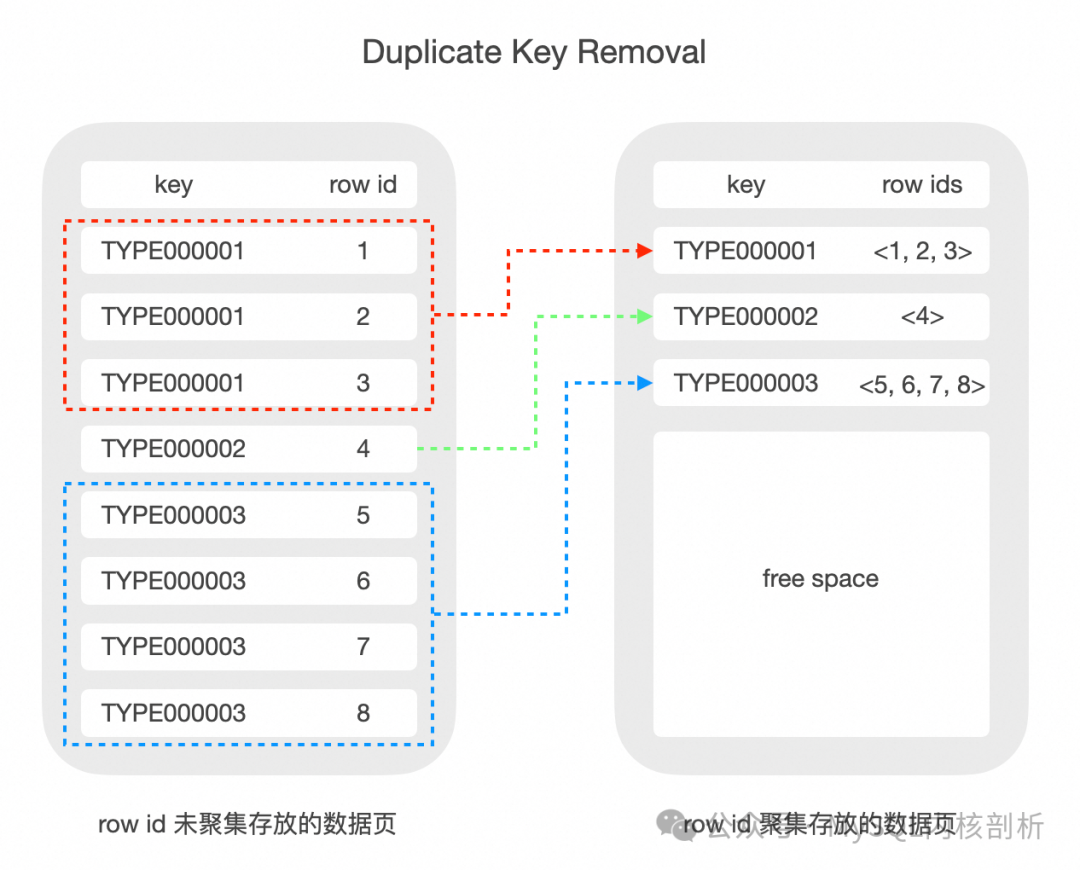
前缀压缩设计原理
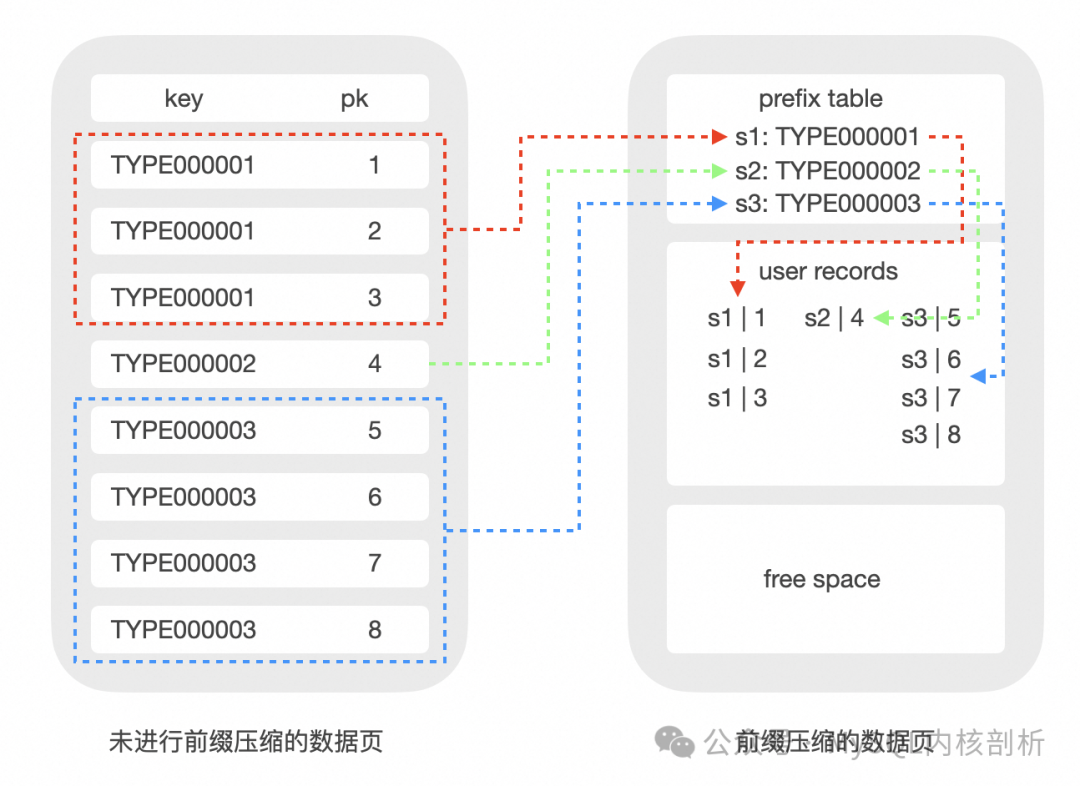
前缀压缩其实有多种具体实现,比如同个 Page 的 record 前缀重复出现部分的直接压缩,如前缀为 "aaaaa" 直接压缩为 "a5";或相对前一记录重复部分的压缩,又或相对具体元素的前缀重复部分,提取 "aaaaa" 到公共区域作为前缀。
我们采用的方法是将 record 分为两个部分:前缀部分在多个 record 之间共享,因此可以只存储一份,从而实现数据压缩;后缀部分由每个 record 单独存储。因此压缩后的 record 中只存储了前缀部分的指针 + 后缀部分的数据。
对数据页内的 record 进行前缀压缩效果:
采用前缀压缩,可以有效减少 btree 索引的节点数量:
压缩元数据的设计
对于InnoDB索引这样有序的数据链,可以依赖前面的记录作为前缀压缩的 prefix base,也可以将 prefix base 额外存储下来。但由于 InnoDB index 的 update-in-place 导致 record 是动态的,所以前者为动态 prefix base,而后者一般设计为(半)静态 prefix base。对于前者,在 base record 变迁情况下,由于依赖的压缩 record 可能膨胀,可能会进一步导致原来 optimistic 操作变成 pessimistic 的,引起明显性能下降,并加剧代码复杂性导致风险。因此,PolarDB 这里采用的是半静态 prefix base 设计。
PolarDB 在 page 内部新建 symbol table 存放压缩所需要的元信息,根据压缩算法的不同,元信息可以是字典信息、前缀信息等等。
symbol table 放在 page 中,可以实现 page 自解析,避免读取时额外的 IO,并且解压 record 是开销非常小的纯内存操作。
symbol table 的物理位置在 system record 之后 user record 之前,也就是 page heap 的起始位置。一旦某个版本的 symbol table 确定之后,除非发生完整的 symbol table 更新,其内容是不会进行修改的,因此我们称之为半静态的。symbol table 内部有版本信息、元数据信息和元数据索引信息等等内容,用来实现 record 的快速压缩和解压。
数据的压缩
以 insert 为例,当经过事务处理、记录构建、索引定位等等操作后,最终会走到 btree 操作的底层函数中。这里会将获取的 dtuple_t 转换成 rec_t 选定(乐观/悲观)模式后插入数据,这时候应该要考虑压缩逻辑了。我们此时已经拿了所需的 page 锁,因此可以保证 page 内相关信息的独占性,所有需要 page 中压缩辅助信息内容的行压缩可以在这一步实现。在这一过程中进行压缩使得 rec_t 中的数据为压缩数据,同时需要在 rec_t 保留相关的元信息。
对于前缀压缩,我们采取压缩的时机是 lazy 的,即新插入的 record 在 page 上保持非压缩状态,等到 page 容量触发阈值时,再对 page 整体进行压缩,这样保证压缩开销被均摊到多次 DML 操作上,而不会每次操作都有压缩开销。
而触发 encode 阈值是在 optimistic 路径的 page 满且判断 reorganize 也无法腾出空间时触发。原本会放锁进入 SMO 流程,我们这里先尝试 page 级别整体的encode。
不在 SMO 时做压缩是因为其持有 index latch 和多个 page latch,对并发操作的影响范围太大,其次 page 内部的压缩不需要依赖其他信息。page 级别的压缩会尝试对所有记录进行最优化选取前缀压缩元信息,并判断对应生成的新 symbol table 是否会有足够收益,有则压缩数据并更新。
我们在 record 的 Info bits 上拓展了一个 bit 来表征此记录是否是压缩格式,老版本记录对应标志不会被设置从而完全兼容原有操作路径。在一个 page 页内可以同时存在压缩和非压缩两种类型的记录,根据对应标志位判断处理模式。
数据的解压
首先需要保证在所有 record 使用路径上,解压逻辑能够全面覆盖,让用户拿到原始记录。其次,InnoDB 内部也存在 dtuple_t(内存记录格式)和 rec_t(页上物理记录格式)两种 record 格式类型的转换与比较。当数据前缀压缩后可能失去列属性,因此 rec_get_offsets 等函数无法对压缩后的 rec_t 直接解析,需要对应的改造相应函数获取 rec_t 中的物理数据偏移。另外,InnoDB 记录的比较是基于列的,offsets 本质是辅助解析 rec_t 至各列的结构,只要保证相应信息能将压缩部分数据也能解析出来,就可以用压缩 rec_t、压缩元信息以及对应的 offsets,去和 dtuple_t 转换或比较。总的来说,对于压缩的 record,要么先完全解压构建原来的 rec_t 数据走原来比较逻辑,要么用改造过的 offsets 或 dtuple_t 以及对应的列比较执行函数来做比较(可解释压缩计算)。PolarDB 目前在不同路径上会根据环境条件从两种方式中选择之一。
前缀压缩的典型应用
对于如 SaaS/电商场景等一些用户,其数据表中存在较多的索引可以通过前缀压缩的降低存储成本。并且我们和客户了解到很多情况下, 表数据中有大量的冗余重复数据, 虽然单表中总共有 1 亿行, 但是某一行, 比如是品类只有 200 种左右, 这种是最常见的场景.
这种场景在 sysbench-toolkit 里面是 saas_multi_index 场景: https://github.com/baotiao/sysbench-toolkit
从下面的测试数据可以看到, 在 Saas/电商等典型场景里面, 前缀压缩可以在获得比较高的压缩率同时提升整体读写性能。
IO Bound 场景
表结构如下
CREATE TABLE `prefix_off_saas_log_10w%d` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `saas_type` varchar(64) DEFAULT NULL, `saas_currency_code` varchar(3) DEFAULT NULL, `saas_amount` bigint(20) DEFAULT '0', `saas_direction` varchar(2) DEFAULT 'NA', `saas_status` varchar(64) DEFAULT NULL, `ewallet_ref` varchar(64) DEFAULT NULL, `merchant_ref` varchar(64) DEFAULT NULL, `third_party_ref` varchar(64) DEFAULT NULL, `created_date_time` datetime DEFAULT NULL, `updated_date_time` datetime DEFAULT NULL, `version` int(11) DEFAULT NULL, `saas_date_time` datetime DEFAULT NULL, `original_saas_ref` varchar(64) DEFAULT NULL, `source_of_fund` varchar(64) DEFAULT NULL, `external_saas_type` varchar(64) DEFAULT NULL, `user_id` varchar(64) DEFAULT NULL, `merchant_id` varchar(64) DEFAULT NULL, `merchant_id_ext` varchar(64) DEFAULT NULL, `mfg_no` varchar(64) DEFAULT NULL, `rfid_tag_no` varchar(64) DEFAULT NULL, `admin_fee` bigint(20) DEFAULT NULL, `ppu_type` varchar(64) DEFAULT NULL, PRIMARY KEY (`id`), KEY `saas_log_idx01` (`user_id`) USING BTREE, KEY `saas_log_idx02` (`saas_type`) USING BTREE, KEY `saas_log_idx03` (`saas_status`) USING BTREE, KEY `saas_log_idx04` (`merchant_ref`) USING BTREE, KEY `saas_log_idx05` (`third_party_ref`) USING BTREE, KEY `saas_log_idx08` (`mfg_no`) USING BTREE, KEY `saas_log_idx09` (`rfid_tag_no`) USING BTREE, KEY `saas_log_idx10` (`merchant_id`) ) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8
IO Bound 场景随机读,采用随机 point read,128线程,4G Buffer Pool,二级索引大小 20G,压缩后 3.5G。测得压缩后 QPS 是 49w,非压缩是 26w,压缩是非压缩的 1.88 倍。
可以看到再开启了压缩之后, 性能并没有下降, 而是有一定程度的提升, 原因如下:
压缩可以减少btree叶子节点的数量,在 IO bound 场景增加了 buffer pool 对叶子节点的覆盖率,覆盖更多的 page 意味着随机读场景更少的 page 换入换出,对 bp 的 hash table 和 lru list 访问频率更小,hash 锁和 lru list 锁竞争更少,此外,对文件系统的 IO 次数更少,用户线程直接命中 BP 即可返回。
CPU Bound 场景
CPU Bound 场景随机写(index锁冲突),256 线程,100G Buffer Pool 足够大,单表,一个二级索引,为了效果更加明显,将二级索引的行长设置为 500,insert 场景,测得压缩 10w QPS,非压缩 8w QPS,压缩是非压缩的 1.25 倍。
page 中 record 密度更大,减少了 page 分裂频率,缓解了分裂对 index SX 锁的争抢,而且减少了正在分裂节点的父节点拿的 X 锁数量,缓解了对其叶子节点的插入。此外,为了减少开启压缩后 SMO 时拿 index 锁时间,压缩路径不覆盖 SMO 过程。
CPU Bound场景随机读,压缩和非压缩性能差不多。
在 bp 足够大时进行随机读取,那么压缩并不会带来性能提升,但访问压缩 record 会带来一定解压开销,但解压开销很小(内存的随机访问),因此读取性能差不多。
压缩率
还有一个比较关心的问题就是压缩效率,目前每个 page 有 symbol table,记录了公共前缀,且一个 record 压缩到最后是有一部分元数据的。所以并不是 record 越大,压缩率就一定会更好的。假设公共前缀部分基本占据了整个 record,那么经过演算得到压缩率随 record size 的变化曲线是抛物线,由于默认 row 格式时 dynamic,其index key长度限制是 3072Bytes,相当于 1024 个 utf8 字符,这个值小于压缩率取到极值的点。
测试结果:
测试二级索引大小对压缩率的影响,探讨压缩的极限压缩率。单线程顺序insert 400w~800w条数据,datasize不超过128的插入800w行,datasize大于128的插入400w行。采用最大的重复率,即每个page里面只有几种rec。data size是二级索引字段的大小,单位是utf8字符,data size为32相当于96Bytes,其未压缩的索引大小是压缩的2.92倍。注意,不同灌数据方式会导致不同的压缩率,这里测的是单线程随机插入,压缩效率优于多线程并发插入,因为并发插入可能导致不必要的page分裂。
| data size | 32 | 64 | 128 | 256 | 512 |
| 压缩率 | 2.92 | 5.04 | 8.28 | 15.11 | 27.36 |
-
压缩
+关注
关注
2文章
101浏览量
19353 -
MySQL
+关注
关注
1文章
799浏览量
26413
原文标题:PolarDB 索引前缀压缩
文章出处:【微信号:inf_storage,微信公众号:数据库和存储】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
阿里国际推出全球首个B2B AI搜索引擎Accio
Meta开发新搜索引擎,减少对谷歌和必应的依赖
OpenAI推出SearchGPT原型,正式向Google搜索引擎发起挑战
微软计划在搜索引擎Bing中引入AI摘要功能
一文了解MySQL索引机制

新火种AI|谷歌推出AI搜索引擎惹得出版商担忧!新闻流量的至暗时刻要来了吗?

OpenAI注册新域名,准备推出结合AI技术的搜索引擎挑战谷歌
OpenAI或将推出ChatGPT搜索引擎
MySQL的整体逻辑架构

谷歌搜索引擎优化的各个方面和步骤
导致MySQL索引失效的情况以及相应的解决方法
Mysql索引是什么东西?索引有哪些特性?索引是如何工作的?





 工商网监
工商网监
评论