 ETH-X超节点:开辟AI算力约束突破的新路径
ETH-X超节点:开辟AI算力约束突破的新路径
面对人工智能大模型的迅速发展及其对算力资源的急剧增长需求,单芯片性能提升遭遇瓶颈,同时通过Scale Out策略扩展多机集群以增加算力也遇到了局限性。在此背景下,中国信通院与腾讯携手GPU、CPU、交换机芯片制造商、服务器供应商、网络设备厂商及互联网企业等多方力量,共同发起超大带宽ETH-X(以太网)超节点计划,旨在通过技术创新与行业合作,构建开放可扩展的HBD(高带宽域)超节点系统样机,探索AI算力提升新途径,为构建ETH-X超节点互联开放协作产业生态提供支撑。同时,将共同编制相关技术规范,为行业树立标准,引导超节点技术高质发展。
AI大模型发展与算力需求
AI大模型的发展依赖于持续提升算力。根据Scaling Law(规模定理),增大模型规模与增加训练数据量是直接提升AI大模型智能水平与性能的关键途径。但对集群算力需求的将呈指数级增长。
长序列是AI大模型发展的另一个重要方向。长序列提高AI大模型回答问题的质量、处理复杂任务的能力以及更强的记忆力和个性化能力的同时,也会加大对训练和推理算力资源的需求1,尤其是对显存资源的需求。因此满足AI大模型发展需求,算力能力的持续提升成为一个重要基础。
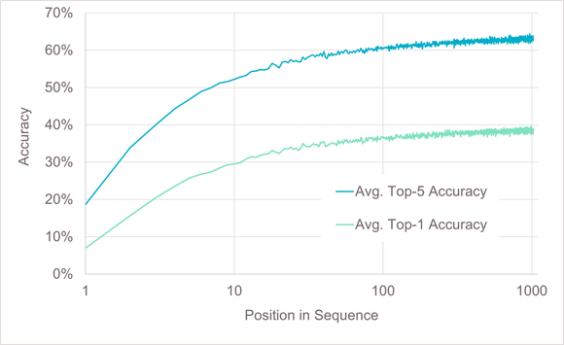
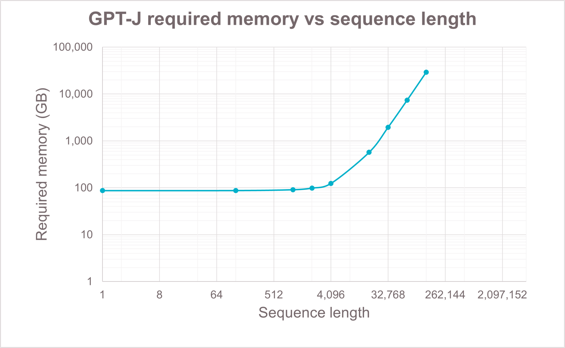
图1 长序列带来的准确率收益以及显存需求
单芯片算力提升遇阻、
scale out集群算力提升受限
当前,提升集群算力已面临一些明显的制约因素。首先,单芯片性能提升受到HBM容量带宽增长赶不上算力增长速度的限制,内存墙问题制约算法发挥。如在典型模型与并行方式下,Nvidia Hopper一代芯片的有效算力(HFU)明显低于Ampere一代芯片,如图2所示。另一种通过Scale out扩展集群规模提升整体算力的方式也受到GBS(Global Batch Size)不能无限增长的限制,导致在集群规模增大到一定程度后,HFU出现明显下降。最后,模型参数量增大需要更大的模型并行规模,模型并行中Tensor并行或MOE类型的Expert并行都会在GPU之间产生大量的通信,并且这部分通信很难与计算进行overlap。而当前典型一机八卡服务器限制了Tensor并行的规模或Expert并行通过机间网络,这都会导致HFU无法提高。
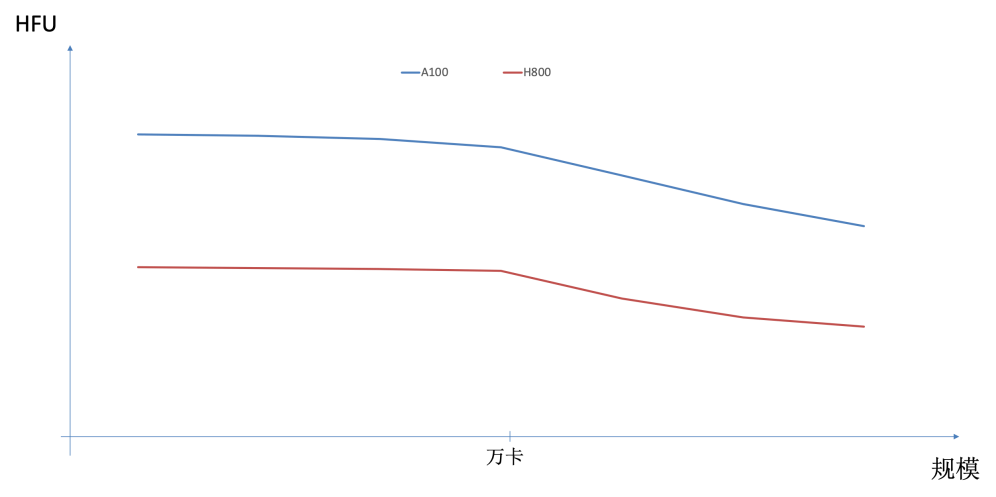
图2 不同型号GPU以及不同规模集群对HFU的影响
通过scale up扩大HBD(超带宽域)的超节点成为突破方向
HBD(High Bandwidth Domain)是一组以超带宽(HB)互联GPU-GPU的系统2。HBD内GPU-GPU通信带宽是HBD之间GPU-GPU通信带宽的数倍。如Nvidia H100 提供900GBps HB带宽,HBD间GPU-GPU通信带宽只有100GBps。因此在模型并行中将数据量大、无法overlap的部分限制在一个HBD内完成。
当前,HBD限制在一台服务器内,典型1机8卡服务器是8张GPU卡之间通过某种HB连接技术实现互联,构成一个HBD=8的系统。然而更大的参数规模、更长的序列长度、更多的MOE专家数量、更大的集群规模,都造成了更多的通信数据量。HBD=8的情况下,大量的数据通信均需经过HBD间的scale out网络,因此通信占比提高、HFU下降的问题凸显。
通过构建更大的HBD系统,以scale up方式提升系统算力是解决上述问题的有效途径之一。如MIT与Meta的研究论文中,通过建模分析3,论证了扩大HBD对训练性能的提升效果。另外,Nvidia也实现了不同规模HBD系统并进行了部署与验证4。
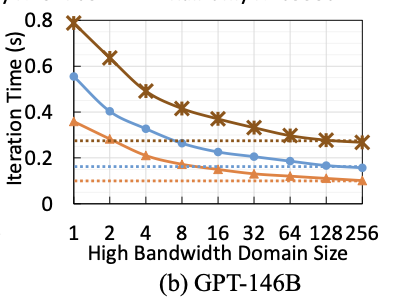
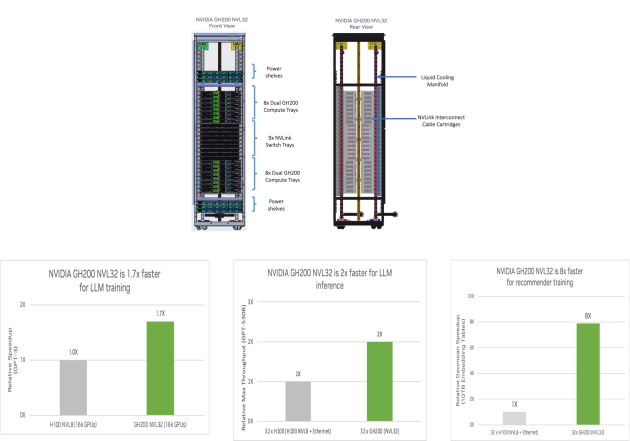
图3 HBD超节点典型代表与业务收益举例
Nvidia将HB互联不仅用于GPU-GPU之间,而是将其应用到GPU-CPU/Memory的超大带宽互联,例如GH200、GB200产品。通过此方式为GPU提供一个超带宽访问CPU/Memory的能力。
Nvidia产品具备支持GPU-CPU/Memory的统一内存编制以及GPU通过内存语义接口read/write直接访问CPU/Memory的能力,具有更高效、更直接的特点。但其同步操作的方式会对时延进行限制,制约可访问CPU/Memory的距离与容量。另外,目前的软件生态中,未有支持直接通过内存语义访问CPU/Memory的系统。
相反若使用异步的memory offload方式将降低对时延的约束,并发利用多节点CPU/Memory,发挥HB互联的带宽优势。另外,当前memory offload已具备一定软件生态上的基础,例如Zero offload5。
综上所述,超节点是一个以超大带宽(HB)互联16卡以上GPU-GPU以及GPU-CPU/Memory的scale up系统,以HBD超节点为单位,通过传统scale out扩展方式可形成更大规模、更高效的算力集群。超节点Scale Up的核心需求是超大带宽(HB),但规模不需要很大。Scale Out的核心需求是超大规模。因此Scale Up网络与Scale Out网络更适合是相互独立共存的两张网络。
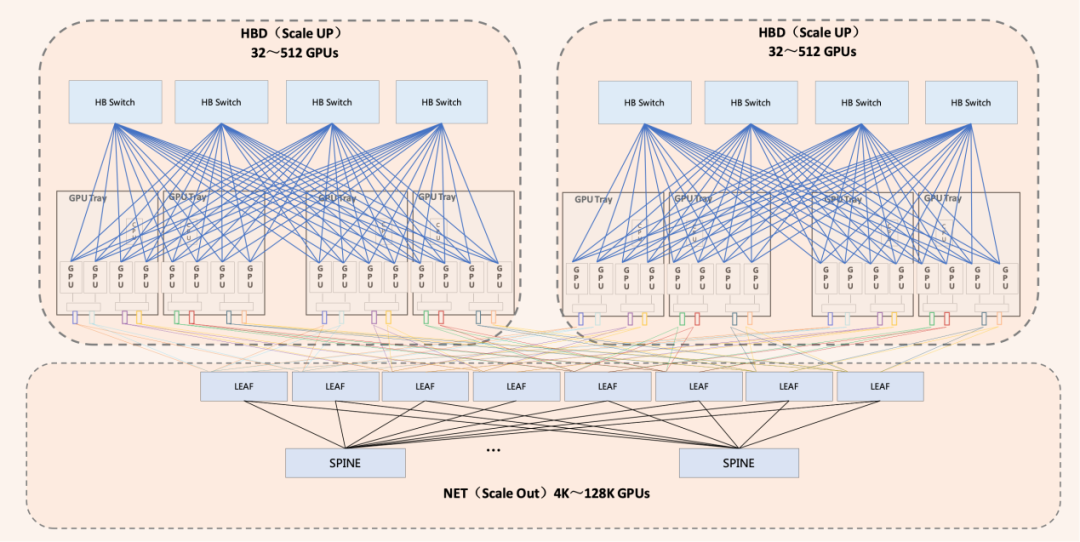
图4 Scale Up超大带宽与Scale Out超大规模共同构建高算力AI集群
ODCC ETH-X计划构建开放超节点产业生态
超节点的核心是HB互联技术,当前工业界已实现的超节点系统均是采用私有技术与协议实现HB互联,例如Nvidia的NVLINK。但此类私有技术与协议由单一企业进行维护,无法保证技术长期、高效的发展。另外,从HBD超节点产品完善角度也无法保证系统的开放,导致无法形成良性、开放的产业生态。
以太网技术凭借开放的生态、多样的产业链环境,为技术的长期演进发展提供支撑。当前以太网技术上从端口带宽及交换容量方面已具有较强的竞争基础。如以太网单端口800G MAC标准已成熟并产业化,以太网单芯片51.2T交换容量 ETH-switch也已在2023年产品化商用。
目前,以太网HB接口GPU产品的日益丰富,HBD超节点系统正逐步依托于以太网互联技术,实现向更为模块化、多元化的结构转型,有效促进了多方厂商的积极参与,各厂商专精于系统内的不同组件或子系统开发,显著提升了HBD超节点产品化的多样性和方案的丰富度,为HBD超节点技术长期演进奠定稳固基石,确保其在应对未来挑战时能够持续进化,保持领先的技术竞争力与生态活力。
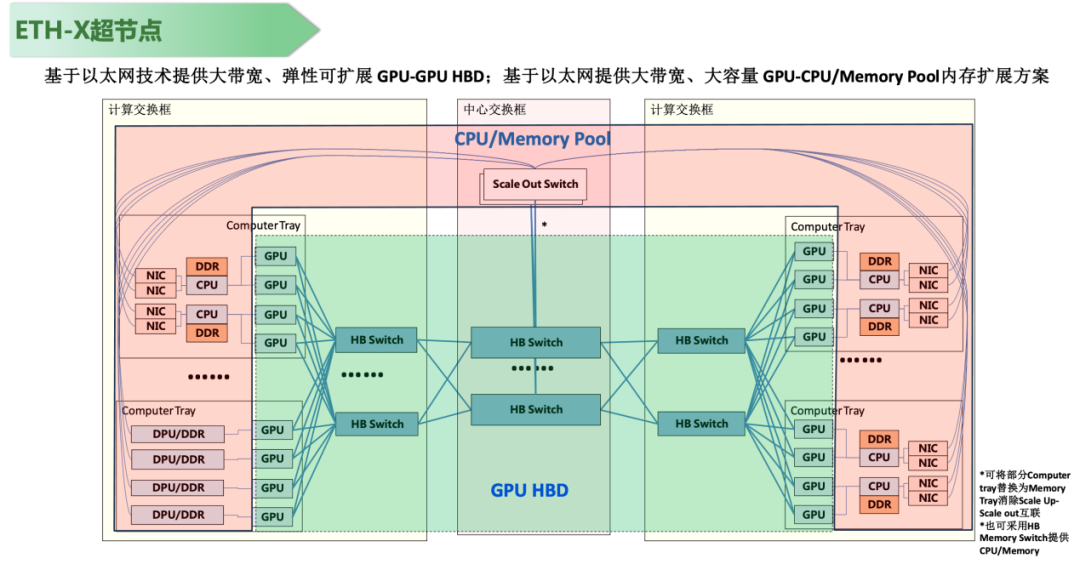
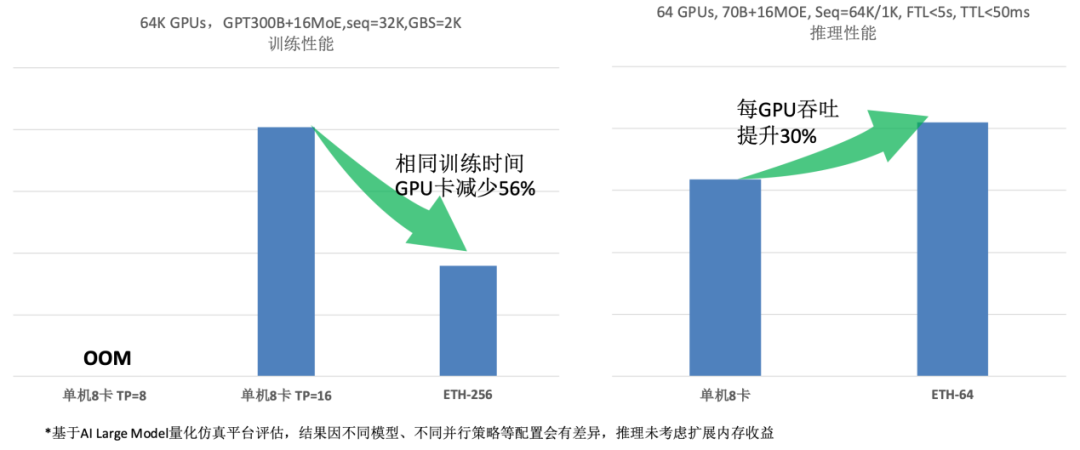
图5 ETH-X超节点参考架构与预期收益评估
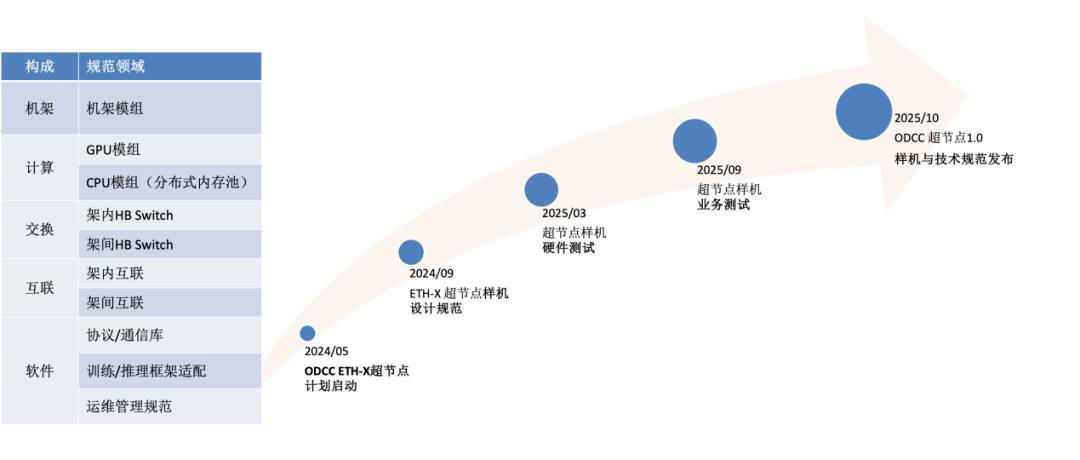
图6 ETH-X技术规范构成与项目计划
为推动算力产业的发展,ODCC网络组启动了ETH-X超节点系列项目。该项目由中国信通院、腾讯联合快手科技、燧原科技、壁仞科技、华勤技术、锐捷网络、新华三、云豹智能、云合智网、盛科通信、立讯精密、光迅科技等合作伙伴共同推动,以产品化样机以及相关技术规范为目标,打造大型多GPU互联算力集群系统。该项目计划在2025年秋季前完成ETH-X超节点样机软硬件研发与相关业务系统验证测试,同时发布ETH-X超节点技术规范1.0。
-
AI
+关注
关注
87文章
30098浏览量
268385 -
人工智能
+关注
关注
1791文章
46841浏览量
237523 -
算力
+关注
关注
1文章
925浏览量
14737
原文标题:ETH-X超节点:探索突破AI算力约束的新途径
文章出处:【微信号:SDNLAB,微信公众号:SDNLAB】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
本源“量超融合先进计算平台”入选2024算力中国·年度重大成果

浅析三大算力之异同

哈尔滨即将迎来算力新纪元:中国移动智算中心节点盛大启用
大模型时代的算力需求
光子计算芯片最新突破,峰值算力超1000tops,比电芯片更适合大模型

江苏省算力基础设施发展专项规划:打造算力供给服务新高地
千亿美元打造一个系统,成本越来越高的AI超算


立足算力,聚焦AI!顺网科技全面走进AI智算时代

AI算力应用中的光模块产品





 工商网监
工商网监
评论