 车载大模型分析揭示:存储带宽对性能影响远超算力
车载大模型分析揭示:存储带宽对性能影响远超算力
车载大模型的定义尚无,传统大模型即LLM的参数一般在70亿至2000亿之间,而早期的CNN模型参数通常不到1000万,CNN模型目前大多做骨干网使用,参数飞速增加。特斯拉使用META的RegNet,参数为8400万,消耗运算资源很少,得分82.9也算不低;小米UniOcc使用META的ConvNeXt-B,参数8900万,消耗运算资源最少,得分83.8;华为RadOcc使用微软的Swin-B,参数8800万。相对于早期的CNN模型,这些都可以叫大模型,但要与真正意义上的ChatGPT之类的LLM大模型比,这些是小模型都称不上,只能叫微模型。
不过,端到端的出现改变了这一现状,端到端实际上是内嵌了一个小型LLM,随着喂养数据的增加,这个大模型的参数会越来越大,最初阶段的模型大小大概是100亿参数,不断迭代,最终会达到1000亿以上。非安全类的大模型应用基本不用考虑计算问题,所以只要是个手机都敢说能跑数百亿的大模型,实际很多算力不如手机的电脑也能跑,因为延迟多几秒几十秒也没有问题,但自动驾驶必须将延迟降低到几十毫秒内。但你要以为这对算力要求更高了,那就大错特错了,存储带宽远比算力重要千倍。
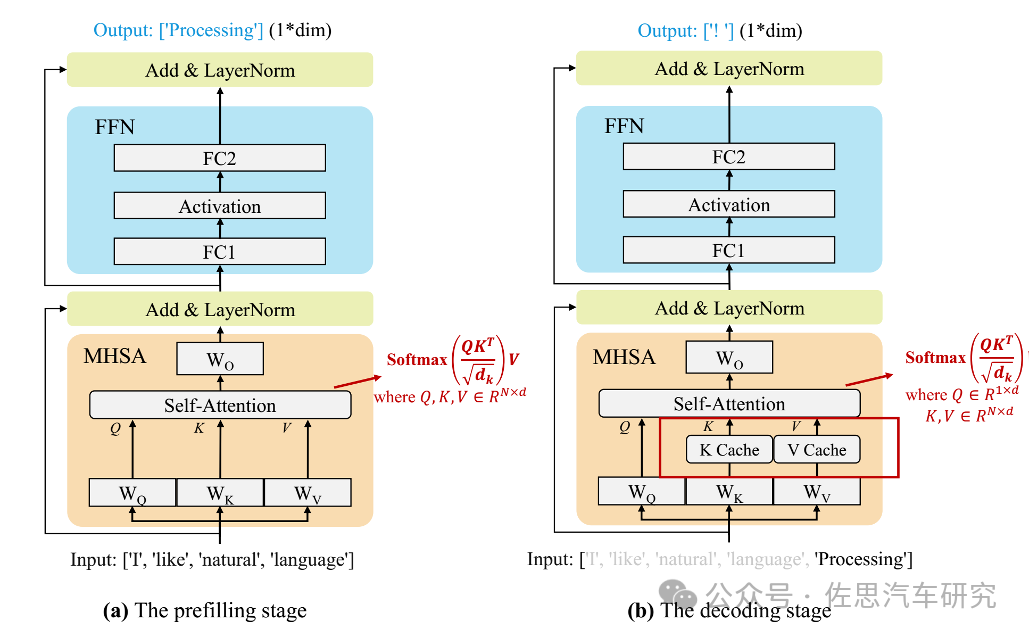
当前的主流 LLM 基本都是Decoder Only的Transformer模型,其推理过程可分为两个阶段:
图片来源:论文 A Survey on Efficient Inference for Large Language Models
Prefill:根据输入Tokens(Recite, the, first, law, of, robotics) 生成第一个输出 Token(A),通过一次Forward就可以完成,在Forward中,输入Tokens间可以并行执行(类似 Bert这些Encoder模型),因此执行效率很高。
Decoding:从生成第一个Token(A)之后开始,采用自回归方式一次生成一个Token,直到生成一个特殊的Stop Token(或者满足用户的某个条件,比如超过特定长度)才会结束,假设输出总共有N个Token,则Decoding阶段需要执行N-1次Forward,这N-1次Forward 只能串行执行,效率很低。另外,在生成过程中,需要关注的Token越来越多(每个Token 的生成都需要Attention之前的Token),计算量也会适当增大。
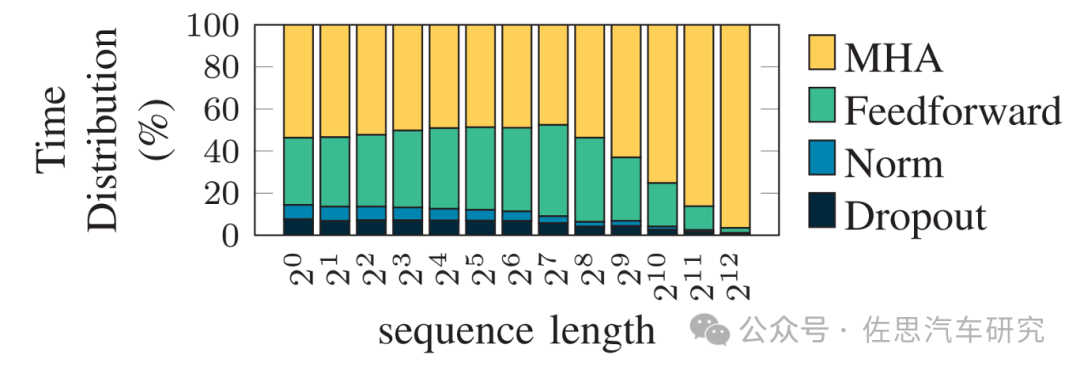
LLM推理计算过程时间分布
图片来源:论文Memory Is All You Need: An Overview of Compute-in-Memory Architectures for Accelerating Large Language Model Inference
在车载自动驾驶应用场合,序列长度基本可等同于摄像头的像素数量和激光雷达的点云密度。
图片来源:论文Memory Is All You Need: An Overview of Compute-in-Memory Architectures for Accelerating Large Language Model Inference
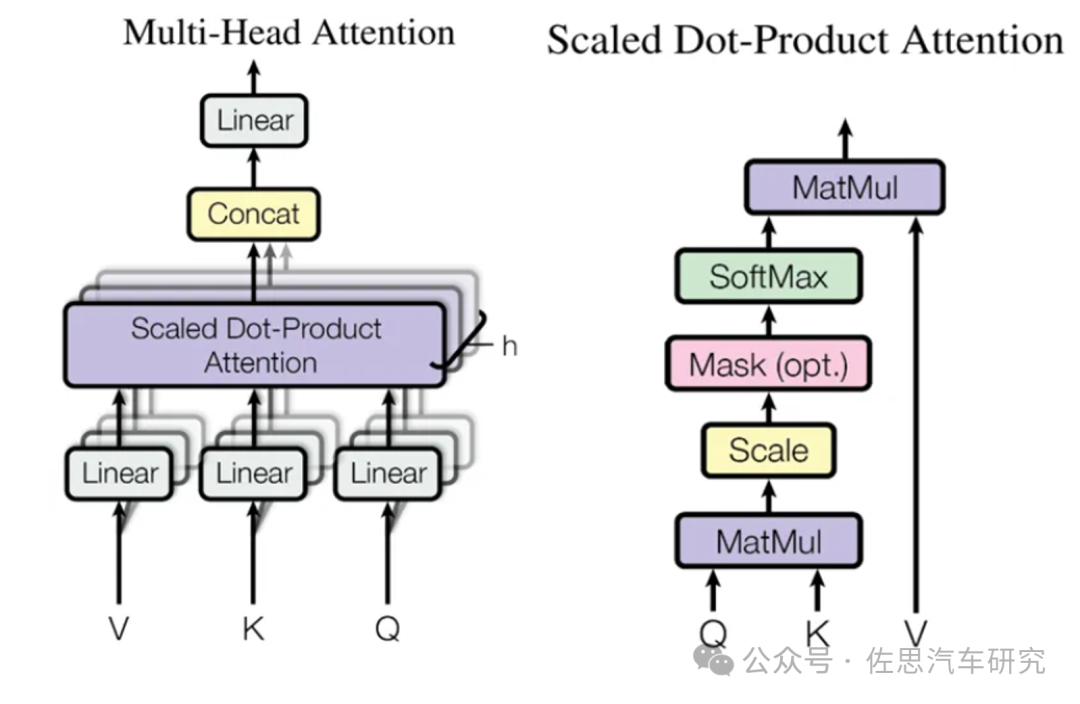
在 LLM 推理中最关键的就是上图中的Multi-Head Attention(MHA),其主要的计算集中在左图中灰色的 Linear(矩阵乘)和Scaled Dot-Product Attention中的MatMul 矩阵乘法。
图中的Mask是一个下三角矩阵,也是因为这个下三角矩阵实现了LLM Decoder的主要特性,每个Token都只能看到当前位置及之前的Token。其中的QKV可以理解为一个相关性矩阵,4个Token对应4 个Step,其中:
Step 2依赖Step 1的结果,相关性矩阵的第1行不用重复计算。
Step 3依赖Step 1和Step 2的结果,相关性矩阵的第1行和第2行不用重复计算。
Step 4依赖Step 1、Step 2和Step 3的结果,相关性矩阵的第1行、第2行和第3行不用重复计算。
在Decoding阶段Token是逐个生成的,上述的计算过程中每次都会依赖之前的结果,换句话说这是串行计算,而非GPU擅长的并行计算,GPU大部分时候都在等待数据搬运。加速的办法是计算当前Token时直接从KV Cache中读取而不是重新计算,对于通用LLM,应用场景是要考虑多个并发客户使用,即Batch Size远大于1,KV Cache的缓存量会随着Batch Size暴增,但在车里用户只有一个,就是自动驾驶端到端大模型,即Batch Size为1。
因为Decoding阶段Token逐个处理,使用KV Cache之后,上面介绍的Multi-Head Attention 里的矩阵乘矩阵操作全部降级为矩阵乘向量即GEMV。此外,Transformer模型中的另一个关键组件FFN 中主要也包含两个矩阵乘法操作,但 Token之间不会交叉融合,也就是任何一个Token都可以独立计算,因此在Decoding阶段不用Cache之前的结果,但同样会出现矩阵乘矩阵操作降级为矩阵乘向量。Prefill阶段则是GEMM,矩阵与矩阵的乘法。
矩阵乘向量操作是明显的访存bound,而以上操作是LLM推理中最主要的部分,这也就导致LLM推理是访存bound类型。
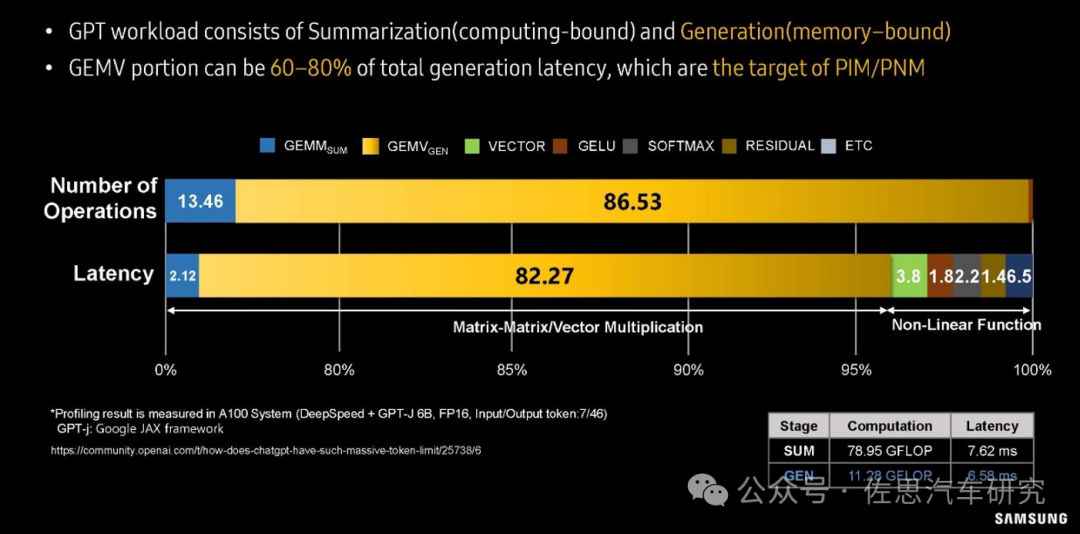
三星对GPT大模型workload分析
图片来源:SAMSUNG
上图是三星对GPT大模型workload分析。在运算操作数量上,GEMV所占的比例高达86.53%;在大模型运算延迟分析上,82.27%的延迟都来自GEMV,GEMM所占只有2.12%,非线性运算也就是神经元激活部分占的比例也远高于GEMM。
三星对GPU利用率的分析
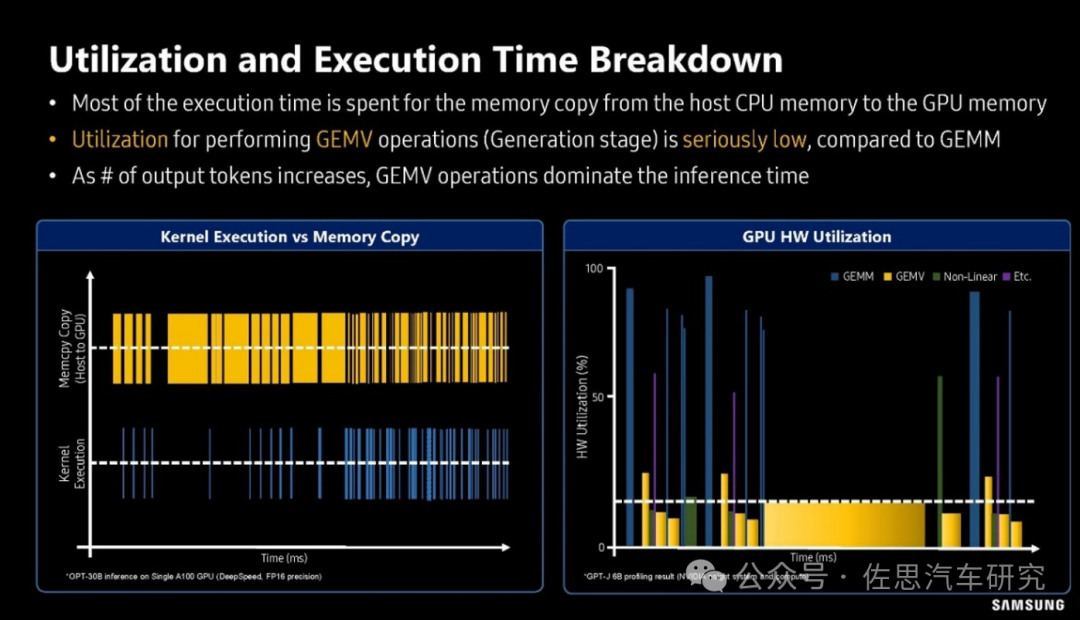
图片来源:SAMSUNG
上图是三星对GPU利用率的分析,可以看出在GEMV算子时,GPU的利用率很低,一般不超过20%,换句话说80%的时间GPU都是在等待存储数据的搬运。还有如矩阵反转,严格地说没有任何运算,只是存储行列对调,完全是存储器和CPU在忙活。解决办法很简单且只有一个,就是用HBM高宽带内存。
与传统LLM最大不同就是车载的Batch Size是1,导致GPU运算效率暴跌,传统LLM的Batch Size通常远大于1,这让GPU效率增加。
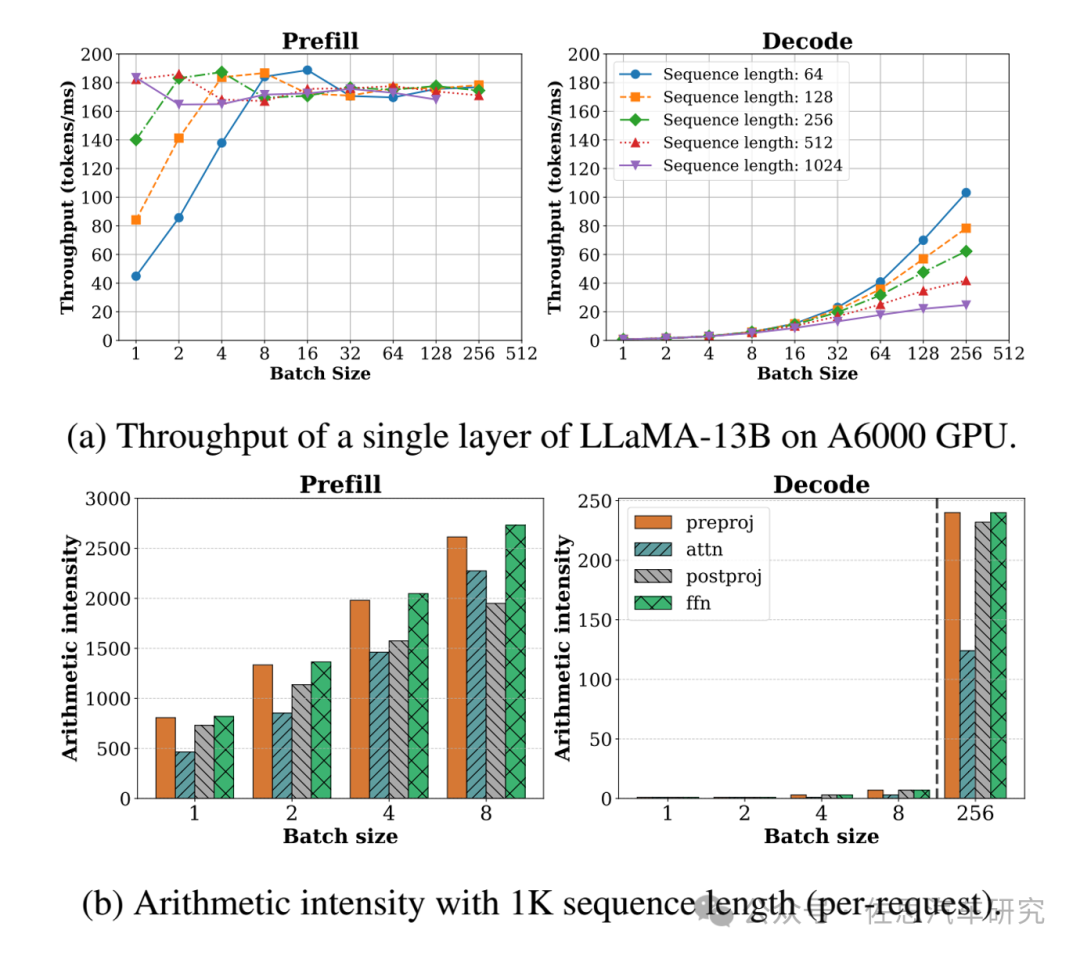
图片来源:论文SARATHI: Effcient LLM Inference by Piggybacking Decodes with Chunked Preflls
图上不难看出,Batch Size越大,推理速度反而越快,但KV Cache容量会暴增;车载的Batch Size是1,推理速度反而很慢,好处是根本不用考虑KV Cache的容量。
最终我们可以得出结论,存储带宽决定了推理计算速度的上限。假设一个大模型参数为70亿,按照车载的INT8精度,它所占的存储是7GB,如果是英伟达的RTX4090,它的显存带宽是1008GB/s,也就是每7毫秒生成一个token,这个就是RTX4090的理论速度上限。特斯拉第一代FSD芯片的存储带宽是63.5GB/s,即每110毫秒生成一个token,帧率不到10Hz,自动驾驶领域一般图像帧率是30Hz;英伟达的Orin存储带宽是204.5GB/s,即每34毫秒生成一个token,勉强可以达到30Hz,注意这只是计算的数据搬运所需要的时间,数据计算的时间都完全忽略了,实际速度要远低于这个数据。并且一个token也不够用,至少需要两个token,端到端的最终输出结果用语言描述就是一段轨迹,比如直行,直行需要有个限制条件,至少有个速度的限制条件,多的可能需要5个以上token,简单计算即可得出存储带宽需要1TB/s以上。
实际情况远比这个复杂的多。车载领域不是传统LLM使用CPU和GPU分离形式,车载领域的计算SoC都是将CPU和AI运算部分合二为一,AI运算部分通常是GPU或加速器是和CPU共享内存的。而在非车载领域,GPU或AI运算部分有独立的存储,即显存。车载领域共享内存一般是LPDDR,它主要是为CPU设计的,注重速度即频率而非带宽。不像显存,一般是GDDR或HBM,注重带宽,不看重频率高低。上述所有理论都是基于显存的,在车载领域共享LPDDR,其性能远远低于单独配置的显存,无论是速度还是容量,共享存储都必须远比单独的显存要高才能做到大模型推理计算。
理想用英伟达Orin做了测试,纯端到端模式延迟高达1.5秒。

图片来源:论文DRIVEVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
所以车载领域存储比算力重要很多,最好的解决办法是HBM,但太贵了,32GB HBM2最低成本也得2000美元,汽车领域对价格还是比较敏感的,退而求其次,就是GDDR了。GDDR6的成本远低于HBM,32GB GDDR6大概只要180美元或更低。
几代GDDR的性能对比
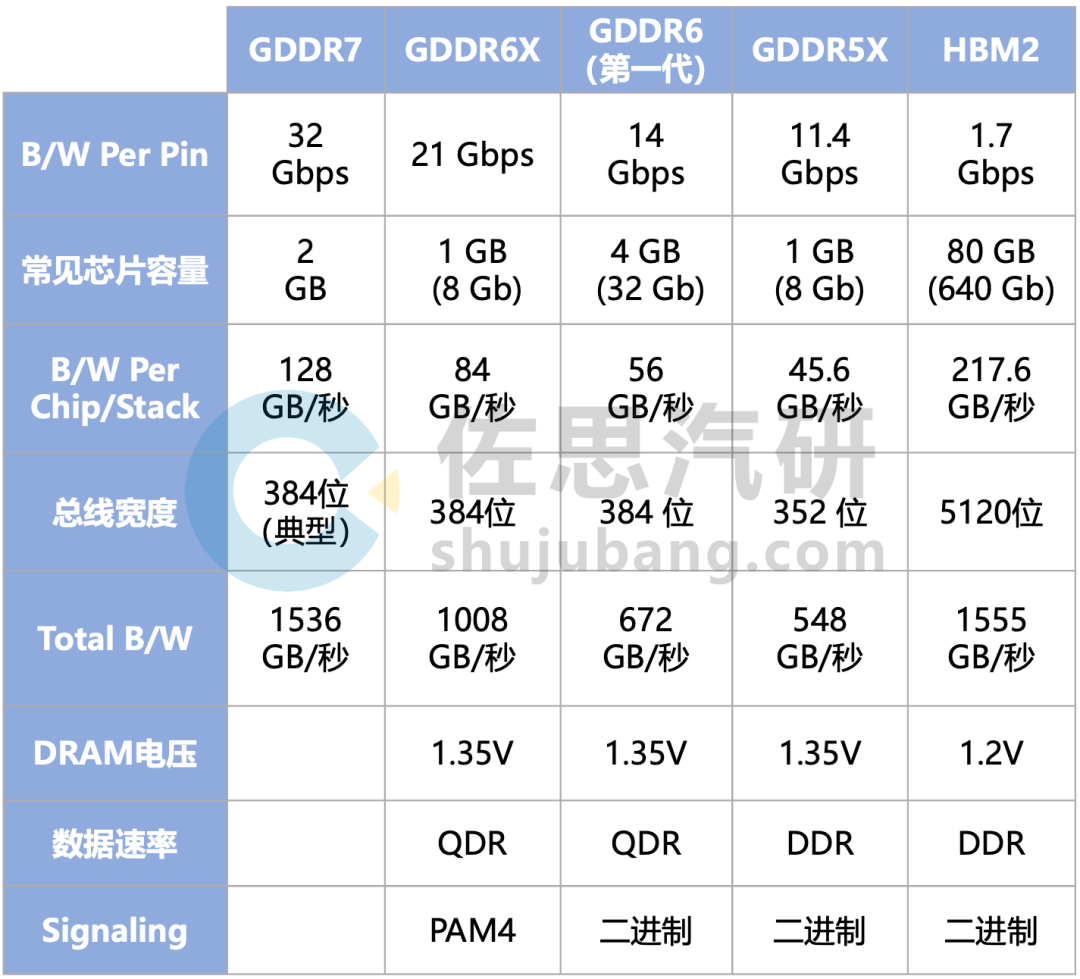
整理:佐思汽研
基本上GDDR6的理论上限就是672GB/s,特斯拉第二代FSD芯片就支持第一代GDDR6,HW4.0上的GDDR6容量为32GB,型号为MT61M512M32KPA-14,频率1750MHz(LPDDR5最低也是3200MHz之上),是第一代GDDR6,速度较低。即使用了GDDR6,要流畅运行百亿级别的大模型,还是无法实现,不过已经是目前最好的了。
GDDR7正式标准在2024年3月公布,不过三星在2023年7月就发布了全球首款GDDR7,目前SK Hynix和美光也都有GDRR7产品推出。有些人会说,换上GDDR7显存不就行了,当然没那么容易,GDDR需要特殊的物理层和控制器,芯片必须内置GDDR的物理层和控制器才能用上GDDR,Rambus和新思科技都有相关IP出售。
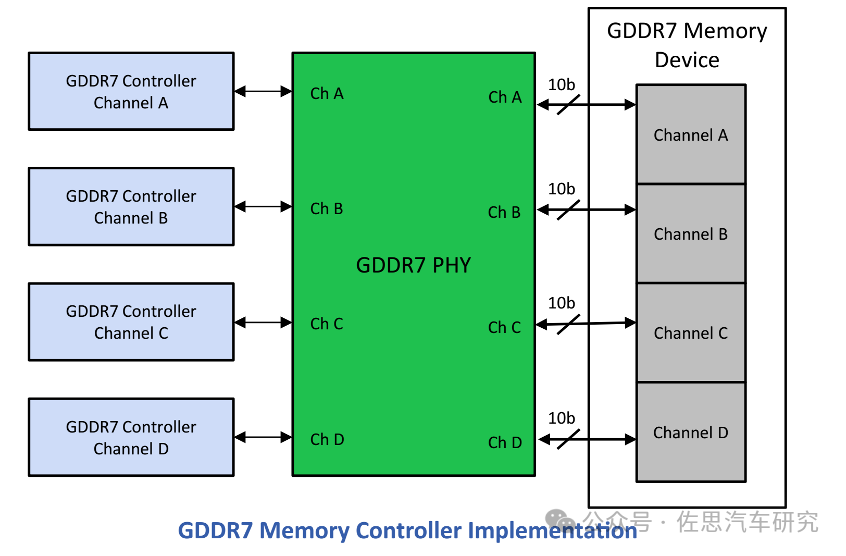
图片来源:网络
在芯片领域,GDDR7增加的成本和LPDDR5X一样的。
特斯拉的HW4.0过了一年半毫无动作,笔者认为特斯拉的第二代FSD芯片显然是落伍了,特斯拉也不打算大规模用了,特斯拉的第三代FSD芯片应该正在开发中,可能2025年底就完成开发,至少支持GDDR6X。
大模型时代,Attention Is All You Need,同样大模型时代 Memory Is All You Need。
-
存储
+关注
关注
13文章
4316浏览量
85866 -
带宽
+关注
关注
3文章
936浏览量
40938 -
LLM
+关注
关注
0文章
288浏览量
344
原文标题:车载大模型计算分析:存储带宽远比算力重要
文章出处:【微信号:zuosiqiche,微信公众号:佐思汽车研究】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】--了解算力芯片CPU
【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】--全书概览
名单公布!【书籍评测活动NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架构分析
名单公布!【书籍评测活动NO.41】大模型时代的基础架构:大模型算力中心建设指南
IaaS+on+DPU(IoD)+下一代高性能算力底座技术白皮书
中国算力中心市场持续增长,智能算力规模快速崛起
算力系列基础篇——算力与计算机性能:解锁超能力的神秘力量!

2024多样性算力产业峰会:江波龙解码AI存储方案的未来之路


液冷是大模型对算力需求的必然选择?|英伟达 GTC 2024六大亮点

【算能RADXA微服务器试用体验】Radxa Fogwise 1684X Mini 规格
智能算力规模超通用算力,大模型对智能算力提出高要求






 工商网监
工商网监
评论