 如何设定机器人语义地图的细粒度级别
如何设定机器人语义地图的细粒度级别
0. 这篇文章干了啥?
机器人学中的一个基本问题是创建机器人观察到的场景的有用地图表示,其中有用性由机器人利用地图完成感兴趣的任务的能力来衡量。最近的研究,包括构建语义度量三维地图,通过检测对象和区域与封闭的语义标签集对应的工作。然而,封闭集检测在能够表示的概念集方面存在固有的限制,并且不能很好地处理自然语言的内在歧义性和可变性。为了克服这些限制,一组新的方法开始利用视觉语言基础模型进行开放集语义理解。这些方法使用一个无类别分割网络(SegmentAnything或SAM)生成图像的细粒度段,然后应用一个基础模型得到描述每个段的开放集语义的嵌入向量。然后通过将段关联起来构造对象,只要它们的嵌入向量在预定义的相似度阈值内。然而,这些方法把调整适当的阈值的困难任务留给了用户,以控制从场景中提取的段的数量,以及用于决定是否必须将两个段聚类在一起的阈值。更重要的是,这些方法没有捕捉到地图中语义概念的选择不仅仅受语义相似性驱动,而且是内在于任务的。例如,考虑一个被指派移动钢琴的机器人。机器人通过区分所有键和弦的位置几乎不会增加价值,但可以通过将钢琴视为一个大对象来完成任务。另一方面,被指派演奏钢琴的机器人必须将钢琴视为许多对象(即键)。被指派调音钢琴的机器人必须将钢琴视为更多的对象------考虑到弦、调音销等。同样,像一堆衣服应该表示为一个单独的堆还是单独的衣服,或者一片森林应该表示为一个单独的地貌区域还是树枝、叶子、树干等,直到我们明确了表示必须支持的任务,这些问题仍然没有得到解决。人类不仅在决定要表示哪些对象以及如何表示时考虑任务(有意识或无意识),而且还能相应地忽略与任务无关的场景部分。
下面一起来阅读一下这项工作~
1. 论文信息
标题:Clio: Real-time Task-Driven Open-Set 3D Scene Graphs
作者:Dominic Maggio, Yun Chang, Nathan Hughes, Matthew Trang, Dan Griffith, Carlyn Dougherty, Eric Cristofalo, Lukas Schmid, Luca Carlone
机构:MIT
原文链接:https://arxiv.org/abs/2404.13696
代码链接:https://github.com/MIT-SPARK/Clio
2. 摘要
现代无关类别图像分割工具(例如SegmentAnything)和开放集语义理解(例如CLIP)为机器人感知和地图绘制提供了前所未有的机会。虽然传统的封闭集度量语义地图仅限于几十个或几百个语义类别,但现在我们可以建立包含大量对象和无数语义变体的地图。这给我们留下了一个基本问题:机器人必须在其地图表示中包含什么样的对象(更一般地说,包含什么样的语义概念)才是正确的粒度?虽然相关工作通过调整对象检测的阈值来隐式选择粒度级别,但我们认为这样的选择本质上取决于任务。本文的第一个贡献是提出了一个任务驱动的3D场景理解问题,其中机器人被给定了一系列用自然语言描述的任务,必须选择足以完成任务的粒度和对象子集以及场景结构并将其保留在其地图中。我们表明,可以使用信息瓶颈(IB)这一已建立的信息论框架来自然地构建这个问题。第二个贡献是一种基于聚合式信息瓶颈方法的任务驱动的3D场景理解算法,能够将环境中的3D基元聚类成与任务相关的对象和区域,并逐步执行。第三个贡献是将我们的任务驱动聚类算法集成到一个名为Clio的实时流水线中,该流水线仅使用板载计算,随着机器人探索环境,在线构建环境的分层3D场景图。我们的最终贡献是进行了大量实验,表明Clio不仅可以实时构建紧凑的开放集3D场景图,而且通过将地图限制在相关的语义概念上,还提高了任务执行的准确性。
3. 效果展示
我们提出了Clio,一种新颖的方法,用于在嵌入的开放集语义的情况下实时构建任务驱动的3D场景图。我们从经典的信息瓶颈原理汲取灵感,根据一组自然语言任务------例如"阅读棕色教科书"------形成与任务相关的对象基元的聚类,并通过将场景聚类为与任务相关的语义区域,如"小厨房"或"工作区"来进行聚类。
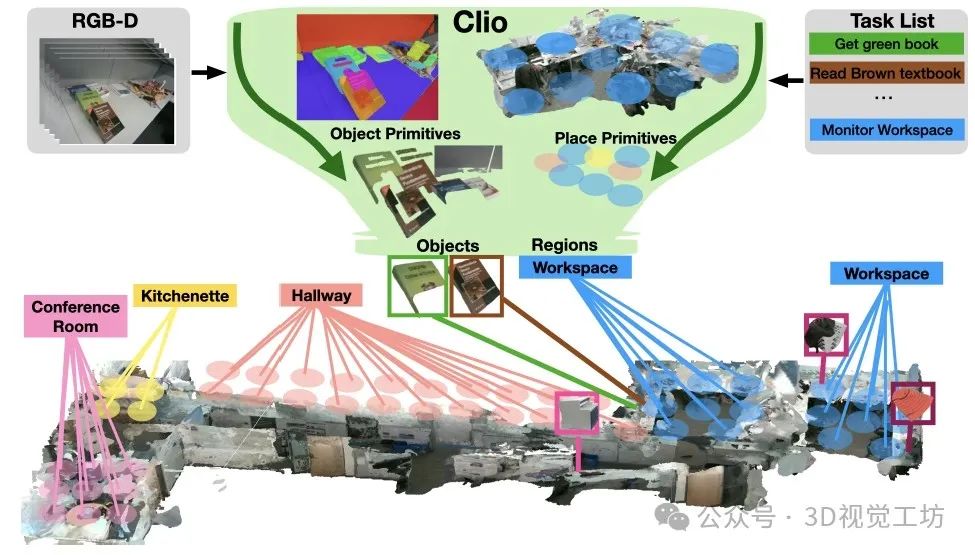
Clio使用Spot携带的笔记本电脑实时生成3D场景图。我们展示了Spot能够使用Clio的任务驱动3D场景图执行用自然语言表达的抓取命令。

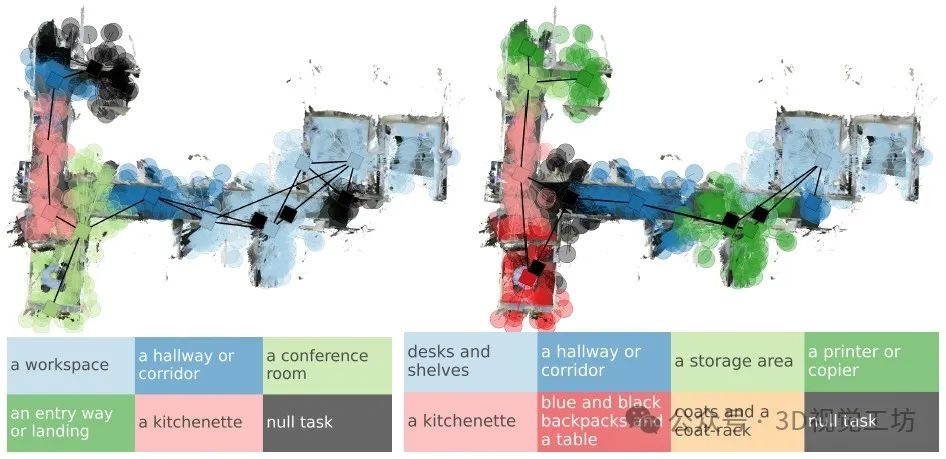
对地点聚类的定性示例。第一张图显示了通过类似房间类别标签的任务提示进行聚类而产生的区域。第二张图显示了通过任务提示进行聚类而产生的区域,这些任务提示是潜在房间和物体的混合。
4. 主要贡献
我们的第一个贡献是阐述任务驱动的三维场景理解问题,其中机器人被给定一组在自然语言中指定的任务,并且需要构建一个足以完成给定任务的最小地图表示。更具体地说,我们假设机器人能够感知环境中的任务无关基元,以一组三维对象段和三维无障碍区域的形式,并且必须将它们聚类成一个仅包含相关对象和区域(例如,房间)的任务相关压缩表示。这个问题可以自然地使用经典的信息瓶颈(IB)理论进行公式化,该理论还提供了用于任务驱动聚类的算法方法。
我们的第二个贡献是将来自任务驱动三维场景理解问题的凝聚IB算法应用到问题中。具体而言,我们展示了如何使用CLIP嵌入获取算法中所需的概率密度,并且表明由此产生的算法可以随着机器人探索环境而逐步执行,其计算复杂度不随环境大小增加。
我们的第三个贡献是将提出的任务驱动聚类算法纳入一个实时系统中,称为Clio。Clio在操作开始时接收一组在自然语言中指定的任务列表:例如,这些可以是机器人在其生命周期内或当前部署期间被设想执行的任务。然后,随着机器人的操作,Clio实时创建一个层次地图,即环境的三维场景图,其中表示仅保留相关对象和区域的任务。与当前用于开放集三维场景图构建的方法相反,这些方法仅限于离线操作,当查询大型视觉语言模型(VLMs)和大型语言模型(LLMs)时,并且Clio在实时和板载上运行,仅依赖于轻量级基础模型,例如CLIP。我们在Replica数据集和四个真实环境中演示了Clio------一个公寓,一个办公室,一个隔间和一个大型建筑场景。我们还展示了在一台波士顿动力Spot四足机器人上使用Clio进行实时板载地图制作。Clio不仅允许实时开放集三维场景图构建,而且通过限制地图仅包含相关对象和区域来提高任务执行的准确性。我们在https://github.com/MIT-SPARK/Clio上开源了Clio,并附带了我们的自定义数据集。
5. 基本原理是啥?
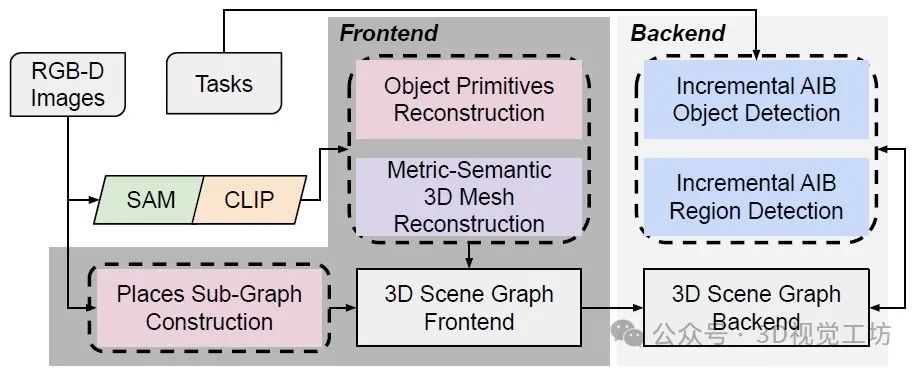
Clio的前端接收RGB-D传感器数据,并构建物体基元的图形,地点图形以及背景的度量-语义3D网格。Clio的后端执行增量聚合IB以根据用户指定的任务列表对对象和区域进行聚类。
Cubicle数据集中需要任务提供对象定义纠正的部分示例。图中展示了两组任务的Clio聚类结果,分别列在(b)和(c)下;在聚类期间,任务列表中包含了14个额外的相同任务,但为了清晰起见未显示出来。

6. 实验结果
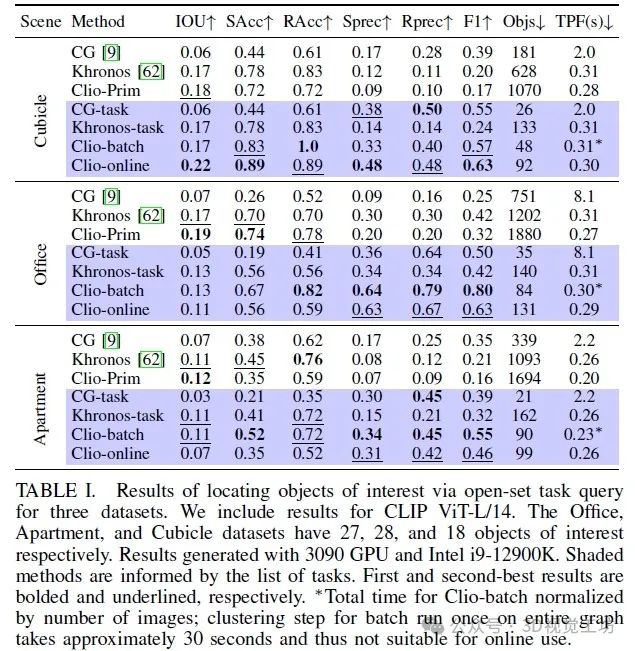
首先,我们观察到任务驱动的方法(表I中蓝色填充的行)通常会在保留较少对象的同时获得更好的性能指标("Objs"列);这验证了我们的论断,即度量-语义映射需要以任务为驱动。具体来说,在某些情况下,与不考虑任务的基线相比,Clio 保留的对象数量要少一个数量级(与没有信息瓶颈任务驱动聚类的 Clio-Prim 中的对象数量相比)。其次,我们观察到 Clio 在各个数据集上的表现大多优于基线,在除了 Office 数据集的 IOU 和 SAcc 指标之外的所有情况下,Clio-batch 和 Clio-online 排名都位居前两位。Office 数据集中的许多对象(例如订书机、自行车头盔)通常被检测为孤立的基元,因此我们看到任务的知识对这个数据集的影响较小,但仍然能够改善所有其他指标的性能。第三,我们观察到 Clio 能够在几分之一秒内运行,比 ConceptGraphs 快约 6 倍;Khronos 和 Clio-Prim 也是实时运行的,但在其他指标方面性能不佳。最后,Clio-batch 和 Clio-online 在大多数情况下表现相似。它们性能上的差异是因为 Clio-online 是实时执行的,可能根据需要丢弃帧以跟上相机图像流。这种差异有时有助于性能指标,有时则会妨碍性能指标的提升。
虽然 Clio 是为开放集检测而设计的,但我们使用的评估方法在闭集 Replica 数据集上展示了我们的任务感知映射公式不会降低闭集映射任务的性能。在这里,我们的任务列表是每个 Replica 场景中存在的对象标签集,其中每个标签都被更改为"{类别}的图像"。对于 Clio,在创建场景图后,我们将每个检测到的对象分配给与其余对象具有最高余弦相似度的标签。为了提高 CLIP 在 Replica 数据集的低纹理区域的可靠性,我们通过将稠密 CLIP 特征合并到 Clio 中,包含了全局上下文的 CLIP 向量。我们报告准确率作为类平均召回(mAcc)和频率加权的平均交并比(f-mIOU)。表II 显示,Clio 达到了与领先的零样本方法相当的性能,表明我们的任务感知聚类不会降低闭集任务的性能。
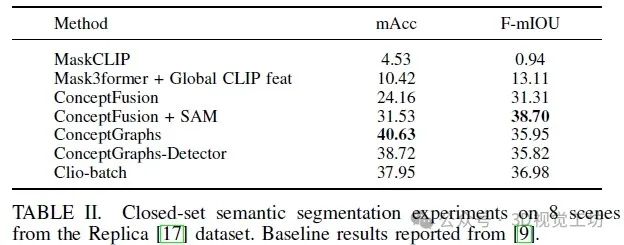
由于手动标记语义 3D 区域是一个高度主观的任务,我们通过一个代理闭集任务评估了 Clio 区域的性能,其中 Clio 获得了场景的可能房间标签集作为任务。我们在三个数据集中标记了房间:Office、Apartment 和 Building。我们不分析 Cubicle 或 Replica 数据集,因为它们只包含单个房间。我们将 α 设为 0,以禁用对空任务的分配,因为每个地点都与至少一个房间标签相关联,并且我们在所有场景中保持所有参数不变。
我们使用精度和召回率指标来比较我们提出的 CLIP 嵌入向量关联策略,Clio(平均),以及另一种更为朴素的策略,Clio(最近),后者使用从仍然可以从其中看到地点节点的最近图像中获取的嵌入向量。此外,我们使用 Hydra的纯几何房间分割方法作为闭集性能的比较点。这次比较的结果显示在表III 中,该表还包括 F1 分数作为摘要统计量。表III 中的结果是在 5 次试验中平均的,并报告了所有指标的标准偏差。我们注意到,我们选择的关联策略在 Office 和 Building 场景中优于 Hydra的纯几何方法和更为朴素的 Clio(最近),但在 Apartment 方面的 F1 分数方面表现相对较差。这是由于场景的性质;Office 和 Building 场景包含带标签的开放平面房间,需要语义知识来检测(例如 Office 场景中的小厨房或 Building 场景中的楼梯间)。Apartment 主要包含几何上不同的房间,这些房间可以用[7]中的几何方法进行直接分割,而 Clio 则会过度分割,这可以从我们的方法的高精度但低召回中看出。另一方面,与 Office 中存在的连接的语义相似区域相比,导致了欠分割和较低的召回率。
7. 限制性
尽管实验结果令人鼓舞,但我们的方法存在多个限制。首先,尽管我们的方法是zero-shot,并且不受任何特定基础模型的限制,但在实施过程中确实继承了一些基础模型的限制,比如对提示调整的强烈敏感。例如,我们讨论了不同CLIP模型对性能的影响。其次,我们目前在合并两个基元时平均了CLIP向量,但考虑更具体的方法来结合它们的语义描述可能会更有趣。第三,如果两个基元分别对同一任务具有相似的余弦相似度,但任务某种方式上需要将它们区分为单独的对象时,Clio可能会过度聚类(例如,我们可能希望在摆放餐具时将叉子与刀子区分开来,尽管它们可能对任务有相似的相关性)。最后,我们目前考虑的是相对简单的单步任务。然而,将所提出的框架扩展到与一组高级复杂任务一起工作将是可取的。
8. 总结
我们提出了一种面向任务的三维度量语义映射的形式化方法,其中机器人被提供了一系列自然语言任务,并且必须创建一个足以支持这些任务的地图,其粒度和结构是足够的。我们已经表明,这个问题可以用经典的信息瓶颈来表达,并且已经开发了聚合信息瓶颈算法的增量版本作为解决策略。我们已将所得算法集成到实时系统Clio中,该系统在机器人探索环境时构建一个三维场景图,包括任务相关的对象和区域。我们还通过展示它可以在Spot机器人上实时执行并支持拾取和放置移动操作任务,证明了Clio对机器人学的相关性。
-
传感器
+关注
关注
2554文章
51593浏览量
757870 -
机器人
+关注
关注
211文章
28817浏览量
209218
原文标题:MIT最新开源!Clio:如何确定机器人语义地图的细粒度?
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
伺服电动缸在人形机器人中的应用
使用 Thonny 对 XRP 机器人进行编程

【「具身智能机器人系统」阅读体验】2.具身智能机器人的基础模块
《具身智能机器人系统》第10-13章阅读心得之具身智能机器人计算挑战
【「具身智能机器人系统」阅读体验】2.具身智能机器人大模型
《人形机器人产业地图(2024)》重磅发布!

机器人没有度量信息如何导航
Perforce Helix Core通过ISO 26262认证!为汽车软件开发团队提供无限可扩展性、细粒度安全性、文件快速访问等

机器人语言系统包括三个基本状态
图像语义分割的实用性是什么
Al大模型机器人
微信大模型扩容并开源,推出首个中英双语文生图模型,参数规模达15亿
一微半导体“基于地图轮廓的区域分界线搜索方法”专利公布





 工商网监
工商网监
评论