 缓存之美——如何选择合适的本地缓存?
缓存之美——如何选择合适的本地缓存?
作者:京东保险 郭盼
1、简介
小编最近在使用系统的时候,发现尽管应用已经使用了redis缓存提高查询效率,但是仍然有进一步优化的空间,于是想到了比分布式缓存性能更好的本地缓存,因此对领域内常用的本地缓存进行了一番调研,有早期的Guava缓存、在Guava上进一步传承的Caffine以及自称在Java中使用最广泛的EhCache,那么我们该怎么选择适合自己应用的缓存呢,小编下面会简单介绍,并将以上缓存进行一个对比,希望帮助大家选择最适合自己系统的本地缓存。
2、Guava缓存简介
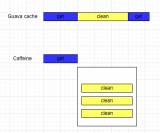
Guava cache是Google开发的Guava工具包中一套完善的JVM本地缓存框架,底层实现的数据结构类似于ConcurrentHashMap,但是进行了更多的能力拓展,包括缓存过期时间设置、缓存容量设置、多种淘汰策略、缓存监控等,下面简单介绍下这些功能及其使用方式。
2.1、缓存过期时间设置
Guava的过期时间设置有基于创建时间和最后一次访问时间两种策略.
(1) 基于创建时间
通过对比缓存记录的插入时间来判断,比如设置过期时间为5分钟,不管中间有没有访问,到时过期。
public Cache< String, String > createCache() { return CacheBuilder.newBuilder() .expireAfterWrite(5L, TimeUnit.MINUTES) .build(); }
(2) 基于过期时间
通过对比最近最后一次的访问时间,比如设置5分钟,每次访问之后都会刷新过期时间为5分钟,只有持续5分钟没有被访问到才会过期。
public Cache< String, String > createCache() {
return CacheBuilder.newBuilder()
.expireAfterAccess(5L, TimeUnit.MINUTES)
.build();
}
2.2、缓存容量和淘汰策略设置
Guava cache是内存型缓存,有内存溢出风险,因此需要设置缓存的最大存储上限,通过缓存的条数或每条缓存的权重来判断是否达到了设定阈值,当缓存的数据量达到设定阈值之后,Guava cache支持使用FIFO和LRU的策略对缓存记录采取淘汰的措施。
(1)限制缓存记录条数
public Cache< String, User > createCache() {
return CacheBuilder.newBuilder()
.maximumSize(100L)
.build();
}
(2)限制缓存记录权重
public Cache< String, User > createCache() {
return CacheBuilder.newBuilder()
.maximumWeight(100L)
.weigher((key, value) -> (int) Math.ceil(instrumentation.getObjectSize(value) / 1024L))
.build();
}
使用限制缓存记录权重时要先计算weight的value对象的字节数,每1kb字节作为一个权重,对比限制缓存记录,我们就能将缓存的总占用限制在100kb左右。
2.3缓存监控
缓存记录的加载和命中情况是评价缓存处理能力的重要指标,Guava cache提供了stat统计日志对这两个指标进行了统计,我们只需要在创建缓存容器的时候加上recordStats就可以开启统计。
public Cache< String, User > createCache() {
return CacheBuilder.newBuilder()
.recordStats()
.build();
}
2.4 Guava cache的优劣势和适用场景
优劣势:Guava cache通过内存处理数据,具有减少IO请求,读写性能快的优势,但是受内存容量限制,只能处理少量数据的读写,还有可能对本机内存造成压力,并且在分布式部署中,会存在不同机器节点数据不一致的情况,即缓存漂移。
适用场景:读多写少,对数据一致性要求不高的场景。
3、Caffeine简介
Caffeine同样是Google开发的,是在Guava cache的基础上改良而来的,底层设计思路、功能和使用方式与Guava非常类似,但是各方面的性能都要远远超过前者,可以看做是Guava cache的升级版,因此,之前使用过Guava cache,也能够很快的上手Caffeine,下面是Caffeine和Guava cache的缓存创建对比,基本可以无门槛过渡。
public Cache< String, String > createCache() {
return Caffeine.newBuilder()
.initialCapacity(1000)
.maximumSize(100L)
.expireAfterWrite(5L, TimeUnit.MINUTES)
.recordStats()
.build();
}
public Cache< String, String > createCache() {
return CacheBuilder.newBuilder()
.initialCapacity(1000)
.maximumSize(100L)
.expireAfterWrite(5L, TimeUnit.MINUTES)
.recordStats()
.build();
}
那么Caffeine底层又做了哪些优化,才能让其性能高于Guava cache呢?主要包含以下三点:
3.1、对比Guava cache的性能主要优化项
(1)异步策略
Guava cache在读操作中可能会触发淘汰数据的清理操作,虽然自身也做了一些优化来减少读的时候的清理操作,但是一旦触发,就会降低查询效率,对缓存性能产生影响。而在Caffeine支持异步操作,采用异步处理的策略,查询请求在触发淘汰数据的清理操作后,会将清理数据的任务添加到独立的线程池中进行异步操作,不会阻塞查询请求,提高了查询性能。
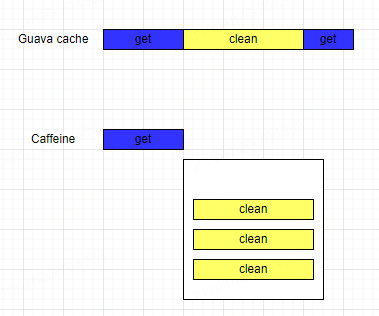
(2)ConcurrentHashMap优化
Caffeine底层都是通过ConcurrentHashMap来进行数据的存储,因此随着Java8中对ConcurrentHashMap的调整,数组+链表的结构升级为数组+链表+红黑树的结构以及分段锁升级为syschronized+CAS,降低了锁的粒度,减少了锁的竞争,这两个优化显著提高了Caffeine在读多写少场景下的查询性能。
(3)新型淘汰算法W-TinyLFU
传统的淘汰算法,如LRU、LFU、FIFO,在实际的缓存场景中都存在一些弊端,如FIFO算法,如果缓存使用的频率较高,那么缓存数据会一直处在进进出出的状态,间接影响到缓存命中率。LRU算法,在批量刷新缓存数据的场景下,可能会将其他缓存数据淘汰掉,从而带来缓存击穿的风险。LFU算法,需要保存缓存记录的访问次数,带来内存空间的损耗。
因此,Caffeine引入了W-TinyLFU算法,由窗口缓存、过滤器、主缓存组成。缓存数据刚进入时会停留在窗口缓存中,这个部分只占总缓存的1%,当被挤出窗口缓存时,会在过滤器汇总和主缓存中淘汰的数据进行比较,如果频率更高,则进入主缓存,否则就被淘汰,主缓存被分为淘汰段和保护段,两段都是LRU算法,第一次被访问的元素会进入淘汰段,第二次被访问会进入保护段,保护段中被淘汰的元素会进入淘汰段,这种算法实现了高命中率和低内存占用。更详细的解释可以参考论文:https://arxiv.org/pdf/1512.00727.pdf
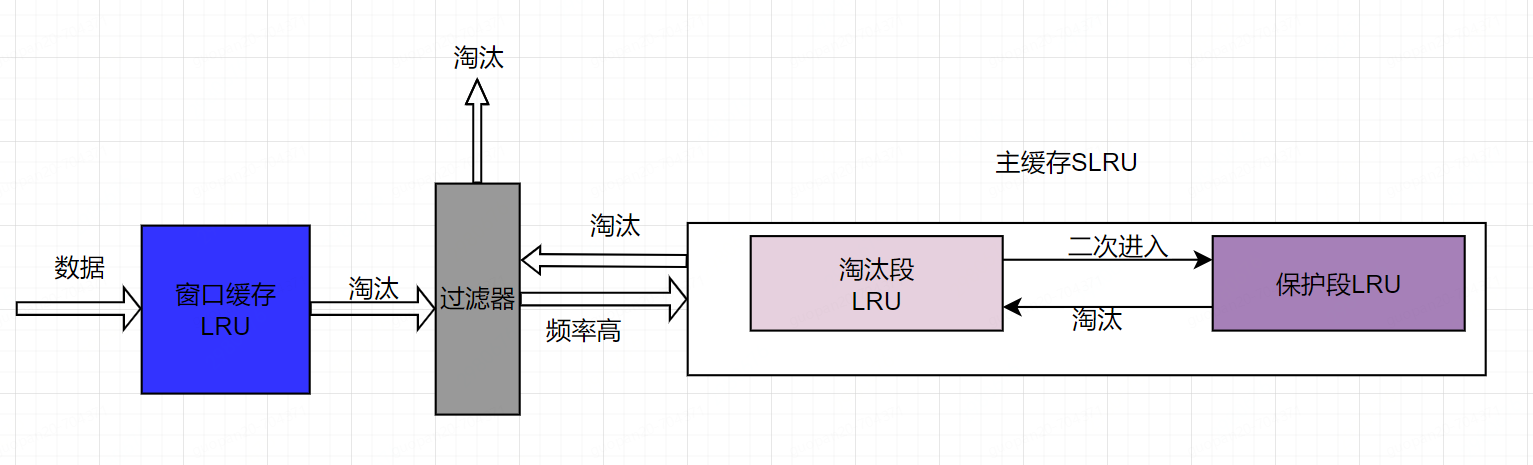
3.2、Caffeine的优劣势和适用场景
优势:对比Guava cache有更高的缓存性能,劣势:仍然存在缓存漂移的问题;JDK版本过低无法使用
适用场景:1、适用场景:读多写少,对数据一致性要求不高的场景;2、纯内存缓存,JDK8及更高版本中,追求比Guava cache更高的性能。
4、Ehcache简介
Guava cache和Caffeine都是JVM缓存,会受到内存大小的制约,最新的Ehcache采用堆内缓存+堆外缓存+磁盘的方式,打破了这一制约。堆内缓存就是被JVM管理的那一部分缓存,而堆外缓存,就是在内存中另外在开辟一块不被JVM管理的部分。堆外缓存这部分既可以享受内存的高速读写能力,而且又避免的JVM频繁的GC,缺点是需要自行清理数据。
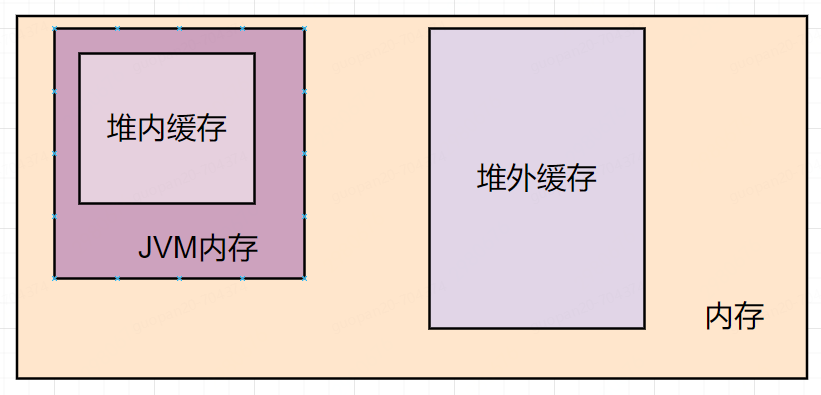
下面是Ehcache缓存的创建,指定了堆内、堆外缓存和磁盘缓存的大小。
ResourcePoolsBuilder.newResourcePoolsBuilder()
.heap(20, MemoryUnit.MB)
.offheap(10, MemoryUnit.MB)
.disk(5, MemoryUnit.GB);
为了解决缓存漂移的问题,Ehcache支持通过集群的方式,实现了分布式节点之间的数据互通。关于Ehcache的集群策略,后续文章再详细阐述。
5、不同本地缓存对比
| 框架 | 命中率 | 速度 | 回收算法 | 使用难度 | 集群 | 适用场景 |
|---|---|---|---|---|---|---|
| Guava cache | 中 | 第三 | LRU、LFU、FIFO | 易 | 不支持 | 读多写少,允许少量缓存偏移 |
| Caffeine | 高 | 第一 | W-TinyLFU | 易 | 不支持 | 读多写少,允许少量缓存偏移,能用Caffeine就别用Guava cache |
| Ehcache | 中 | 第二 | LRU、LFU、FIFO | 中 | 支持 | 分布式系统中对数据一致性要求高 |
-
JAVA
+关注
关注
19文章
2978浏览量
105341 -
缓存
+关注
关注
1文章
242浏览量
26787 -
Redis
+关注
关注
0文章
379浏览量
10987
发布评论请先 登录
相关推荐
高并发系统中的缓存 缓存系统存在的三大问题
本地缓存的技术实践
如何选择合适的本地缓存?
Mybatis缓存之一级缓存
什么是Web缓存,HTTP缓存和浏览器缓存的区别

ThingJS平台推出3D场景本地缓存技术
聊聊本地缓存和分布式缓存
如何在 Linux 上查看本地 DNS 缓存

Ehcache!这才是Java本地缓存之王!






 工商网监
工商网监
评论