 基于hadoop的数据仓库介绍
基于hadoop的数据仓库介绍
一、Hadoop介绍
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(HadoopDistributedFileSystem),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(highthroughput)来访问应用程序的数据,适合那些有着超大数据集(largedataset)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streamingaccess)文件系统中的数据。
Hadoop的核心架构
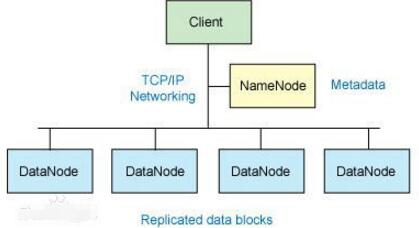
HDFS
对外部客户机而言,HDFS就像一个传统的分级文件系统。可以创建、删除、移动或重命名文件,等等。但是HDFS的架构是基于一组特定的节点构建的(参见图1),这是由它自身的特点决定的。这些节点包括NameNode(仅一个),它在HDFS内部提供元数据服务;DataNode,它为HDFS提供存储块。由于仅存在一个NameNode,因此这是HDFS的一个缺点(单点失败)。
存储在HDFS中的文件被分成块,然后将这些块复制到多个计算机中(DataNode)。这与传统的RAID架构大不相同。块的大小(通常为64MB)和复制的块数量在创建文件时由客户机决定。NameNode可以控制所有文件操作。HDFS内部的所有通信都基于标准的TCP/IP协议。
NameNode
NameNode是一个通常在HDFS实例中的单独机器上运行的软件。它负责管理文件系统名称空间和控制外部客户机的访问。NameNode决定是否将文件映射到DataNode上的复制块上。对于最常见的3个复制块,第一个复制块存储在同一机架的不同节点上,最后一个复制块存储在不同机架的某个节点上。注意,这里需要您了解集群架构。
二、hive介绍
Hive是部署在hadoop集群上的数据仓库工具。
数据库和数据仓库的区别:
数据库(如常用关系型数据库)可以支持实时增删改查。
数据仓库不仅仅是为了存放数据,它可以存放海量数据,而且可以查询、分析和计算存储在Hadoop中的大规模数据。但他有一个弱点,他不能进行实时的更新、删除等操作。也就是一次写入多次读取。
Hive也定义了简单的类SQL查询语言,称为QL,它允许熟悉SQL的用户查询数据。现在hive2.0也支持更新、索引和事务,几乎SQL的其它特征都能支持。
Hive支持SQL92大部分功能,我们暂时可以把hive理解成一个关系型数据库,语法和MySQL是几乎是一样的。
Hive是Hadoop上的数据仓库基础构架之一,是SQL解析引擎,它可以将SQL转换成MapReduce任务,然后在Hadoop执行。
实际的I/O事务并没有经过NameNode,只有表示DataNode和块的文件映射的元数据经过NameNode。当外部客户机发送请求要求创建文件时,NameNode会以块标识和该块的第一个副本的DataNodeIP地址作为响应。这个NameNode还会通知其他将要接收该块的副本的DataNode。
NameNode在一个称为FsImage的文件中存储所有关于文件系统名称空间的信息。这个文件和一个包含所有事务的记录文件(这里是EditLog)将存储在NameNode的本地文件系统上。FsImage和EditLog文件也需要复制副本,以防文件损坏或NameNode系统丢失。
NameNode本身不可避免地具有SPOF(SinglePointOfFailure)单点失效的风险,主备模式并不能解决这个问题,通过HadoopNon-stopnamenode才能实现100%uptime可用时间。
DataNode
DataNode也是一个通常在HDFS实例中的单独机器上运行的软件。Hadoop集群包含一个NameNode和大量DataNode。DataNode通常以机架的形式组织,机架通过一个交换机将所有系统连接起来。Hadoop的一个假设是:机架内部节点之间的传输速度快于机架间节点的传输速度。
DataNode响应来自HDFS客户机的读写请求。它们还响应来自NameNode的创建、删除和复制块的命令。NameNode依赖来自每个DataNode的定期心跳(heartbeat)消息。每条消息都包含一个块报告,NameNode可以根据这个报告验证块映射和其他文件系统元数据。如果DataNode不能发送心跳消息,NameNode将采取修复措施,重新复制在该节点上丢失的块。
文件操作
可见,HDFS并不是一个万能的文件系统。它的主要目的是支持以流的形式访问写入的大型文件。
如果客户机想将文件写到HDFS上,首先需要将该文件缓存到本地的临时存储。如果缓存的数据大于所需的HDFS块大小,创建文件的请求将发送给NameNode。NameNode将以DataNode标识和目标块响应客户机。
同时也通知将要保存文件块副本的DataNode。当客户机开始将临时文件发送给第一个DataNode时,将立即通过管道方式将块内容转发给副本DataNode。客户机也负责创建保存在相同HDFS名称空间中的校验和(checksum)文件。
在最后的文件块发送之后,NameNode将文件创建提交到它的持久化元数据存储(在EditLog和FsImage文件)。
Linux集群
Hadoop框架可在单一的Linux平台上使用(开发和调试时),官方提供MiniCluster作为单元测试使用,不过使用存放在机架上的商业服务器才能发挥它的力量。这些机架组成一个Hadoop集群。它通过集群拓扑知识决定如何在整个集群中分配作业和文件。Hadoop假定节点可能失败,因此采用本机方法处理单个计算机甚至所有机架的失败。
Hive的系统架构
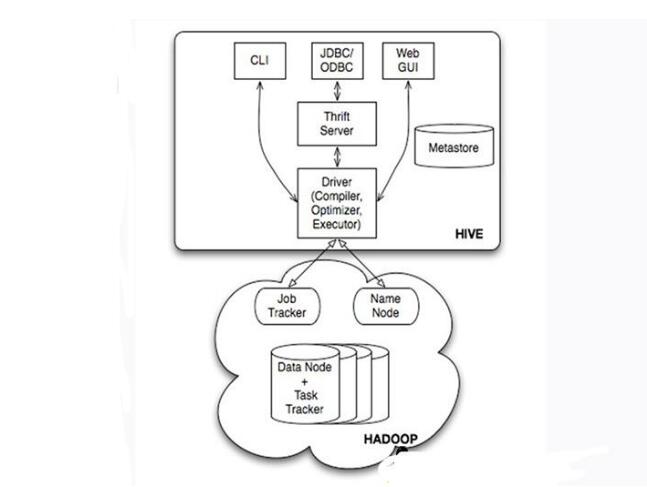
•用户接口,包括CLI(Shell命令行),JDBC/ODBC,WebUI
•MetaStore元数据库,通常是存储在关系数据库如mysql,derby中
•Driver包含解释器、编译器、优化器、执行器
•Hadoop:用HDFS进行存储,利用MapReduce进行计算
Hive的表和数据库,对应的其实是HDFS(Hadoop分布式文件系统)的目录/文件,按表名把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在MapReduceJob里使用这些数据。
三、Hive与Hadoop生态系统中其他组件的关系
1、Hive依赖于HDFS存储数据,依赖MR处理数据;
2、Pig可作为Hive的替代工具,是一种数据流语言和运行环境,适合用于在Hadoop平台上查询半结构化数据集,用于与ETL过程的一部分,即将外部数据装载到Hadoop集群中,转换为用户需要的数据格式;
3、HBase是一个面向列的、分布式可伸缩的数据库,可提供数据的实时访问功能,而Hive只能处理静态数据,主要是BI报表数据,Hive的初衷是为减少复杂MR应用程序的编写工作,HBase则是为了实现对数据的实时访问。
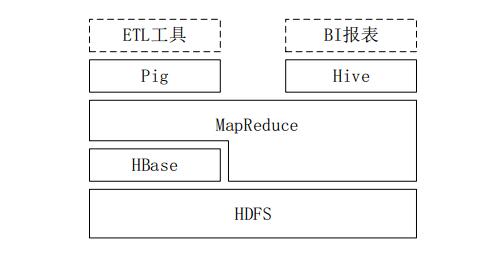
Hive与传统数据库的对比
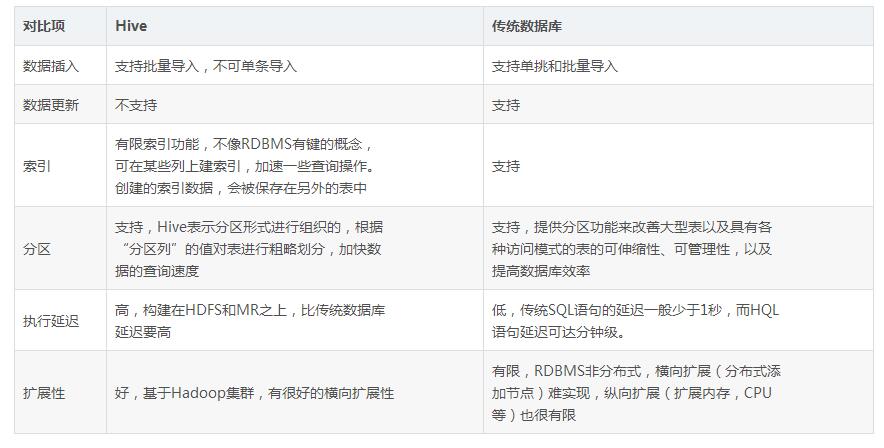
四、Hive的部署和应用
Hive在企业大数据分析平台中的应用
当前企业中部署的大数据分析平台,除Hadoop的基本组件HDFS和MR外,还结合使用Hive、Pig、HBase、Mahout,从而满足不同业务场景需求。
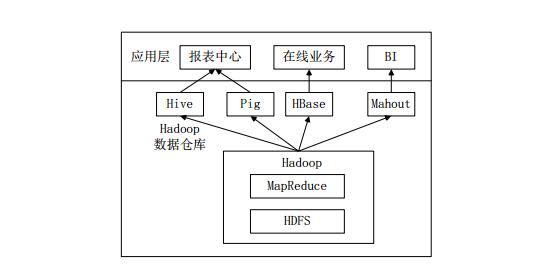
图企业中一种常见的大数据分析平台部署框架
上图是企业中一种常见的大数据分析平台部署框架,在这种部署架构中:
Hive和Pig用于报表中心,Hive用于分析报表,Pig用于报表中数据的转换工作。
HBase用于在线业务,HDFS不支持随机读写操作,而HBase正是为此开发,可较好地支持实时访问数据。
Mahout提供一些可扩展的机器学习领域的经典算法实现,用于创建商务智能(BI)应用程序。
五、Hive工作原理
1、SQL语句转换成MapReduce作业的基本原理
1.1用MapReduce实现连接操作
假设连接(join)的两个表分别是用户表User(uid,name)和订单表Order(uid,orderid),具体的SQL命令:
SELECTname,orderidFROMUseruJOINOrderoONu.uid=o.uid;
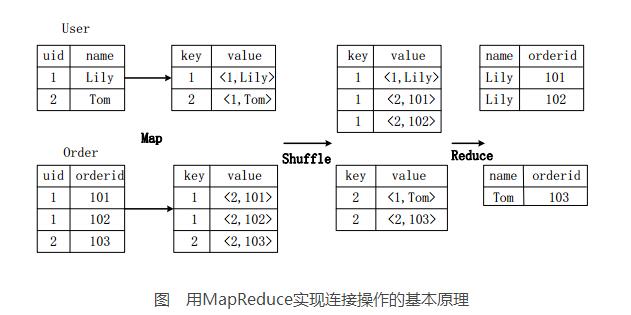
上图描述了连接操作转换为MapReduce操作任务的具体执行过程。
首先,在Map阶段,
User表以uid为key,以name和表的标记位(这里User的标记位记为1)为value,进行Map操作,把表中记录转换生成一系列KV对的形式。比如,User表中记录(1,Lily)转换为键值对(1,《1,Lily》),其中第一个“1”是uid的值,第二个“1”是表User的标记位,用来标示这个键值对来自User表;
同样,Order表以uid为key,以orderid和表的标记位(这里表Order的标记位记为2)为值进行Map操作,把表中的记录转换生成一系列KV对的形式;
接着,在Shuffle阶段,把User表和Order表生成的KV对按键值进行Hash,然后传送给对应的Reduce机器执行。比如KV对(1,《1,Lily》)、(1,《2,101》)、(1,《2,102》)传送到同一台Reduce机器上。当Reduce机器接收到这些KV对时,还需按表的标记位对这些键值对进行排序,以优化连接操作;
最后,在Reduce阶段,对同一台Reduce机器上的键值对,根据“值”(value)中的表标记位,对来自表User和Order的数据进行笛卡尔积连接操作,以生成最终的结果。比如键值对(1,《1,Lily》)与键值对(1,《2,101》)、(1,《2,102》)的连接结果是(Lily,101)、(Lily,102)。
1.2用MR实现分组操作
假设分数表Score(rank,level),具有rank(排名)和level(级别)两个属性,需要进行一个分组(GroupBy)操作,功能是把表Score的不同片段按照rank和level的组合值进行合并,并计算不同的组合值有几条记录。SQL语句命令如下:
SELECT rank,level,count(*) as value FROM score GROUP BY rank,level;
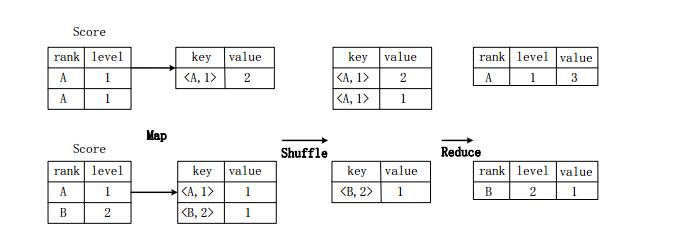
图用MapReduce实现分组操作的实现原理
上图描述分组操作转化为MapReduce任务的具体执行过程。
首先,在Map阶段,对表Score进行Map操作,生成一系列KV对,其键为《rank,level》,值为“拥有该《rank,level》组合值的记录的条数”。比如,Score表的第一片段中有两条记录(A,1),所以进行Map操作后,转化为键值对(《A,1》,2);
接着在Shuffle阶段,对Score表生成的键值对,按照“键”的值进行Hash,然后根据Hash结果传送给对应的Reduce机器去执行。比如,键值对(《A,1》,2)、(《A,1》,1)传送到同一台Reduce机器上,键值对(《B,2》,1)传送另一Reduce机器上。然后,Reduce机器对接收到的这些键值对,按“键”的值进行排序;
在Reduce阶段,把具有相同键的所有键值对的“值”进行累加,生成分组的最终结果。比如,在同一台Reduce机器上的键值对(《A,1》,2)和(《A,1》,1)Reduce操作后的输出结果为(A,1,3)。
2、Hive中SQL查询转换成MR作业的过程
当Hive接收到一条HQL语句后,需要与Hadoop交互工作来完成该操作。HQL首先进入驱动模块,由驱动模块中的编译器解析编译,并由优化器对该操作进行优化计算,然后交给执行器去执行。执行器通常启动一个或多个MR任务,有时也不启动(如SELECT*FROMtb1,全表扫描,不存在投影和选择操作)
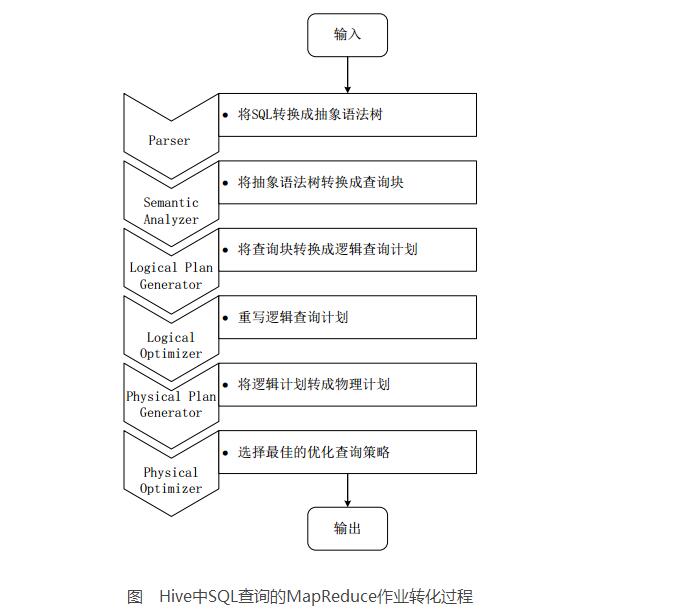
上图是Hive把HQL语句转化成MR任务进行执行的详细过程。
由驱动模块中的编译器–Antlr语言识别工具,对用户输入的SQL语句进行词法和语法解析,将HQL语句转换成抽象语法树(ASTTree)的形式;
遍历抽象语法树,转化成QueryBlock查询单元。因为AST结构复杂,不方便直接翻译成MR算法程序。其中QueryBlock是一条最基本的SQL语法组成单元,包括输入源、计算过程、和输入三个部分;
遍历QueryBlock,生成OperatorTree(操作树),OperatorTree由很多逻辑操作符组成,如TableScanOperator、SelectOperator、FilterOperator、JoinOperator、GroupByOperator和ReduceSinkOperator等。这些逻辑操作符可在Map、Reduce阶段完成某一特定操作;
Hive驱动模块中的逻辑优化器对OperatorTree进行优化,变换OperatorTree的形式,合并多余的操作符,减少MR任务数、以及Shuffle阶段的数据量;
遍历优化后的OperatorTree,根据OperatorTree中的逻辑操作符生成需要执行的MR任务;
启动Hive驱动模块中的物理优化器,对生成的MR任务进行优化,生成最终的MR任务执行计划;
最后,有Hive驱动模块中的执行器,对最终的MR任务执行输出。
Hive驱动模块中的执行器执行最终的MR任务时,Hive本身不会生成MR算法程序。它通过一个表示“Job执行计划”的XML文件,来驱动内置的、原生的Mapper和Reducer模块。Hive通过和JobTracker通信来初始化MR任务,而不需直接部署在JobTracker所在管理节点上执行。通常在大型集群中,会有专门的网关机来部署Hive工具,这些网关机的作用主要是远程操作和管理节点上的JobTracker通信来执行任务。Hive要处理的数据文件常存储在HDFS上,HDFS由名称节点(NameNode)来管理。
JobTracker/TaskTracker
NameNode/DataNode
六、HiveHA基本原理
在实际应用中,Hive也暴露出不稳定的问题,在极少数情况下,会出现端口不响应或进程丢失问题。HiveHA(HighAvailablity)可以解决这类问题。
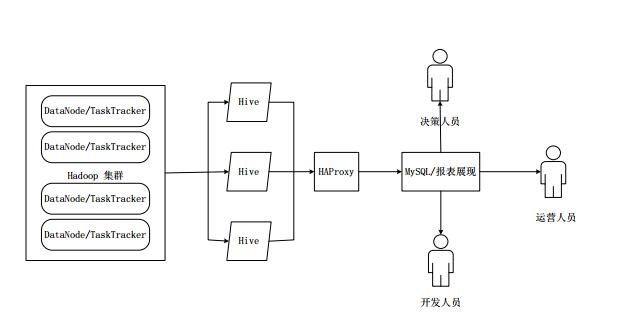
在HiveHA中,在Hadoop集群上构建的数据仓库是由多个Hive实例进行管理的,这些Hive实例被纳入到一个资源池中,由HAProxy提供统一的对外接口。客户端的查询请求,首先访问HAProxy,由HAProxy对访问请求进行转发。HAProxy收到请求后,会轮询资源池中可用的Hive实例,执行逻辑可用性测试。
如果某个Hive实例逻辑可用,就会把客户端的访问请求转发到Hive实例上;
如果某个实例不可用,就把它放入黑名单,并继续从资源池中取出下一个Hive实例进行逻辑可用性测试。
对于黑名单中的Hive,HiveHA会每隔一段时间进行统一处理,首先尝试重启该Hive实例,如果重启成功,就再次把它放入资源池中。
由于HAProxy提供统一的对外访问接口,因此,对于程序开发人员来说,可把它看成一台超强“Hive”。
七、Impala
1、Impala简介
Impala由Cloudera公司开发,提供SQL语义,可查询存储在Hadoop和HBase上的PB级海量数据。Hive也提供SQL语义,但底层执行任务仍借助于MR,实时性不好,查询延迟较高。
Impala作为新一代开源大数据分析引擎,最初参照Dremel(由Google开发的交互式数据分析系统),支持实时计算,提供与Hive类似的功能,在性能上高出Hive3~30倍。Impala可能会超过Hive的使用率能成为Hadoop上最流行的实时计算平台。Impala采用与商用并行关系数据库类似的分布式查询引擎,可直接从HDFS、HBase中用SQL语句查询数据,不需把SQL语句转换成MR任务,降低延迟,可很好地满足实时查询需求。
Impala不能替换Hive,可提供一个统一的平台用于实时查询。Impala的运行依赖于Hive的元数据(Metastore)。Impala和Hive采用相同的SQL语法、ODBC驱动程序和用户接口,可统一部署Hive和Impala等分析工具,同时支持批处理和实时查询。
2、Impala系统架构
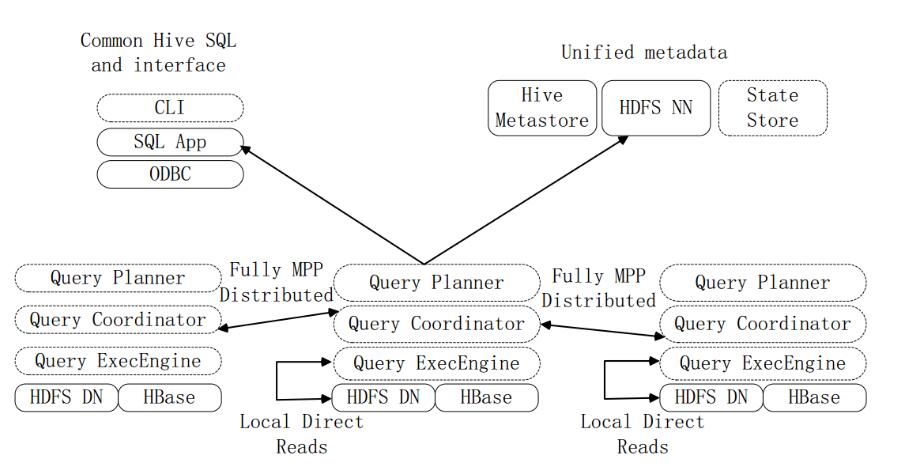
图Impala系统架构
上图是Impala系统结构图,虚线模块数据Impala组件。Impala和Hive、HDFS、HBase统一部署在Hadoop平台上。Impala由Impalad、StateStore和CLI三部分组成。
Implalad:是Impala的一个进程,负责协调客户端提供的查询执行,给其他Impalad分配任务,以及收集其他Impalad的执行结果进行汇总。Impalad也会执行其他Impalad给其分配的任务,主要是对本地HDFS和HBase里的部分数据进行操作。Impalad进程主要含QueryPlanner、QueryCoordinator和QueryExecEngine三个模块,与HDFS的数据节点(HDFSDataNode)运行在同一节点上,且完全分布运行在MPP(大规模并行处理系统)架构上。
StateStore:收集分布在集群上各个Impalad进程的资源信息,用于查询的调度,它会创建一个statestored进程,来跟踪集群中的Impalad的健康状态及位置信息。statestored进程通过创建多个线程来处理Impalad的注册订阅以及与多个Impalad保持心跳连接,此外,各Impalad都会缓存一份StateStore中的信息。当StateStore离线后,Impalad一旦发现StateStore处于离线状态时,就会进入恢复模式,并进行返回注册。当StateStore重新加入集群后,自动恢复正常,更新缓存数据。
CLI:CLI给用户提供了执行查询的命令行工具。Impala还提供了Hue、JDBC及ODBC使用接口。
3、Impala查询执行过程
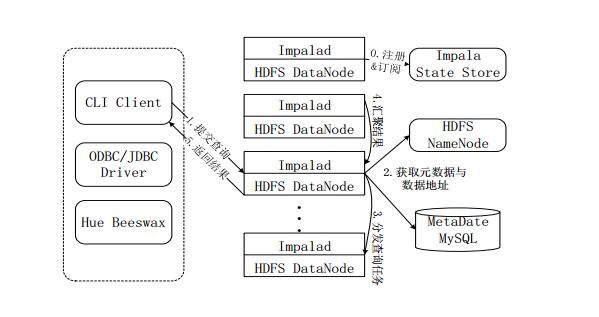
图Impala查询执行过程
注册和订阅。当用户提交查询前,Impala先创建一个Impalad进程来负责协调客户端提交的查询,该进程会向StateStore提交注册订阅信息,StateStore会创建一个statestored进程,statestored进程通过创建多个线程来处理Impalad的注册订阅信息。
提交查询。通过CLI提交一个查询到Impalad进程,Impalad的QueryPlanner对SQL语句解析,生成解析树;Planner将解析树变成若干PlanFragment,发送到QueryCoordinator。其中PlanFragment由PlanNode组成,能被分发到单独的节点上执行,每个PlanNode表示一个关系操作和对其执行优化需要的信息。
获取元数据与数据地址。QueryCoordinator从MySQL元数据库中获取元数据(即查询需要用到哪些数据),从HDFS的名称节点中获取数据地址(即数据被保存到哪个数据节点上),从而得到存储这个查询相关数据的所有数据节点。
分发查询任务。QueryCoordinator初始化相应的Impalad上的任务,即把查询任务分配给所有存储这个查询相关数据的数据节点。
汇聚结果。QueryExecutor通过流式交换中间输出,并由QueryCoordinator汇聚来自各个Impalad的结果。
返回结果。QueryCoordinator把汇总后的结果返回给CLI客户端。
4、Impala与Hive
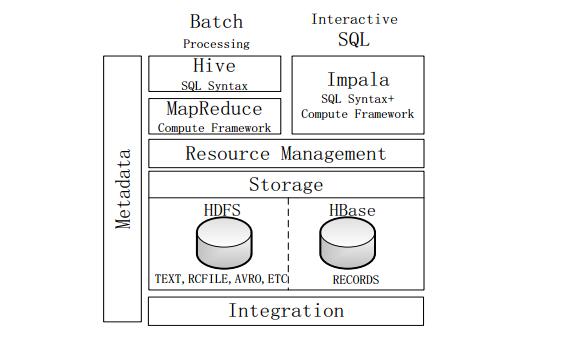
图Impala与Hive的对比
不同点:
Hive适合长时间批处理查询分析;而Impala适合进行交互式SQL查询。
Hive依赖于MR计算框架,执行计划组合成管道型MR任务模型进行执行;而Impala则把执行计划表现为一棵完整的执行计划树,可更自然地分发执行计划到各个Impalad执行查询。
Hive在执行过程中,若内存放不下所有数据,则会使用外存,以保证查询能够顺利执行完成;而Impala在遇到内存放不下数据时,不会利用外存,所以Impala处理查询时会受到一定的限制。
相同点:
使用相同的存储数据池,都支持把数据存储在HDFS和HBase中,其中HDFS支持存储TEXT、RCFILE、PARQUET、AVRO、ETC等格式的数据,HBase存储表中记录。
使用相同的元数据。
对SQL的解析处理比较类似,都是通过词法分析生成执行计划。
-
数据仓库
+关注
关注
0文章
61浏览量
10448 -
Hadoop
+关注
关注
1文章
90浏览量
15989 -
hive
+关注
关注
0文章
12浏览量
3850
发布评论请先 登录
相关推荐
什么是数据仓库?数据仓库的优势分析

多版本数据仓库模型设计
统计行业数据仓库构建及应用
OLAP在电信数据仓库中的设计
保护MySQL数据仓库的最佳实践
数据仓库是什么_数据仓库的特点_数据仓库与数据库区别
数据仓库是什么_数据仓库有什么特点_数据库和数据仓库区别分析





 工商网监
工商网监
评论