 利用NVIDIA SHARP网络计算提升系统性能
利用NVIDIA SHARP网络计算提升系统性能
AI 和科学计算是分布式计算问题的典型示例。这些问题通常计算量巨大,计算很密集,无法在单台机器上完成。于是,这些计算被分解为并行任务,由分布在数千个 CPU 或 GPU 的计算引擎上运行。
为了实现可扩展的性能,需要把工作负载划分在多个节点,如训练数据、模型参数或两者一起划分。然后,这些节点之间需要频繁交换信息,例如模型训练中反向传播期间新处理的模型计算的梯度。这些通信往往需要高效的集合通信,如 all-reduce、broadcast 以及 gather 和 scatter 等操作。
这些集合通信模式可确保整个分布式计算中模型参数的同步和收敛。这些操作的效率对于最大限度地减少通信开销和最大限度地提高并行计算效率至关重要,优化不佳的集合通信可能会导致瓶颈,限制可扩展性。
瓶颈源于以下几个因素:
延迟和带宽限制:集合操作依赖于节点间的高速数据传输,而这些高速数据传输受到物理网络延迟和带宽的限制。随着系统规模的增加,要交换的数据量也随之增加,通信所花费的时间成为至关重要的因素。
同步开销:许多集合操作需要同步点,确保所有参与的节点必须先达到相同的状态,才能继续下一步操作。如果某些节点速度较慢,将拖累整个系统延迟,从而导致效率低下,被称为 stragglers。
网络争用:随着越来越多的节点试图同时通信,网络变得更加拥塞,对带宽和网络资源的争夺也在增加,这进一步降低了集合操作的性能。
非优化通信模式:一些集合通信算法(例如基于树的归约操作或基于 Ring 的 all-reduce 操作)并非始终针对大规模系统进行了良好优化,导致可用资源的低效利用和延迟增加。
克服这一瓶颈需要先进的网络技术(例如 InfiniBand 和 RDMA)和算法优化(例如分层 all-reduce 或流水线技术),以最大限度地减少同步延迟、减少资源争用并优化分布式系统之间的数据流。
创建 NVIDIA SHARP
关键的集合通信使所有计算引擎能够相互交换数据。在网卡或服务器上管理这类通信需要交换大量数据,并且会受到延迟或集合性能差异的影响,称为服务器抖动。
将管理和执行这些集合通信的任务迁移到网络交换机上,可以将传输的数据量减半,并最大限度地减少抖动。NVIDIA Scalable Hierarchical Aggregation and Reduction Protocol(SHARP)技术实现了这一理念,并引入了网络计算概念。它集成在交换机 ASIC 中,旨在加速分布式计算系统中的集合通信。
SHARP 已随着NVIDIA InfiniBand网络一起推出,可将集合通信操作(如 all-reduce、reduce 和 broadcast 等)从服务器的计算引擎卸载到网络交换机。通过直接在网络中执行归约(如求和、平均等),SHARP 可以显著改进这些操作并提升整体应用程序性能。
NVIDIA SHARP 代际演进
第一代 SHARP 专为科学计算应用而设计,侧重于小消息归约操作。它随着NVIDIA EDR 100Gb/s 交换机产品推出,并迅速得到行业领先 MPI 通讯库的支持。SHARPv1 小消息归约可以并行支持多个科学计算应用。
MVAPICH2 是 MPI 标准的开源实现,专为 HPC 场景而设计。负责 MVAPICH MPI 通信库的俄亥俄州立大学团队在德克萨斯先进计算中心 Frontera 超级计算机上验证了 SHARP 的性能。MPI AllReduce 的性能提高了 5 倍,而 MPI Barrier 集合通信的性能则提高了 9 倍。
第二代 SHARP 随着NVIDIA HDR 200Gb/s Quantum InfiniBand 交换机推出,增加了对 AI 工作负载的支持。SHARPv2 支持大消息规约操作,每次支持一个工作负载。这一版本进一步提升了该技术的可扩展性和灵活性,支持更复杂的数据类型和集合操作。
2021 年 6 月 NVIDIA MLPerf 提交的结果展示了 SHARPv2 的性能优势,其中 BERT 的训练性能提高了 17%。扫描二维码,参阅技术博客:
NVIDIA 副总裁兼人工智能系统首席架构师 Michael Houston在加州大学伯克利分校的机器学习系统课程中介绍了 SHARPv2 的 AllReduce 性能优势。
SHARPv2 将 AllReduce 的带宽性能提高了一倍,将 BERT 训练性能提高了 17%。
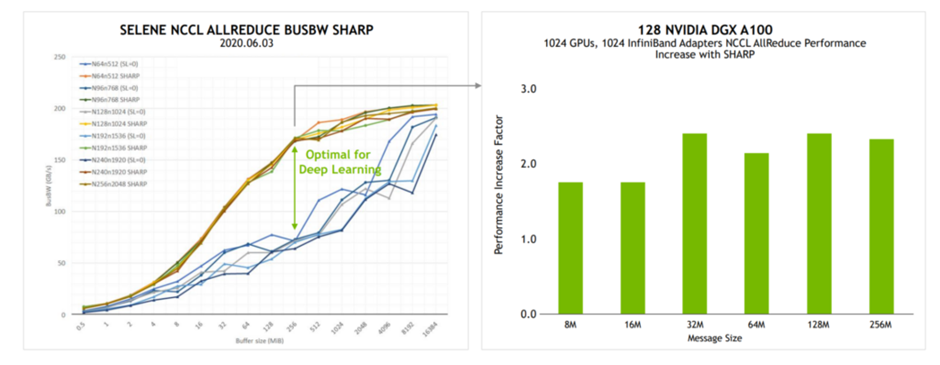
图 1.加州大学伯克利分校机器学习系统课程示例(来源:分布式深度学习,第 II 部分:扩展约束)
第三代 SHARP 随着NVIDIA Quantum-2 NDR 400G InfiniBand平台推出。SHARPv3 支持多租户 AI 工作负载网络计算,与 SHARPv2 的单工作负载相比,可同时支持多个 AI 工作负载的并行使用。
Microsoft Azure 首席软件工程师 Jithin Jose 在“Transforming Clouds to Cloud-Native Supercomputing:Best Practices with Microsoft Azure”专题会议上展示了 SHARPv3 性能。Jithin 介绍了 InfiniBand 网络计算技术在 Azure 上的应用,并展示了 AllReduce 在延迟方面取得数量级的性能优势。
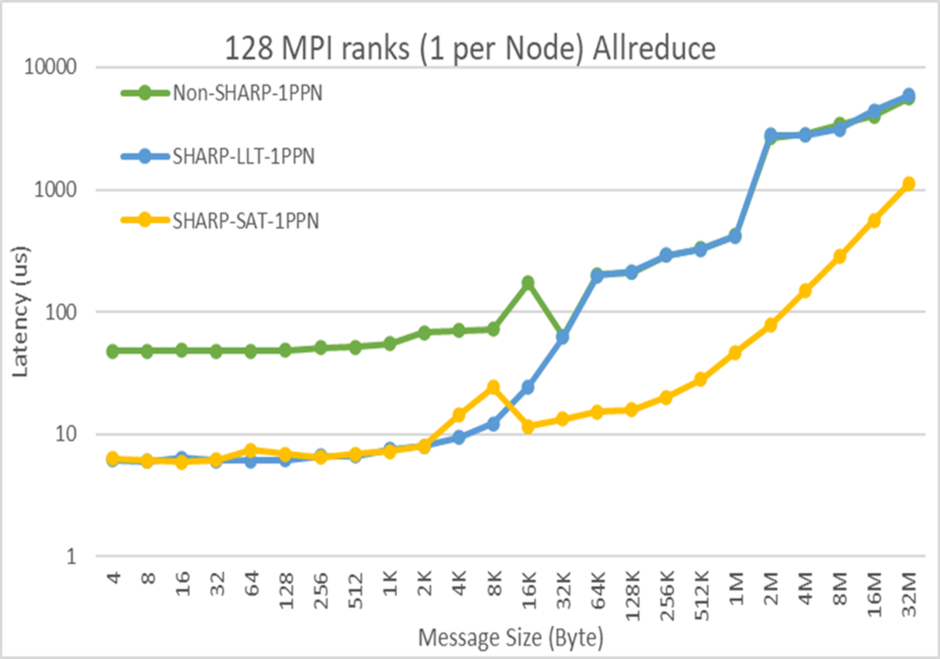
图 2. SHARPv3 的 AllReduce 延迟性能
端到端 AI 系统优化
SHARP 强大功能的经典示例是 allreduce 运算。在模型训练期间,多个 GPU 或节点之间需要进行梯度求和,SHARP 在网络中实现梯度求和,从而无需在 GPU 之间或节点之间进行完整的数据集传送。这缩短了通信时间,从而加快 AI 工作负载的迭代速度并提高吞吐量。
在网络计算和 SHARP 时代到来之前,NVIDIA Collective Communication Library(NCCL)通信软件会从图中复制所有模型权重,执行 all-reduce 运算来计算权重之和,然后将更新的权重写回图,从而产生多次数据复制。
2021 年,NCCL 团队开始集成 SHARP,引入了用户缓冲区注册。这使 NCCL 集合操作能够直接使用指针,从而消除了在此过程中来回复制数据的需求,提高了效率。
如今,SHARP 已与广泛用于分布式 AI 训练框架的 NCCL 紧密集成。经过优化的 NCCL 充分利用 SHARP 的能力,将关键的集合通信操作卸载到网络,从而显著提高分布式深度学习工作负载的可扩展性和性能。
SHARP 技术有助于提高分布式计算应用程序的性能。SHARP 正被 HPC 超级计算中心用于科学计算工作负载,也被人工智能(AI)超级计算机用于 AI 应用程序。SHARP 已成为实现竞争优势的“秘诀”。一家大型服务提供商使用 SHARP 将其内部 AI 工作负载的性能提高了 10% 到 20%。
SHARPv4
SHARPv4 引入了新算法,可支持更多种类的集合通信,这些通信类型已用于领先的人工智能训练应用。
SHARPv4 将随着NVIDIA Quantum-X800 XDR InfiniBand 交换机平台一起发布,从而将网络计算能力提升至更高水平。
-
cpu
+关注
关注
68文章
10901浏览量
212772 -
NVIDIA
+关注
关注
14文章
5075浏览量
103582 -
网络
+关注
关注
14文章
7597浏览量
89142 -
Sharp
+关注
关注
0文章
6浏览量
9103
原文标题:利用 NVIDIA SHARP 网络计算提升系统性能
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
最新可用隔离元件的性能提升如何帮助替代架构在不影响安全性的前提下提升系统性能
HPC 研究人员借助 NVIDIA BlueField DPU 为网络计算的未来打下坚实基础

NVIDIA火热招聘深度学习/高性能计算解决方案架构师
NVIDIA火热招聘GPU高性能计算架构师
多核和多线程技术怎么提升Android网页浏览性能?
感知系统性能评估分析解决方案 精选资料分享
利用NVIDIA BlueField DPU将加速计算提升到新的水平
利用NVIDIA RAPIDS加速DolphinDB Shark平台提升计算性能





 工商网监
工商网监
评论