 智算中心网络交换机需要什么样的缓存架构
智算中心网络交换机需要什么样的缓存架构
在交换机上,缓存就是数据交换的缓冲区,被交换机用来协调不同网络设备之间的速度匹配问题,突发数据可以存储在缓冲区内,直到被慢速设备处理为止。数据中心交换机应用在HPC/AI大模型训练、分布式存储等场景时,并非缓存越大越好,过大的缓存会导致更长的队列、更高的时延和抖动、更高的成本,所以不能简单地去扩大缓存,交换机避免丢包所需的缓存与此带宽延迟积BDP直接相关,借助于带宽时延积BDP可以确定合适的内存大小。
缓存架构分类
按照缓冲区的大小,以太网交换机通常分为深缓冲区交换机和浅缓冲区交换机,深缓冲区交换机缓冲区容量高达数GB,与浅缓冲区交换机的几十MB形成鲜明对比。这种设计上的差异源于应用场景的差异,深缓冲区交换机(或路由器)主要面向路由和广域网场景,RTT时间长,希望能够容纳更多的数据流量,对微突发流量不敏感,但也意味着更高的尾延迟和抖动,这一点与HPC/AI大模型训练、分布式存储等场景的低时延要求显然是相违背的,浅缓冲区交换机在这种场景下更适合,以目前最高端的51.2Tbps(64个800G)的交换机为例,如果RTT时间是3~5微秒,缓存仅需33MB左右,这是交换机中所需的总缓存,那么这个总的缓存能否被每一个端口充分利用吗?
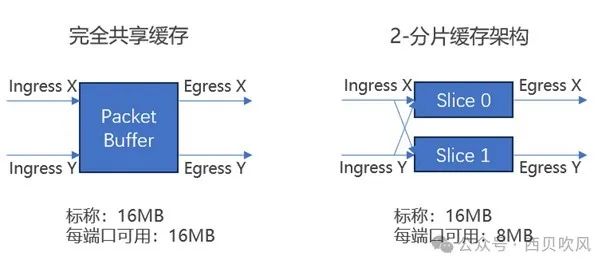
这就取决于交换机(交换芯片)所采用缓存架构。交换芯片的缓存架构通常分为:完全共享缓存架构和分片报文缓存架构(也称分割缓冲区结构)。
完全共享缓存架构:设备中的所有缓存都可用于动态分配到任何端口,意味着在所有输入-输出端口之间共享缓存而没有任何限制,最大限度地提高了可用内存的效率。
分片报文缓存架构:由多片较小的缓存共同组成了芯片内部的缓存,所有的物理接口也被划分成了不同的组,同一组内的物理接口共享对应的缓存单元。
不同缓存架构影响
如下图所示,同样是16MB的缓存情况下,完全共享缓冲架构中的每个端口极限情况下(如多打一的Incast场景,)可以最大利用到16MB;如果是两个分片的分组端口缓存架构下,每个端口极限情况下仅可以最大利用到8MB;而如果是四个分片的分组端口缓存架构下,每个端口极限情况下仅可以最大利用到4MB。
思科之前的文档中也做过分析,分片报文缓存架构下,不同的流量模型对微突发流量吸收的影响或限制也不同,如下图所示:
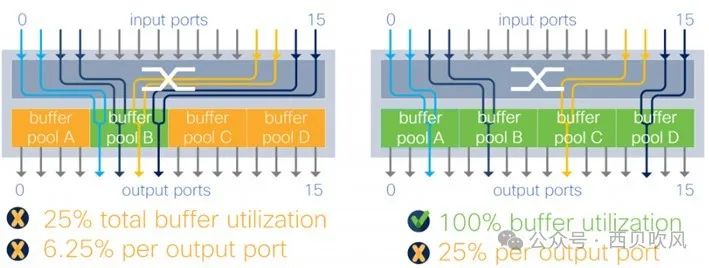
以图中右侧图示情况为例,4个分片的架构下,如果四个输出端口位于4个不同的分片上,最理想的情况可以达到100%的缓存利用,但是任意一个输出端口最多仅可以消耗总内存的25%。在复杂的流量模式下,这种限制可能会更加痛苦,如图中右侧图示为例,此情况下,一个输出端口的缓存被限制为总缓冲区的1/16(6.25%),这种限制使得Incast下的缓冲行为不可预测。 在完全共享缓存架构中,设备中的所有数据包缓冲区都可用于动态分配到任意一个端口,这意味着在所有输入输出端口之间共享缓存而没有任何限制,最大限度地提高了可用内存的效率,并且使微突发流量吸收能力可预测,与流量模型没有任何关系。
完全共享缓存的优势也体现在RoCEv2网络中,RoCEv2是TCP/IP协议中UDP层实现,因为使用不需要确认的UDP协议,此时RTT不是缓冲区需求的直接驱动因素,但是RDMA的无损特性往往要依靠PFC来实现,PFC逐级反压控制会导致拥塞蔓延,完全共享缓存通过在需要的时间和节点支持更多的缓存,有助于最大限度地减少触发PFC流量控制的需要。
主流厂商实现当前市场上,大多数数据中心交换机都是使用商用交换芯片ASIC构建的,这些ASIC针对传统的数据流量模式和数据包大小进行了成本优化,为了在实现带宽目标的同时保持低成本,芯片供应商更多使用了分片缓存架构,牺牲了公平性,同时面临不可预测性和微突发吸收的问题。
但是,当前几个主要厂商51.2Tbps最高容量的交换芯片,由于应对场景以HPC/AI大模型训练等为主,基本都采用完全共享缓存架构,相关的交换芯片或交换机如博通Tomahawk5、英伟达Spectrum-4、思科Silicon One G200都是宣传采用完全共享缓存架构。
-
网络交换机
+关注
关注
1文章
67浏览量
16037 -
缓存
+关注
关注
1文章
239浏览量
26665 -
智算中心
+关注
关注
0文章
67浏览量
1688
原文标题:智算中心网络交换机需要什么样的缓存架构?
文章出处:【微信号:SDNLAB,微信公众号:SDNLAB】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
广西南宁企业级综合网关、网络核心交换机等售后维修服务中心点深妙科技

反射内存交换机与普通交换机的区别

网管型交换机和非网管型交换机的区别
园区交换机 VS 数据中心交换机







 工商网监
工商网监
评论