 一文了解嵌入式软件开发的对象
一文了解嵌入式软件开发的对象
以前应用场景很单一,嵌入式开发可能谈不上面向对象开发。但现在,做嵌入式开发,没有面向对象开发,你就有点落伍了。
本文结合个人经验和周立功《抽象接口技术和组件开发规范及其思想》,循序渐进的用代码范例说明嵌入式软件开发的对象,前提你最好有一点点C++基础。间接说明理论指导实践的意义。
纸上得来终觉浅,绝知此事要躬行。
1 面向对象编程基础
面向对象编程涉及到三个重要的特性:封装、继承与多态。部分 C 程序员,特别是嵌入式 C 程序员有一种误解,C 语言不是面向对象的编程语言,C++、Java、Python 等更高级的才是,使用 C 语言无法实现面向对象编程。这种误解致使他们没有动力学习一些优秀的面向对象编程方法,例如设计模式、设计原则、软件架构设计等等,进而很难开发出易维护、易部署、易重用、易管理的软件,很难面对项目需求的变更、扩展,很难开发和维护大型的复杂项目。
1.1 对象
面向对象编程,“对象”是整个编程过程的关键。其常见的解释是“数据与函数的组合”。每个对象都是由一组数据(用以描述对象的状态)和一组函数(对象支持的操作,用以描述对象的行为)组成的。对象实现了数据和操作的结合,使数据和操作可以封装于“对象”这个统一体中。
在面向过程编程中,程序设计注重的是“过程”,先做什么,后做什么;在外界看来,整个程序由一系列散乱的数据和函数组合而成。而在面向对象编程中,程序设计注重的是“对象”,在外界看来,整个程序由一系列“对象”块组合而成,数据和函数封装到了对象内部。
1.2 类
对象是有“类型”的,即类。“类”是对一组对象共性的抽象,表示一类对象,而对象是某个类的一个具体化的个例,通常称之为类的实例。对象通常是由数据和函数组成的,相应的类也具有两部分内容:属性(数据的抽象)和方法(对象行为的抽象)。
除了封装属性和操作外,类还具有访问控制的能力,如某些属性和方法是私有的,不能被外界访问。通过访问控制,能够对内部数据提供不同级别的保护,以防止外界意外地改变或使用私有部分。
1. 属性
类具有属性,它是对数据(对象的状态)的抽象。在 C 程序设计时,通常使用结构体类型来表示一个类,相关属性即包含在相应的结构体类型中。例如学生具有属性:姓名、学号、性别、身高、体重等信息,可以使用如下结构体类型表示“学生类”:
//微信公众号【嵌入式系统】 structstudent { charname[10];/*姓名(假定最长10字符)*/ unsignedintid;/*学号*/ charsex;/*性别:'M',男;'F',女*/ floatheight;/*身高*/ floatweight;/*体重*/ }; //提示,关于结构体、枚举等复杂类型定义推荐使用关键字typedef
提示,关于结构体、枚举等复杂类型定义推荐使用关键字 typedef,更多C关键字了解可以参考《C语言关键字应用技巧》、《高质量嵌入式软件的开发技巧》。
2. 方法
类具有方法,它是对象行为的抽象,在 C 程序中,方法可以看作普通函数,不过其通常有一个特点 ,函数的第一个参数为类型的指针,指向了一个确定的对象,用以表明此次操作针对哪个对象,在方法实现时,即可通过该指针访问到对象中的各个属性。(微信公众号【嵌入式系统】这是C面向对象必须的,类似C++的this)
针对学生对象,为了对外展现学生自身的信息,自我介绍的格式是对外输出一个固定格式的字符串:
"Hi! My name is xxx, I'm a (boy/girl). My school number is xxx. My height is xxxcm and weight is xxxkg . "
其中的 xxx 对应学生实际的信息,基于此,可以为学生类定义并实现一个“自我介绍”的方法:
voidstudent_self_introduction(structstudent*p_this)
{
printf("Hi!Mynameis%s,I'ma%s.Myschoolnumberis%d.Myheightis%fcmandweightis%fkg",
p_this->name,
(p_this->sex=='M')?"boy":"girl",
p_this->id,
p_this->height,
p_this->weight);
}
对于外界来讲,调用学生的“自我介绍”方法可以获知学生的全部信息。基于该类的定义,一个简易的应用程序范例详如下:
voidmain(void)
{
structstudentchengj={"chengj",2024001,'M',173,68};
structstudenthehe={"hehe",2024002,'M',150,45};
student_self_introduction(&chengj);
student_self_introduction(&hehe);
//...
}
类中的方法 student_self_introduction 可以作用于任一学生类对象,对于程序员来讲,编写的代码将适用于一组对象,而非特定的某一个对象,提高了代码利用率。
在实际应用中,对比代码《嵌入式算法14---数据流与环形队列》,不少程序员都喜欢编写出一堆非常类似的接口,它们仅通过某一个数字后缀(0、1、2……)来区分,如系统使用到 3 个栈,初级程序员可能实现 3 个入栈函数,不良示意代码如下:
//三个栈入栈的不良范例,引以为戒 intpush_stack0(intdata) { //... } intpush_stack1(intdata) { //... } intpush_stack2(intdata) { //... }
三个操作可能除了极小部分的差异外,其它处理完全相同,这就是没有面向对象编程的思维,没有定义对象类型的概念,将操作直接针对每个具体对象(栈 0、栈 1、栈 2),而不是一组同类的对象(所有栈对象)。显然,3个栈的特性和行为都基本类似,因而可以定义一个“栈类型”,如此一来,入栈操作将属于栈类型中的一个方法,适用于所有栈对象。例如:
//数据压入栈,p_stack指向具体的栈对象 intpush_stack(stack*p_stack,intdata); //微信公众号:嵌入式系统 //三个栈的入栈操作均可使用同一个方法 push_stack(p_stack0,1); push_stack(p_stack1,2); push_stack(p_stack2,3);
这只是示意性代码,说明使用“类”的设计解决问题所带来的优势。
1.3 UML 类图
在面向对象的设计和开发过程中,通常使用 UML 工具来进行分析与设计。最基本的就是使用 UML 类图来表示类以及描述类之间的关系。
在 UML 类图中,一个矩形框表示一个类,矩形框内部被分隔为上、中、下三部分,上部为类的名字,中部为类的属性,下面部分为类的方法。对于属性和方法,还可以使用“+”、“-”修饰符来表示访问权限,“+”为公有属性、“-”为私有属性。如前面的学生类,其类名为 student,属性包括姓名、学号、性别、身高、体重,方法有“自我介绍”方法,则其对应的类图如下:
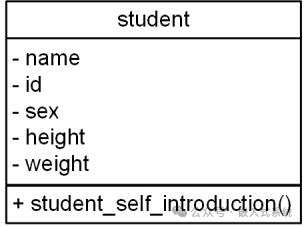
通常情况下,类中的所有属性均为私有属性,不建议直接访问,所有属性的访问都通过类提供的方法。基于此,假定了学生类中的所有属性均为私有属性,因而在所有属性前都增加了“-”修饰符。
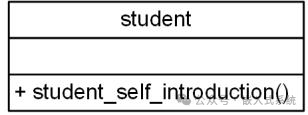
UML 类图主要用于辅助分析和设计,设计类时应聚焦在与当前问题有关的重要属性和行为,无关的属性和方法可去掉,确保简洁。由于私有属性仅在内部使用,外界无需关心,因此UML 类图中通常不体现私有属性和方法,除非某些特殊的私有属性和方法影响到问题的理解或者类的实现。基于此可以简化。
2 封装
类是对一组对象共性的抽象,封装了属性和方法;即把一组关联的数据和函数圈起来,使圈外的代码只能看见部分函数,数据则完全不可见(微信公众号【嵌入式系统】一般建议数据的访问都应通过类提供的方法,而不是全局变量满天飞)。
2.1 “封装”示例
在C语言中,可使用一个 C 文件(*.c 文件)和 H 文件(*.h 文件)完成“类”的定义,将所有需要封装的东西都存于 C 文件中,H 文件中只展现“对外可见、无需封装”的内容。
以栈的实现为例,将所有实现代码都存于 C 文件中,H 文件只包含与栈相关接口的声明,比如入栈和出栈等。头文件和源文件的示意内容分别详见如下:
stack.h文件
#ifndef__STACK_H #define__STACK_H //微信公众号:嵌入式系统所有头文件都必须防止重复引用 /*类型声明,无需关心类定义的具体细节*/ structstack; /*创建栈,并指定栈空间的大小*/ structstack*stack_create(intsize); /*入栈*/ intstack_push(structstack*p_stack,intval); /*出栈*/ intstack_pop(structstack*p_stack,int*p_val); /*删除栈*/ intstack_delete(structstack*p_stack); #endif
stack.c文件
//微信公众号:嵌入式系统
#include"stack.h"
#include"stdlib.h"
structstack
{
inttop;/*栈顶*/
int*p_buf;/*栈缓存*/
unsignedintsize;/*栈缓存的大小*/
};
unsignedintsize;/*栈缓存的大小*/
structstack*stack_create(intsize)
{
structstack*p_stack=(structstack*)malloc(sizeof(structstack));
if(p_stack!=NULL)
{
p_stack->top=0;
p_stack->size=size;
p_stack->p_buf=(int*)malloc(sizeof(int)*size);
if(p_stack->p_buf!=NULL)
{
returnp_stack;
}
free(p_stack);/*分配栈内存失败*/
}
returnNULL;/*创建栈失败,返回NULL*/
}
intstack_push(structstack*p_stack,intval)
{
if(p_stack->top!=p_stack->size)//未满可入栈
{
p_stack->p_buf[p_stack->top++]=val;
return0;
}
return-1;
}
intstack_pop(structstack*p_stack,int*p_val)
{
if(p_stack->top!=0)//非空可出栈
{
*p_val=p_stack->p_buf[--p_stack->top];
return0;
}
return-1;
}
intstack_delete(structstack*p_stack)
{
if(p_stack==NULL)
{
return-1;
}
if(p_stack->p_buf!=NULL)
{
free(p_stack->p_buf);
}
free(p_stack);
return0;
}
使用 stack.h 的程序没有 struct stack 结构体成员的访问权限的,只能调用stack.h 文件中声明的方法。对于外界用户来说,struct stack 结构体的内部细节,以及各个函数的具体实现方式都是不可见的。这正是完美的封装!
由于所有细节都封装到了 C 文件内部,用户通过 stack.h 文件并不能看到 struct stack 结构体的具体定义,因此也无法访问 stack 结构体中的成员。若用户尝试访问 struct stack结构体中的成员,将会编译报错。(微信公众号【嵌入式系统】C 语言不是面向对象的编程语言,实现封装有扩展性的牺牲)。
C语言实现封装的一般做法为:在头文件中进行数据结构以及函数定义的前置声明,在源文件中完成各函数的具体实现以及数据结构的定义。这样所有函数实现及定义细节均封装到了源文件中,对使用者来说是完全不可见的。
2.2 创建对象
2.2.1 内存分配的问题
基于前面创建栈方法,可以创建多个栈对象,例如:
structstack*p_stack1=stack_create(20); structstack*p_stack2=stack_create(30); structstack*p_stack3=stack_create(50);
每个栈对象需要两部分内存:
一是栈对象本身的内存(内存大小为 sizeof(struct stack));
二是该栈对象用于存储数据的缓存(内存大小为 sizeof(int) * size,其中,size 由用户在创建 栈时通过参数指定)。
在栈对象的创建函数中,使用 malloc()分配了该对象所需的内存空间,使用 malloc()分配内存空间非常方便,但这种做法也限制了对象内存的来源——必须使用动态内存。但对于嵌入式系统,内存往往是很大的瓶颈,很多应用场合可能并不太适合使用动态内存,主要有以下几个因素:
1)内存资源不足。运行嵌入式软件的硬件平台普遍内存小甚至只有几k RAM。这种条件下管理使用动态内存是比较浪费的行为,可能产生内存碎片,且内存分配的软件算法本身也会占用一定的内存空间。
2)实时性要求高。部分嵌入式应用对实时性要求很高,但由于资源的限制,集成的动态内存分配算法不是很完善,使得很难确保动态内存分配的实时性。
3)内存泄漏。动态内存分配可能出现内存泄漏。
4)软件编程复杂。在可靠的设计中,必须考虑内存分配失败的情况并对其进行异常处理,如果存在大量的动态内存分配,则处处都需考虑分配失败的情况。
将对象内存的来源限制为动态内存分配,限制了该类的应用场合,致使部分应用场合因为内存来源的问题不得不放弃该类的使用。
2.2.2 内存来源的探索
在 C 程序开发中,除了使用 malloc()得到一段内存空间外,还可以使用“直接定义变量”的形式分配一段内存。直接定义变量的形式,内存在编译阶段由编译器负责分配,无需用户作任何干预。根据变量定义位置的不同,实际内存的开辟位置存在一定的区别,主要有两类:
局部变量:内存开辟在栈中; 静态变量(static 修饰的变量)或全局变量:内存开辟在全局静态存储区。
两种变量主要是生命周期的不同:局部变量在退出当前作用域后(比如函数返回),内存自动释放;静态变量或全局变量内存开辟在全局静态存储区,它们在程序的整个生命周期均有效。
内存可以有 3 种来源,它们的优缺点对比详见下表:
| 内存类别 | 内存位置 | 生命周期 | 优点 | 缺点 |
|---|---|---|---|---|
| 动态内存 | 系统堆 Heap | 直到调用free()释放内存 | 灵活,可以随时按需分配和释放 | 内存分配可能失败,花费的时间可能不确定;需要处理内存分配失败的情况,增加程序的复杂性 |
| 静态内存 | 全局静态存储区(.data、.bss存储段) | 程序的整个运行周期 | 确定性好,只要程序能够编译、链接成功,内存一定能够分配成功 | 需要编程时确定内存的大小;一直占用内存,无法释放 |
| 栈内存 | 系统栈(或任务栈) | 函数调用周期 | 自动完成内存的分配和回收 | 内存太大会导致栈溢出 |
| 微信公众号:嵌入式系统 |
不同来源的内存各有优劣。前面提到,stack_create()函数将内存的来源限制为仅动态内存不太合理。为了避免内存来源受限,“内存的分配”这一步交由用户实现,以便用户根据实际需要自由选择内存的来源。基于此,可以将对象的创建拆分为两个独立的步骤,分配对象所需的内存和初始化对象。
2.2.3 分配对象所需的内存
内存分配的工作交由用户完成,以便用户根据实际需要自由选择。用户能够完成内存分配的前提是:用户知道应该分配的内存大小。前面提到,每个栈对象需要两部分内存:一是栈对象本身的内存(内存大小为:sizeof(struct stack));二是该栈对象用于存储数据的缓存(内存大小为 sizeof(int) * size,其中,size 由用户在创建栈时通过参数指定)。
1、栈对象本身的内存
栈对象本身的内存大小为 sizeof(struct stack),若用户直接采用静态内存分配的方式(直接定义一个变量),则形式如下:
structstackmy_stack;
也可以继续采用动态内存的分配方式,例如:
structstack*p_stack=(structstack*)malloc(sizeof(structstack));
但是,若将这两行代码直接放到主程序中会无法编译,因为之前描述的“封装”特性,使外界看不到 struct stack 的具体定义,也就是说,对于外界而言,该类型仅仅只是声明并未定义,该类型对应变量的大小对外也是未知的。
在 C 语言中定义一个变量时,编译器将负责该变量所占用内存的分配。内存的大小与类型相关,要完成变量内存的分配,编译器必须知道变量所占用的存储空间大小。当一个变量的类型未定义时,无法完成该类型对应变量的定义,因此,如下语句在编译时会出错:
structstackmy_stack;
同理,sizeof 语句用于获得相应类型数据的大小,而未定义的类型显然是不知道其大小的,动态内存分配中所使用的 sizeof(struct stack)语句也是错误的。
也许部分人会有疑问,既然该类型未定义,为什么在主程序中定义该类型的指针变量却可以呢?
structstack*p_stack=//...
虽然 struct stack 类型未定义,但在之前已经声明,因此,编译器知道它是一个“合法的结构体类型”。此外,这里定义的是一个指针变量,在特定系统中,指针变量所占用的内存大小是确定的,例如,在 32 位系统中,指针通常占用 4 个字节。即指针变量所占用的内存空间大小与其指向的数据类型无关,编译器无需知道其指向的数据类型,就可完成指针变量内存的分配。因此,一个类型未定义,只要其声明了,就可以定义该类型的指针变量。但需要注意的是,在完成该类型的定义之前,不得尝试访问该指针所指向的内容。
完成内存的分配,提供三种方案。
(1) 将类的具体定义放到 H 文件中
为了使用户知道对象内存的大小,一种最简单的办法是直接将类型的定义放在 H 文件中。更新后的 H 文件示意代码如下:
stack.h文件
#ifndef__STACK_H
#define__STACK_H
/*类型定义*/
structstack
{
inttop;/*栈顶*/
int*p_buf;/*栈缓存*/
unsignedintsize;/*栈缓存的大小*/
};
//......其它函数声明
#endif
此时,对于外界,类型已经定义,如下语句均可正常使用:
structstackmy_stack;//静态内存分配 structstack*p_stack=(structstack*)malloc(sizeof(structstack));//动态内存分配
由于类型的定义存放到了 H 文件中,暴露了类中的成员,在一定程度上破坏了类的“封装”性。此时外界可以直接访问类中的数据成员。牺牲一定的封装性,换来内存分配的灵活性,这也是在嵌入式系统中,基于 C 语言实现面向对象编程的一般做法(数据结构定义存放在 H 文件中更加符合程序员的编程风格)。嵌入式软件大多数类定义在 H文件中,并没有封装在 C 文件中。
虽然类的定义存放在 H 文件中,但出于封装性考虑,外界任何时候都不应直接访问对象中的数据,应该将其视为使用 C 语言实现面向对象编程的一条准则。软件开发需要遵守两个规则:一是在设计类时,应考虑到用户可能访问的数据,并为这些数据提供相应的访问接口;二是在使用别人提供的类时,除非有特殊说明,否则都不应该尝试直接访问类中的数据。
这种方法是目前嵌入式系统中使用得最为广泛的一种方法,因此后文使用这种方法讨论。
(2) 在 H 文件中定义一个新的结构体类型
为了继续保持类的封装性,类的定义依然保留在 C 文件中。只不过与此同时,在 H 文件中定义一个新的结构体类型。在该结构体类型中,各个成员的顺序和类型与类定义完全一致,仅命名不同。
structstack_mem
{
intdummy1;
int*dummy2;
unsignedintdummy3;
};
各成员的顺序和类型均与 struct stack 的定义完全相同,以此保证两个类型数据所需要的内存空间完全一致。同时,为了屏蔽各个成员的具体含义,所有成员均以 dummy 开头进行命名。对于外界来讲,可以基于 struct stack_mem 类型完成内存的分配,例如:
structstack_memmy_stack;//静态内存分配 structstack*p_stack=(structstack*)malloc(sizeof(structstack_mem));//动态内存分配
使用这种方案,类的实际定义依然没有暴露给外界,继续保持了良好的封装。(微信公众号【嵌入式系统】实际上FreeRTOS中,很多地方都采用了这种方法)。但这里定义了一个新的类型,给用户理解上造成了一定的困扰,此外,为确保两个类型完全一致,就要求类的设计者在修改类的定义时,必须确保 struct stack_mem 类型也同步修改,这给类的维护工作带来了挑战;稍有不慎,某一个类型没有同步修改就可能造成严重的错误,且这种错误编译器不会给出任何提示,非常隐蔽。关于代码审查可以参考《代码审查那些事》、《代码的保养》。
(3) 使用宏的形式告知对象所需的内存大小
既然外界只需要知道对象内存的大小,可以在开发过程中使用 sizoeof()获得struct stack 类型的大小,然后将其以宏的形式定义在 H 文件中。例如在 32 位系统中,使用 sizeof()获知 struct stack 类型的长度为 12,则可以在 H 文件中定义一个宏,例如:
#defineSTACK_MEM_SIZE12
用户使用该宏完成内存分配,例如:
unsignedcharstack_mem[STACK_MEM_SIZE];
这种做法仅仅在头文件中新增了一个宏定义,类的定义依然保持的 C 文件中,“封装”完全没有被破坏,看起来也非常完美。但这种做法也存在一些问题,因而很少采用。
a)对于同一个类型,不同系统中 sizeof()的结果可能不同。类型的长度与系统和编译器均相关。以 int 类型为例,在 32 位系统中为 32 位(4 字节),但 16 位系统中,其位宽可能为 16 位(2 字节)。因此,同样是 sizeof(int),结果可能为 4,也可能为 2。使用 sizeof()获取类型的长度时,不同系统中获取的结果可能并不相同。这就导致 H 文件中的宏定义,切换平台需要重新测试验证。同时,由于类型的定义封装到了 C 文件中,因此修改过程只能有类的开发者完成,一般用户还无法完成,这就使得该类的跨平台特性很差,移植有风险。
b)内存不仅有大小的要求,还有内存对齐的要求。
因此,通过一个宏告知用户需要分配的内存空间大小并不是十分合适,会遇到跨平台、内存对齐等多个注意事项,用户可能在不经意间出错。在实际嵌入式系统中很少使用。一些编码技能可以参考《高质量嵌入式软件的开发技巧》。
2、存储数据的缓存
存储数据的缓存大小为 sizeof(int) *size,其中的 size 本身就是由用户指定的,这部分内存的大小用户很容易得知,进而完成内存的分配。可以采用静态内存分配的方式(直接定义一个变量)完成内存的分配:
intbuf[20];
也可以采用动态内存分配的方式完成内存的分配:
int*p_buf=(int*)malloc(sizeof(int)*20);
2.2.4 内存小曲
内存的来源主要有三种:动态内存、静态内存和栈内存,具体如何选择按实际情况。
| 对象类别 | 应用场合 |
|---|---|
| 动态对象 | 不会频繁创建、销毁对象的应用;内存占用太大的对象 |
| 静态对象 | 确定性要求较高,长生命周期的对象 |
| 栈对象 | 函数内部使用的临时对象;对象内存占用较小的对象 |
一些入式应用对确定性要求较高,建议优先使用静态对象。如此一来只要能够编译(包含链接)成功,应用程序往往就可以按照确定的流程正确执行;若使用动态对象,则必须考虑对象创建失败的情况。偶尔使用的大块内存则建议使用动态内存,使用注意和防范可参考《动态内存管理及防御性编程》。
2.3 初始化对象
初始化对象的具体细节用户不需要关心,指定栈对象的地址、缓存地址及缓存大小,基于此,可以定义初始化函数的原型为:
intstack_init(structstack*p_stack,int*p_buf,intsize);
对于栈来讲,栈顶索引(top)的初始值恒为 0,因此该值无需通过初始化函数的参数传递。int 类型的返回值常用于表示执行的结果(微信公众号【嵌入式系统】建议非指针类型的返回值,以0表示成功,负数表示失败)。该函数的实现示意如下:
//微信公众号:嵌入式系统
intstack_init(structstack*p_stack,int*p_buf,intsize)
{
p_stack->top=0;
p_stack->size=size;
p_stack->p_buf=p_buf;
return0;
}
该初始化函数的实现仅作为原理性展示,没有做过多的错误处理或参数检查,实际应用中,p_stack 为 NULL 或 p_buf 为 NULL 等情况都是错误情况,后续范例也会省去部分参数校验)。
至此,完成了将创建对象分离为“分配对象所需的内存”和“初始化对象”两个步骤,对象内存的来源交由用户决定,用户根据需要获得内存后,再将相关内存的首地址传递给初始化函数。
2.4 销毁对象
实现 stack_create()以及对应的stack_delete(),设计该函数的初衷是当一个栈对象不会再被使用时,可以通过该函数释放栈占用的资源,比如释放在 stack_create()函数中使用 malloc()分配的内存资源。
当将 stack_create()拆分为两步后,内存的分配将由用户决定,对应地内存的释放也应由用户决定。回顾 stack_delete()函数的实现,该函数目前只做了内存释放相关的操作,当不需要释放内存时,该函数看起来没有存在的必要。实际上,stack_delete()和 stack_create()函数是对应的,当将 stack_create()拆分为“分配对象所需的内存”和“初始化对象”两个步骤后,stack_delete()也应该相应的拆分为两个步骤:“释放对象占用的内存”和“解初始化对象”(微信公众号【嵌入式系统】解初始化或者反初始化,不用太在意这个操作的名称,只要理解表达的意思是初始化的逆过程即可,init:deinit,关于命名的英文集客参考《嵌入式软件命名常用英文集》)。
1. 释放对象占用的内存
前面已经提到,释放内存交由用户处理,释放方法与内存的来源相关。
动态内存的释放动态内存分配应使用相应的释放内存函数(如 free())进行释放。在释放时应确保分配的内存全部被有效释放。若某一部分内存被遗漏,将造成内存泄漏。随着程序的长期运行,内存不断泄漏可能导致系统崩溃。
静态内存的释放使用静态内存(定义变量的形式),则内存的释放是系统自动完成的。若将对象定义为局部变量,内存开辟在系统栈中,则退出当前作用域后(函数返回)自动释放;若将对象定义为静态变量(static)或全局变量,则内存开辟在全局静态区,该区域的内存在应用程序的整个生命周期均有效,无法释放。
2. 解初始化对象
释放内存已交由用户处理,对于类的设计来讲,重点是设计“解初始化对象”对应的函数,该函数与 stack_init()函数对应,通常命名为“*_deinit”,即:stack_deinit()。该函数通常用于释放在初始化对象时占用的其它资源。
对于纯软件对象(与硬件无关的软件),通常其只会占用内存资源,不会额外占用其它资源,对这类对象解初始化时可能无需做任何事情。例如前面关于栈的实现,在stack_init()函数中仅对几个属性进行了赋值,没有额外占用其它任何资源,此时,stack_deinit()可能无需做任何事情,成为一个空函数。
intstack_deinit(structstack*p_stack)
{
return0;
}
在嵌入式系统中,经常会遇到与硬件相关的对象,其初始化时往往会占用一定的硬件资源:I/O 引脚、系统中断、系统总线。在解初始化这种对象时,应同时释放占用的资源。可重点关注对象的初始化函数,查看其中是否分配、占用了某些资源。若有,则在解初始化函数中作相应的释放操作;若无,则解初始化函数留空。为了提高软件的简洁性,也可删除了空的解初始化函数,但这里为了展示软件结构,依然保留了解初始化函数。
将原 H 文件中的创建接口更新为初始化接口,删除接口更新为解初始化接口,更新后的 H 文件内容和 C 文件如下:
stack.h文件
//微信公众号:嵌入式系统
#ifndef__STACK_H
#define__STACK_H
/*类型定义*/
structstack
{
inttop;/*栈顶*/
int*p_buf;/*栈缓存*/
unsignedintsize;/*栈缓存的大小*/
};
/*初始化*/
intstack_init(structstack*p_stack,int*p_buf,intsize);
/*入栈*/
intstack_push(structstack*p_stack,intval);
/*出栈*/
intstack_pop(structstack*p_stack,int*p_val);
/*解初始化*/
intstack_deinit(structstack*p_stack);
#endif
stack.c文件
//微信公众号:嵌入式系统
#include"stack.h"
intstack_init(structstack*p_stack,int*p_buf,intsize)
{
p_stack->top=0;
p_stack->size=size;
p_stack->p_buf=p_buf;
return0;
}
intstack_push(structstack*p_stack,intval)
{
if(p_stack->top!=p_stack->size)
{
p_stack->p_buf[p_stack->top++]=val;
return0;
}
return-1;
}
intstack_pop(structstack*p_stack,int*p_val)
{
if(p_stack->top!=0)
{
*p_val=p_stack->p_buf[--p_stack->top];
return0;
}
return-1;
}
intstack_deinit(structstack*p_stack)
{
return0;
}
3. 销毁对象的顺序
创建对象时是先分配对象所需内存,再初始化对象,因为在初始化对象时,需要传递相应内存空间的首地址作为初始化函数的参数。这就保证了在初始化对象之前,必须完成相关内存的分配。而销毁一个对象时,释放内存与调用解初始化函数并不能通过接口进行制约,销毁过程与创建恰恰相反,应先解初始化对象,再释放对象占用的内存。因为在解初始化对象时,还会使用到对象中的数据,若先释放对象占用的内存,则对象在被解初始化之前,就被彻底销毁了,对象已经不存在了,显然无法再进行解初始化操作。
若内存来源于动态内存分配,则完整的应用程序范例如下:
//微信公众号:嵌入式系统
#include"stack.h"
#include"stdio.h"
#include"stdlib.h"
intmain()
{
intval;
structstack*p_stack=(structstack*)malloc(sizeof(structstack));
int*p_buf=(int*)malloc(sizeof(int)*20);
//初始化
stack_init(p_stack,buf,20);
//依次压入数据:2、4、5、8
stack_push(p_stack,2);
stack_push(p_stack,4);
stack_push(p_stack,5);
stack_push(p_stack,8);
//依次弹出各个数据,并打印
stack_pop(p_stack,&val);
printf("%d",val);
stack_pop(p_stack,&val);
printf("%d",val);
stack_pop(p_stack,&val);
printf("%d",val);
stack_pop(p_stack,&val);
printf("%d",val);
//解初始化
stack_deinit(p_stack);
//释放内存
free(p_stack);
free(p_buf);
return0;
}
若内存来源于静态内存分配,则内存的分配和释放完全由系统自行完成,如内存以“局部变量”的形式分配,范例程序如下:
//微信公众号:嵌入式系统
#include"stack.h"
#include"stdio.h"
intmain()
{
intval;
intbuf[20];
structstackstack;
structstack*p_stack=&stack;
stack_init(p_stack,buf,20);
//依次压入数据:2、4、5、8
stack_push(p_stack,2);
stack_push(p_stack,4);
stack_push(p_stack,5);
stack_push(p_stack,8);
//依次弹出各个数据,并打印
stack_pop(p_stack,&val);
printf("%d",val);
stack_pop(p_stack,&val);
printf("%d",val);
stack_pop(p_stack,&val);
printf("%d",val);
stack_pop(p_stack,&val);
printf("%d",val);
stack_deinit(p_stack);
return0;
}
从形式上看,虽然栈类的代码变得复杂了一些,但对象内存的来源更具有灵活性,使得栈的适用范围更加广泛。在部分系统中,在保证对象内存来源不受限制的同时,为了特殊情况下的便利性,往往还保留了基于动态内存分配创建对象的方法,在这种情况下,将同时提供create 和 init 两套接口。
以 FreeRTOS 为例,其提供了两套创建任务的接口:xTaskCreate()和 xTaskCreateStatic()。其中,xTaskCreate()函数中采用动态内存分配的方法获得了任务相关内存;而 xTaskCreateStatic()函数即用于以“静态”的方式创建任务,任务相关的内存需要用户通过函数的参数传递(实际上该函数的作用就类似于 init 初始化函数,只不过其命名为了 Create)。freeRTOS可以作为RTOS开发入门的基础,具体可参考《FreeRTOS及其应用,万字长文,基础入门》、《基于RTOS的软件开发理论》。
在绝大部分面向对象编程语言中,也有类似于初始化和解初始化的接口,以C++为例,在定义类时,每个类都有构造函数和析构函数两个特殊的函数。构造函数就相当于这里的初始化函数,其在创建对象时自动调用;析构函数就相当于这里的解初始化函数,其在销毁对象时自动调用。例如,以局部变量的形式定义一个对象,则在定义对象时,会自动调用构造函数;在退出当前作用域(函数返回)时,会自动调用析构函数。高级的面向对象编程语言,为很多操作提供了语法特性上的原生支持,给实际编程带来了极大的便利。
3 继承
继承表示了一种类与类之间的特殊关系,即 is-a 关系,例如苹果是一种水果。A is-a B,表明了 A 只是 B 的一个特例,并不是 B 的全部,A(苹果)是子类,B(水果)是父类(又称基类、超类)。
子类是父类的一个特例,可以看作是在父类的基础上作了一些属性或方法的扩展,子类依然具有父类的属性和方法。使用继承关系在一个已经存在的类的基础上,定义一个新类。新类将自动继承已存在类的属性和方法,并可根据需要添加新的属性和方法。继承使子类可以重用父类中已经实现的属性和方法,无需再重复设计和编程,以此实现代码最大限度的复用。
3.1 “继承”示例
在 C 语言编程中,在定义子类(子类结构体类型)时,通过将父类作为子类的第一个成员实现继承。之所以这样做,是因为在 C 语言结构体中,第一个成员(父类)的地址和结构体自身(子类)的地址相同,当子类需要复用父类的方法时,子类的地址也可以作为父类的地址使用(微信公众号【嵌入式系统】这是后续继承操作取巧的基础)。
例如在一个系统中具有多个栈,为便于区分,每个栈可以具有不同的名称(系统栈、数据栈、符号栈……)。基于该需求,可以实现一个带名称的栈(为便于和前文普通栈区分,后文将其称为“命名栈”),即在普通栈的基础上,增加一个“名称”属性,该属性使每个栈都具有一个可供识别的名称,该栈类型的定义及接口声明如下:
stack_named.h文件
//微信公众号:嵌入式系统
#ifndef__STACK_NAMED_H
#define__STACK_NAMED_H
#include"stack.h"/*包含基类头文件*/
structstack_named
{
structstacksuper;/*基类(超类)*/
constchar*p_name;/*栈名*/
};
/*初始化*/
intstack_named_init(structstack_named*p_stack,int*p_buf,intsize,constchar*p_name);
/*设置名称*/
intstack_named_set(structstack_named*p_stack,constchar*p_name);
/*获取名称*/
constchar*stack_named_get(structstack_named*p_stack);
/*解初始化*/
intstack_named_deinit(structstack_named*p_stack);
#endif
stack_named.c文件
//微信公众号:嵌入式系统
#include"stack_named.h"
intstack_named_init(structstack_named*p_stack,int*p_buf,intsize,constchar*p_name)
{
stack_init(&p_stack->super,p_buf,size);/*初始化基类*/
p_stack->p_name=p_name;/*初始化子类成员*/
return0;
}
intstack_named_set(structstack_named*p_stack,constchar*p_name)
{
p_stack->p_name=p_name;
return0;
}
constchar*stack_named_get(structstack_named*p_stack)
{
returnp_stack->p_name;
}
intstack_named_deinit(structstack_named*p_stack)
{
returnstack_deinit(&p_stack->super);/*解初始化基类*/
}
实现“命名栈”时,除初始化函数和解初始化函数外,仅为新增的属性p_name 提供了设置和获取方法,栈的核心逻辑相关函数(入栈、出栈)无需重复实现,入栈和出栈方法作为“命名栈”父类的方法,可以被复用。使用“命名栈”的应用程序范例如下:
//微信公众号:嵌入式系统
#include"stack_named.h"
#include"stdio.h"
intmain()
{
intval;
intbuf[20];
structstack_namedstack_named;
structstack_named*p_stack_named=&stack_named;
stack_named_init(p_stack_named,buf,20,"chengj");
printf("Thestacknameis%s!
",stack_named_get(p_stack_named));
//依次压入数据:2、4、5、8
stack_push((structstack*)p_stack_named,2);//强制栈类型转换
stack_push((structstack*)p_stack_named,4);
stack_push((structstack*)p_stack_named,5);
stack_push((structstack*)p_stack_named,8);
//依次弹出各个数据,并打印
stack_pop((structstack*)p_stack_named,&val);//强制栈类型转换
printf("%d",val);
stack_pop((structstack*)p_stack_named,&val);
printf("%d",val);
stack_pop((structstack*)p_stack_named,&val);
printf("%d",val);
stack_pop((structstack*)p_stack_named,&val);
printf("%d",val);
stack_named_deinit(p_stack_named);
return0;
}
程序中,因为父类(struct stack)和子类(struct stack_named)对应的类型并不相同,所以当父类方法(stack_push()、stack_pop())作用于子类对象(stack_named)时,为了避免编译器输出“类型不匹配”的警告,必须对类型进行强制转换。
在 C 语言中,大量的使用类型强制转换存在一定的风险,如两个类之间没有继承关系,使用强制转换将屏蔽编译器输出的警告信息,导致这类错误在编译阶段无法发现。为了避免使用强制类型转换,可以多做一步操作,从子类中取出父类的地址进行传递,保证参数类型一致:
stack_push((structstack*)p_stack_named,2); //改为 stack_push(&p_stack_named->super,2);
但无论使用哪种方法,看起来都不是很完美。这类问题的存在主要是因为 C语言并非真正的面向对象编程语言,使用 C 语言实现面向对象编程时,需要使用到一些看似“投机取巧”的手段。在真正的面向对象编程语言中,编译器可以识别继承关系,无需任何强制转换语句,父类的方法可以直接作用于子类。
3.2 初始化函数
回顾前面命名栈初始化函数:
intstack_named_init(structstack_named*p_stack,int*p_buf,intsize,constchar*p_name)
{
stack_init(&p_stack->super,p_buf,size);/*初始化基类*/
p_stack->p_name=p_name;/*初始化子类成员*/
return0;
}
先调用了父类的初始化函数(stack_init()),再初始化命名栈特有的 p_name 属性。这里指出了一个隐含的规则:先初始化基类的成员,再初始化派生类特有的成员。该规则与面向对象编程语言中构造函数的调用顺序是一致的:在建立一个对象时,首先调用基类的构造函数,然后再调用派生类的构造函数。
3.3 解初始化函数
解初始化的顺序与初始化的顺序是恰好相反的,应先对派生类中特有的数据“解初始化”,再对基类作解初始化操作。解初始化函数的实现详见程序如下:
intstack_deinit(structstack*p_stack)
{
p_stack->top=0;
return0;
}
intstack_named_deinit(structstack_named*p_stack)
{
p_stack->p_name=NULL;
returnstack_deinit(&p_stack->super);/*解初始化基类在后*/
}
3.4 最少知识原则
所谓 “最少知识原则”就是,对使用者而言,不管类的内部如何,只调用提供的方法,其他的一概不管。(微信公众号【嵌入式系统】更多编码原则可以参考《嵌入式软件设计原则随想》)显然前面的“命名栈”并非如此,对于命名栈的使用者,其必须知道命名栈与普通栈之间的继承关系,进而才可以正确的使用普通栈的入栈方法,操作命名栈,例如:
stack_push((structstack*)p_stack_named,2);//类型转换关系
这对用户来说并不友好,因为其使用的是“命名栈”类(stack_named.h),却还要关心“普通栈”类(stack.h)。为满足“最少知识原则”,命名栈也可以提供入栈和出栈方法,使用户仅需关心命名栈的公共接口就可以完成命名栈的所有操作。
stack_named.h文件
#ifndef__STACK_NAMED_H
#define__STACK_NAMED_H
#include"stack.h"
/*包含基类头文件*/
structstack_named
{
structstacksuper;/*基类(超类)*/
constchar*p_name;/*栈名*/
};
/*初始化*/
intstack_named_init(structstack_named*p_stack,int*p_buf,intsize,constchar*p_name);
/*设置名称*/
intstack_named_set(structstack_named*p_stack,constchar*p_name);
/*获取名称*/
constchar*stack_named_get(structstack_named*p_stack);
//微信公众号:嵌入式系统
staticinlineintstack_named_push(structstack_named*p_stack,intval)
{
returnstack_push(&p_stack->super,val);
}
staticinlineintstack_named_pop(structstack_named*p_stack,int*p_val)
{
returnstack_pop(&p_stack->super,p_val);
}
/*解初始化*/
intstack_named_deinit(structstack_named*p_stack);
#endif
头文件中增加了两个方法:stack_named_push()和 stack_named_pop(),由于这两个函数非常简单,只是调用了其父类中相应的方法,仅一行代码,因而使用了内联函数的形式,如此可以优化代码大小和执行速度。经过简单的包装后,用户使用的所有方法都是作用于“命名栈”对象的,无需再使用类型强制转换等特殊的方法。更新后的“命名栈”使用范例片段如下:
//压入数据
stack_named_push(p_stack_named,2);
//弹出数据并打印
stack_named_pop(p_stack_named,&val);printf("%d",val);
从用户角度看,包装后的“命名栈”对用户来讲更加友好(无需类型强制转换)。但在实际开发过程中,若所有继承关系都再次封装一遍会显得累赘。因此,只对用户开放的类才需要这样做,如果某些类无需对用户开放,仅在内部使用,则可以酌情省略包装过程。
4 多态
多态字面含义就是具有“多种形式”。从调用者的角度看对象,会发现它们非常相似,但内部处理实际上却各不相同。换句话说,各对象虽然内部处理不同,但对于使用者(调用者)来讲,它们却是相同的。
4.1 学生的“自我介绍”
在前面提到的学生类,包含姓名、学号、性别、身高、体重等属性,并对外提供了一个“自我介绍”方法。
voidstudent_self_introduction(structstudent*p_this)
{
printf("Hi!Mynameis%s,I'ma%s.Myschoolnumberis%d.Myheightis%fcmandweightis%fkg",
p_this->name,
(p_this->sex=='M')?"boy":"girl",
p_this->id,
p_this->height,
p_this->weight);
}
假设一个场景,开学第一课所有同学依次作一个简单的自我介绍,调用所有同学的自我介绍方法即可,范例程序如下:
voidfirst_class(structstudent*p_students,intnum) { inti; for(i=0;i< num; i++) { student_self_introduction(&p_students[i]); } }
调用该函数前,需要将所有学生对象创建好,并存于一个数组中,假定一个班级有 50个学生,则调用示意代码如下:
intmain()
{
structstudentstudent[50];
/*根据每个学生的信息,依次创建各个学生对象*/
student_init(&student[0],"zhangsan",2024001,'M',173,60);
student_init(&student[1],"lisi",2024002,'F',168,65);
//...
/*上第一节课*/
first_class(student,50);
}
上面的实现代码,假定了学生的“自我介绍”格式是完全相同的,都是将个人信息陈述一遍,显然,这样的自我介绍无法体现每个学生的个性和差异。例如,一个名叫张三的学生,其期望这样介绍自己:
“亲爱的老师,同学们!我叫张三,来自湖北仙桃,是一个自信开朗,积极向上的人,我有着广泛的兴趣爱好,喜欢打篮球、看书、下棋、听音乐……”
每个学生自我介绍的内容并不期望千篇一律。若不基于多态的思想,最简单粗暴的方式是每个学生都提供一个自我介绍方法,例如 student_zhangsan_introduction()。这种情况下每个学生提供的方法都不相同(函数名不同),根本无法统一调用,此时,第一节课的调用将会大改,需要依次调用每个学生提供的不同的自我介绍方法,例如:
voidfirst_class()
{
student_zhangsan_introduction(&zhangshan);//张三自我介绍
student_lisi_introduction(&lisi);//李四自我介绍
//….
}
无法使用同样的调用形式(函数)完成不同对象的“自我介绍”。对于调用者来讲,需要关注每个对象提供的特殊方法,复杂度将提升。
使用多态的思想即可很好的解决这个问题,进而保证 firstt_class()的内容不变,虽然每个对象方法的实现不同,但可以使用同样的形式调用它。在 C 语言中,函数指针就是解决这个问题的“利器”。
函数指针的原型决定了调用方法,例如定义函数指针:
int(*student_self_introduction)(structstudent*p_student);
无论该函数指针指向何处,都表示该函数指针指向的是 int 类型返回值,具有一个*p_student 参数的函数,其调用形式如下:
student_self_introduction(p_student);
函数指针的指向代表了函数的实现,指向不同的函数就代表了不同的实现。基于此,为了使每个学生对象可以有自己独特的介绍方式,在学生类的定义中,可以不实现自我介绍方法,但可以通过函数指针约定自我介绍方法的调用形式。更新学生类的定义:
student.h文件```
```c
//微信公众号:嵌入式系统
#ifndef__STUDENT_H
#define__STUDENT_H
structstudent
{
int(*student_self_introduction)(structstudent*p_student);/*新增个性化自我介绍*/
charname[10];/*姓名(假定最长10字符)*/
unsignedintid;/*学号*/
charsex;/*性别:'M',男;'F',女*/
floatheight;/*身高*/
floatweight;/*体重*/
};
intstudent_init(structstudent*p_student,
char*p_name,
unsignedintid,
charsex,
floatheight,
floatweight,
int(*student_self_introduction)(structstudent*));
/*学生类提供的自我介绍方法*/
staticinlineintstudent_self_introduction(structstudent*p_student)
{
returnp_student->student_self_introduction(p_student);
}
#endif
此时,对于外界来讲,学生类“自我介绍方法”的调用形式并未发生任何改变,函数原型还是一样的(由于只有一行代码,因而以内联函数的形式存放到了头文件中)。基于此,“第一节课的内容”可以保持完全不变(for循环调用全部)。在这种方式下,每个对象在初始化时,需要指定自己特殊的自我介绍方,例如张三对象的创建过程为:
intstudent_zhangsan_introduction(structstudent*p_student)
{
constchar*str="亲爱的老师,同学们!我叫张三,来自湖北仙桃,是一个自信开朗,积极向上的人,我有着广泛的兴趣爱好,喜欢打篮球、看书、下棋、听音乐……";
printf("%s
",str);
return0;
}
intmain()
{
structstudentstudent[50];
/*根据每个学生的信息,依次创建各个学生对象*/
student_init(&student[0],"zhangsan",2024001,'M',173,60,student_zhangsan_introduction);
//...
/*上第一节课*/
first_class(student,50);
}
多态的核心是:对于上层调用者,不同的对象可以使用完全相同的操作方法,但是每个对象可以有各自不同的实现方式。多态是面向对象编程非常重要的特性,C 语言依赖指针实现多态。
很多设计模式或硬件多型号适配都是基于这个基础,可以参考《嵌入式软件的设计模式(上)》)。
4.2 I/O 设备驱动
C 程序使用 printf()打印日志信息,在 PC 上运行时,日志信息可能输出到控制台,而在嵌入式系统中,信息可能通过某个串口输出。printf()函数的解释是输出信息至 STDOUT(标准输出)。显然printf()函数就具有多态性,对于用户来讲,其调用形式是确定的,但内部具体输出信息到哪里,却会随着 STDOUT 的不同而不同。
在一些操作系统中(如Linux),硬件设备(例串口、ADC 等)的操作方法都和文件操作方法类似(一切皆文件),都可以通过 open()、close()、read()、write()等几个标准函数进行操作。为统一 I/O 设备的使用方法,要求每个 I/O 设备都提供 open、close、read、write 这几个标准函数的实现,即每个 I/O设备的驱动程序,对这些标准函数的实现在函数调用上必须保持一致。这本质上就是一个多态问题,即以同样的方法使用不同的 I/O 设备。
通过函数指针解决这个问题,首先定义file_ops结构体,包含了相对应的函数指针,指向I/O 设备针对操作的实现函数。
file_ops.h文件
//微信公众号:嵌入式系统 //代码片段只是原理性展示 structfile_ops { void(*open)(char*name,intmode); void(*close)(); int(*read)(); void(*write)(); };
对于 I/O设备,其驱动程序提供这 4个函数的实现,并将 file_ops结构体的函数指针指向对应的函数。
#include"file_ops.h"
staticvoidopen(char*name,intmode)
{
//...
}
staticvoidclose()
{
//...
}
staticintread()
{
//...
}
staticvoidwrite()
{
//...
}
structfile_opsmy_console={open,close,read,write};
所有的函数都使用 static修饰符,避免与外部的函数产生命名冲突。对于该设备,仅对外提供了一个可以使用的 file_ops 对象 my_console。
上面展示了设备 I/O 的一般管理方法,其中的编程方法或技巧正是面向对象编程中多态的基础,也再一次展现了函数指针在多态中的重要地位,多态可以视为函数指针的一种典型应用。(微信公众号【嵌入式系统】类似使用是Linux设备驱动的基础)。
4.3 带检查功能的栈
前面范例实现了栈的核心逻辑(入栈和出栈),假设现在增加需求,实现“带检查功能的栈”,即在数据入栈之前,必须进行特定的检查,“检查通过”后才能压人栈中。检查方式有多种:
范围检查:必须在特定的范围之内,比如1 ~ 9,才视为检查通过; 奇偶检查:必须是奇数或者偶数,才视为检查通过; 变化检查:值必须增加(比上一次的值大),才视为检查通过。
4.3.1 基于继承实现“带范围检查功能”的栈
先不考虑多种检查方式,仅实现范围检查。参照“命名栈”的实现,使用继承方式,在普通栈的基础上实现一个新类,范例程序如下:
stack_with_range_check.h带范围检查的栈
#ifndef__STACK_WITH_RANGE_CHECK_H
#define__STACK_WITH_RANGE_CHECK_H
#include"stack.h"/*包含基类头文件*/
structstack_with_range_check
{
structstacksuper;/*基类(超类)*/
intmin;/*最小值*/
intmax;/*最大值*/
};
intstack_with_range_check_init(structstack_with_range_check*p_stack,
int*p_buf,
intsize,
intmin,intmax);
/*入栈*/
intstack_with_range_check_push(structstack_with_range_check*p_stack,intval);
/*出栈*/
intstack_with_range_check_pop(structstack_with_range_check*p_stack,int*p_val);
#endif
带范围检查的栈 C 文件 stack_with_range_check.c
#include"stack_with_range_check.h"
intstack_with_range_check_init(structstack_with_range_check*p_stack,
int*p_buf,
intsize,
intmin,intmax)
{
/*初始化基类*/
stack_init(&p_stack->super,p_buf,size);
/*初始化子类成员*/
p_stack->min=min;
p_stack->max=max;
return0;
}
intstack_with_range_check_push(structstack_with_range_check*p_stack,intval)
{
if((val>=p_stack->min)&&(val<= p_stack->max))//差异点
{
returnstack_push(&p_stack->super,val);
}
return-1;
}
intstack_with_range_check_pop(structstack_with_range_check*p_stack,int*p_val)
{
returnstack_pop(&p_stack->super,p_val);
}
为了接口的简洁性,没有再展示解初始化等函数的定义。新增入栈时作检查,出栈和普通栈是完全相同的,但基于最小知识原则也封装了一个 pop 接口,使该类的用户完全不需要关心普通栈。
依照这个方法,可以实现其它检查方式的栈。核心是实现带检查功能的入栈函数,因而仅简单展示另外两种检查方式下入栈函数的实现,分别如下:
//奇偶检查入栈函数
intstack_with_oddeven_check_push(structstack_with_oddeven_check*p_stack,intval)
{
if(((p_stack->iseven)&&((val%2)==0))||((!p_stack->iseven)&&((val%2)!=0)))
{
returnstack_push(&p_stack->super,val);//检查通过:偶校验且为偶数,或奇校验且为奇数
}
return-1;
}
//变化检查入栈函数
intstack_with_change_check_push(structstack_with_change_check*p_stack,intval)
{
if(p_stack->pre_value< val)
{
p_stack->pre_value=val;
returnstack_push(&p_stack->super,val);//检查通过:本次入栈值大于上一次的值
}
return-1;
}
由此可见,这种实现方式存在一定的缺陷,不同检查方法对应的入栈函数不相同,对于用户来讲,使用不同的检查功能,就必须调用不同的入栈函数。即操作不同的栈使用不同的接口。但观察几个入栈函数,其入栈方法类似,示意代码如下:
intstack_XXX_push(structstack_XXX*p_stack,intval)
{
if(检查通过)//不同栈的差异仅是检测条件不同
{
returnstack_push(&p_stack->super,val);
}
return-1;
}
可使用多态思想,将“检查”函数的调用形式标准化编写一个通用的、与具体检查方式无关的入栈函数。
4.3.2 基于多态实现通用的“带检查功能的栈”
使用函数指针表示“检查功能”,指向不同的检查函数。可以定义一个包含函数指针的类:
structstack_with_validate
{
structstacksuper;/*基类(超类)*/
int(*validate)(structstack_with_validate*p_this,intval);/*检查函数*/
};
和其它普通方法一样,类中抽象方法(函数指针)的第一个成员同样是指向该类对象的指针。此时,数据入栈前的检查工作交给 validate 指针所指向的函数实现。假定其指向的函数在检查数据时,返回 0 表示检查通过可入栈,其它值表示检查未通过。完整的带检查功能的栈实现范例如下:
带检查功能的栈 H 文件(stack_with_validate.h)
#ifndef__STACK_WITH_VALIDATE_H
#define__STACK_WITH_VALIDATE_H
#include"stack.h"/*包含基类头文件*/
structstack_with_validate
{
structstacksuper;/*基类(超类)*/
int(*validate)(structstack_with_validate*p_this,intval);/*检查函数*/
};
intstack_with_validate_init(structstack_with_validate*p_stack,
int*p_buf,
intsize,
int(*validate)(structstack_with_validate*,int));
/*入栈*/
intstack_with_validate_push(structstack_with_validate*p_stack,intval);
/*出栈*/
intstack_with_validate_pop(structstack_with_validate*p_stack,int*p_val);
#endif
带检查功能的栈 C 文件(stack_with_validate.c)
#include"stack_with_validate.h"
#include"stdio.h"
intstack_with_validate_init(structstack_with_validate*p_stack,
int*p_buf,
intsize,
int(*validate)(structstack_with_validate*,int))
{
/*初始化基类*/
stack_init(&p_stack->super,p_buf,size);
p_stack->validate=validate;//检查条件,上层说了算
return0;
}
intstack_with_validate_push(structstack_with_validate*p_stack,intval)
{
if((p_stack->validate==NULL)||
((p_stack->validate!=NULL)&&(p_stack->validate(p_stack,val)==0)))
{
returnstack_push(&p_stack->super,val);
}
return-1;
}
intstack_with_validate_pop(structstack_with_validate*p_stack,int*p_val)
{
returnstack_pop(&p_stack->super,p_val);
}
带某种检查功能的栈,重点是实现其中的 validate 方法。基于带检查的栈,实现带范围检查的栈,程序详见如下:
带范围检查的栈 H 文件更新(stack_with_range_check.h)
#ifndef__STACK_WITH_RANGE_CHECK_H
#define__STACK_WITH_RANGE_CHECK_H
#include"stack_with_validate.h"/*包含基类头文件*/
structstack_with_range_check
{
structstack_with_validatesuper;/*基类(超类)*/
intmin;/*最小值*/
intmax;/*最大值*/
};
structstack_with_validate*stack_with_range_check_init(structstack_with_range_check*p_stack,
int*p_buf,
intsize,
intmin,
intmax);
#endif
带范围检查的栈 C 文件更新(stack_with_range_check.c)
#include"stack_with_range_check.h"
staticint_validate(structstack_with_validate*p_this,intval)
{
structstack_with_range_check*p_stack=(structstack_with_range_check*)p_this;
if((val>=p_stack->min)&&(val<= p_stack->max))
{
return0;/*检查通过*/
}
return-1;
}
structstack_with_validate*stack_with_range_check_init(structstack_with_range_check*p_stack,
int*p_buf,
intsize,
intmin,
intmax)
{
/*初始化基类*/
stack_with_validate_init(&p_stack->super,p_buf,size,_validate);
/*初始化子类成员*/
p_stack->min=min;
p_stack->max=max;
return0;
}
带范围检查的栈,主要目的就是实现“检查功能”对应的函数:_validate,并将其作为 validate 函数指针(抽象方法)的值。
在面向对象编程中,包含抽象方法的类通常称之为抽象类,抽象类不能直接实例化(因为其还有方法未实现),抽象类只能被继承,且由子类实现其中定义的抽象方法。在 UML 类图中,抽象类的类名和其中的抽象方法均使用斜体表示,普通栈、带检查功能的栈和带范围检查的栈,它们之间的关系详见图。
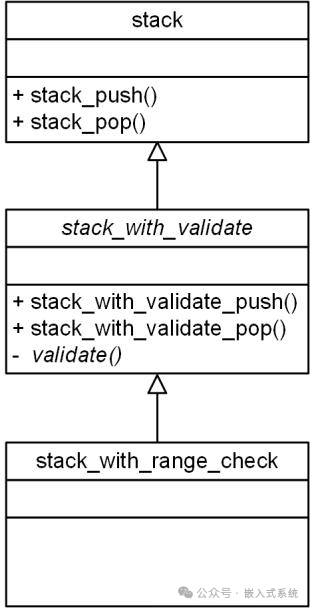
带范围检查的栈,其主要作用是实现其父类中定义的抽象方法,进而创建一个真正的“带检查功能”的栈对象(此时的抽象方法已实现),该对象即可提交给外部使用。带范围检查的栈并没有其他特殊的方法,因而在其初始化完成后,通过初始化函数的返回值向外界提供了一个“带检查功能”的栈对象,后续用户即可使用 stack_with_validate.h 文件中的push 和 pop 方法操作该对象。
带范围检查的栈使用范例如下:
//微信公众号:嵌入式系统
#include"stack_with_range_check.h"
#include"stdio.h"
intmain()
{
intval;
intbuf[20];
inti;
inttest_data[5]={2,4,5,3,10};
structstack_with_range_checkstack;
structstack_with_validate*p_stack=stack_with_range_check_init(&stack,buf,20,1,9);
for(i=0;i< 5; i++)
{
if(stack_with_validate_push(p_stack, test_data[i]) != 0)
{
printf("The data %d push failed!
", test_data[i]);
}
}
printf("The pop data: ");
while(1) /* 弹出所有数据 */
{
if(stack_with_validate_pop(p_stack, &val) == 0)
{
printf("%d ", val);
}
else
{
break;
}
}
return 0;
}
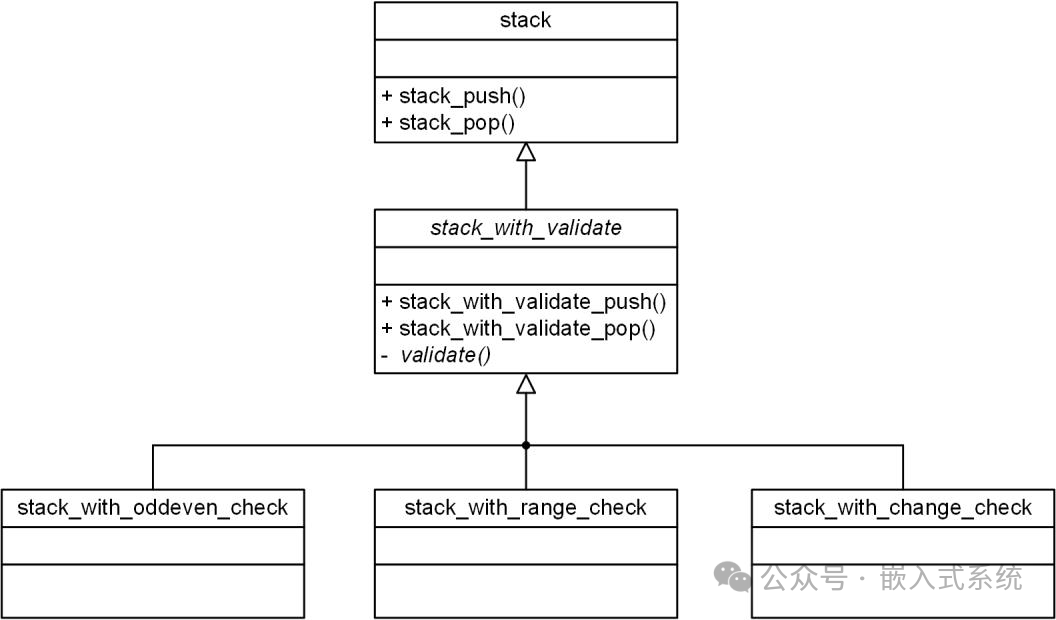
无论何种检查方式,其主要目的都是创建“带检查功能”的栈对象(完成抽象方法的实现)。创建完毕后,对于用户操作方法都是完全相同的 stack_with_validate_push 和 stack_with_validate_pop ,与检查方式无关。为避免赘述,这里不再实现另外两种检查功能的栈,仅展示出他们的类图。
在这里插入图片描述
在一些大型项目中,初始化过程往往和应用程序是分离的(即stack_with_range_check_init 内部封闭不可见),也就是说,对于用户来讲,其仅会获取到一个 struct stack_with_validate *类型的指针,其指向某个“带检查功能的栈”,实际检查什么,用户可能并不关心,应用程序基于该类型指针编程,将使应用程序与具体检查功能无关,即使后续更换为其它检查方式,应用程序也不需要做任何改动。
4.4 抽象分离
如果是硬件资源有限,功能单一或大概率无需扩展的嵌入式软件开发,进行到这基本可以满足需求;如果是复杂应用,且硬件资源充足还可继续优化。
4.4.1 检查功能抽象
前面的实现中,将检查功能视为栈的一种扩展(使用继承),检查逻辑直接在相应的扩展类中实现。这就使检查功能与栈绑定在一起,检查功能的实现无法独立复用。如果要实现一个“带检查功能的队列”,同样是上述的 3 种检查逻辑,期望能够复用检查逻辑相关的代码。显然,由于当前检查逻辑的实现与栈捆绑在一起,无法单独提取出来复用。
检查功能与栈的绑定,主要在“带检查功能的栈”中体现,该类的定义如下:
structstack_with_validate
{
structstacksuper;/*基类(超类)*/
int(*validate)(structstack_with_validate*p_this,intval);/*检查函数*/
};
super 用于继承自普通栈,validate 表示一个抽象的数据检查方法,不同的检查方法,通过该指针所指向的函数体现。由于检查方法validate是该类的一个方法,检查逻辑与栈绑定。为了解绑分离,可以将检查逻辑放到独立的与栈无关的类中,额外定义一个抽象的校验器类,专门表示数据检查逻辑:
structvalidator
{
int(*validate)(structvalidator*p_this,intval);/*检查函数*/
};
虽然该类仅包含 validate 函数指针,但需注意该函数指针类型的变化,其第一个参数为指向校验器的指针,而在“带检查功能的栈”中,其第一个参数是指向“带检查功能的栈”的指针。通过该类的定义,明确的将检查逻辑封装到独立的校验器类中,与栈再无任何关联。不同的检查逻辑,可以在其子类中实现,校验器类和各个子类之间的关系如下:
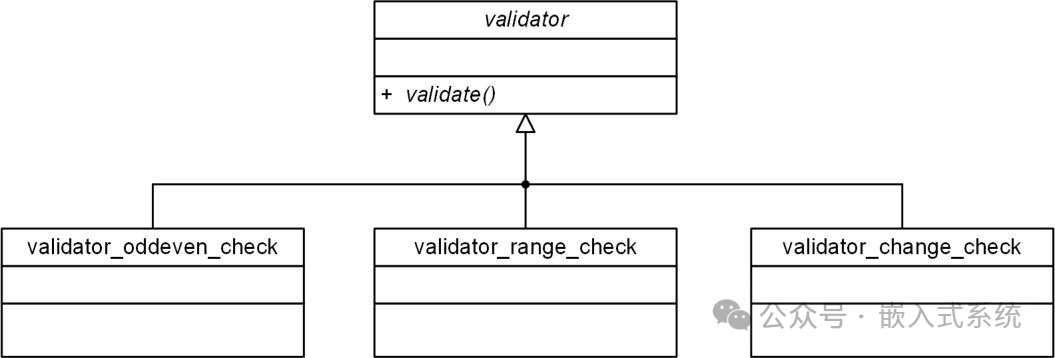
由于校验器类仅包含一个函数指针,因此其只需要在头文件中定义出类即可,程序如下:
校验器类定义(validator.h)
#ifndef__VALIDATOR_H
#define__VALIDATOR_H
structvalidator
{
int(*validate)(structvalidator*p_this,intval);
};
staticinlineintvalidator_init(structvalidator*p_validator,
int(*validate)(structvalidator*,int))
{
p_validator->validate=validate;
return0;
}
staticinlineintvalidator_validate(structvalidator*p_validator,intval)/*校验函数*/
{
if(p_validator->validate==NULL)/*校验函数为空,视为无需校验*/
{
return0;
}
returnp_validator->validate(p_validator,val);
}
#endif
初始化函数负责为 validate 赋值,validator_validate 函数是校验器对外提供的校验函数,在其实现中仅调用了 validate 函数指针指向的函数。由于函数都比较简单,因而直接使用了内联函数的形式进行了定义。接下来以范围校验为例,实现一个范围校验器。
范围校验器 H 文件内容(validator_range_check.h)
#ifndef__VALIDATOR_RANGE_CHECK_H
#define__VALIDATOR_RANGE_CHECK_H
#include"validator.h"
structvalidator_range_check
{
structvalidatorsuper;
intmin;
intmax;
};
structvalidator*validator_range_check_init(structvalidator_range_check*p_validator,intmin,intmax);
#endif
范围校验器 C 文件内容(validator_range_check.c)
//微信公众号:嵌入式系统
#include"validator_range_check.h"
staticint_validate(structvalidator*p_this,intval)
{
structvalidator_range_check*p_stack=(structvalidator_range_check*)p_this;
if((val>=p_stack->min)&&(val<= p_stack->max))
{
return0;/*检查通过*/
}
return-1;
}
structvalidator*validator_range_check_init(structvalidator_range_check*p_validator,intmin,intmax)
{
validator_init(&p_validator->super,_validate);
p_validator->min=min;
p_validator->max=max;
return&p_validator->super;
}
由于 validator_range_check 类仅用于实现 validator 抽象类中定义的抽象方法,其初始化函数可以直接对外返回一个标准的校验器(其中的抽象方法已实现)。按照同样的方法,可以实现validator_oddeven_check 类和 validator_change_check 类。将检查功能从“带检查功能的栈”中分离出来之后,“带检查功能的栈”中就无需再维护检查功能对应的抽象方法。其可以通过依赖的方式使用检查功能,即依赖一个校验器。在类图中,依赖关系可以使用一个虚线箭头表示,箭头指向被依赖的类,示意图如下:
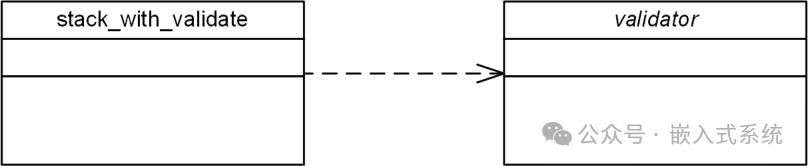
“带检查功能的栈”类定义如下:
structstack_with_validate
{
structstacksuper;/*基类(超类)*/
structvalidator*p_validator;/*依赖的校验器*/
};
与先前相比,其核心变化是由一个 validate 函数指针(指向具体的检查方法)变更为 p_validator 指针(指向抽象的检查方法),变化虽小,但是两种截然不同的设计理念。之前的方式是定义了一个抽象方法,而现在的方式是依赖于一个校验器对象。
基于此更新“带检查功能的栈”类的实现如下:
带检查功能的栈 H 文件更新(stack_with_validate.h)
#ifndef__STACK_WITH_VALIDATE_H
#define__STACK_WITH_VALIDATE_H
#include"stack.h"/*包含基类头文件*/
#include"validator.h"
structstack_with_validate
{
structstacksuper;/*基类(超类)*/
structvalidator*p_validator;
};
intstack_with_validate_init(structstack_with_validate*p_stack,
int*p_buf,
intsize,
structvalidator*p_validator);
intstack_with_validate_push(structstack_with_validate*p_stack,intval);
intstack_with_validate_pop(structstack_with_validate*p_stack,int*p_val);
#endif
带检查功能的栈 C 文件更新(stack_with_validate.c)
//微信公众号:嵌入式系统
#include"stack_with_validate.h"
#include"stdio.h"
intstack_with_validate_init(structstack_with_validate*p_stack,
int*p_buf,
intsize,
structvalidator*p_validator)
{
stack_init(&p_stack->super,p_buf,size);
p_stack->p_validator=p_validator;
return0;
}
intstack_with_validate_push(structstack_with_validate*p_stack,intval)
{
if((p_stack->p_validator==NULL)||(validator_validate(p_stack->p_validator,val)==0))//注意差别
{
returnstack_push(&p_stack->super,val);
}
return-1;
}
intstack_with_validate_pop(structstack_with_validate*p_stack,int*p_val)
{
returnstack_pop(&p_stack->super,p_val);
}
“带检查功能的栈”的应用接口(push 和 pop)并没有发生任何改变,应用程序可以被复用,测试更新后的带检查功能的栈:
#include"stack_with_validate.h"
#include"validator_range_check.h"
#include"stdio.h"
intmain()
{
intbuf[20];
structstack_with_validatestack;
structvalidator_range_checkvalidator_range_check;
/*获取范围检查校验器*/
structvalidator*p_validator=validator_range_check_init(&validator_range_check,1,9);
stack_with_validate_init(&stack,buf,20,p_validator);
stack_validate_application(&stack);//使用和先前继承方式一样,实现忽略
return0;
}
4.4.2 定义抽象栈
定义校验器类后,整个系统实现了两种栈:普通栈和“带检查功能的栈”,无论什么栈,对于用户来讲都是实现入栈和出栈两个核心逻辑。两种栈提供两种入栈和出栈方法。
普通栈提供的方法为:
intstack_push(structstack*p_stack,intval);/*入栈*/ intstack_pop(structstack*p_stack,int*p_val);/*出栈*/
“带检查功能的栈”提供的方法为:
intstack_with_validate_push(structstack_with_validate*p_stack,intval);/*入栈*/ intstack_with_validate_pop(structstack_with_validate*p_stack,int*p_val);/*出栈*/
用户执行入栈和出栈操作,使用不同类的栈,调用的函数不同。通过多态思想,将入栈和出栈定义为抽象方法(函数指针),则可以达到这样的效果:无论使用何种栈,都可以使用相同的方法来实现入栈和出栈。基于此定义抽象栈。
抽象栈类定义(stack.h)
#ifndef__STACK_H
#define__STACK_H
structstack
{
int(*push)(structstack*p_stack,intval);
int(*pop)(structstack*p_stack,int*p_val);
};
staticinlineintstack_init(structstack*p_stack,
int(*push)(structstack*,int),
int(*pop)(structstack*,int*))
{
p_stack->push=push;
p_stack->pop=pop;
}
staticinlineintstack_push(structstack*p_stack,intval)
{
returnp_stack->push(p_stack,val);
}
staticinlineintstack_pop(structstack*p_stack,int*p_val)
{
returnp_stack->pop(p_stack,p_val);
}
#endif
基于抽象栈的定义,使用抽象栈提供的接口实现一个通用的应用程序,该应用程序与底层细节无关,任何栈都可以使用该应用程序进行测试。
基于抽象栈实现的应用程序:
#include"stack.h"
#include"stdio.h"
intstack_application(structstack*p_stack)
{
inti;
intval;
inttest_data[5]={2,4,5,3,10};
for(i=0;i< 5; i++)
{
if(stack_push(p_stack, test_data[i]) != 0)
{
printf("The data %d push failed!
", test_data[i]);
}
}
printf("The pop data: ");
while(1)
{
if(stack_pop(p_stack, &val) == 0)
{
printf("%d", val);
}
else
{
break;
}
}
return 0;
}
先有应用层代码再有底层代码。在实现具体栈之前,就可以开始编写应用程序(微信公众号【嵌入式系统】这就是依赖倒置原则,可参考《嵌入式软件设计原则随想》)。实现普通栈:
普通栈 H 文件内容(stack_normal.h)
#ifndef__STACK_NORMAL_H
#define__STACK_NORMAL_H
#include"stack.h"
structstack_normal
{
structstacksuper;
inttop;/*栈顶*/
int*p_buf;/*栈缓存*/
unsignedintsize;/*栈缓存的大小*/
};
structstack*stack_normal_init(structstack_normal*p_stack,int*p_buf,intsize);
#endif
普通栈 C 文件内容(stack_normal.c)
//微信公众号:嵌入式系统
#include"stack_normal.h"
staticint_push(structstack*p_this,intval)
{
structstack_normal*p_stack=(structstack_normal*)p_this;
if(p_stack->top!=p_stack->size)
{
p_stack->p_buf[p_stack->top++]=val;
return0;
}
return-1;
}
staticint_pop(structstack*p_this,int*p_val)
{
structstack_normal*p_stack=(structstack_normal*)p_this;
if(p_stack->top!=0)
{
*p_val=p_stack->p_buf[--p_stack->top];
return0;
}
return-1;
}
structstack*stack_normal_init(structstack_normal*p_stack,int*p_buf,intsize)
{
p_stack->top=0;
p_stack->size=size;
p_stack->p_buf=p_buf;
stack_init(&p_stack->super,_push,_pop);
return&p_stack->super;
}
基于普通类的实现,测试普通栈类:
#include"stack_normal.h"
intmain()
{
intbuf[20];
structstack_normalstack;
structstack*p_stack=stack_normal_init(&stack,buf,20);
stack_application(p_stack);
return0;
}
“带检查功能的栈”是在普通栈的基础上,增加了检查功能,实现范例程序如下:
带检查功能的栈 H 文件更新(stack_with_validate.h)
#ifndef__STACK_WITH_VALIDATE_H
#define__STACK_WITH_VALIDATE_H
#include"stack.h"/*包含基类头文件*/
#include"validator.h"
structstack_with_validate
{
structstacksuper;/*基类(超类)*/
structstack*p_normal_stack;/*依赖于普通栈的实现*/
structvalidator*p_validator;
};
structstack*stack_with_validate_init(structstack_with_validate*p_stack,
structstack*p_normal_stack,
structvalidator*p_validator);
#endif
检查功能的栈 C 文件更新(stack_with_validate.c)
#include"stack_with_validate.h"
#include"stdio.h"
staticint_push(structstack*p_this,intval)
{
structstack_with_validate*p_stack=(structstack_with_validate*)p_this;
if((p_stack->p_validator==NULL)||(validator_validate(p_stack->p_validator,val)==0))
{
returnstack_push(p_stack->p_normal_stack,val);
}
return-1;
}
staticint_pop(structstack*p_this,int*p_val)
{
structstack_with_validate*p_stack=(structstack_with_validate*)p_this;
returnstack_pop(p_stack->p_normal_stack,p_val);
}
structstack*stack_with_validate_init(structstack_with_validate*p_stack,
structstack*p_normal_stack,
structvalidator*p_validator)
{
stack_init(&p_stack->super,_push,_pop);
p_stack->p_validator=p_validator;
p_stack->p_normal_stack=p_normal_stack;
return&p_stack->super;
}
基于“带检查功能的栈”的实现,测试范例如下:
#include"stack_normal.h"
#include"stack_with_validate.h"
#include"validator_range_check.h"
intmain()
{
intbuf[20];
structstack_normalstack;
structstack_with_validatestack_with_validate;
structvalidator_range_checkvalidator_range_check;
structstack*p_stack_normal=stack_normal_init(&stack,buf,20);
structvalidator*p_validator=validator_range_check_init(&validator_range_check,1,9);
structstack*p_stack=stack_with_validate_init(&stack_with_validate,
p_stack_normal,
p_validator);
stack_application(p_stack);
return0;
}
由此可见,无论底层的各种栈如何实现,对于上层应用来讲,其可以使用同一套接口stack_application操作各种各样不同的栈。
多种多态示例的核心解决方案都是相同的,即:定义抽象方法(函数指针),使上层应用可以使用同一套接口访问不同的对象。从类的角度看,每个类中操作的规约都是相同的,而这些类可以用不同的方式实现这些同名的操作,从而使得拥有相同接口的对象可以在运行时相互替换。
同样的应用程序,可以在多个硬件平台上运行,更换硬件时应用程序无需作任何改动。在嵌入式系统中,相同功能芯片的更新替换,也是多态应用最多的场景,根据硬件差异多态封装,应用层无感使用相同接口。基于多态的思想实现“与硬件无关”的应用程序,还可以衍生出两个概念:抽象接口与依赖倒置,它们的核心都是多态。更多编码原则可参考《嵌入式软件设计原则随想》、《Unix哲学之编程原则》,分层架构《嵌入式软件分层隔离的典范》。
5 小节
学会了屠龙技,但是没有龙,怎么办?有些东西只是一种思维模式,作为日常开发工作中潜移默化的一种偏爱。所以嵌入式软件开发究竟有没对象呢?有但少。
-
编程
+关注
关注
88文章
3606浏览量
93669 -
嵌入式软件
+关注
关注
4文章
240浏览量
26635
原文标题:一文了解嵌入式软件开发的“对象”
文章出处:【微信号:strongerHuang,微信公众号:strongerHuang】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
嵌入式软件开发工具
Eclipse嵌入式软件开发平台

嵌入式软件开发的优势分析
嵌入式软件开发环境

嵌入式软件开发做什么?嵌入式开发培训学哪些





 工商网监
工商网监
评论