 开源与闭源之争:最新的开源模型到底还落后多少?
开源与闭源之争:最新的开源模型到底还落后多少?
一,引言
随着人工智能(AI)技术的迅猛发展,大模型已经成为推动科技进步的重要力量。然而,超大规模模型在带来高性能的同时,也面临着资源消耗大、部署困难等问题。本文将探讨AI大模型未来的发展方向。
开放性一直是人工智能研究领域的常态,促进了该领域的合作。然而,人工智能的快速发展引发了关于发布最强大模型可能带来的后果的担忧。此外,像ChatGPT这样的模型的销售企业有保持模型私有的商业动机。
行业AI实验室以多种方式回应了这些发展:
未发布模型:例如,谷歌DeepMind的Chinchilla模型尚未发布。
结构化访问控制:像GPT-4这样的模型有结构化的访问控制,控制用户如何与模型交互。
有限制的开源模型:Meta的Llama模型的权重可以下载,但使用条款有限制。
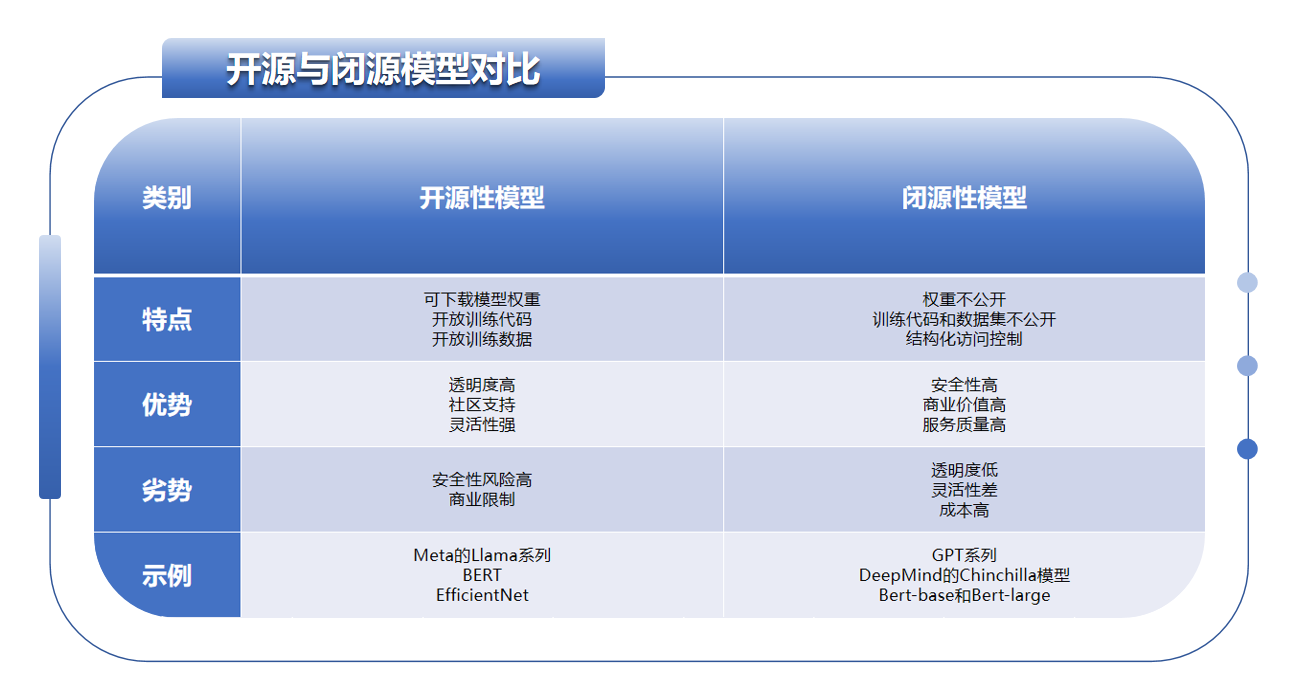
二,开源与闭源模型的对比
1,争议
发布模型、代码和数据集能够促进创新和外部审查,但这也是不可逆的,并且如果模型的安全措施被绕过,就有被滥用的风险。关于这种权衡是否可接受或可避免,存在持续的争论。开源AI的支持者认为,开放性通过开放社区开发的创新和工具,对社会以及模型开发者都有益。甚至有人认为,更多的闭源AI开发者已经被开源社区超越,保持封闭变得毫无意义。
2,二者用户基数对比
ChatGPT(封闭模型):每月大约有3.5亿用户。
Meta AI助手(开放模型):每月有近5亿用户。
3,性能和训练计算方面的差距
为了系统地比较开放和封闭AI模型随时间的能力,我们收集了自2018年以来发布的数百个著名AI模型的权重和训练代码的可访问性数据。以下是主要发现:
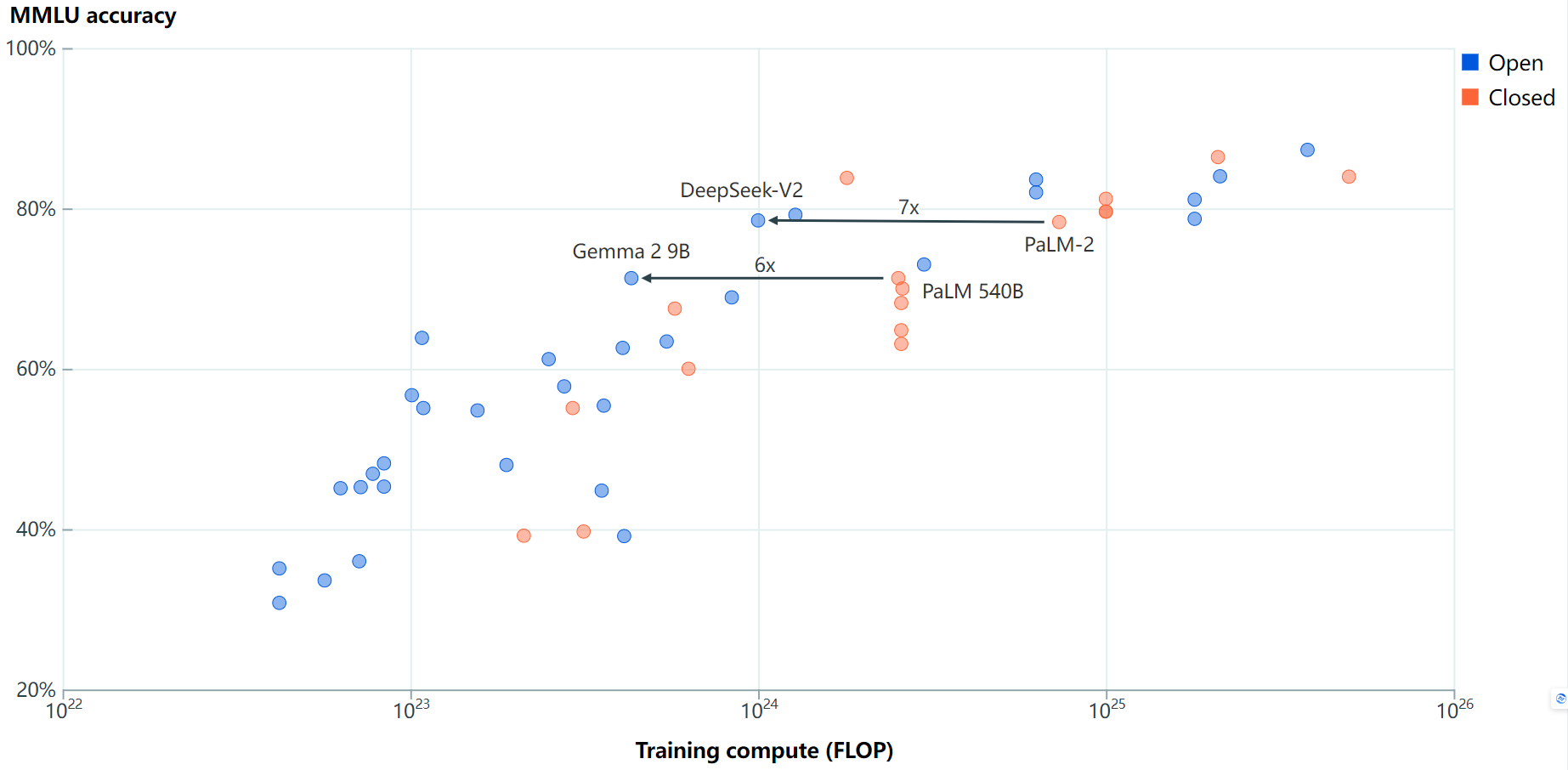
基准性能:
最好的开源大型语言模型(LLMs)在多个基准测试上落后于最好的闭源LLMs5到22个月。Meta的Llama 3.1 405B是最新的一个在多个基准上缩小差距的开源模型。即使不考虑Meta的Llama模型,结果也类似。
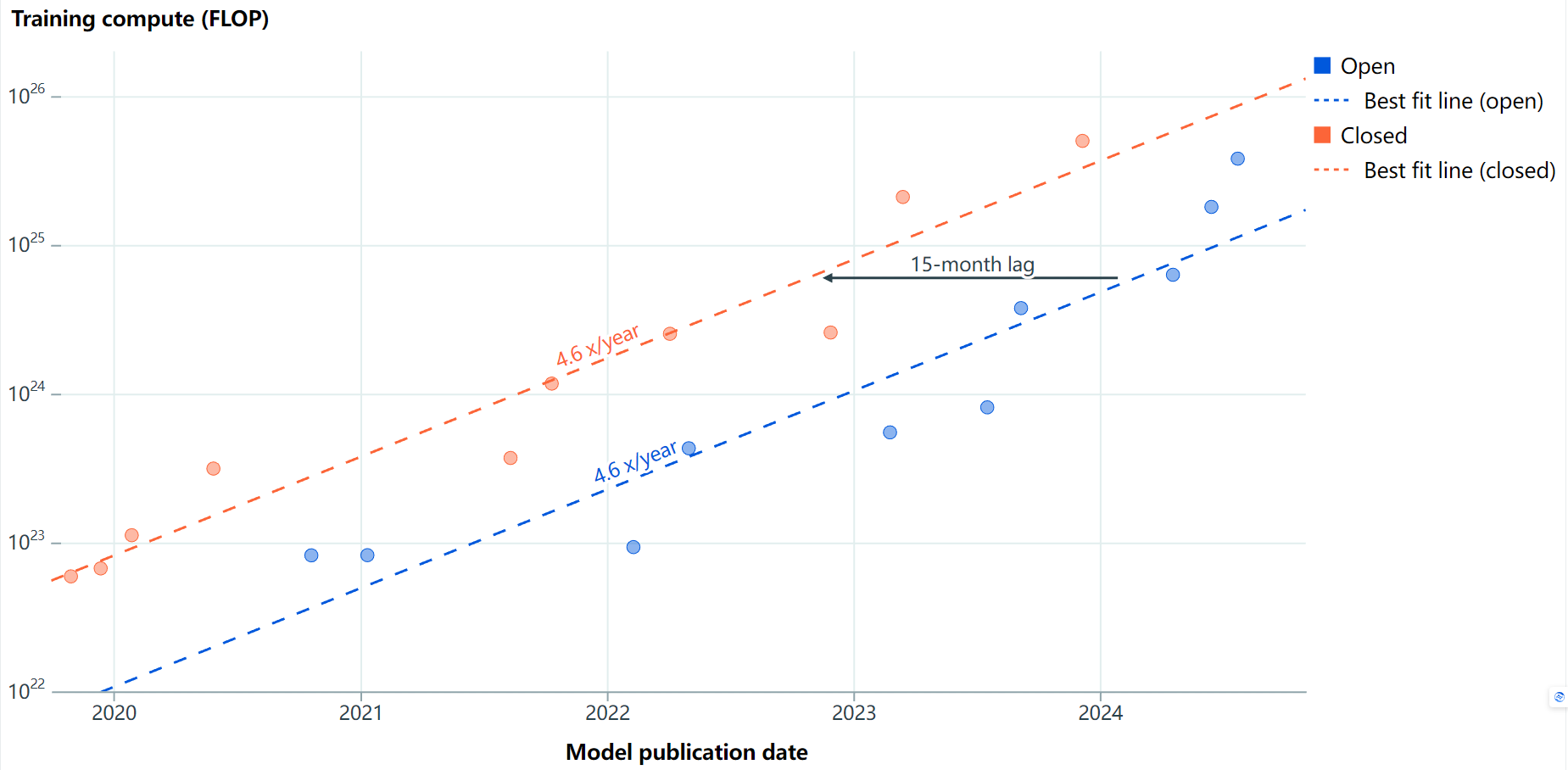
训练计算:
在训练计算方面,最大的开源模型落后于最大的闭源模型大约15个月。
Llama 3.1 405B相对于GPT-4的发布,差距为16个月。由于我们尚未看到比GPT-4规模更大的闭源模型,Llama 3.1 405B已经在缩小训练计算的差距。
训练效率:
尽管开源LLMs在达到与闭源LLMs相似的基准性能后,通常使用较少的训练计算,但新模型通常更高效。因此,我们缺乏同样高效的新闭源模型的数据。
训练数据污染和“为排行榜而学习”也可能导致更高的分数。
三,总结
开源与闭源AI模型之间的竞争和差距反映了AI领域的多样性和复杂性。尽管开源模型在某些方面落后于闭源模型,但它们在促进创新和安全性研究方面具有独特的优势。未来的发展将是结合两者的优点,开发能力优秀、规模适中、边缘友好的AI模型,以满足多样化的应用需求。当然也取决于技术进步、市场需求和政策监管的综合影响。
这两种模型你更看好哪一个呢?欢迎评论留言讨论。
更多精彩内容请关注“算力魔方®”!
审核编辑 黄宇
-
开源
+关注
关注
3文章
3309浏览量
42471 -
模型
+关注
关注
1文章
3226浏览量
48809
发布评论请先 登录
相关推荐
Meta AI高管批评OpenAI闭源模式
阿里通义千问代码模型全系列开源
科技云报到:假开源真噱头?开源大模型和你想的不一样!
Llama 3 与开源AI模型的关系

英伟达将全面转向开源GPU内核模块
浪潮信息发布源2.0-M32开源大模型,模算效率大幅提升
浪潮信息发布“源2.0-M32”开源大模型
智源研究院揭晓大模型测评结果,豆包与百川智能大模型表现优异
HDMI论坛出手,AMD开源HDMI 2.1驱动被拒
机器人基于开源的多模态语言视觉大模型

心寄源 | 2023开源法律热点,Pick您最关心的话题






 工商网监
工商网监
评论