 高效大模型的推理综述
高效大模型的推理综述
大模型由于其在各种任务中的出色表现而引起了广泛的关注。然而,大模型推理的大量计算和内存需求对其在资源受限场景的部署提出了挑战。业内一直在努力开发旨在提高大模型推理效率的技术。本文对现有的关于高效大模型推理的文献进行了全面的综述总结。首先分析了大模型推理效率低下的主要原因,即大模型参数规模、注意力计算操的二次复杂度作和自回归解码方法。然后,引入了一个全面的分类法,将现有优化工作划分为数据级别、模型级别和系统级别的优化。此外,本文还对关键子领域的代表性方法进行了对比实验,以及分析并给出一定的见解。最后,对相关工作进行总结,并对未来的研究方向进行了讨论。
1 Introduction
近年来,大模型受到了学术界和工业界的广泛关注。
LLM领域经历了显著的增长和显著的成就。许多开源llm已经出现,包括gpt-系列(GPT-1, GPT-2和GPT-3), OPT, lama系列(LLaMA , LLaMA 2,BaiChuan 2 ,Vicuna, LongChat), BLOOM, FALCON, GLM和Mtaistral[12],他们用于学术研究和商业落地。大模型的成功源于其处理各种任务的强大能力,如神经语言理解(NLU)、神经语言生成(NLG)、推理和代码生成[15],从而实现了ChatGPT、Copilot和Bing等有影响力的应用程序。越来越多的人认为[16]LMM士的崛起和取得的成就标志着人类向通用人工智能(AGI)迈进了一大步。
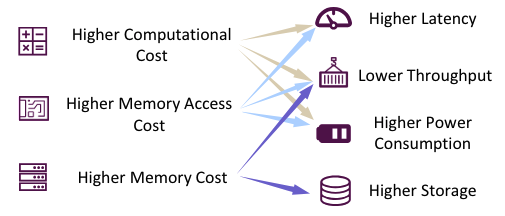
图1:大模型部署挑战
然而,LLM的部署并不总是很顺利。如图1所示,在推理过程中,使用LLM通常需要更高的计算成本,内存访问成本和内存占用。(根本原因分析见Sec. 2.3)在资源受限的场景中,推理效率也会降低(如,延迟,吞吐量,功耗和存储)。这对LLM在终端以及云场景这两方面的应用带来了挑战。例如,巨大的存储需求使得在个人笔记本电脑上部署70B参数量的模型来用于辅助开发是不切实际的。此外,如果将LLM用于每一个搜索引擎请求,那么低吞吐量将带来巨大的成本,从而导致搜索引擎利润的大幅减少。
幸运的是,大量的技术已经被提出来,以实现LLM的有效推理。为了获得对现有研究的全面了解,并激发进一步的研究,文章对当前现有的LLM高效推理工作采用了分级分类和系统总结。具体来说,将现有工作划分组织为数据级别、模型级别和系统级别的优化。此外,文章对关键子领域内的代表性方法进行了实验分析,以巩固知识,提供实际性建议并为未来的研究努力提供指导。
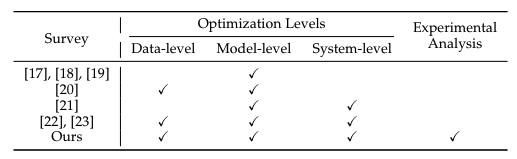
表1:综述对比
目前,综述[17],[18],[19],[20],[21],[22]均涉及LLM领域。这些综述主要集中在LLM效率的不同方面,但提供了进一步改进的机会。Zhu等[17],Park等[18]和Wang等。[19]将综述的重心放在,模型压缩技术上,是模型级别的优化。Ding等[20]将数据和模型架构作为研究重心。Miao等[21]从机器学习系统(MLSys)研究的角度研究LLM的有效推理。相比之下,本文提供了一个更全面的研究范围,在三个层次上解决优化:数据级别、模型级别和系统级别,同时也囊括了最近的研究工作。而Wan等[22]和Xu等[23]也对高效LLM研究进行了全面综述。基于在几个关键的子领域如模型量化和模型server端中进行的实验分析,本文通过整合对比实验,提供实际的见解和建议。如表1所示,展示了各种综述之间的比较。
本文行文结构划分如下:第二章介绍了LLMs的基本概念和知识,并对LLMs推理过程中效率瓶颈进行了详细的分析。第三章展示了本文提出的分类法。第四章到第六章从三个不同优化级别分别对相关工作进行展示讨论。第七章针对几个关键的应用场景进行更广泛的讨论。第八章总结本综述的关键贡献。
2 Preliminaries
2.1 transformer架构的LLM
语言建模作为语言模型的基本功能,包括对单词序列概率进行建模并预测后续单词的概率分布。近年来研究人员发现增加语言模型规模不仅提高了语言建模能力,除了传统的NLP任务之外,还产生了处理更复杂任务的能力[24],这些规模更大的语言模型是被称为大模型(LLMs)。
主流大模型是基于Transformer架构[25]设计的。典型的transformer架构的模型由数个堆叠的transformer block组成。通常,一个transformer block由一个多头自注意力(MHSA)模块,一个前馈神经网络(FFN)和一个LayerNorm(LN)层组成。每个transformer block接收前一个transformer block的输出特征,并将其作为输入,并将特征串行送进每个子模块中,最后输出。特别的是,在第一个transformer block前,需要用一个tokenizer将传统的输入语句转化为token序列,并紧接着使用一个embedding层将token序列转化为输入特征。且一个额外的位置embedding被加入到输入特征中,来对输入token序列的token顺序进行编码。
Transformer架构的核心是自注意力机制,其在多头自注意力(MHSA)模块被使用。MHSA模块对输入进行线性变换,得到了Q,K,V向量,如公式(1)所示:
其中为输入特征,为第个注意力头的变换矩阵。接着自注意力操作被应用于每个()元组并得到第个注意力头的特征,如公式(2)所示:
其中是query(key)的维度。自注意力计算包含矩阵乘法,其计算复杂度是输入长度的二次方。最后,MHSA模块将所有注意力头的特征进行拼接,并对他们做映射矩阵变换,如公式(3)所示:
其中是映射矩阵。自注意力机制可以让模型识别不同输入部分的重要性,而不用去考虑距离,也已就此可以获得输入语句的长距离依赖以及复杂的关系。
FFN作为transformer block的另一个重要模块,被设置在多头自注意力(MHSA)模块之后,且包含两个使用非线性激活函数的。其接收MHSA模块的输出特征如公式(4)所示,进行计算:
其中,和为两个线性层的权重矩阵,为激活函数。
2.2 大模型推理过程
最受欢迎的大模型,如,decoder-only架构的大模型通常采用自回归的方式生成输出语句,自回归的方式是逐token的进行输出。在每一次生成步中,大模型将过去的全部token序列作为输入,包括输入token以及刚刚生成的token,并生成下一个token。随着序列长度的增加,生过文本这一过程的时间成本也显著藏家。为了解决这个问题,一个关键技术,key-value(KV)缓存被提出来,用于加速文本生成。
KV缓存技术,包括在多头自注意(MHSA)块内,存储和复用前面的token对应的key 向量(K)和value向量(V)。此项技术在大模型推理以中得到了广泛的应用,因为其对文本生成延迟实现了巨大的优化。基于此项技术,大模型的推理过程可以划分为两个阶段:
①prefilling阶段:大模型计算并存储原始输入token的KV缓存,并生成第一个输出token,如图2(a)所示
②decoding阶段:大模型利用KV 缓存逐个输出token,并用新生成的token的K,V(键-值)对进行KV缓存更新。
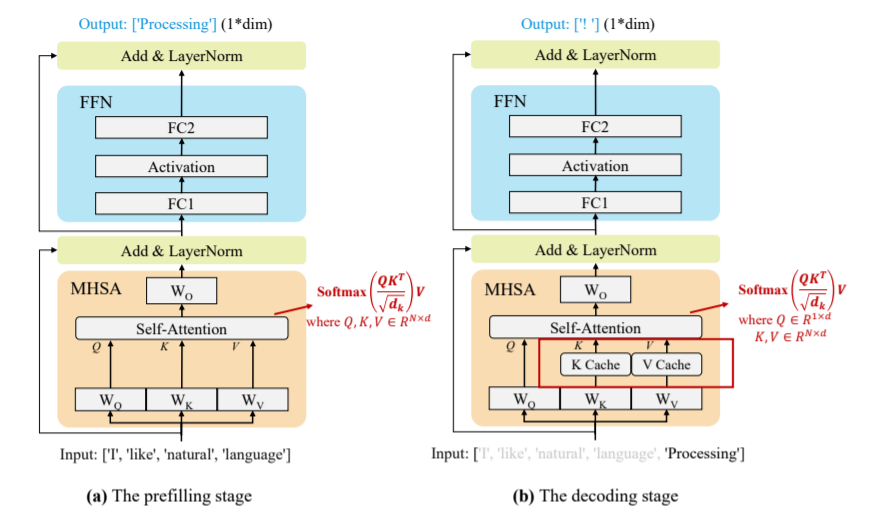
图2:KV缓存技术在大模型推理中应用原理示意图
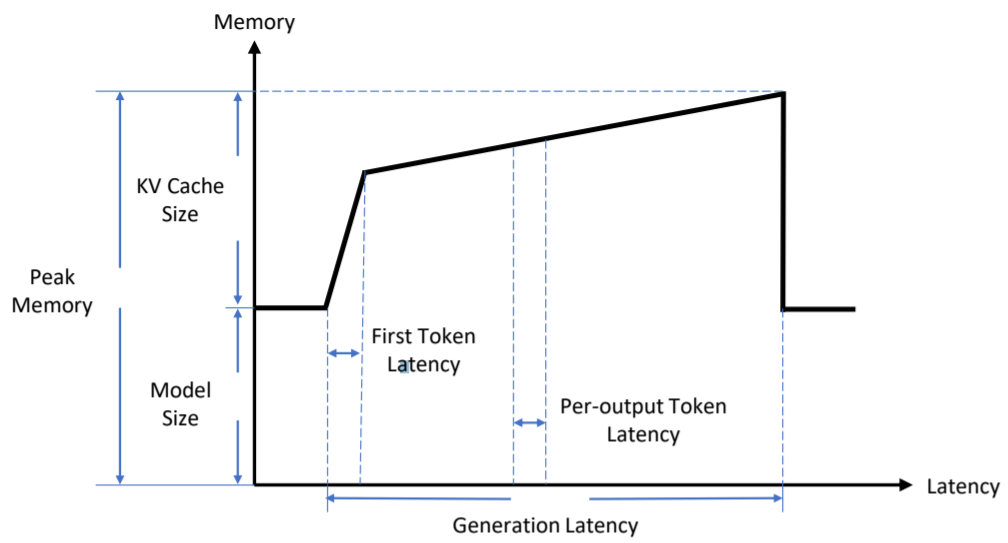
如图3所示,展示了提升推理效率的关键指标。对于横轴Latency(延迟,在预填充(prefilling)阶段,将first token latency记作生成第一个token的时间;在decoding阶段,将per-output token latency记作生成一个token的平均时间。此外,generation latency表示输出整个token序列的时间。对于纵轴Memory(内存),model size被用来表示存储模型权重所需要的内存大小以及KV cache size代表存储存储KV缓存的内存大小。此外,peak memory代表在生成工程中需要占用的最大内存。其大约为model size与KV cache size之和。对模型权重和KV缓存的内存和。除去延迟和内存中,吞吐量(throughput)也是大模型推理服务系统中的一个广泛使用的指标。token throughput表示每秒生成的token数量,request throughput表示每秒完成的请求数。
2.3 推理效率分析
在资源受限的场景中,部署大模型并保持其推理效率以及性能对于工业界和科研及都是巨大的挑战。例如,对有700亿参数量的LLaMA-2-70B进行部署,以FP16数据格式对其权重进行加载需要140GB显存(VRAM),进行推理需要至少6张 RTX 3090Ti GPU(单卡显存24GB)或者2张NVIDIA的A100 GPU(单卡显存80GB)。在推理延迟方面,2张NVIDIA的A100 GPU上生成一个token需要100毫秒。因此,生成一个具有数百个token的序列需要超过10秒。除去内存占用和推理延迟,吞吐量以及能源电量的消耗都需要被考虑。大模型推理过程中,三个重要因素将很大程度上影响上述指标。计算成本(computational cost),内存访问成本(memory access cost)和内存使用(memory usage)。大模型推理低效率的根本原因需要关注三个关键因素:
①Model Size:主流大模型通常包含数十亿甚至万亿的参数。例如,LLaMA-70B模型包括700亿参数,而GPT-3为1750亿参数。在推理过程中,模型大小对计算成本、内存访问成本和内存使用产生了显著影响。
②Attention Operation:如2.1和2.2中所述,prefilling阶段中,自注意操作的计算复杂度为输入长度的2次方,因此输入长度的增加,计算成本、内存访问成本和内存使用都会显著增加。
③Decoding Approach:自回归解码是逐token的进行生成。在每个decoding step,所有模型权重都来自于GPU芯片的片下HBM,导致内存访问成本巨大。此外,KV缓存随着输入长度的增长而增长,可能导致内存分散和不规则内存访问。
3 TAXONOMY
上述部分讲述了影响大模型推理性能的关键因素,如计算成本、内存访问成本和内存使用,并进一步分析了根本原因:Model Size、Attention Operation和Decoding Approach。许多研究从不同的角度对优化推理效率进行了努力。通过回顾和总结这些研究,文章将它们分为三个级别的优化,即:数据级别优化、模型级别优化和系统级别优化(如图4所示):
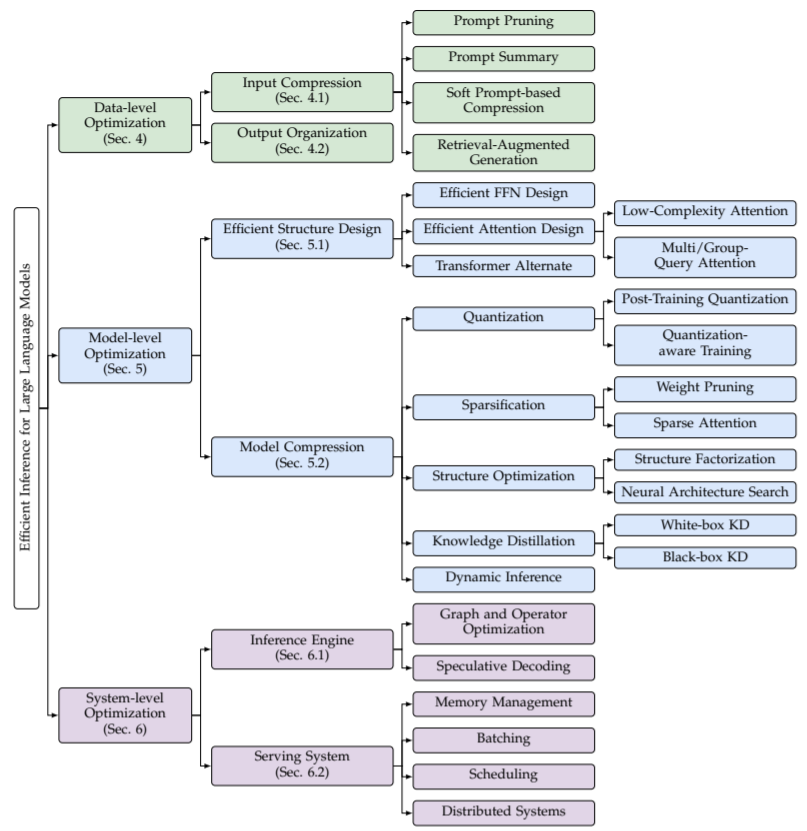
图4:大模型推理性能优化分类
数据级别优化:即通过优化输入prompt(例如,输入压缩)或者更好的组织输出内容(例如,输出组织)。这类优化通常不会改变原来的模型,因此没有高昂的模型训练成本(其中,可能需要对少量的辅助模型进行训练,但与训练大模型的成本相比,这个成本可以被忽略)。
模型级别优化:即在模型推理时,通过设计一个有效的模型结构(如有效的结构设计)或者压缩预训练模型(如模型压缩)来优化推理效率。优化第一种优化通常需要昂贵的预训练或少量的微调来保留或者恢复模型能力的成本,而第二种典型的会给模型性能带来损失。
系统级别优化:即优化推理引擎或者服务系统。推理引擎的优化不需要进行模型训练,服务系统的优化对于模型性能而言更是无损的。此外,文章还在章节6.3中队硬件加速设计进行了简单的介绍。
4.数据级别优化
数据级别的优化今年来的工作可以划分为两类,如优输入压缩或者输出组织。输入压缩技术直接缩短了模型的输入长度来减少推理损失。同时输出组织技术通过组织输出内容的结构来实现批量(并行)推理,此方法可以提升硬件利用率和降低模型的生成延迟。
4.1输入压缩
在大模型的实际应用中,提示词prompt至关重要,许多工作都提出了设计提示词的新方法,它们在实践中均展示出精心设计的提示可以释放大模型的性能。例如,上下文学习(In-Context Learning)建议在prompt中包含多个相关示例,这种方法能够鼓励大模型去进行类比学习。思维链(Chain-of-Thought, COT)技术则是在上下文的示例中加入一系列中间的推理步骤,用于帮助大模型进行复杂的推理。然而,这些提示词上的相关技巧不可避免地会导致提示词更长,这是一个挑战,因为计算成本和内存使用在prefilling期间会二次增长(如2.3节所示)。
为了解决这个问腿输入prompt压缩技术被提出来用于缩短提示词长度且不对大模型的回答质量构成显著性影响。在这一技术方面,相关研究可分为四个方面,如图5所示:提示词裁剪(prompt pruning),提示词总结(prompt summary),基于提示词的软压缩(soft prompt-based compression)和检索增强生成(retrieval augmented generation, RAG)。
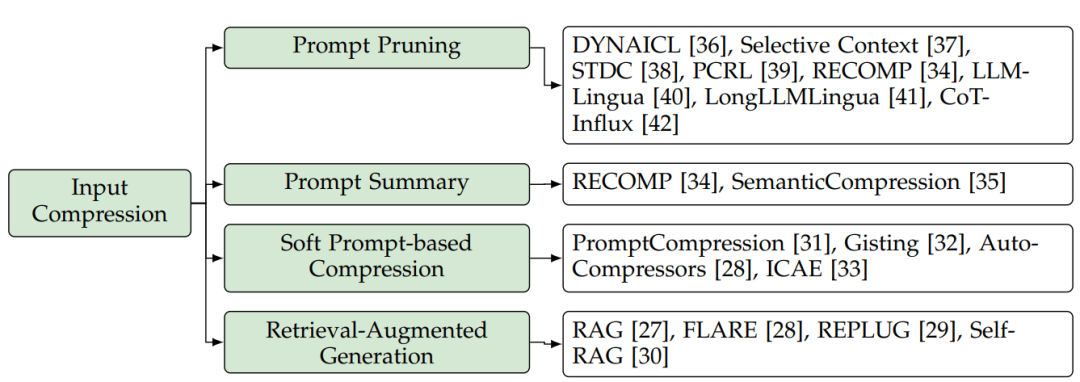
图5:大模型输入压缩方法分类
4.1.1 提示词裁剪(prompt pruning)
提示词裁剪的核心思想是从输入prompt中基于预定义或者学习到的关键性指标中去在线去除不重要的token,语句或者文档。DYNAICL提出对给定输入,动态地确定上下文示例的最优数量,通过一个训练好的基于大模型的controller。Selective Context这篇论文提出将token合并为数个单元,接着使用一个基于self-information指标(如,negative log likelihood)的单元级别地prompt裁剪。STDC论文基于解析树进行提示词裁剪,其迭代地删除在裁剪后导致最小性能下降的短语node。PCRL论文引入了一种基于强化学习的token级别的裁剪方案。PCRL背后的核心思想是通过将忠实度和压缩比组合到奖励函数中来训练一个策略大模型。忠实度是通过计算经过裁剪后的输出提示符和原始提示词之间的相似度来衡量的。RECOMP方法实现了一种句子级别裁剪策略来压缩用于检索增强语言模型(Retrieval-Augmented Language Models, RALMs)的提示。该方法包括使用预训练的encoder将输入问题和文档编码为latent embedding。然后,它根据文档embedding与问题embedding的相似度决定要去除哪些文档。LLMLingua引入了一种粗到细的剪枝方案,用于prompt压缩。最初,它执行示范级别的裁剪,然后根据困惑度执行token级别的裁剪。为了提高性能,LLMLingua提出了一个预算控制器,在提示词的不同部分之间动态分配裁剪预算。此外,它利用迭代式的token级的压缩算法来解决由条件独立性假设引入的不准确性。LLMLingua还采用了一种分布对齐策略,将目标大模型的输出分布与用于困惑度计算的较小大模型进行对齐。LongLLMLingua[41]在LLMLingua的基础上进行了一些加强:(1)它利用以输入问题为条件的困惑度作为提示词裁剪的指标。(2)它为不同的演示分配不同的修剪比例,并根据其指标值在最终提示词内重新排序。(3)基于响应恢复原始内容。CoT-Influx引入了一种使用强化学习对思维链(CoT)提示词进行粗到细粒度裁剪的方法。具体来说,它会先裁剪去除不重要的示例,然后在剩下的示例中继续删除不重要的token。
4.1.2 提示词总结(prompt summary)
提示词总结的核心思想是在保持相似的语义信息的前提下,将原有提示词浓缩为更短的总结。这些技术还可以作为提示词的在线压缩方法。与前面提到的保留未裁剪标记的提示词裁剪技术不同,这一行方法将整个提示符转换为总结。RECOMP[34]引入了一个抽象压缩器(Abstractive Compressor),其将输入问题和检索到的文档作为输入,生成一个简洁的摘要。具体来说,它从大规模的大模型中提取轻量级压缩器来进行总结工作。SemanticCompression提出了一种语义压缩方法。它首先将文本分解成句子。然后,它根据主题将句子分组,然后总结每组中的句子。
4.1.3 基于提示词的软压缩(Soft Prompt-based Compression)
这种压缩技术的核心思想是设计一个比原始提示词短得多的软提示词,作为大模型的输入。软提示词被定义为一系列可学习的连续token。有些技术对固定前缀的提示词(如系统提示词、特定任务提示词)采用脱机压缩。例如,PromptCompression训练软提示来模拟预定的系统提示词。该方法包括在输入token之前添加几个软token,并允许在反向传播期间对这些软token进行调整。在对提示数据集进行微调之后,软token序列充当软提示词。Gisting引入了一种方法,使用前缀词调优将特定任务的提示词压缩为一组简洁的gist token。鉴于特定任务的提示会因任务而异,前缀词调优将针对每个任务单独使用。为了提高效率,Gisting进一步引入了一种元学习方法,用于预测新的未见过的gist token基于先前任务中的的gist token。
其他技术对每个新的输入提示词进行在线压缩。例如,AutoCompressors训练一个预训练的语言模型,通过无监督学习将提示词压缩成总结向量。ICAE训练了一个自动编码器将原始上下文压缩到短记忆槽中。具体来说,ICAE采用适应LoRA的大模型作为编码器,并使用目标大模型作为解码器。在输入token之前添加一组记忆token并将其编码到记忆槽中。
4.1.4 检索增强生成(retrieval augmented generation, RAG)
检索增强生成(Retrieval-Augmented Generation, RAG)旨在通过整合外部知识来源来提高大模型回答的质量。RAG也可以看作是在处理大量数据时提高推理效率的一种技术。RAG没有将所有信息合并到一个过长的prompt中,而是将检索到的相关信息添加到原始提示符中,从而确保模型在显著减少提示词长度的同时接收到必要的信息。FLARE使用对即将到来的句子的预测来主动决定何时以及检索什么信息。REPLUG将大模型视为一个黑盒,并使用可调检索模型对其进行扩充。它将检索到的文档添加到冻结的黑盒大模型的输入中,并进一步利用大模型来监督检索模型。Self-RAG通过检索和自我反思来提高大模型的质量和真实性。它引入了反馈token,使大模型在推理阶段可控。
4.2 输出组织(Output Organization)
传统的大模型的推理过程是完全顺序生成的,这会导致大量的时间消耗。输出组织技术旨在通过组织输出内容的结构来(部分地)实现并行化生成。
思维骨架(Skeleton-of-Thought, SoT)是这个方向的先驱。SoT背后的核心思想是利用大模型的新兴能力来对输出内容的结构进行规划。具体来说,SoT包括两个主要阶段。在第一阶段(即框架阶段),SoT指导大模型使用预定义的“框架提示词”生成答案的简明框架。例如,给定一个问题,如“中国菜的典型类型是什么?”,这个阶段的输出将是一个菜的列表(例如,面条,火锅,米饭),没有详细的描述。然后,在第二阶段(即点扩展阶段),SoT指导大模型使用“点扩展提示符”来同时扩展骨架中的每个点,然后将这些拓展连接起来最终形成最后答案。当应用于开源模型时,可以通过批推理执行点扩展,这可以提升硬件利用率,并在使用相同的计算资源的前提下减少总体生成延迟,以减少额外的计算。SoT的推理流程展示如图6所示:
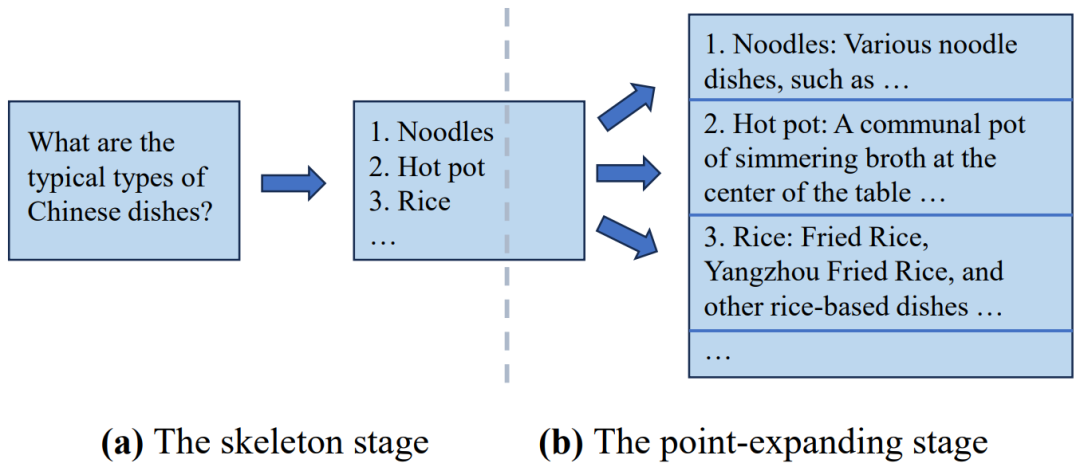
由于额外的提示词(如骨架提示词和点扩展提示词)带来的开销,SoT讨论了在点扩展阶段跨多个点来共享公共提示词前缀的KV缓存的可能性。此外,SoT使用路由模型来决定SoT是否适合应用于特定的问题,目的是将其限制在合适的情况下使用。结果,SoT在最近发布的12个大模型上 实现了高达2.39倍的推理加速,并通过提高答案的多样性和相关性来提高答案质量。
SGD进一步扩展了SoT的思想,其将子问题点组织成一个有向无环图(DAG),并在一个回合内并行地回答逻辑独立的子问题。与SoT类似,SGD还利用大模型的新兴能力,通过提供自己制作的提示词和几个示例来生成输出结构。SGD放宽了不同点之间严格的独立性假设,以提高答案的质量,特别是对于数学和编码问题。与SoT相比,SGD优先考虑答案质量而不是速度。此外,SGD引入了一个自适应的模型选择方法,来根据其估计的复杂性为每个子问题分配最优模型大小,从而进一步提高效率。
APAR采用了与SoT类似的思想,利用大模型输出特殊的控制token(如 ,[fork])来自动动态的触发并行解码。为了有效地利用输出内容中固有的可并行化结构并准确地生成控制token,APAR对大模型进行了微调,这些大模型是精心设计的数据上进行的,这些数据是在特定树结构中形成的。因此,APAR在基准测试中实现1.4到2.0倍的平均加速,且对答案质量的影响可以忽略不计。此外,APAR将他们的解码方法与推测解码技术(如Medusa)和推理框架(如vLLM)结合,来进一步改进推理延迟和系统吞吐量。
SGLang在Python 特征原语中引入了一种领域特定语言(DSL),其能够灵活地促进大模型编程。SGLang的核心思想是自动分析各种生成调用之间的依赖关系,并在此基础上进行批量推理和KV缓存共享。使用该语言,用户可以轻松实现各种提示词策略,并从SGLang的自动效率优化(如SoT,ToT)中收益。此外,SGLang 还介绍并结合了几种系统级别的编译技术,如代码移动和预取注释。
4.3 认识,建议和未来方向
大模型处理更长的输入、生成更长的输出的需求日益增长,这凸显了数据级别的优化技术的重要性。在这些技术中,输入压缩方法的主要目标是通过减少由attention操作引起的计算和内存成本来提升prefilling阶段的效率。此外,对于基于API的大模型,这些方法可以减少与输入token相关的API成本。相比之下,输出组织方法侧重于通过降低与自回归解码方法相关的大量内存访问成本来优化解码阶段。
随着大模型的功能越来越强大,是有可能能利用它们来压缩输入提示词或构建输出内容的。输出组织方法的最新进展也证明了利用大模型将输出内容组织成独立点或依赖图的有效性,从而便于批量推理以改善生成延迟。这些方法利用了输出内容中固有的可并行结构,使大模型能够执行并行解码,从而提高硬件利用率,从而减少端到端的生成延迟。
最近,各种提示词pipeline(如,ToT ,GoT)和Agent框架正在出现。虽然这些创新提高了大模型的能力,但它们也增加了输入prompt的长度,导致计算成本增加。为了解决这个问题,采用输入压缩技术来减少输入长度是一种很有希望的解决方案。同时,这些pipeline和框架自然地为输出结构引入了更多的并行性,增加了并行解码和跨不同解码线程来共享KV cache的可能性。SGLang支持灵活的大模型编程,并为前端和后端协同优化提供了机会,为该领域的进一步扩展和改进奠定了基础。总之,数据级别优化,包括输入压缩和输出组织技术,在可预见的将来,为了提高大模型推理效率,将变得越来越必要。
除了优化现有框架的推理效率外,一些研究还侧重于直接设计更高效的智能体框架。例如,FrugalGPT提出了一个由不同大小的大模型组成的模型级联,如果模型对答案达到足够的确定性水平,那么推理过程就会提前停止。该方法通过利用分层的模型体系结构和基于模型置信度估计的智能推理终止来提高效率。与模型级别的动态推理技术(第5.2.5节)相比,FrugalGPT在pipeline级别执行动态推理。
5 模型级别优化
大模型高效推理的模型级别优化主要集中在模型结构或数据表示的优化上。模型结构优化包括直接设计有效的模型结构、修改原模型和调整推理时间结构。在数据表示优化方面,通常采用模型量化技术。
在本节中,文章将根据所需的额外训练开销对模型级别的优化技术进行分类。第一类包含设计更有效的模型结构(又叫有效结构设计)。使用这种方法开发的模型通常需要从头开始训练。第二类侧重于压缩预训练模型(称为模型压缩)。此类别中的压缩模型通常只需要最小的微调即可恢复其性能。
5.1 有效结构设计
目前,SOTA大模型通常使用Transformer架构,如2.1节所述。然而,基于transformer的大模型的关键组件,包括前馈网络(FFN)和attention操作,在推理过程中存在效率问题。文章认为原因如下:
FFN在基于transformer的大模型中贡献了很大一部分模型参数,这导致显著的内存访问成本和内存使用,特别是在解码阶段。例如,FFN模块在LLaMA-7B模型中占63.01%,在LLaMA-70B模型中占71.69%。
attention操作在的复杂度是输入长度的二次方,这导致大量的计算成本和内存使用,特别是在处理较长的输入上下文时。
为了解决这些计算效率问题,一些研究集中在开发更有效的模型结构上。文章将相关研究分为三组(如图7所示):高效FFN设计、高效注意力设计和Transformer替代。
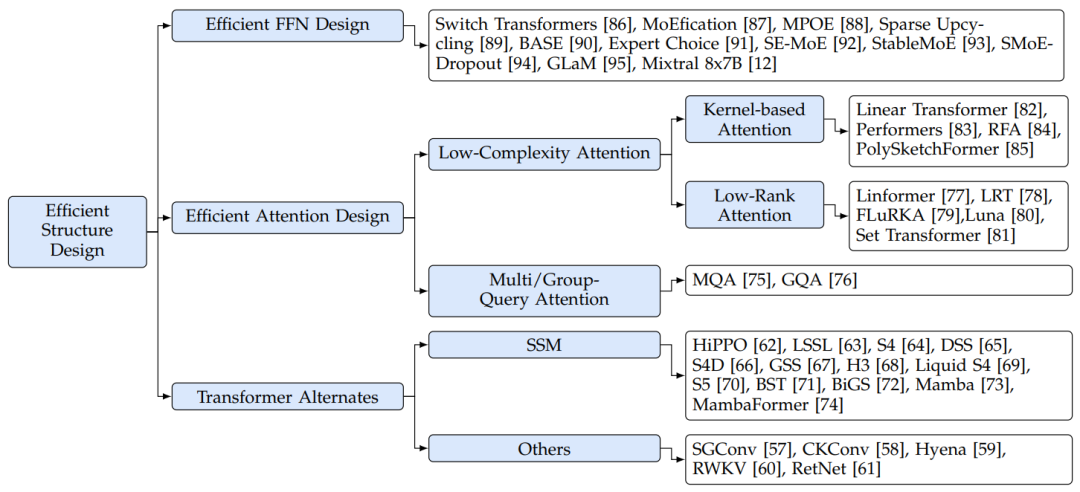
图7:大模型有效结构设计分类
5.1.1 高效FFN设计
在这一方面,许多研究都集中在将混合专家(mixture-of-experts, MoE)技术集成到大模型中,以提高大模型的性能,同时保持计算成本。MoE的核心思想是动态地分配各种预算,在面对不同的输入token时。在基于MoE的Transformers中,多个并行的前馈审计网络(FFN),即专家,与可训练的路由模块一起使用。在推理过程中,模型选择性地为路由模块控制的每个token激活特定的专家。
一些研究集中研究FFN专家的工作,主要是在优化专家权值的获取过程或使专家更轻量化以提高效率。例如,MoEfication设计了一种方法,使用预训练的权重将非MoE大模型转换为MoE版本。这种方法免去了对MoE模型进行昂贵的预训练的需要。为了实现这个技术,MoEfication首先将预训练大模型的FFN神经元分成多组。在每一组中,神经元通常同时被激活函数激活。然后,它以专家的身份重组每组神经元。Sparse Upcycling引入了一种方法,直接从密集模型的checkpoint中初始化基于MoE的LLM的权重。在这种方法中,基于MoE的LLM中的专家是密集模型中FFN的精确复制品。通过使用这种简单的初始化,Sparse Upcycling可以有效地训练MoE模型以达到高性能。MPOE提出通过矩阵乘积算子(Matrix Product Operators, MPO)分解来减少基于MoE的大模型的参数。该方法将FFN的每个权重矩阵分解为一个包含公共信息的全局共享张量和一组捕获特定特征的局部辅助张量。
另一项研究侧重于改进MoE模型中路由模块(或策略)的设计。在以前的MoE模型中,路由模块容易导致负载不平衡问题,这意味着一些专家被分配了大量token,而另一些专家只处理少量token。这种不平衡不仅浪费了未充分利用的专家的能力,降低了模型的性能,还降低了推断推理质量。当前的MoE实现经常使用批矩阵乘法来同时计算所有FFN专家。这就要求每个专家的输入矩阵必须具有相同的形状。然而,由于存在负载不平衡问题,需要向那些未充分利用的专家中填充输入token集以满足形状约束,这会造成计算浪费。因此,路由模块设计的主要目标是在MoE专家的token分配中实现更好的平衡。Switch Transformers在最终loss函数中引入了一个额外的loss,即负载平衡loss,以惩罚路由模块的不平衡分配。这种loss被表述为token分配分数向量和均匀分布向量之间的缩放点积。因此,只有在所有专家之间平衡token分配时,损失才会最小化。这种方法鼓励路由模块在专家之间均匀地分发token,促进负载平衡并最终提高模型性能和效率。BASE用端到端的方式学习了每个专家的embedding,然后根据embedding的相似性将专家分配给令token。为了保证负载均衡,BASE制定了一个线性分配问题,并利用拍卖算法有效地解决了这个问题。Expert Choice引入了一种简单而有效的策略来确保基于MoE的模型的完美负载平衡。与以前将专家分配给token的方法不同,Expert Choice允许每个专家根据embedding的相似度独立选择top-k个token。这种方法确保每个专家处理固定数量的token,即使每个token可能分配给不同数量的专家。
除了上述关注模型架构本身的研究外,也有对基于MoE的模型的训练方法改进的相关工作。SE-MoE引入了一种新的辅助loss,称为router z-loss,其目的是在不影响性能的情况下提高模型训练的稳定性。SE-MoE发现在路由模块中,softmax操作所引入的指数函数会加剧舍入误差,导致训练不稳定。为了解决这个问题,router z-loss会惩罚输入到指数函数中的大概率,从而最小化训练期间的舍入误差。StableMoE指出基于MoE的大模型存在路由波动问题,即在训练和推理阶段专家分配不一致。对于相同的输入token,在训练时其被分配给了不同的专家,但在推理时却只激活一个专家。为了解决这个问题,StableMoE建议采用更一致的训练方法。它首先学习路由策略,然后在模型主干训练和推理阶段保持固定的路由策略。SMoE-Dropout为基于MoE的大模型设计了一种训练方法,其提出在训练过程中逐步增加激活专家的数量。这种方法提升了基于MoE的模型的推理和下游微调的可扩展性。GLaM预训练并发布了一系列具有不同参数大小的模型,这证明了它们在few-shot任务上与密集大模型的性能相当。这个系列模型中,最大的模型的参数高达1.2万亿。Mixtral 8x7B是最近发布的一个引人注目的开源模型。在推理过程中,它只利用了130亿个活动参数,在不同的基准测试中取得了比LLaMA-2-70B模型更好的性能。Mixtral 8x7B每层由8个前馈网络(FFN)专家组成,每个token在推理过程中分配给两个专家。
5.1.2 高效attention设计
attention操作是Transformer体系结构中的一个关键部分。然而,它的计算复杂度是与输入长度相关的二次方,这导致了大量的计算成本、内存访问成本和内存使用,特别是在处理长上下文时。为了解决这个问题,研究人员正在探索更有效的方法来近似原始attention操作的功能。这些研究大致可以分为两个主要分支:multi-query attention和low complexity attention。
①Multi-Query Attention。Multi-Query Attention(MQA)通过共享横跨不同注意力头的KV缓存来优化attention 操作。这项策略有效的减少了推理时的内存访问成本和内存使用,对改善Transformer模型的性能带来了帮助。如第2.2节所述,transformer类型的大模型通常采用多头注意力(MHA)操作。该操作需要在解码阶段为每个注意力头存储和检索KV对,导致内存访问成本和内存使用大幅增加。而MQA通过在不同的头上使用相同的KV对,同时保持不同的Q值来解决这一问题。通过广泛的测试,MQA已经被证明可以显著降低内存需求,且对模型性能的影响很小,这使它成为一个提高推理效率的关键技术。Grouped-query attention(GQA)进一步扩展了MQA的概念,它可以看作是MHA和MQA的混合。具体来说,GQA将注意力头分成不同的组,然后为每个组存储一组KV值。这种方法不仅保持了MQA在减少内存开销方面的优势,还强化了推理速度和输出质量之间的平衡。
②Low-Complexity Attention。Low-Complexity Attention方法旨在设计新的机制来降低每个注意力头的计算复杂度。为了简化讨论,这里假设Q(查询)、K(键)和V(值)矩阵的维度是相同的,即。由于下面的工作不涉及像MQA那样改变注意头的数量,此处的讨论集中在每个头内的注意力机制。如2.2节所述,传统注意力机制的计算复杂度为,相当于随着输入长度增长,呈二次增长。为了解决低效率问题,Kernel-based Attention和Low-Rank Attention方法被提出,此方法将复杂度降低到。
Kernel-based Attention。基于核的注意力设计了一个核,通过变换特征映射之间的线性点积如,,来近似的非线性softmax操作。它通过优先计算,然后将其与相乘,从而避免了与相关的传统二次计算。具体来说,输入Q和K矩阵首先通过核函数映射到核空间,但是保持其原始维度。接着利用矩阵乘法的关联特性,允许K和V在与Q交互之前相乘。因此注意力机制被重新表述为:
其中,。此方法有效的将计算复杂度降低至,使其与输入长度成线性关系。Linear Transformer是第一个提出基于核的注意力的工作。它采用作为核函数,其中表示指数线性单元激活函数。Performers和RFA提出使用随机特征映射来更好地近似softmax函数。PolySketchFormer采用多项式函数和素描技术近似softmax函数。
Low-Rank Attention。 Low-Rank Attention技术在执行注意计算之前,将K和V矩阵的token维度(如)压缩到较小的固定长度(即如)。该方法基于对注意力矩阵通常表现出低秩特性的认识,使得在token维度上压缩它是可行的。这条研究路线的主要重点是设计有效的压缩方法,其中可以是上下文矩阵,也可以是K和V矩阵:
有一种工作是使用线性投影来压缩token维度。它通过将K和V矩阵与映射矩阵相乘来完成的。这样,注意力计算的计算复杂度降至,与输入长度成线性关系。Linformer首先观察并分析了注意力的低秩性,提出了低秩注意力框架。LRT提出将低秩变换同时应用于attention模块和FFN,来进一步提高计算效率。FLuRKA将低秩变换和核化结合到注意力矩阵中,进一步提高了效率。具体的说,它首先降低K和V矩阵的token的维度,然后对Q和低秩K矩阵应用核函数。
除了线性映射外,其他的token维度压缩方法也被提出出来。Luna和Set Transformer利用额外的注意力计算和较小的query来有效地压缩K和V矩阵。Luna则是使用了一个额外的固定长度为的query矩阵。小的query使用原始的上下文矩阵执行注意力计算,称为pack attention,来将上下文矩阵压缩到大小为。随后,常规的注意力计算,称为unpack attention,将注意力计算应用于原始Q矩阵和压缩的K和V矩阵。额外的query矩阵可以是可学习的参数或从前一层中获取。Set Transformer通过引入固定长度的矢量,设计了类似的技术。FunnelTransformer不同于以往压缩K和V的工作,它使用池化操作来逐步压缩Q矩阵的序列长度。
5.1.3 Transformer替代
除了聚焦于优化注意力操作之外,最近的研究还创新地设计了高效而有效的序列建模体系结构。表2比较了一些代表性的非transformer架构模型的性能。在训练和推理过程中,这些架构的模型在序列长度方面表现出小于二次方的计算复杂度,使大模型能够显着增加其上下文长度。
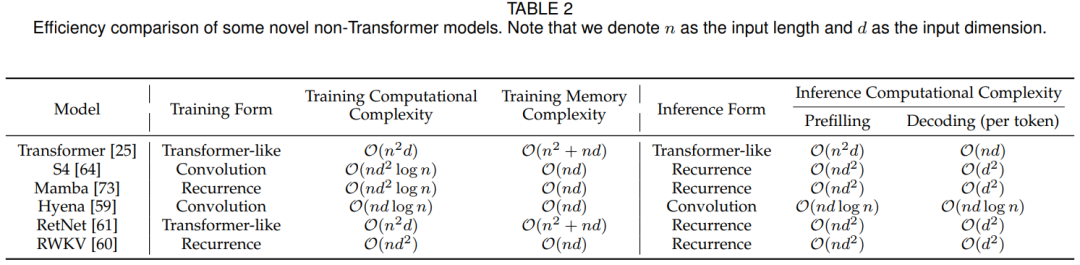
典型非Transformer架构模型性能比较
在这些研究中,有两个突出的研究方向引起了极大的关注。其中一条研究集中在状态空间模型(State Space Model, SSM)上,该模型将序列建模视作一种基于HiPPO理论的递归变换。此外,其他研究主要集中在使用长卷积或设计类似注意力的公式来建模序列。
State Space Model:状态空间模型(SSM)在某些NLP和CV任务中的建模能力极具竞争力。与基于注意力的Transformer相比,SSM在输入序列长度方面表现出线性的计算和存储复杂度,这提高了其处理长上下文序列的能力。本篇综述中,SSM是指一系列满足以下两个属性的模型架构:
(1)它们基于HiPPO和LSSL提出的以下公式对序列进行建模:
其中,表示转移矩阵。为中间状态,为输入序列。
(2)他们基于HiPPO理论设计了转移矩阵A。具体来说,HiPPO提出通过将输入序列映射到一组多项式基上,将其压缩为系数序列(即)。
在上述框架的基础上,一些研究主要集中在改进转移矩阵A的参数化或初始化。这包括在SSM中重新定义矩阵的公式或初始化方式,以增强其在序列建模任务中的有效性和性能。LSSL首先提出用HiPPO设计的最优转移矩阵初始化A。此外,LSSL还通过展开公式(7),以卷积的方式训练SSM。具体地说,通过定义一个卷积核为,可以将公式(7)改写为,也可以通过快速傅里叶变换(FFT)高效地计算。然而,计算这个卷积核的代价是昂贵的,因为它需要多次乘以A。为此,S4、DSS和S4D提出对矩阵A进行对角化,从而加快计算速度。这可以看作是转换矩阵A的参数化技术。过去的SSM独立处理每个输入维度,从而会产生大量可训练的参数。为了提高效率,S5提出使用一组参数同时处理所有输入维度。在此结构的基础上,S5介绍了基于标准HiPPO矩阵的A的参数化和初始化方法。Liquid S4和Mamba以输入依赖的方式对转移矩阵进行参数化,这进一步增强了SSM的建模能力。此外,S5和Mamba均采用并行扫描技术,无需卷积操作即可进行有效的模型训练。这种技术在现代GPU硬件上的实现和部署方面具有优势。
另一类研究方向是基于SSM设计更好的模型架构。GSS和BiGS结合了门控注意力单元(GAU)和SSM。它们将GAU中的注意力操作替换为SSM操作。BST将SSM模型与提出的使用强局部感应偏置的Block Transformer相结合。H3观察到SSM在召回较早的token和跨序列比较token方面很弱。为此,它建议在标准SSM操作之前增加一个移位SSM操作,用于直接将输入令牌移位进入状态。MambaFormer结合了标准Transformer和SSM模型,将Transformer中的FFN层替换为SSM层。Jamba引入了另一种方法,通过在SSM模型中添加四个Transformer层来组合Transformer和SSM模型。DenseMamba探讨了传统SSM中隐藏状态退化的问题,并在SSM体系结构中引入了稠密连接,以在模型的更深层中保存细粒度信息。BlackMamba和MoE- mamba提出用混合专家(Mixture-of-Experts, MoE)技术增强SSM模型,在保持模型性能的同时优化训练和推理效率。
其他代替:除了SSM之外,还有其他几种高效的替代方案也引起了极大的关注,包括长卷积和类attention的递归运算。一些研究在长序列建模中采用了长卷积。这些工作主要是关于卷积参数的参数化的。例如,Hyena采用了一种数据相关的参数化方法,用于使用浅前馈神经网络(FFN)的长卷积。其他设计类注意力操作,但可以纳入循环方式的研究,从而实现高效的训练和高效的推理。例如,RWKV是在AFT的基础上建立的,AFT提出将Transformer模型中的注意力操作代入如下公式:
其中,和Transformer一样 ,分别为quey,key,vakue,为一个可学习的成对位置偏差和为一个非线性函数。具体来说,它进一步将位置偏差进行重参数化,,因此可以将公式(8)重写为递归形式。这样,RWKV可以将Transformer的有效并行化训练特性和RNN的高效推理能力结合起来。
效果分析:文章在表2中分析和比较了几种创新的和具有代表性的非Transformer架构的模型的计算和内存复杂性。在训练时间方面,许多模型(如S4, Hyena, RetNet)这些通过使用卷积或注意力等训练形式来保持训练并行性。值得注意的是,Mamba用并行扫描技术处理输入序列,从而也使用了训练并行性。
另一方面,在推理过程中,大多数研究选择循环架构来保持prefilling阶段的线性计算复杂度并在decoding阶段保持上下文长度不可知。而且,在decoding阶段,这些新颖的体系结构消除了缓存和加载历史token的特性的需要(类似于基于Transformer的语言模型中的KV缓存),从而显著节省了内存访问成本。
5.2 模型压缩
模型压缩包括一系列旨在通过修改预训练模型的数据表示(例如,量化)或改变其模型架构(例如,稀疏化、结构优化和动态推理)来提高其推理效率的技术,如图8所示。
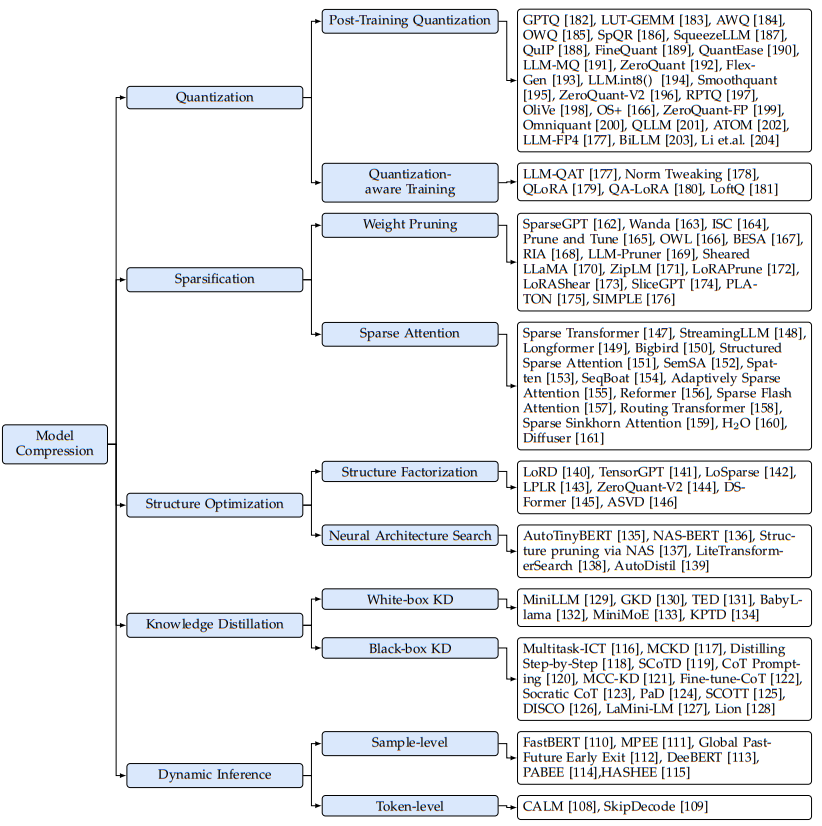
图8:大模型的模型压缩方法分类
5.2.1 量化
量化是一种广泛使用的技术,通过将模型的权重和激活从高位宽表示转换为低位宽表示来减少大模型的计算和内存成本。具体来说,许多方法都涉及到将FP16张量量化为低位整型张量,可以表示为如下公式:
其中表示16位浮点(FP16)值,表示低精度整数值,表示位数,和表示缩放因子和零点。
在下面,本文从效率分析开始,说明量化技术如何减少大模型的端到端推理延迟。随后,再分别详细介绍两种不同的量化工作流程:Post-Training Quantization (PTQ)和Quantization-Aware Training (QAT)。
效率分析:如2.2节所述,大模型的推理过程包括两个阶段:prefilling阶段和decoding阶段。在prefilling阶段,大模型通常处理长token序列,主要操作是通用矩阵乘法(GEMM)。Prefilling阶段的延迟主要受到高精度CUDA内核执行的计算操作的限制。为了解决这个问题,现有的研究方法对权重和激活量化,以使用低精度Tensor核来加速计算。如图9 (b)所示,在每次GEMM操作之前会在线执行激活量化,从而允许使用低精度Tensor核(例如INT8)进行计算。这种量化方法被称为权重激活量化。
相比之下,在解码阶段,大模型在每个生成步中只处理一个token,其使用通用矩阵向量乘法(GEMV)作为核心操作。解码阶段的延迟主要受到加载大权重张量的影响。为了解决这个问题,现有的方法只关注量化权重来加速内存访问。这种方法称为,首先对权重进行离线量化,然后将低精度权重去量化为FP16格式进行计算,如图9 (a)所示。
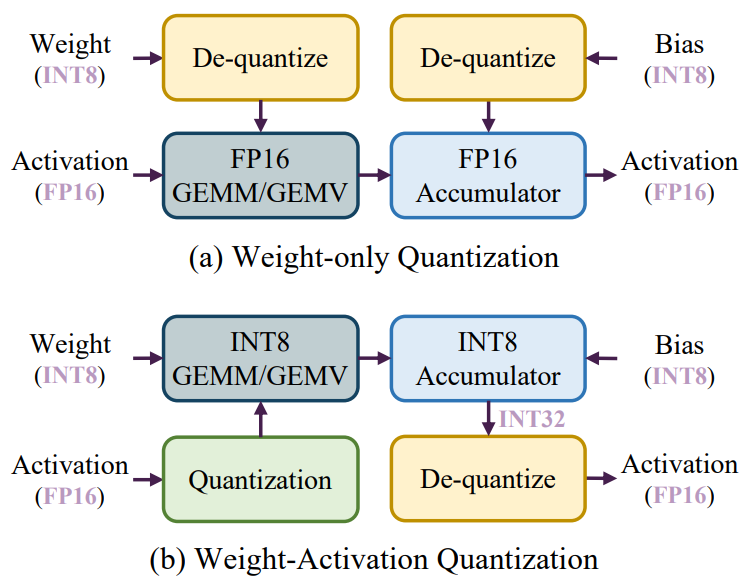
图9:(a)纯权重量化推理流程。(b)权重激活量化推理流程。
Post-Training Quantization: PTQ涉及对预训练模型进行量化,而不需要再训练,这可能是一个昂贵的过程。尽管PTQ方法已经在较小的模型中得到了很好的探索,但是将现有的量化技术直接应用于大模型存在困难。这主要是因为与较小的模型相比,大模型的权重和激活通常表现出更多的异常值,并且具有更宽的分布范围,这使得它们的量化更具挑战性。总之,大模型的复杂特性,以其规模和复杂性为特征,需要用专门的方法来有效地处理量化过程。大模型中异常值和更宽的分布范围的存在需要开发量身定制的量化技术,以便在不影响模型性能或效率的情况下处理这些独特的特征。
大量的研究致力于开发有效的量化算法来压缩大模型。本文在表3中提供了跨四个维度分类的代表性算法的综合。对于量化张量的种类,某些研究专注于weight-only quantization,而其他许多研究则专注于权重和激活的量化。值得注意的是,在大模型中,KV缓存代表了影响内存和内存访问的独特组件。因此,一些研究提出对KV缓存进行量化。在量化格式方面,为了便于硬件实现,大多数算法采用统一的格式。关于量化参数(如缩放因子、零点)的确定,大多数研究依赖于由权重或激活值得出的统计数据。然而,也有一些研究主张基于重构loss来寻找最优参数。此外,一些研究也建议在量化之前或量化过程中更新未量化的权重(称为)以提高性能。
在weight-only quantization方法中,GPTQ代表了大模型量化的早期较好的工作,它建立在传统算法OBQ的基础上。OBQ通过相对于未量化权重的Hessian矩阵的重建误差的方法,来实现每行权重矩阵的最优量化顺序。在每个量化步骤之后,OBQ迭代调整未量化的权重以减轻重建误差。然而,量化过程中频繁更新Hessian矩阵增加了计算复杂度。GPTQ通过采用统一的从左到右的顺序来量化每一行,从而简化了这个过程,从而避免了大量更新Hessian矩阵的需要。该策略通过在量化一行时仅计算Hessian矩阵,然后将计算结果用于后续行,从而大大减少了计算需求,从而加快了整个量化过程。LUT- GEMM提出了一种新的利用查找表(Look-Up Table, LUT)的去量化方法,旨在通过减少去量化开销来加速量化大模型的推理过程。此外,它采用了一种称为二进制编码量化(BCQ)的非均匀量化方法,该方法包含了可学习的量化区间。AWQ观察到权重通道对性能的重要性各不相同,特别强调那些与激活异常值的输入通道对齐的通道。为了增强关键权重通道的保存,AWQ采用了一种重参数化的方法。该方法通过网格搜索选择重参数化系数,有效地减小了重构误差。OWQ观察到量化与激活异常值相关的权重的困难。为了解决这个问题,OWQ采用了混合精度量化策略。该方法识别权重矩阵中的弱列,并为这些特定权重分配更高的精度,同时以较低的精度级别量化其余权重。SpQR引入了一种方法,在量化过程中识别和分配更高精度的权重异常值,而其余权重被量化为3位。SqueezeLLM提出将离群值存储在全精度稀疏矩阵中,并对剩余权重应用非均匀量化。根据量化灵敏度确定非均匀量化的值,能够提高量化模型的性能。QuIP引入了LDLQ,一种二次代理目标的最优自适应方法。研究表明,保证权值与Hessian矩阵之间的不相干性可以提高LDLQ的有效性。QuIP利用LDLQ,通过随机正交矩阵乘法实现非相干性。FineQuant采用了一种启发式方法。为了确定每列量化的粒度,结合从实验中获得的经验见解来设计量化方案。QuantEase的工作建立在GPTQ之上。在对每一层进行量化时,其提出了一种基于坐标下降的方法来更精确地补偿未量化的权重。此外,QuantEase可以利用来自GPTQ的量化权重作为初始化,并进一步完善补偿过程。LLM-MQ采用FP16格式保护权重异常值,并将其存储在压缩稀疏行(CSR)格式中,以提高计算效率。此外,LLM-MQ将每个层的位宽分配,建模为整数规划问题,并采用高效的求解器在几秒内求解。LLM-MQ还设计了一个高效的CUDA内核来集成去量化运算符,从而降低了计算过程中的内存访问成本。
对于weight-activation quantization,ZeroQuant采用细粒度量化权值和激活,利用核融合来最小化量化过程中的内存访问成本,并逐层进行知识蒸馏以恢复性能。FlexGen将权重和KV缓存直接量化到INT4中,以减少大批量推理期间的内存占用。LLM.int8() 发现激活中的异常值集中在一小部分通道中。基于这一点,LLM.int8() 根据输入通道内的离群值分布将激活和权重分成两个不同的部分,以最小化激活中的量化误差。包含激活值和权重的异常数据的通道以FP16格式存储,其他通道则以INT8格式存储。SmoothQuant采用了一种重新参数化技术来解决量化激活值的挑战。该方法引入比例因子,扩大了权重通道的数据范围,缩小了相应激活通道的数据范围。ZeroQuant引入了权重的组级别的量化策略和激活的token级别的量化方法。在此方法的基础上,ZeroQuantV2提出了LoRC(低秩补偿)技术,采用低秩矩阵来减轻量化不准确性。RPTQ发现不同激活通道的分布,实质上是变化的,这给量化带来了挑战。为了缓解这个问题,RPTQ将具有相似激活分布的通道重新组织到集群中,并在每个集群中独立地应用量化。OliVe观察到离群值附近的正态值不那么关键。因此,它将每个离群值与一个正态值配对,牺牲正态值,以获得更大的离群值表示范围。OS+观察到异常值的分布是集中且不对称的,这对大模型的量化提出了挑战。为了解决这个问题,OS+引入了一种通道级别的移动和缩放技术。在搜索过程去确定移动和缩放参数,能有效地处理集中和不对称的离群值分布。ZeroQuant-FP研究了将权重和激活值量化为FP4和FP8格式的可行性。研究表明,与整数类型相比,将激活量化为浮点类型(FP4和FP8)会产生更好的结果。Omniquant与先前依赖量化参数的经验设计的方法不同。相反,它优化了权值裁剪的边界和等效变换的缩放因子,以最小化量化误差。QLLM通过实现通道重组来解决异常值对量化的影响。此外,QLLM还设计了可学习的低秩参数,来减小post-quantized模型的量化误差。Atom采用了混合精度和动态量化激活的策略。值得注意的是,它扩展了这种方法,将KV缓存量化为INT4,以提高吞吐量性能。LLM-FP4努力将整个模型量化为FP4格式,并引入了预移位指数偏置技术。该方法将激活值的比例因子与权重相结合,以解决异常值带来的量化问题。BiLLM代表了迄今为止最低位PTQ的工作之一。BiLLM识别了权值的钟形分布和权值Hessian矩阵的异常长尾分布。在此基础上,提出了将基于Hessian矩阵的权重结构分类为显著值和非显著值,并分别进行二值化。因此,BiLLM可以将大模型广泛量化到1.08位,且不会显著降低困惑度。KVQuant通过在校准集上离线导出最优数据类型,提出了KV缓存量化的非均匀量化方案。KIVI提出了一种无需调优的2bit KV缓存量化算法,该算法利用单通道量化用于key cache,利用单token量化进行value cache。Li等进行了全面的评估,评估了量化对不同张量类型(包括KV Cache)、各种任务、11种不同的大模型和SOTA量化方法的影响。
Quantization-Aware Training:QAT在模型训练过程中考虑了量化的影响。通过集成复制量化效果的层,QAT有助于权重适应量化引起的错误,从而提高任务性能。然而,训练大模型通常需要大量的训练数据和计算资源,这对QAT的实施构成了潜在的瓶颈。因此,目前的研究工作集中在减少训练数据需求或减轻与QAT实施相关的计算负担的策略上。为了减少数据需求,LLM-QAT引入了一种无数据的方法,利用原始FP16的大模型生成训练数据。具体来说,LLM-QAT使用词表中的每个token作为生成句子的起始标记。基于生成的训练数据,LLM- QAT应用了基于蒸馏的工作流来训练量化的LLM,以匹配原始FP16大模型的输出分布。Norm Tweaking只针对那些在语言类别中占最高比例的语言,做了起始标记的限制选择。这一策略可以有效地提高量化模型在不同任务上的生成性能。
为了减少计算量,许多方法采用高效参数微调(parameter-efficient tuning,PEFT)策略来加速QAT。QLoRA将大模型的权重量化为4位,随后在BF16中对每个4位权重矩阵使用LoRA来对量化模型进行微调。QLoRA允许在一个只有30GB内存的GPU上对65B参数的大模型进行有效的微调。QALoRA则提出在QLoRA中加入分组量化。作者观察到QLoRA中量化参数的数量明显小于LoRA参数的数量,这会导致量化与低秩自适应之间的不平衡。他们建议,组级别的操作可以通过增加专用于量化的参数数量来解决这个问题。此外,QA-LoRA可以将LoRA项合并到相应的量化权矩阵中。LoftQ指出,在QLoRA中用零初始化LoRA矩阵对于下游任务是低效的。作为一种替代方案,LoftQ建议使用原始FP16权重与量化权重之间差距的奇异值分解(Singular Value Decomposition,SVD)来初始化LoRA矩阵。LoftQ迭代地应用量化和奇异值分解来获得更精确的原始权重近似值。Norm Tweaking提出在量化后训练LayerNorm层,并使用知识蒸馏将量化模型的输出分布与FP16模型的输出分布进行匹配,达到类似LLM-QAT的效果,同时避免了较高的训练成本。
对比实验与分析:本综述的作者对不同场景下的weight-only quantization技术所产生的加速效果。作者使用了LLaMA-2-7B和LLaMA-2-13B,并使用AWQ将它们的权重量化至4-bit。作者使用NVIDIA A100进行实验,并使用TensorRT-LLM和LMDeploy这两个推理框架部署量化后的大模型。然后,作者评估了这些推理框架在不同的输入序列上实现的加速,这些序列是批大小和上下文长度不同的。prefilling延迟、decoding延迟端到端延迟的加速效果,如表4所示。
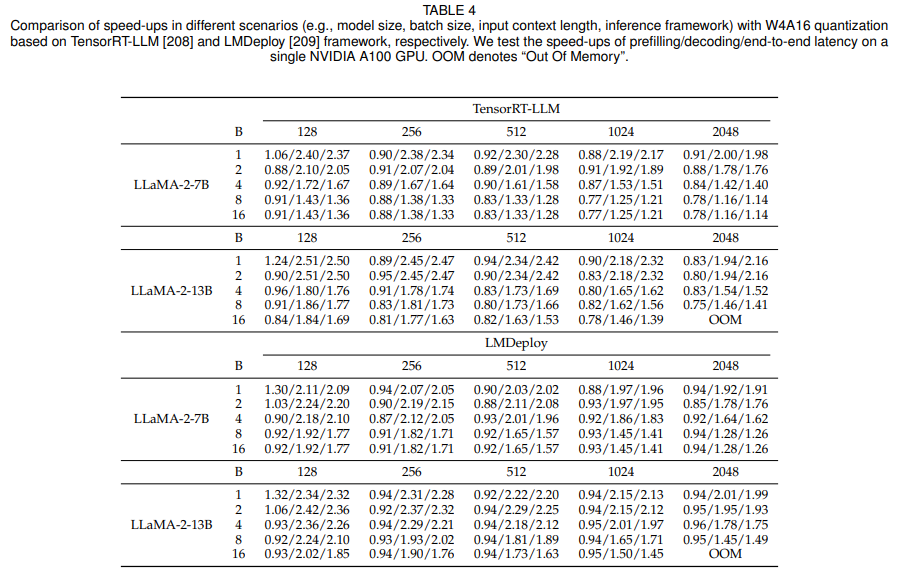
表4:大模型加速效果对比
实验结果表明:(1)Weight-only quantization可以在decoding阶段加速,进而实现端到端的加速。这种提升主要源于从高带宽内存( High Bandwidth Memory,HBM)更快地加载具有低精度权重张量的量化模型,这种方法显著减少了内存访问开销。(2)对于prefilling阶段,weight-only quantization可能会增加延迟。这是因为prefilling阶段的瓶颈是计算成本,而不是内存访问开销。因此,只量化没有激活的权重对延迟的影响最小。此外,如图9所示,weight-only quantization需要将低精度权重去量化到FP16,这会导致额外的计算开销,从而减慢prefilling。(3)随着批量大小和输入长度的增加,weight-only quantization的加速程度逐渐减小。这主要是因为,对于更大的批处理大小和输入长度,计算成本构成了更大比例的延迟。虽然weight-only quantization主要降低了内存访问成本,但随着批量大小和输入长度增大,计算需求变得更加突出,它对延迟的影响变得不那么显著。(4)由于内存访问开销与模型的参数量规模相关,weight-only quantization为参数规模较大的模型提供了更大的好处。随着模型的复杂度与尺寸的增长,存储和访问权重所需的内存量也会成比例地增加。通过量化模型权重,weight-only quantization可以有效地减少内存占用和内存访问开销。
5.2.2 稀疏化(Sparsification)
稀疏化是一种压缩技术,可以增加数据结构(如模型参数或激活)中零值元素的比例。该方法通过在计算过程中有效地忽略零元素来降低计算复杂度和内存占用。在应用到大模型中时,稀疏化通常应用于权重参数和注意力激活。这导致了权值修剪策略和稀疏注意力机制的发展。
权重修剪(Weight Pruning):权值修剪系统地从模型中去除不太关键的权值和结构,旨在减少预填充阶段和解码阶段的计算和内存成本,而不会显著影响性能。这种稀疏化方法分为两种主要类型:非结构化修剪和结构化修剪。它们的分类基于修剪过程的粒度,如图10所示。
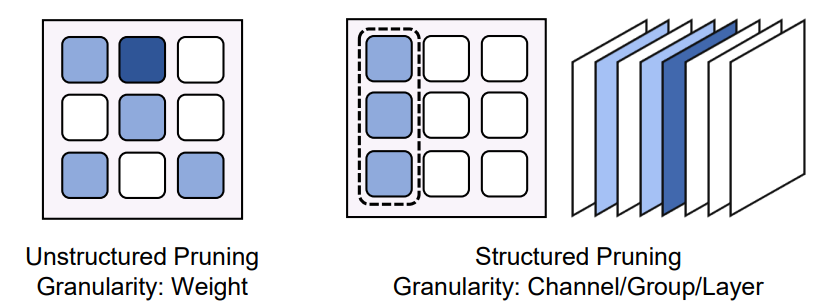
图10:非结构化修剪和结构化修剪
非结构化修剪以细粒度修剪单个权重值。与结构化修剪相比,它通常在对模型预测影响最小的情况下实现更高的稀疏度。然而,通过非结构化剪枝实现的稀疏模式缺乏高层次的规律性,导致不规则的内存访问和计算模式。这种不规律会严重阻碍硬件加速的潜力,因为现代计算架构针对密集、规则的数据进行了优化。因此,尽管实现了更高的稀疏度级别,但非结构化剪枝在硬件效率和计算加速方面的实际好处可能是有限的。
权值修剪的焦点是修剪标准,包括权重重要性和修剪比例。考虑到大模型的参数规模巨大,提高剪枝效率也至关重要。一个修剪准则是最小化模型的重建损失。SparseGPT是该领域的代表性方法。它遵循OBS的思想,考虑去除每个权值对网络重构损失的影响。OBS迭代地确定一个剪枝掩模对权值进行剪枝,并重建未剪枝的权值以补偿剪枝损失。SparseGPT通过最优部分更新技术克服了OBS的效率瓶颈,设计了一种基于OBS重构误差的自适应掩码选择技术。Prune and Tune通过在修剪过程中使用最少的训练步骤微调大模型来改进SparseGPT。ISC结合OBS和OBD中的显著性标准设计了一种新的修剪标准。该算法进一步根据Hessian信息为每一层分配非均匀剪枝比例。BESA通过重构损失的梯度下降学习一个可微的二值掩码。每一层的剪枝比依次通过最小化重建误差来确定。另一种流行的修剪标准是基于大小缺定。Wanda提出使用权值与输入激活范数之间的元素积作为修剪准则。RIA通过使用相对重要性和激活度的度量来联合考虑权重和激活度,该度量基于其所有连接的权重来评估每个权重元素的重要性。此外,RIA将非结构化稀疏范式转换为结构化N:M稀疏范式,可以在NVIDIA GPU上获得实际的加速。OWL侧重于确定各层的剪枝比例。它根据激活异常值比率为每一层分配剪枝比率。
与非结构化修剪相比,结构化修剪以更粗的粒度操作,修剪模型中较大的结构单元,例如整个通道或层。这些方法直接促进了在传统硬件平台上的推理加速,因为它们与这些系统优化处理的密集、规则的数据范式保持一致。然而,结构化修剪的粗粒度通常会对模型性能产生更明显的影响。这类修剪标准还强制执行结构化修剪模式。LLM-Prune提出了一种任务不可知的结构化修剪算法。具体来说,它首先根据神经元之间的连接依赖关系识别出大模型中的偶联结构。然后,它根据设计良好的组级别的修剪度量来决定要删除哪些结构组。修剪后,进一步提出通过一个高校参数训练技术,如LoRA来恢复模型性能。 Sheared LLaMA提出将原始大模型修剪为现有预训练大模型的特定目标架构。此外,它设计了动态批数据加载技术来提升post-training 性能。
ZipLM迭代地识别和修剪结构组件,在损失和运行时间之间进行最坏的权衡。LoRAPrune为带有LoRA模块的预训练大模型提出了结构化修剪框架,以实现基于LoRA的模型的快速推理。它设计了基于LoRA的权值和梯度的由LoRA引导的剪枝准则,并设计了基于该准则去除不重要权值的迭代剪枝方案。LoRAShear还为基于LoRA的大模型设计了一种修剪方法,该方法采用(1)图算法来识别最小的去除结构,(2)渐进式结构化剪接算法LHSPG,(3)动态知识恢复机制来恢复模型性能。SliceGPT[174]基于RMSNorm操作的计算不变性思想。它提出在每个权值矩阵中对稀疏性进行结构化排列,并对整个行或列进行切片。PLATON[提出通过考虑权重的重要性和不确定性来修剪权重。它使用重要性分数的指数移动平均(Exponential Moving Average,EMA)来估计重要性,对不确定性采用上置信度界(UCB)。SIMPLE提出通过学习相应的稀疏掩码来修剪注意头、FFN神经元和隐藏维度。在进行剪枝后,进一步采用知识精馏对剪枝后的模型进行微调,实现性能恢复。
稀疏注意力(Sparse Attention):Transformer多头自注意力(MHSA)组件中的稀疏注意技术可以策略性地省略某些注意运算,以提高注意运算的计算效率,主要是在预填充阶段。这些机制根据对特定输入数据的依赖程度分为静态和动态两类。
静态稀疏注意力去除了独立于特定输入的激活值。这些方法预先确定了稀疏的注意力掩码,并在推理过程中将其强加于注意力矩阵。过去的研究工作结合了不同的稀疏模式来保留每个注意力矩阵中最基本的元素。如图11(a)所示,最常见的稀疏注意力模式是局部和全局注意模式。本地注意力范式捕获每个token的本地上下文,并在每个token周围设置固定大小的窗口注意。全局注意力范式通过计算和关注整个序列中的所有token来捕获特定token与所有其他token之间的相关性。利用全局模式可以消除存储未使用的token的KV对的需要,从而减少了解码阶段的内存访问成本和内存使用。Sparse Transformer将这些模式结合起来,用本地模式捕获本地上下文,然后每隔几个单词就用全局模式聚合信息。StreamingLLM只对前几个token应用本地模式和全局模式。结果表明,这种全局模式作为注意力漕,保持了对初始标记的强注意得分。它有助于大模型推广到无限输入序列长度。Bigbird也使用随机模式,其中所有token都参加一组随机token。证明了局部模式、全局模式和随机模式的组合可以封装所有连续序列到序列的函数,并证实了其图灵完备性。如图11(b)所示,Longformer还引入了膨胀的滑动窗口模式。它类似于扩张的CNN,使滑动窗口“扩张”以增加接受野。为了使模型适应稀疏设置,Structured sparse Attention提倡一种熵感知的训练方法,将高概率的注意力值聚集到更密集的区域中。与以往手工设计稀疏模式的研究不同,SemSA使用基于梯度的分析来识别重要的注意模式,并自动优化注意密度分布,进一步提高模型效率。
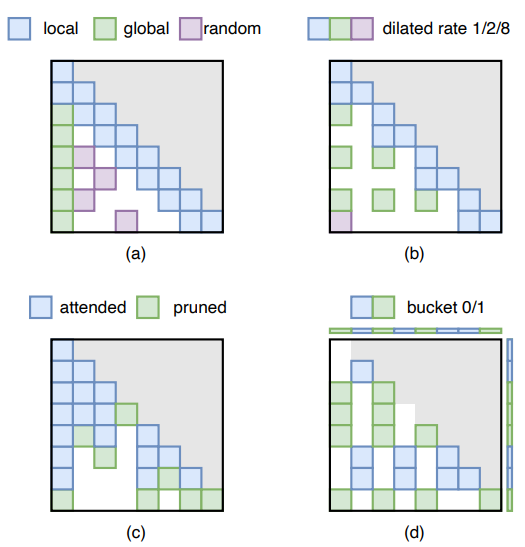
图11:不同的稀疏注意力掩码举例
相比之下,动态稀疏注意力根据不同的输入自适应地消除激活值,通过实时监测神经元的激活值来绕过对神经元的影响可以忽略的计算,从而实现修剪。大多数动态稀疏注意方法采用动态token修剪方法,如图11(c)所示。Spatten、SeqBoat和Adaptive Sparse Attention利用语言结构的固有冗余提出动态标记级修剪策略。Spatten通过汇总注意力矩阵列来评估每个单词的累积重要性,并在后面的层中从输入中对具有最小累积重要性的token进行修剪。SeqBoat训练了一个线性状态空间模型(State Space Model, SSM),该模型带有一个稀疏的sigmoid函数,以确定每个注意力头需要修剪哪个token。Spatten和SeqBoat都对整个输入的无信息的token进行了修剪。自适应稀疏注意力在生成过程中逐渐修剪token。它去除了上下文中,在未来生成不再需要的部分。
除了动态token修剪,动态注意力修剪技术也被应用。如图11(d)所示,这些方法不是修剪某些token的所有注意力值,而是根据输入动态地修剪注意力的选择部分。在相关工作中,一个较为不错的方法是动态地将输入token分成组,称为桶,并策略性地省略驻留在单独桶中的token的注意力计算。这些方法的重点在于如何将相关的token聚类在一起,来促进它们之间的注意力计算,从而提高效率。Reformer利用位置敏感的哈希来将共享相同哈希码的key和query聚集到同一个桶中。在此之后,Sparse Flash Attention引入了专门针对这种基于哈希的稀疏注意力机制进行优化的GPU内核,进一步提高了计算效率。同时,Routing Transformer采用球形k-means聚类算法将token聚合到桶中,优化了注意力计算的选择过程。Sparse Sinkhorn Attention采用学习排序网络将key与其相关的query桶对齐,确保仅在相应的query和key对之间计算注意力。与桶级操作不同,H2O引入了token级动态注意力修剪机制。它将静态本地注意力与当前query和一组动态标识的key token之间的动态计算结合起来,称作heavy-hitters(H2)。这些 heavy-hitters通过移除策略进行动态调整,该策略旨在在每个生成步骤中删除最不重要的key,从而有效地管理heavy-hitter集的大小和相关性。
此外,将每个token视为图节点,将token之间的注意力视为边,可以扩展静态稀疏注意力的视角。原始的全注意力机制等同于一个均匀最短路径距离为1的完整图。稀疏注意力通过其随机掩码引入随机边,有效地将任意两个节点之间的最短路径距离减小到,从而保持类似于完全注意的高效信息流。Diffuser利用图论的视角,通过多跳token关联来扩展稀疏注意的接受场。它还从扩展图属性中获得灵感,以设计更好的稀疏模式,以近似全注意力的信息流。
除了注意力级和token级的稀疏性之外,注意力修剪的范围扩展到各种粒度。Spatten还将修剪从token粒度扩展到注意力头粒度,消除了不必要的注意力头的计算,以进一步减少计算和内存需求。
5.2.3 架构优化(Structure Optimization)
架构优化的目标是重新定义模型的体系结构或者架构,以提高模型效率和性能之间的平衡。相关工作中有两种突出的技术:神经结构搜索(Neural Architecture Search, NAS)和低秩分解(Low Rank Factorization, LRF)。
神经结构搜索(Neural Architecture Search):神经架构搜索(Neural Architecture Search, NAS)旨在自动搜索在效率和性能之间达到最佳平衡的最优神经架构。AutoTinyBERT利用one-shot神经架构搜索(NAS)来发现Transformer架构的超参数。值得注意的是,它引入了一种引人注目的批处理训练方法来训练超级预训练语言模型(SuperPLM),随后使用进化算法来识别最优子模型。NAS-BERT使用一些创新技术,如块级别搜索、搜索空间修剪和性能逼近,在传统的自监督预训练任务上训练大型超级网络。这种方法允许NAS-BERT有效地应用于各种下游任务,而不需要大量的重新训练。通过NAS进行结构剪枝将结构剪枝作为一个多目标NAS问题,通过一次性的NAS方法进行解决。LiteTransformerSearch提出使用不需要训练的指标,例如参数的数量作为代理指标来指导搜索。这种方法可以有效地探索和选择最优的体系结构,而不需要在搜索阶段进行实际的训练。AutoDistil提出了一种完全与任务无关的few-shot NAS算法,该算法具有三种主要技术:搜索空间划分、与任务无关的SuperLM训练和与任务无关的搜索。这种方法的目的是促进跨各种任务的高效体系结构发现,并减少特定于任务的调整。通常,NAS算法需要评估每个采样架构的性能,这可能会产生大量的训练成本。因此,这些技术在应用于大模型时具有挑战性。
低秩分解(Low Rank Factorization):低秩分解(LRF)或低秩分解(Low Rank Decomposition)的目的是用两个低秩矩阵和近似一个矩阵:
其中比和小得多。这样,LRF可以减少内存使用,提高计算效率。此外,在大模型推理的解码阶段,内存访问成本是解码速度的瓶颈。因此,LRF可以减少需要加载的参数数量,从而加快解码速度。LoRD显示了压缩大模型的潜力,而不会通过LRF大幅降低性能。具体来说,采用奇异值分解(SVD)对权重矩阵进行因式分解,成功地将一个包含16B个参数的大模型压缩为12.3B,性能小幅度下降。TensorGPT引入了一种使用Tensor-Train Decomposition来压缩embedding层的方法。每个token embedding都被视为矩阵乘积状态(Matrix Product State, MPS),并以分布式方式高效计算。LoSparse结合了LRF和权值剪枝在LLM压缩中的优点。通过利用低秩近似,LoSparse降低了直接进行模型修剪通常会丢失太多表达神经元的风险。LPLR和ZeroQuant-V2都提出了对权矩阵进行LRF和量化同时压缩的方法。DSFormer提出将权重矩阵分解为半结构化稀疏矩阵与一个小型密集型矩阵的乘积。ASVD设计了一个激活感知的奇异值分解方法。该方法包括在应用奇异值分解进行矩阵分解之前,根据激活分布缩放权重矩阵。ASVD还包括通过一个搜索进程确定每个层的合适的截断秩。
5.2.4 知识蒸馏(Knowledge Distillation)
知识蒸馏(Knowledge Distillation, KD)是一种成熟的模型压缩技术,其中来自大型模型(称为teacher模型)的知识被转移到较小的模型(称为student模型)。在大模型的背景下,KD使用原始的大模型作为teacher模型来提炼较小的大模型。目前许多研究都集中在如何有效地将大模型的各种能力转移到更小的模型上。在这个领域,方法可以分为两种主要类型:白盒KD和黑盒KD(如图12所示)。
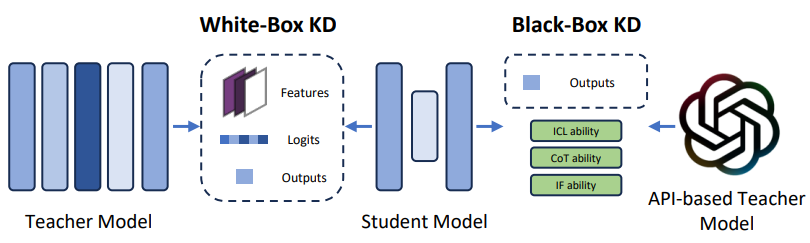
图12:白盒KD(左)与黑盒KD(右)示意图
白盒KD(White-box KD):白盒KD指的是利用对teacher模型的结构和参数的访问的蒸馏方法。这些方法使KD能够有效地利用teacher模型的中间特征和输出概率来增强student模型的性能。MiniLLM采用标准白盒KD方法,但将正向Kullback-Leibler divergence(KLD)替换为反向KLD。GKD引入了对 on-policy数据的使用,其中包括由student模型本身生成的输出序列,以进一步蒸馏学生模型。该方法侧重于使用这些策略数据来对齐teacher和student模型之间的输出概率。TED提出了一种任务感知的层级别的方法,包括结合额外的检索分层KD方法。这种方法包括在teacher和student模型的每一层之后添加过滤器,训练这些特定任务的过滤器,然后冻结teacher模型的过滤器,在训练student过滤器以使其输出特征与相应的teacher过滤器对齐时。MiniMoE通过使用混合专家(MoE)模型作为student模型来缓解能力差距。对于新出现的实体,预训练语言模型可能缺乏最新的信息。为了解决这个问题,一种解决方案是将额外的检索文本合并到提示中,尽管这会增加推理成本。另外,KPTD通过知识蒸馏将知识从实体定义转移到大模型参数。该方法生成一个基于实体定义的传输集,并提取student模型,以便将输出分布与基于这些定义的teacher模型相匹配。
黑盒KD(Black-box KD):黑盒KD是指teacher模型的结构和参数不可获取的知识蒸馏方法。通常,黑箱KD只使用teacher模型得到的最终结果来蒸馏student模型。在大模型领域,黑箱KD主要引导student模型学习大模型的泛化能力和涌现能力,包括InContext Learning (ICL)能力、 思维链(Chain-of-Thought, CoT)推理能力和Instruction Following (IF)能力。在ICL能力方面,Multitask-ICT引入了上下文学习蒸馏(in-context learning distillation)来转移大模型的多任务few-shot能力,同时利用上下文学习和语言建模能力。MCKD观察到,从通过语境学习得到的teacher模型中提炼出来的student模型,在看不见的输入prompt上往往表现优异。基于这一观察,MCKD设计了一个多阶段蒸馏范式,其中使用前阶段的student模型为后续阶段生成蒸馏数据,从而提高了蒸馏方法的有效性。为了提炼思维链(CoT)推理能力,诸如 Distilling Step-by-Step、SCoTD、CoT prompt、MCC-KD和Fine-tune-CoT等几种技术提出了提炼方法,将从大模型中提取的反应和基本原理结合起来训练student模型。 Socratic CoT也将推理能力转移到较小的模型。具体来说,它对一对student模型进行了微调,即问题生成(QG)模型和问题回答(QA)模型。QG模型被训练成基于输入问题生成中间问题,指导QA模型生成最终的回答。PaD观察到错误的推理(即正确的最终答案但错误的推理步骤)可能对student模型有害。为了解决这个问题,PaD建议生成合成程序用于推理问题,然后由附加的解释器自动检查。这种方法有助于去除带有错误推理的蒸馏数据,提高student模型训练数据的质量。
5.2.5 动态推理
动态推理涉及在推理过程中自适应选择模型子结构,其以输入数据为条件。此小节重点介绍early exiting的技术,这些技术使大模型能够根据特定的样本或token在不同的模型层停止其推理。值得注意的是,虽然MoE技术(在第5.1.1节中讨论)也会在推理过程中调整模型结构,但它们通常涉及昂贵的预训练成本。相比之下,这些技术只需要训练一个小模块来确定何时结束推理。本文将此类研究分为两大类:样本级别的early exiting和token级别的early exiting(如图13所示)。
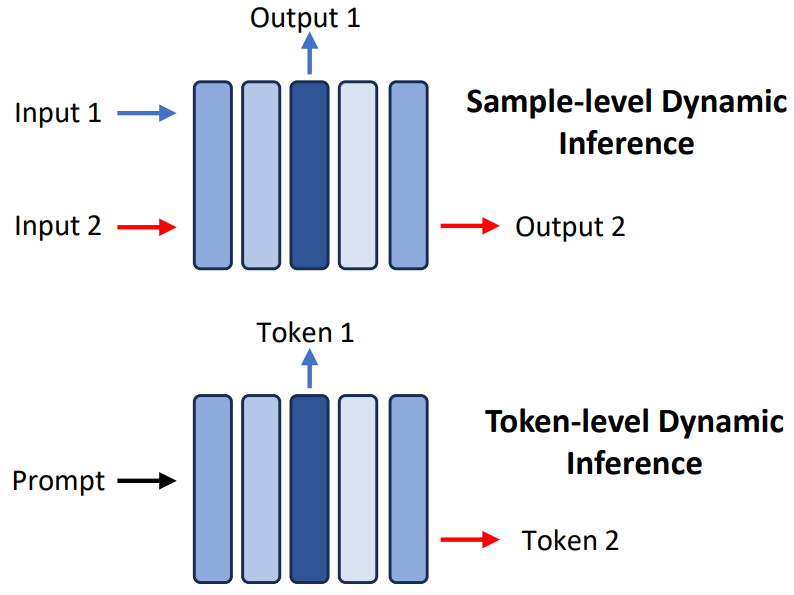
图13:token级别和样本级别的动态推理示意图
样本级别:样本级别的early exiting技术侧重于确定用于单个输入样本的大模型的最佳大小和结构。一种常见的方法是在每一层之后使用额外的模块来扩展大模型,利用这些模块来决定是否在特定层终止推理。FastBERT, DeeBERT, MP和MPEE直接训练这些模块来根据当前层的特征做出决策(例如,输出0继续或输出1停止)。Global Past-Future Early Exit提出了一种方法,利用来自前一层和后一层的语言信息丰富这些模块的输入。考虑到在推理过程中不能直接访问未来层的特征,论文训练了一个简单的前馈层来估计这些未来特征。PABEE训练模块来作为直接预测的输出头,建议在预测保持一致时终止推理。HASHEE采用了一种非参数决策方法,该方法基于相似样本应在同一层退出推理的假设。
Token级别:在大模型推理的decodig阶段,依次生成token,token级别的early exiting技术旨在优化用于每个输出token的大模型的大小和结构。CALM在每个Transformer层之后引入early exit分类器,训练它们输出置信度分数,以确定是否在特定层停止推理。值得注意的是,在self-attention模块中,计算每层当前token的特征依赖于同一层中所有先前token的特征(即KV cache)。为了解决由于先前token early exit而导致KV cache丢失的问题,CALM建议直接将该特征从现有层复制到后续层,实验结果显示只有轻微的性能下降。SkipDecode解决了先前早期存在的方法的局限性,这些方法阻碍了它们对批处理推理和KV cache的适用性,从而限制了实际的加速增益。对于批处理推理,SkipDecode为批处理中的所有token提出了一个统一的退出点。对于KV cache,SkipDecode确保了exit point的单调减少,以防止KV缓存的重新计算,从而促进了推理过程中的效率提高。
5.3 认识,建议和未来方向
在高效结构设计方面,寻找替代Transformer的结构是一个新兴的研究领域。例如,Mamba、RWKV及其各自的变种在各种任务中表现出了竞争力,近年来引起了越来越多的关注。然而,调查这些非Transformer模型与Transformer模型相比是否会表现出某些缺点仍然是相关的。同时,探索非transformer架构与注意力操作的集成是未来另一个有希望的研究方向。
在模型压缩领域,量化作为在大模型部署中使用的主要方法脱颖而出,主要是由于两个关键因素。首先,量化提供了一种方便的压缩大模型的方法。例如,使用Post-Training Quantization(PTQ)方法可以在几分钟内将具有70亿个参数的大模型的参数数分钟内减少到压缩形式。其次,量化具有实现内存消耗和推理速度大幅降低的潜力,同时只引入了很小的性能折损。对于许多实际应用,这种折损通常被认为是可以接受的。然而,值得注意的是,量化仍然可能会损害大模型的某些突发能力,例如自校准或多步推理。此外,在处理长上下文等特定场景中,量化可能导致显著的性能下降。因此,在这些特殊情况下,需要仔细选择适当的量化方法来减轻这种退化的风险。大量文献研究了稀疏注意力技术在长上下文处理中的应用。例如,最近的一项代表性工作StreamingLLM仅通过恢复几个注意力汇token就可以处理400万个token。尽管如此,这些方法往往会牺牲关键信息,从而导致性能下降。因此,在有效管理长上下文的同时保留基本信息的挑战仍然是未来探索的一个重要领域。至于权值修剪技术,LLM-KICK指出,即使在相对较低的稀疏度比下,当前最先进的(SOTA)方法也会出现相当大的性能下降。因此,开发有效的权值修剪方法来保持大模型性能仍然是一个新兴和关键的研究方向。
模型结构的优化通常涉及使用神经结构搜索(NAS),这通常需要大量的计算资源,这对其在压缩大模型中的实际应用构成了潜在的障碍。因此,相关研究采用自动结构优化进行大模型压缩的可行性值得进一步探索。此外,像低秩分解(LRF)这样的技术在压缩比和任务性能之间实现最佳平衡仍然是一个挑战。例如,ASVD在不影响大模型推理能力的情况下,只能实现适度的10%到20%的压缩比。
除了采用单独的模型压缩技术外,一些研究还探索了不同方法的组合来压缩大模型,利用各自的优势来提高效率。例如,MPOE将权重矩阵分解专门应用于基于MoE的大模型中的专家前馈网络(FFNs),目的是进一步降低内存需求。LLM-MQ利用权值稀疏性技术在模型量化过程中保护权值异常值,从而最大限度地减少量化误差。LPLR侧重于量化低秩分解权重矩阵,以进一步降低大模型推理过程中的内存占用和内存访问成本。此外,LoSparse将低秩分解与权值剪枝相结合,利用剪枝增强低秩近似的多样性,同时利用低秩分解保留重要权值,防止关键信息丢失。这些方法强调了集成多种压缩技术以更好地优化大模型的潜力。
6 系统级别优化
大模型推理的系统级优化主要涉及增强模型前向传递。考虑到大模型的计算图,存在多个算子,其中注意力算子和线性算子占据了大部分的运行时间。如2.3节所述,系统级优化主要考虑大模型中注意算子和解码方法的独特特征。特别是,为了解决大模型解码方法的具体问题,线性算子需要特殊的平铺设计,推测解码方法也被提出以提高利用率。此外,在在线服务的上下文中,请求通常来自多个用户。因此,除了前面讨论的优化之外,在线服务还面临着与异步请求引起的内存、批处理和调度相关的挑战。
6.1 推理引擎
目前对推理引擎的优化主要在于加速模型向前推理过程。对大模型推理中的主要算子和计算图进行了高度优化。此外,为了在不降低性能的前提下提高推理速度,推测解码技术也被提出。
6.1.1 图和计算优化
运行时间分析:通过HuggingFace,作者用不同的模型和上下文长度来分析推理运行时间。图15的分析结果表明,注意力计算和线性计算占据了运行时间的绝大部分,它们通常超过推理持续时间的75%。因此,大部分优化工作都致力于提高两个操作的性能。此外,有多个操作符占用了一小部分运行时间,这使得操作符的执行时间支离破碎,增加了CPU端的内核启动成本。为了解决这个问题,在图计算级别,当前优化的推理引擎实现了高度融合的算子。
注意力计算优化:标准的注意力计算(例如,使用Pytorch)包含矩阵Q与矩阵(K)的乘法,这导致时间和空间复杂度与输入序列长度呈现二次增长。如图15所示,注意力计算操作的时间占比随着上下文长度的增加而增加。这意味着对内存大小和计算能力的要求很高,特别是在处理长序列时。为了解决GPU上标准注意力计算的计算和内存开销,定制化注意力计算是必不可少的。FlashAttention将整个注意力操作融合为一个单一的、内存高效的操作,以减轻内存访问开销。输入矩阵(Q, K, V)和注意力矩阵被平铺成多个块,从而消除了完整数据加载的需要。FlashDecoding建立在Flash Attention的基础上,旨在最大限度地提高解码的计算并行性。由于译码方法的应用,Q矩阵在decoding过程中会退化为一批向量,如果并行度仅限于batch大小维度,则很难填充计算单元。FlashDecoding通过在序列维度上引入并行计算来解决这个问题。虽然这会给softmax计算带来一些同步开销,但它会显著提高并行性,特别是对于小批量大小和长序列。随后的工作FlashDecoding++观察到,在之前的工作中,softmax内的最大值仅作为防止数据溢出的比例因子。然而,动态最大值会导致显著的同步开销。此外,大量实验表明,在典型的大模型(如Llama2, ChatGLM)中,超过99.99%的softmax输入在一定范围内。因此,FlashDecoding++提出基于统计数据提前确定比例因子。这消除了softmax计算中的同步开销,使后续操作能够在softmax计算的同时并行执行。
线性计算优化:线性算子在大模型推理、特征投影和前馈神经网络(FFN)中发挥着关键作用。在传统神经网络中,线性算子可以抽象为通用矩阵-矩阵乘法(General Matrix-Matrix Multiplication, GEMM)运算。然而,对于大模型,decoding方法的应用导致维度的明显降低,与传统的GEMM工作负载不同。传统GEMM的底层实现得到了高度优化,主流大模型推理框架(例如,DeepSpeed , vLLM, OpenPPL等)主要调用cuBLAS为线性算子提供的GEMM API接口。
如果没有针对降低维数的GEMM明确定制的实现,decoding过程中的线性计算将会效率低下。在最新版本的TensorRT-LLM中可以观察到解决该问题的issue。它引入了专用的通用矩阵向量乘法(General Matrix-Vector Multiplication, GEMV)实现,潜在地提高了decoding步骤的效率。最近的研究FlashDecoding++做了进一步的改进,在解码步骤中处理小批量数据时,解决了cuBLAS和CUTLASS库的低效率问题。该研究的作者首先引入了FlatGEMM操作的概念,以高度降低的维度(FlashDecoding++中的维数< 8)来表示GEMM的工作负载。由于FlatGEMM具有新的计算特性,传统GEMM的平铺策略需要进行修改。作者观察到,随着工作负载的变化,存在两个问题:低并行性和内存访问瓶颈。
为了解决这些问题,FlashDecoding++采用了细粒度平铺策略来提高并行性,并利用双缓冲技术来隐藏内存访问延迟。此外,当前经典大模型(例如,Llama2, ChatGLM)中的线性操作通常具有固定的形状,FlashDecoding++建立了启发式选择机制。这个机制根据输入大小在不同的线性运算符之间进行动态地选择转换。这些选项包括FastGEMV、FlatGEMM和由cuBLAS库提供的GEMM。这种方法确保为给定的线性工作负载选择最有效的计算操作,从而可能导致更好的端到端性能。
近年来,应用MoE FFN来增强模型能力已成为大模型研究的一种趋势。这种模型结构也对算子优化提出了新的要求。如图15所示,在具有MoE FFN的Mixtral模型中,由于HuggingFace实现中未优化FFN计算,线性算子在运行时占主导地位。此外,Mixtral采用了GQA注意结构,其降低了注意力算子的运行时间比例,进一步指出了对优化FFN层迫切需要。MegaBlocks是第一个针对MoE FFN层优化计算的算法。该工作将MoE FFN计算制定为块稀疏操作,并提出了用于加速的定制GPU内核。MegaBlocks专注于MoE模型的有效训练,因此忽略了推理的特征(例如,解码方法)。现有框架正在努力优化MoE FFN推理阶段的计算。vLLM的官方在Triton中集成了MoE FFN的融合内核,无缝地消除了索引开销。
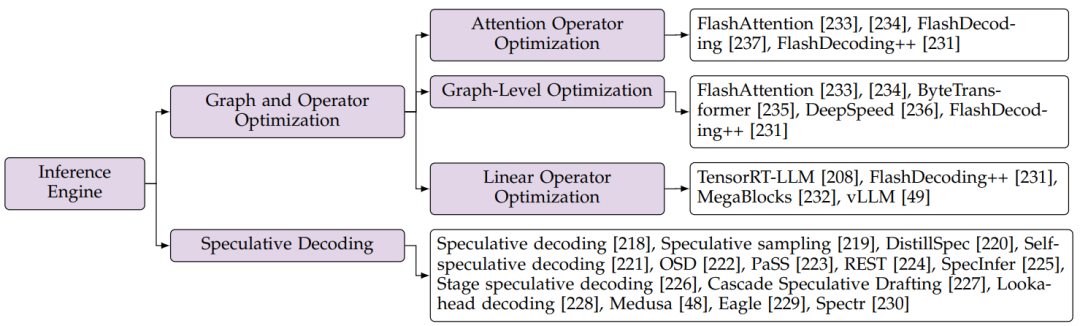
图14:大模型推理引擎优化分类
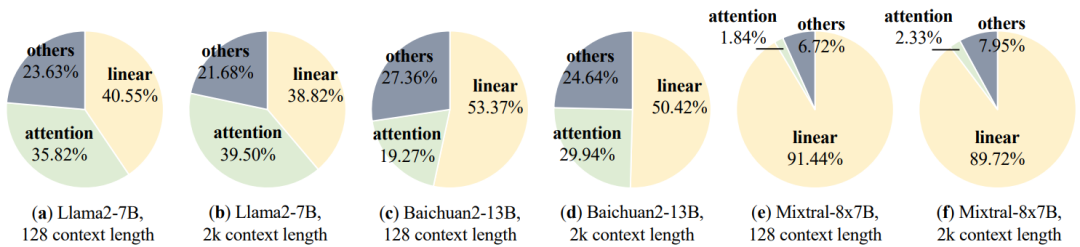
图15:多个大模型的推理运行时间分析
图级别的优化:核融合作为一种流行的图级优化脱颖而出,因为它能够减少运行时间。应用核融合有三个主要优点:(1)减少内存访问。融合内核从本质上消除了中间结果的内存访问,减轻了计算操作的内存瓶颈。(2)减轻内核启动开销。对于一些轻量级操作(如残差add),内核启动时间占据了大部分延迟,内核融合减少了单个内核的启动。(3)增强并行性。对于那些没有数据依赖的运算符,当单个内核执行无法填充硬件容量时,通过融合实现内核并行是有益的。
核融合技术被证明对大模型推理是有效的,具有上述所有优点。FlashAttention将注意力运算符表述成一个单一的内核,消除了访问注意力结果的开销。基于注意力算子是内存有限的这一事实,内存访问的减少能有效地转化为运行时加速。ByteTransformer和DeepSpeed提出将包括残差加法、层模和激活函数在内的轻量级算子融合到前线性算子中,以减少内核启动开销。
和DeepSpeed[236]提出将包括残差add、layernorm和激活函数在内的轻量级算子融合到前面的线性算子中,以减少内核启动开销。因此,这些轻量级操作符在时间轴上消失,几乎没有额外的延迟。此外,还采用核融合来提高大模型推理的利用率。Q、K和V矩阵的投影变换原本是三个单独的线性运算,并融合成一个线性运算符部署在现代GPU上。目前,核融合技术已经应用于大模型推理实践中,高度优化的推理引擎在运行时只使用少数融合核。例如,在FlashDecoding++实现中,一个transformer块仅集成了七个融合的内核。利用上述运算符和内核融合优化,FlashDecoding++实现了在HuggingFace高达4.86倍的加速。
6.1.2 推测解码
推测解码(如投机采样)是一种用于自回归大模型的创新解码技术,旨在提高解码效率,同时不影响输出的质量。这种方法的核心思想包括使用一个较小的模型(称为草稿模型)来有效地预测几个后续token,然后使用目标大模型并行验证这些预测。该方法旨在使大模型能够在单个推理通常所需的时间范围内生成多个token。图16显示了传统自回归解码方法与推测解码方法的比较。理论上,推测解码方法包括两个步骤:
1)草稿构建:采用草稿模型,以并行或自回归的方式生成多个后续token,即Draft token。2)草案验证:利用目标模型在单个大模型推理步骤中计算所有草稿token的条件概率,随后依次确定每个草稿token的接受程度。接受率表示每个推理步骤接受的草稿token的平均数量,是评估推测解码算法性能的关键指标。
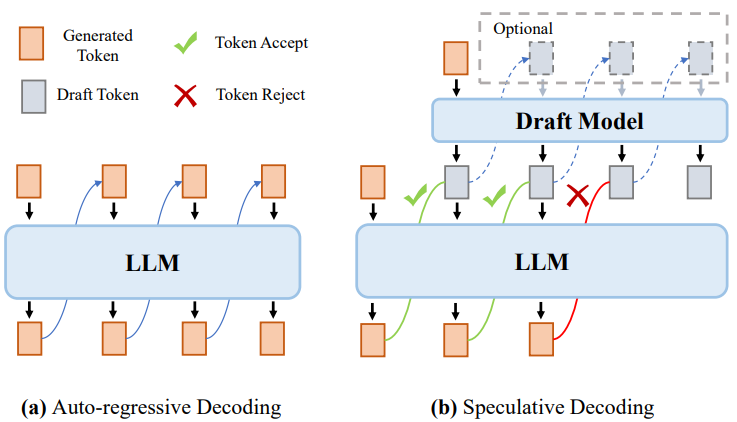
图16:自回归解码(a)和推测解码(b)对比
推测解码确保了输出与自回归解码方法的质量对等。传统解码技术主要使用两个采样方法:greedy sampling和 nucleus sampling。greedy sampling涉及在每个解码步骤中选择概率最高的令牌来生成特定的输出序列。推测解码的最初工作,被称为Blockwise Parallel Decoding,旨在确保草草稿token与通过greedy sampling的token实现精确匹配,从而保持输出令牌等价。相比之下,nucleus sampling涉及从概率分布中抽样token,每次运行都会产生不同的token序列。这种多样性使得nucleus sampling很受欢迎。为了在推测解码框架内容纳nucleus sampling,已经提出了投机采样技术。投机采样保持输出分布不变,与nucleus sampling的概率性质一致,以产生不同的标记序列。形式上,给定一个token序列和一个草稿token序列,投机采样策略以以下概率接受第i个草稿token:
其中和分别代表来自目标大模型和草稿模型的概率分布。如果第个token被接受,它设定为。另外,它退出草稿token的验证,并从下面的分布中进行的重采样:
基于投机采样,出现了几种变体,旨在验证多个草稿token序列。值得注意的是,在这种情况下,token tree verfier已成为一种广泛采用的验证策略。这种方法利用草稿token集的树状结构表示,并采用树注意力机制来有效地执行验证过程。
在推测解码方法中,草稿token的接受率受到草稿模型的输出分布与原始大模型的输出分布的一致程度的显著影响。因此,大量的研究工作都是为了改进草稿模型。DistillSpec直接从目标大模型中提取较小的草稿模型。SSD包括从目标大模型中自动识别子模型(模型层的子集)作为草稿模型,从而消除了对草稿模型进行单独训练的需要。OSD动态调整草稿模型的输出分布,以匹配在线大模型服务中的用户查询分布。它通过监视来自大模型的被拒绝的草稿token,并使用该数据通过蒸馏来改进草稿模型来实现这一点。PaSS提出利用目标大模型本身作为草稿模型,将可训练的token(look -ahead token)作为输入序列,以同时生成后续token。REST引入了一种基于检索的推测解码方法,采用非参数检索数据存储作为草稿模型。SpecInfer引入了一种集体提升调优技术来对齐一组草稿模型的输出分布通过目标大模型。Lookahead decoding 包含大模型生成并行的生成n-grams来生成草稿token。Medusa对大模型的几个头进行微调,专门用于生成后续的草稿token。Eagle采用一种称为自回归头的轻量级Transformer层,以自回归的方式生成草稿token,将目标大模型的丰富上下文特征集成到草稿模型的输入中。
另一项研究侧重于设计更有效的草稿构建策略。传统的方法通常产生单一的草稿token序列,这对通过验证提出了挑战。对此,Spectr主张生成多个草稿token序列,并采用k-sequential草稿选择技术并发验证k个序列。该方法利用推测抽样,确保输出分布的一致性。类似地,SpecInfer采用了类似的方法。然而,与Spectr不同的是,SpecInfer将草稿token序列合并到一个“token tree”中,并引入了一个用于验证的树形注意力机制。这种策略被称为“token tree verifier”。由于其有效性,token tree verifier在众多推测解码算法中被广泛采用。除了这些努力之外,Stage Speculative Decoding和Cascade Speculative Drafting(CS Drafting)建议通过将投机解码直接集成到token生成过程中来加速草稿构建。
对比实验与分析:论文作者通过实验来评估推测解码方法的加速性能。具体来说,作者对该领域的研究进行了全面的回顾,并选择了其中6个已经开源的代码进行研究,分别是:Speculative Decoding (SpD)、Lookahead Decoding (LADE)、REST、Self-speculative Decoding (SSD)、Medusa和Eagle。对于评估数据集,使用Vicuna-80对上述方法进行评估,该数据集包含80个问题,分为10类。这80个问题的平均结果作为输出。对于目标大模型,作者采用了五个主流的开源大模型,分别是Vicuna-7B-V1.3、Vicuna-13B-V1.3、Vicuna-33B-V1.3、LLaMA-2-7B和LLaMA-2-13B。作者展示了这5个大模型的评估指标范围。对于草稿模型,作者对SpD采用了两个个训练好的草稿模型,即LLaMA-68M和LLaMA-160M。对于其他推测解码方法,作者遵循它们提出的草稿构建方法和使用他们提供的权重。在评价指标方面,作者使用接受率和加速率,接受率是指接受token数与生成步数之比,加速比是指在确定输出总长度时,原始自回归解码的延迟与推测解码的延迟之比。
表5提供了各种推测解码方法的比较,突出了几个关键观察结果:(1) Eagle表现出优异的性能,在多个大模型上实现了3.47~3.72倍的端到端加速。为了理解它的成功,作者对Eagle的深入分析揭示了两个关键因素。首先,Eagle采用自回归方法来解码草稿token,直接利用先前生成的token的信息。其次,Eagle集成了原始大模型和草案模型的先前token的丰富特征,以提高下一个草稿token生成的准确性。(2) token tree verifier被证明在提升投机采样方法的性能中是有效的。(3)这些方法实现的端到端加速往往低于接受率。这种差异是由于与草稿模型相关的生成成本不可忽视的实际考虑而产生的。
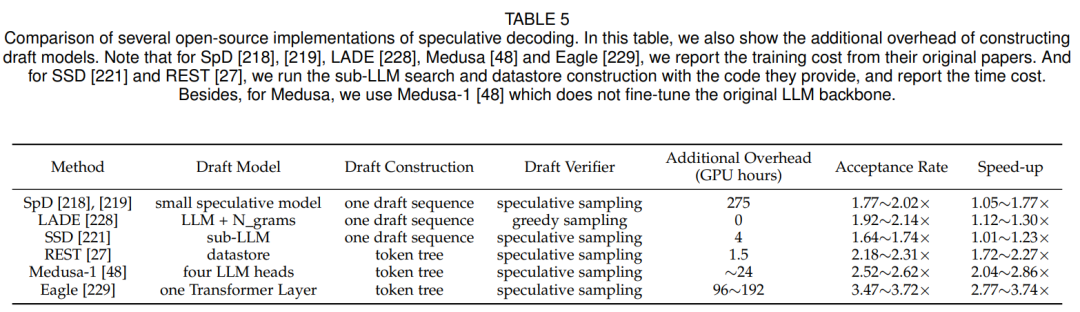
表5:实验结果
6.2 推理服务系统
推理服务系统的优化主要在于提高处理异步请求的效率。优化了内存管理以容纳更多的请求,并集成了高效的批处理和调度策略以提高系统吞吐量。此外,提出了针对分布式系统的优化方法,以充分利用分布式计算资源。
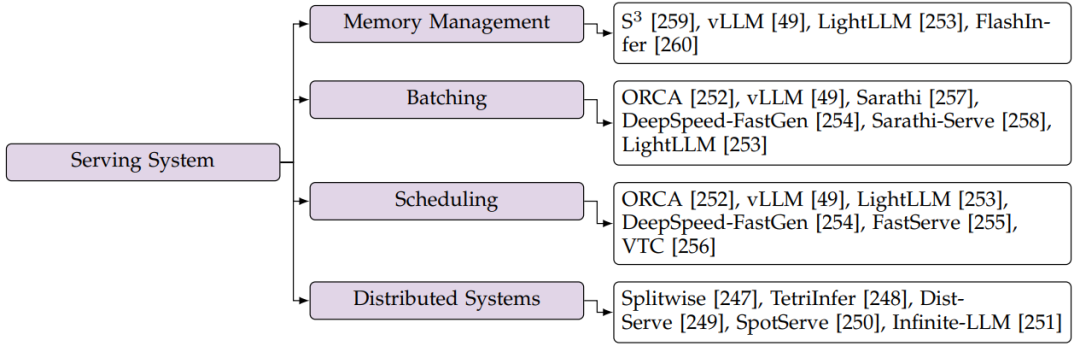
图17:推理服务系统分类图
6.2.1内存管理
在大模型服务中,KV缓存的存储决定了内存的使用,特别是当上下文长度很长时(参见第2.3节)。由于生成长度不确定,提前分配KV cache存储空间很难。早期的实现通常根据每个请求的预设最大长度预先分配存储空间。但是,在终止请求生成的时,这种方法会导致存储资源的大量浪费。为了解决这个问题,为了减少预分配空间的浪费,提出了为每个请求预测生成长度的上界。
但是,当不存在如此大的连续空间时,静态的KV缓存分配方式仍然是失败的。为了应对碎片化存储,vLLM提出以操作系统的样式,以分页的方式存储KV缓存。vLLM首先分配尽可能大的内存空间,并将其平均划分为多个物理块。当请求来临时,vLLM以不连续的方式动态地将生成的KV缓存映射到预分配的物理块。通过这种方式,vLLM显著减少了存储碎片,并在大模型服务中实现了更高的吞吐量。在vLLM的基础上,LightLLM使用了更细粒度的KV缓存存储,减少了不规则边界产生的浪费。LightLLM将token的KV缓存作为一个单元来处理,而不是一个块,因此生成的KV缓存总是使预分配的空间饱和。
当前优化的推理服务系统通常采用这种分页方式来管理KV缓存存储,从而减少冗余KV缓存的浪费。然而,分页存储导致注意力操作中的内存访问不规则。对于使用分页KV缓存的注意力算子,这就需要考虑KV缓存的虚拟地址空间与其对应的物理地址空间之间的映射关系。为了提高注意力算子的计算效率,必须对KV缓存的加载模式进行调整,以方便连续存储器访问。例如,在vLLM的PagedAttention中,对于K cache,head大小维度的存储结构为16字节的连续向量,而FlashInfer为KV缓存编排了各种数据布局,并伴随着适当设计的内存访问方案。注意力算子的优化与页面KV缓存存储的结合仍然是推理服务系统发展中的一个前沿挑战。
6.2.2 连续批处理
批处理中的请求长度可能不同,当较短的请求完成而较长的请求仍在运行时,会导致利用率较低。由于服务场景中的请求具有异步特性,因此缓解这种低利用率的时间段是有可能的。基于此,连续批处理技术被提出,以便在一些旧请求完成后对新请求进行批处理。ORCA是在大模型服务端第一个这样做的工作。
每个请求的计算包含多个迭代,每个迭代表示预填充步骤或解码步骤。作者建议可以在迭代级别对不同的请求进行批处理。此工作在线性操作符中实现迭代级批处理,在序列维度中将不同的请求连接在一起。因此,与完成的请求相对应的备用存储和计算资源被及时释放。继ORCA之后,vLLM将该技术扩展到注意力计算,使不同KV缓存长度的请求能够批处理在一起。Sarathi、DeepSpeed-FastGen和SarathiServe进一步引入了一种split-and-fuse方法,将预填充请求和解码请求批处理在一起。具体来说,此方法首先在序列维度上拆分长预填充请求,然后将其与多个短解码请求批处理在一起。该方法平衡了不同迭代之间的工作负载,并通过消除新请求的延迟显著减少了尾部延迟。LightLLM也采用了split-and-fuse方法。
6.2.3 Scheduling技术
在大模型服务中,每个请求的作业长度具有可变性,因此执行请求的顺序会显著影响服务系统的吞吐量。head-of-line blocking发生在长请求被赋予优先级时。具体来说,对于长请求,内存使用会迅速增长,当系统内存容量耗尽时,会导致后续请求受阻。ORCA和开源框架,包括vLLM和LightLLM,采用简单的先到先服务(FCFS)原则来调度请求。DeepSpeed-FastGen则优先考虑解码请求以提高性能。FastServe提出了一种抢占式调度策略来优化排队阻塞问题,实现大模型服务的低作业完成时间(JCT)。FastServe采用多级反馈队列(MLFQ)来优先处理剩余时间最短的请求。由于自动回归解码方法会产生未知的请求长度,FastServe首先预测长度,并利用跳过连接方式为每个请求找到适当的优先级。与以往的工作不同,VTC讨论了大模型推理服务中的公平性。VTC引入了一个基于token数的成本函数来衡量客户端之间的公平性,并进一步提出了一个公平调度程序来确保公平性。
6.2.4 分布式系统
为了实现高吞吐量,大模型服务通常部署在分布式平台上。最近的工作还侧重于通过利用分布式特征来优化此类推理服务的性能。值得注意的是,预填充是计算密集型的,解码是内存密集型的,splitwise, TetriInfer和DistServe证明了分解请求的预填充和解码步骤的效率。这样,两个不同的阶段就可以根据各自的特点进行独立的处理。SpotServe设计用于在具有可抢占GPU实例的云上提供大模型服务。SpotServe有效地处理包括动态并行控制和实例迁移在内的挑战,并且还利用大模型的自回归特性来实现token级别的状态恢复。此外,Infinite-LLM将vLLM中的分页KV缓存方法扩展到分布式云环境。
6.3 硬件加速器设计
过去的研究工作集中在优化Transformer架构,特别是优化注意力算子,通常采用稀疏方法来促进FPGA部署。与NVIDIA V100 GPU相比,FACT加速器通过线性运算的混合精度量化和算法-硬件协同设计实现了卓越的能效,而且这些方法不是为生成式大模型量身定制的。
近期的工作,如ALLO突出了FPGA在管理内存密集型解码阶段方面的优势。强调了模型压缩技术对大模型高效FPGA部署的重要性。相反,DFX侧重于解码阶段优化,但缺少模型压缩方法,限制了可扩展性在更大的模型和更长的输入(最多1.5B模型和256个token)。ALLO建立在这些见解的基础上,进一步提供了一个可组合和可重用的高级合成(High-level Synthesis, HLS)内核库。与DFX相比,ALLO的实现在预填充阶段展示了卓越的生成加速,在解码期间实现了比NVIDIA A100 GPU更高的能效和加速。
FlightLLM也利用了这些见解,引入了一个可配置的稀疏数字信号处理器(DSP)链,用于各种具有高计算效率的稀疏模式。为了提高存储带宽利用率,提出了一种支持混合精度的片上译码方案。FlightLLM在Llama2-7B型号上实现了比NVIDIA V100S GPU高6.0倍的能效和1.8倍的成本效益,解码时的吞吐量比NVIDIA A100 GPU高1.2倍。
6.4 大模型推理框架对比
作者对比了多个推理框架的性能,如表6所示。使用Llama2-7B(batch size=1,输入长度=1k,输出长度=128)测量推理吞吐量。推理服务性能是在ShareGPT数据集上测量的最大吞吐量。两者都基于单个NVIDIA A100 80GB GPU。在上述框架中,DeepSpeed、vLLM、LightLLM和TensorRT-LLM集成了推理服务功能,为来自多个用户的异步请求提供服务。作者还在表格中列出了每个框架的优化。作者还在表中列出了针对每个框架的优化。除了HuggingFace外,所有框架都实现了operator级别或图优化级别的优化以提高性能,其中一些框架还支持推测解码技术。请注意,作者测量所有框架的推理性能时,没有使用推测解码技术。推理吞吐量的结果表明,FlashDecoding++和TensorRT-LLM在覆盖主要算子和计算图的优化方面优于其他算法。在推理服务方面,各框架均采用细粒度、不连续存储方式进行KV缓存,并采用连续批处理技术提高系统利用率。与vLLM和LightLLM不同,DeepSpeed在调度中优先考虑解码请求,这意味着如果批处理中有足够的现有解码请求,则不会合并新请求。

表6:开源推理框架性能对比
6.5 认识,建议和未来方向
系统级优化在不降低精度的同时提高了效率,因此在大模型推理实践中越来越普遍。对推理的优化也适用于服务。最近,operator优化已经与实际服务场景紧密结合,例如,专门为前缀缓存设计的RadixAttention和加速推测解码验证的tree attention。应用和场景的迭代将不断对operator的发展提出新的要求。
考虑到实际推理服务系统中固有的多方面目标,例如JCT、系统吞吐量和公平性,调度策略的设计相应地变得复杂。在请求长度不确定的大模型服务领域,现有文献通常依赖于预测机制来促进调度策略的设计。然而,目前的预测器的有效性达不到理想的标准,这表明在服务调度策略开发中存在改进和优化的潜力。
7 关键应用场景讨论
目前的研究在探索跨各种优化级别的高效大模型推理的边界方面取得了重大进展。然而,需要进一步的研究来提高大模型在实际场景中的效率。作者为数据级(第4.3节)、模型级(第5.3节)和系统级(第6.5节)的优化技术分析了有希望的未来方向。在本节中,作者总结了四个关键场景:Agent and Multi-Model Framework、Long-Context LLMs、Edge Scenario Deployment和安Security-Efficiency Synergy,并对它们进行了更广泛的讨论。
Agent and Multi-Model Framework:如4.3章所讨论,Agent 和Multi-Model框架的最近工作,通过利用大模型的强大能力,显著提高了Agent处理复杂任务和人类请求的能力。这些框架在增加大模型计算需求的同时,在大模型输出内容的结构中引入了更多的并行性,从而为数据级和系统级优化(如输出组织技术)创造了机会。此外,这些框架自然地引入了一个新的优化级别,即pipeline级别,它具有在该级别上提高效率的潜力。
此外,越来越多的研究趋势侧重于将AI智能体扩展到多模态领域,通常使用多模态大模型(Large multimodal Models, LMM)作为这些Agent系统的核心。为了提高这些新兴的基于LMM的智能体的效率,为LMM设计优化技术是一个很有前途的研究方向。
Long-Context LLMs:目前,大模型面临着处理越来越长的输入上下文的挑战。然而,自注意力操作(Transformer-style大模型的基本组成部分)表现出与上下文长度相关的二次复杂度,对最大上下文长度施加了限制在训练和推理阶段。各种策略已经被探索了来解决这一限制,包括输入压缩(第4.1节)、稀疏注意力(第5.2.2节)、低复杂度结构的设计(第5.1.3节)和注意算子的优化(第6.1.1节)。值得注意的是,具有次二次或线性复杂性的非transformer架构(第5.1.3节)最近引起了研究人员的极大兴趣。
尽管它们效率很高,但与Transformer架构相比,这些新架构在各种能力(如上下文学习能力和远程建模能力)上的竞争力仍有待考察。因此,从多个角度探索这些新架构的功能并解决它们的局限性仍然是一个有价值的追求。此外,为各种场景和任务确定必要的上下文长度,以及确定将作为未来大模型基础支柱的下一代架构,这一点至关重要。
Edge Scenario Deployment:尽管提高大模型推理的效率已经有了许多工作,但将大模型部署到资源极其有限的边缘设备(如移动电话)上仍然存在挑战。最近,许多研究人员对具有1B ~ 3B参数的较小语言模型的预训练表现出了兴趣。这种规模的模型在推理过程中提供了更少的资源成本,并且与更大的模型相比,具有实现泛化能力和竞争性能的潜力。然而,开发如此高效和强大的小型语言模型的方法仍然没有得到充分的探索。
一些研究已经开启了这个有希望的方向。例如,MiniCPM通过沙盒实验来确定最优的预训练超参数。PanGu-π-Pro建议使用来自模型修剪的矩阵和技术来初始化预训练打磨谢谢的模型权重。MobileLLM在小型模型设计中采用了“深而薄”的架构,并提出了跨不同层的权重共享,在不增加额外内存成本的情况下增加层数。然而,小模型和大模型之间仍存在性能差距,需要未来的研究来缩小这一差距。未来,迫切需要研究如何识别边缘场景下的模型尺度,并探索各种优化方法在设计上的边界。
除了设计较小的模型之外,系统级优化为大模型部署提供了一个有前途的方向。最近一个值得注意的项目,MLC-LLM成功地在移动电话上部署了LLaMA-7B模型。MLC-LLM主要使用融合、内存规划和循环优化等编译技术来增强延迟并降低推理期间的内存成本。此外,采用云边缘协作技术或设计更复杂的硬件加速器也可以帮助将大模型部署到边缘设备上。
Security-Efficiency Synergy:除了任务性能和效率外,安全性也是大模型应用中必须考虑的关键因素。目前的研究主要集中在效率优化方面,没有充分解决安全考虑的操作。因此,研究效率和安全性之间的相互作用,并确定当前的优化技术是否会损害大模型的安全性是至关重要的。如果这些技术对大模型的安全性产生负面影响,一个有希望的方向是开发新的优化方法或改进现有的方法,以实现大模型的效率和安全性之间更好的权衡。
8 总结
高效的大模型推理侧重于减少大模型推理过程中的计算、内存访问和内存成本,旨在优化诸如延迟、吞吐量、存储、功率和能源等效率指标。作者在本综述中提供了高效大模型推理研究的全面回顾,提出了关键技术的见解,建议和未来方向。首先,作者引入了包含数据级、模型级和系统级优化的分层分类法。随后,在这一分类方法的指导下,作者总结每个层次和子领域的研究。对于模型量化和高效服务系统等成熟的技术,作者进行了实验来评估和分析它们的性能。在此基础上,提出了实践建议。为该领域的从业者和研究人员提出建议并确定有前途的研究途径。
-
大模型
+关注
关注
2文章
2407浏览量
2622 -
LLM
+关注
关注
0文章
285浏览量
325
原文标题:3万字详细解析清华大学最新综述工作:大模型高效推理综述
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
用tflite接口调用tensorflow模型进行推理
【飞凌RK3568开发板试用体验】RKNN模型推理测试
压缩模型会加速推理吗?
如何提高YOLOv4模型的推理性能?
AscendCL快速入门——模型推理篇(上)
HarmonyOS:使用MindSpore Lite引擎进行模型推理
主流大模型推理框架盘点解析
澎峰科技发布大模型推理引擎PerfXLLM
基于LLM的表格数据的大模型推理综述

自然语言处理应用LLM推理优化综述







 工商网监
工商网监
评论