 OrangePi KunPeng Pro部署AI模型介绍
OrangePi KunPeng Pro部署AI模型介绍
一、OrangePi Kunpeng Pro简介
OrangePi Kunpeng Pro是一款香橙派联合华为精心打造的高性能板卡,搭载了鲲鹏处理器,可提供8TOPS INT8计算能力,板卡设计很精致,板载资源也非常多:
•拥有以太网、Wi-Fi+蓝牙功能,提供多种可选择的网络接入方式。
• 2个USB3.0 Host、1个支持USB3.0的Type-C接口:可接入鼠标、键盘、USB摄像头等设备,方便板卡操作。
• 2个HDMI接口、1 个 MIPI DSI 2 Lane接口,提供两种显示方案。
•引出了40 pin 扩展口,可扩展UART、I2C、SPI、PWM 和 GPIO 等接口功能。板卡完整接口如下图所示:

板卡扩展出的功能很多,能够满足很多应用场景和行业的开发需求,本文将描述使用OrangePi Kunpeng Pro来部署AI大模型,记录分析模型运行期间板卡的状态和模型运行效果。
二、环境搭建
(1)首先取出板卡,为板卡接入一个HDMI显示屏、一个无线蓝牙鼠标、一个有线键盘,接着接通电源,完成后如下图所示:

(2)随后板卡将自动启动运行openEuler操作系统,接着我们进入终端:
(3)查看下存储容量:
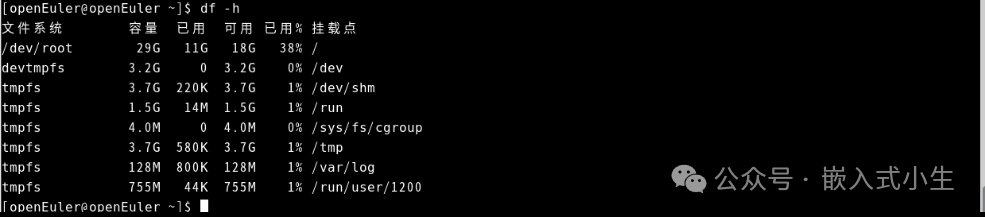
从上图可知目前可用容量很大,可满足小量级离线模型的存储。
板卡运行openEuler非常流畅,使用体验感非常好。
(4)选择网络接入方式,本文使用Wifi接入。
(5)更改CPU为AI CPU

从上图中可知目前板卡有3个AI CPU和1个control CPU。
接着就进行模型运行环境搭建和模型部署了。
三、模型运行环境搭建
(1)下载Ollama用于启动并运行大型语言模型
由于在线下载Ollama速度较慢,故而使用手动方式安装Ollama,首先从下列地址下载Ollama:
https://ollama.com/download/ollama-linux-arm64
完成后将其通过ssh方式传输到板卡。接着将其重名为ollama,便于命令操作,然后将ollama复制到/usr/bin目录中并赋予可执行权限:
sudochmod+x/usr/bin/ollama
(2)配置ollama系统服务
使用以下命令创建ollama服务描述文件:
sudotouch/etc/systemd/system/ollama.service
并在文件中编辑如下内容:
[Unit] Description=OllamaService After=network-online.target [Service] ExecStart=/usr/bin/ollamaserve User=root Group=root Restart=always RestartSec=3 [Install] WantedBy=default.target
(3)启动ollama服务
使用下述命令启动ollama服务:
sudosystemctldaemon-reload sudosystemctlenableollama
(4)启动ollama
使用下述命令启动ollama:
sudosystemctlstartollama
(5)查看ollama运行状态
使用如下命令查看ollama运行状态:
systemctlstatusollama.service

从上图可知目前ollama启动成功。
四、模型部署
通过上述第三小节的步骤后,Ollama模型运行环境就搭建完成,本小节将部署五个模型:1.8b的qwen、2b的gemma、3.8b的phi3、4b的qwen和7b的llama2,测试OrangePi Kunpeng Pro运行模型的实际效果。模型细节如下表所示:
| 序号 | 模型 | 参数 | 描述 |
| 1 | qwen | 1.8b | Qwen是阿里云开发的大型语言模型,1.8b,1.1GB |
| 2 | gemma | 2b | Gemma是由Google DeepMind构建的一系列轻量级的开放模型,大小1.7GB |
| 3 | phi3 | 3.8b | phi3是微软开发的开放AI模型系列,3.8b为Mini系列,大小2.4GB |
| 4 | qwen | 4b | Qwen是阿里云开发的大型语言模型,4b,大小2.3GB |
| 5 | llama2 | 7b | Llama 2是由Meta平台公司发行的基础语言模型,大小3.8GB |
(1)部署1.8b的qwen
使用ollama run qwen:1.8b部署1.8b的qwen模型:

上述模型部署完成后,对其进行问答测试,如下图所示:
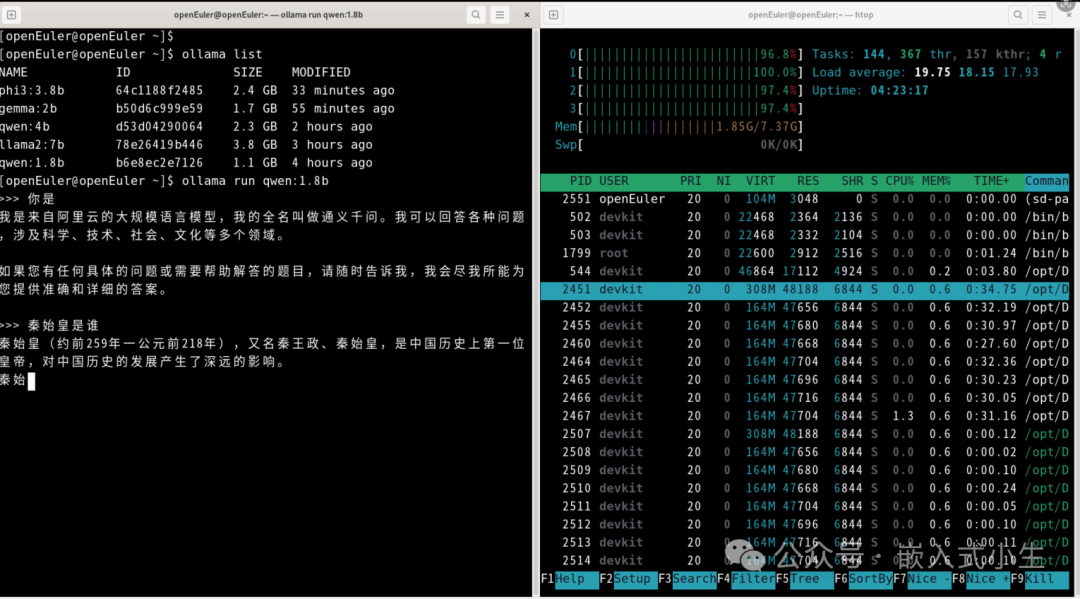
效果:运行1.8b的qwen模型,CPU负载没有占满,进行问答测试,回答速度较快,效果很好!
(2)部署2b的gemma
使用ollama run gemma:2b部署2b的gemma模型:

上述模型部署完成后,对其进行问答测试,如下图所示:
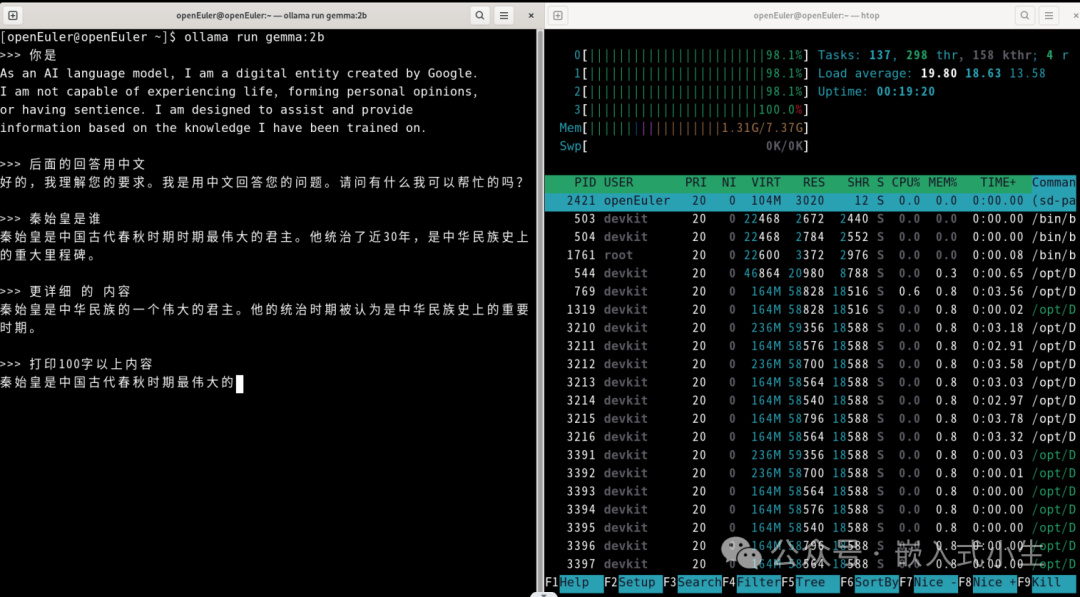
效果:运行2b的gemma模型和运行1.8b的qwen模型效果相似,CPU负载同样没有占满,进行问答测试,回答速度快,效果好!
(3)部署3.8的phi3
使用ollama run phi3:3.8b部署3.8b的phi3模型:
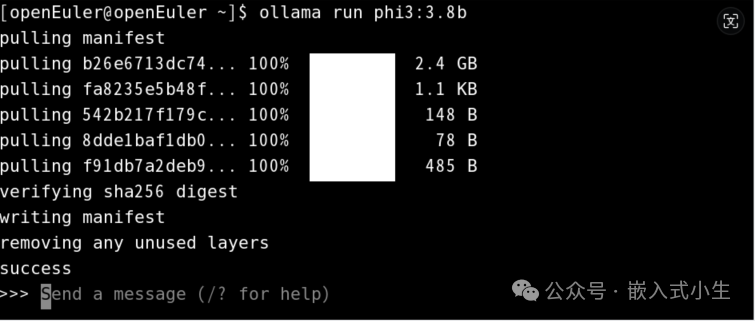
上述模型部署完成后,对其进行问答测试,如下图所示:
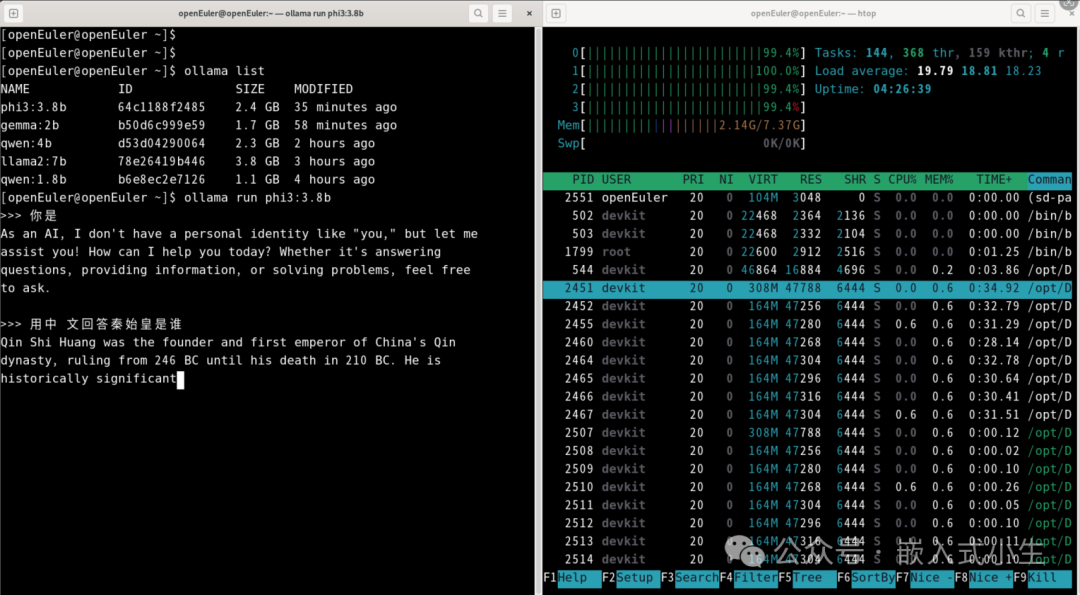
效果:运行3.8b的phi3模型,进行问答测试,回答速度变慢了。
(4)部署4b的qwen
使用ollama run qwen:4b部署4b的qwen模型:

上述模型部署完成后,对其进行问答测试,如下图所示:
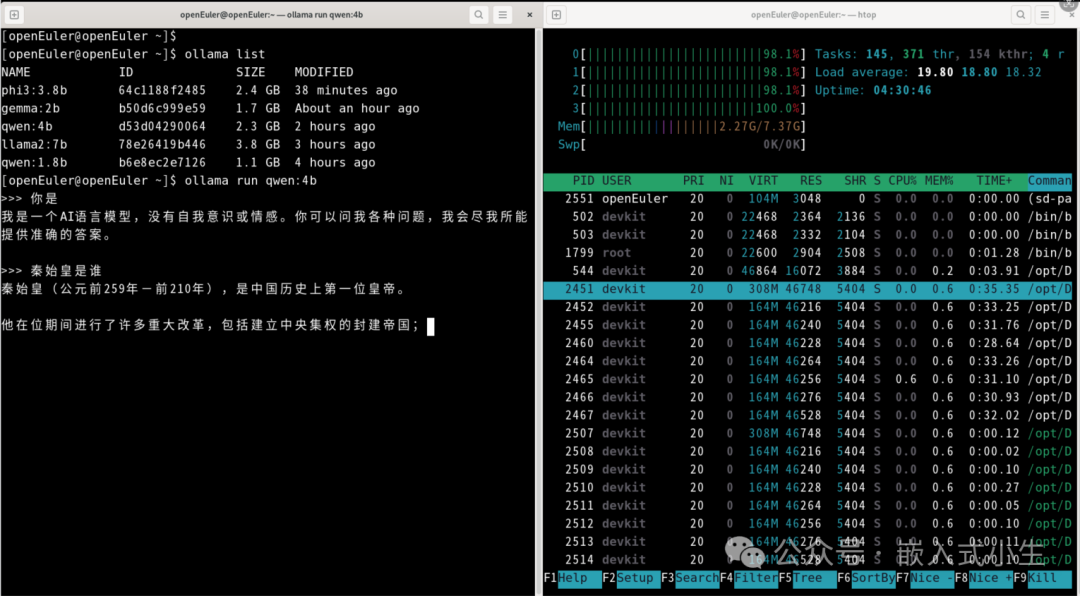
效果:运行4b的qwen模型,进行问答测试,回答问题速度明显变慢:计算生成答案的速度变慢,打印文字的速度也变慢了。
(5)部署7b的llama2
使用ollama run llama2:7b部署7b的llama2模型:

上述模型部署完成后,对其进行问答测试,如下图所示:
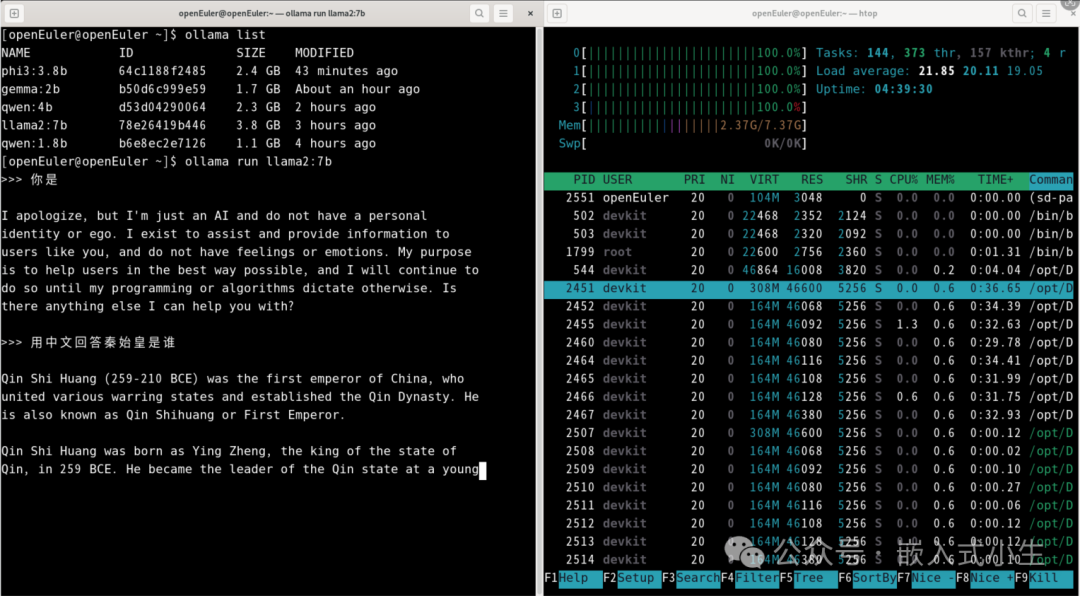
效果:运行7b的llama2模型,CPU满负载了,进行问答测试,回答问题速度也明显变得很慢:计算生成答案的速度变慢,打印文字的速度也变慢了。
五、实际效果
上述第四小节描述了运行五个模型的实际使用效果,本小节附上运行2b的gemma模型的效果,如下图所示:
(注:因gif图对视频有所处理,以实际运行效果为准!)
六、总结
OrangePi Kunpeng Pro板卡是一块拥有较高计算性能的板卡,本文使用该板卡部署了五个模型(以本文所描述模型为参考),对于1.8b和2b量级的模型来说运行效果还可以,体验较好;对于3.8b和4b量级的模型来说,体验感有所下降,一是计算生成答案的过程变长,二是文字输出存在断续;对于7b量级的模型,体验感更是降了一个层次,文字输出存在明显的断续了。
体验感是一个非理性的名词,因人而异,不同的场景和模型,不同的使用者都可能存在不同的体验,本文所有内容仅供参考和评测!
-
AI
+关注
关注
87文章
32328浏览量
271425 -
板卡
+关注
关注
3文章
119浏览量
16944 -
模型
+关注
关注
1文章
3406浏览量
49457
原文标题:玩玩OrangePi KunPeng Pro部署AI模型
文章出处:【微信号:嵌入式小生,微信公众号:嵌入式小生】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
香橙派发布OrangePi 5Plus本地部署Deepseek-R1蒸馏模型指南

云轴科技ZStack智塔携手昇腾AI实现DeepSeek模型部署

C#集成OpenVINO™:简化AI模型部署

添越智创基于 RK3588 开发板部署测试 DeepSeek 模型全攻略
中兴通讯AiCube:破解AI模型部署难题
企业AI模型部署攻略
AI模型部署边缘设备的奇妙之旅:目标检测模型
AI模型部署边缘设备的奇妙之旅:如何实现手写数字识别
如何在STM32f4系列开发板上部署STM32Cube.AI,
香橙派OrangePi 5 Pro性能全面测试!

树莓派5最大的竞争对手OrangePi 5 Pro ,新增4GB/8GB版本

OrangePi 5 Pro正式开售,树莓派5真正的挑战者来了






 工商网监
工商网监
评论