 英特尔助力百度智能云千帆大模型平台加速LLM推理
英特尔助力百度智能云千帆大模型平台加速LLM推理
“大模型在各行业的广泛应用驱动了新一轮产业革命,也凸显了在AI算力方面的瓶颈。通过携手英特尔释放英特尔 至强 可扩展处理器的算力潜力,我们为用户提供了高性能、灵活、经济的算力基础设施方案,结合千帆大模型平台在大模型工具链、丰富的预置模型等方面的升级,我们将进一步推动大模型技术在各行各业的广泛应用,为企业智能化提供更多可能性。”
—— 谢广军
百度副总裁
“百花齐放的大模型时代呼唤着更加经济、可及的AI算力资源,通过百度智能云千帆大模型平台,用户能够快捷、高效地部署基于CPU的LLM推理服务,并发挥英特尔 至强 可扩展处理器在AI推理方面的巨大价值。我们将进一步加速大模型的生态建设与软硬件创新,助力更多的用户利用大模型推动业务创新。”
—— 陈葆立
中国区总经理
概 述
以文心大模型、Llama、GPT和ChatGLM为代表的大语言模型(LLM)展示了人工智能(AI)的惊人潜力,其在艺术创作、办公、娱乐、生产方面的广泛应用激发了新一轮的产业革命。虽然LLM在各种自然语言处理任务中表现优越,但也带来了巨量的算力资源消耗。目前机器学习开源框架如PyTorch等虽然支持基于CPU平台执行计算,但CPU上的算力并没有被充分挖掘,通用框架软件基于CPU硬件的优化程度欠佳,其推理性能并不能满足真实业务的吞吐和时延需求。
百度智能云千帆大模型平台是一个面向开发者和企业的人工智能服务平台。它为开发者提供了丰富的人工智能模型和算法,尤其是丰富的LLM支持,能够帮助用户构建各种智能应用。为了提升基于CPU的LLM推理性能,百度智能云利用英特尔 至强 可扩展处理器搭载的英特尔 高级矩阵扩展(英特尔 AMX)等高级硬件能力,助力千帆大模型平台在CPU端的推理加速。
挑战:LLM推理带来算力、资源利用率等挑战
目前开源的LLM网络结构主要以Transformer子结构为基础模块,其推理解码的过程是一个自回归的过程,当前词的生成计算依赖于所有前文的计算结果。LLM推理过程中涉及大量的、多维度的矩阵乘法计算,在不同参数量级模型、不同并发、不同数据分布等场景下,模型推理的性能瓶颈可能在于计算或者带宽,为了保证模型生成的吞吐和时延,对硬件平台的算力和访存带宽都会提出较高的要求。
目前,行业还存在大量离线的LLM应用需求,如生成文章总结、摘要、数据分析等,与在线场景相比,离线场景通常会利用平台的闲时算力资源,对于推理的时延要求不高,而对于推理的成本较为敏感,因此用户更加倾向采用低成本、易获得的CPU来进行推理。百度智能云等云平台中部署着大量基于CPU的云服务器,释放这些CPU的AI算力潜力将有助于提升资源利用率,满足用户快速部署LLM模型的需求。
此外,对于30B等规模的LLM,需要采用高规格的GPU来进行推理,普通GPU无法支持。但是,高规格的GPU的成本较高、供货紧缺,对于离线场景的用户来说不是一个理想的选择。而针对该场景,CPU不仅可以很好地支持30B及以下规模的模型,而且在性价比上更具优势。
解决方案:千帆大模型采用英特尔至强可扩展处理器加速LLM推理
百度智能云千帆大模型平台为企业提供大模型全生命周期工具链和整套环境,用户可以在百度智能云千帆上开发、训练、部署和调用自己的大模型服务。其提供智能计算基础设施、丰富的大模型、数据集和精选应用范式,以及包含数据管理、模型训练、评估和优化、推理服务部署、Prompt工程等大模型全生命周期工具链,能够显著提升模型精调效果和应用集成效率。
•覆盖大模型全生命周期:提供数据标注,模型训练与评估,推理服务与应用集成的全面功能服务;
•推理能力大幅提升:可充分释放CPU、GPU等硬件的推理性能潜力,算力利用率大幅提升,满足不同规模模型的推理所需;
•快速应用编排与插件集成:预置百度文心大模型与国内外主流大模型,支持插件与应用灵活编排,助力大模型多场景落地应用。
百度智能云千帆大模型平台可以利用百度智能云平台中丰富的英特尔 至强 可扩展处理器资源,加速LLM模型的推理,满足LLM模型实际部署的需求。
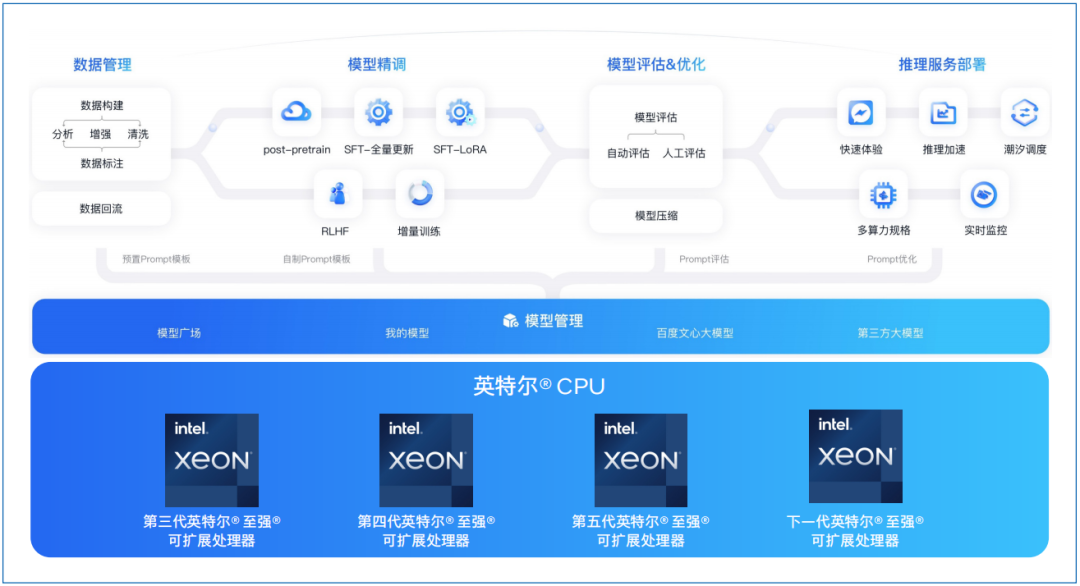
图1. 百度智能云千帆大模型平台支持的英特尔 CPU
新一代英特尔 至强 可扩展处理器通过创新架构增加了每个时钟周期的指令,有效提升了内存带宽与速度,并通过PCIe 5.0实现了更高的PCIe带宽提升。英特尔 至强 可扩展处理器提供了出色性能和安全性,可根据用户的业务需求进行扩展。借助内置的加速器,用户可以在AI、分析、云和微服务、网络、数据库、存储等类型的工作负载中获得优化的性能。通过与强大的生态系统相结合,英特尔 至强 可扩展处理器能够帮助用户构建更加高效、安全的基础设施。
第四代和第五代英特尔 至强 可扩展处理器中内置了英特尔 AMX加速器,可优化深度学习(DL)训练和推理工作负载。英特尔 AMX架构由两部分组件构成:第一部分为TILE,由8个1KB大小的2D寄存器组成,可存储大数据块。
第二部分为平铺矩阵乘法(TMUL),它是与TILE连接的加速引擎,可执行用于AI的矩阵乘法计算。英特尔 AMX支持INT8和BF16两种数据类型以满足不同精度的加速需求。AMX让英特尔 至强 可扩展处理器实现了大幅代际性能提升,与内置英特尔 高级矢量扩展512矢量神经网络指令(Intel Advanced Vector Extensions 512 Vector Neural Network Instructions,英特尔 AVX-512 VNNI)的第三代英特尔 至强 可扩展处理器 相比,内置英特尔 AMX的第四代英特尔 至强 可扩展处理器将单位计算周期内执行INT8运算的次数从256次提高至2048次,是AVX512_VNNI同样数据类型的8倍。
英特尔 至强 可扩展处理器可支持High Bandwidth Memory(HBM)内存,高带宽内存HBM和DDR5相比,具有更多的访存通道和更长的读取位宽,理论带宽可达DDR5的4倍。虽然HBM的容量相对较小(每个CPU Socket 64 GB),每个物理核心仅可以平均获得超过1GB的高带宽内存容量,但对于包括大模型推理任务在内的绝大多数计算任务,HBM可以容纳全部的权重数据,显著提升访存限制型的计算任务。经实测,在真实的大模型推理任务上可以实现明显的端到端加速。
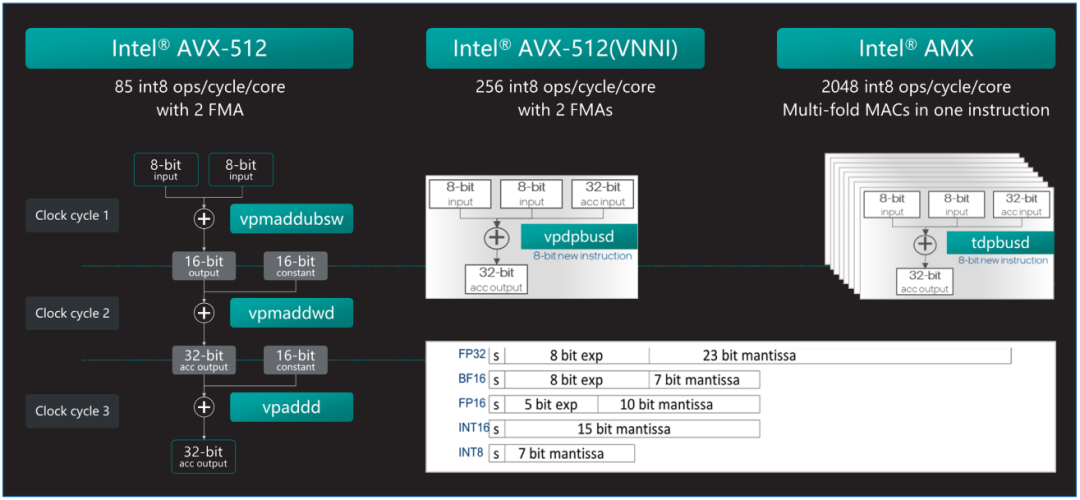
图2. 英特尔 AMX可以更高效的实现AI加速
百度智能云千帆大模型平台采用基于AMX加速器和HBM硬件特性极致优化的大模型推理软件解决方案xFasterTransformer(xFT),进一步加速英特尔 至强 可扩展处理器的LLM推理速度。软件架构的详细信息如图3所示,其具备如下优势:
•通过模型转换工具,xFT实现了对HuggingFace上开源模型格式的全面支持。
•软件的核心高性能计算库包括oneDNN、MKL以及针对LLM特别优化的计算实现,这些高性能计算库把对AMX/AVX512等加速部件的相关实现进行隐藏,上层的LLM基础算子实现以及网络层的实现都建立在此基础之上,形成了软件和硬件特性的解耦。
•最上层提供C++以及Python接口方便测试,且由于全部的核心代码均基于C++实现,因此集成进现有的框架非常便捷。
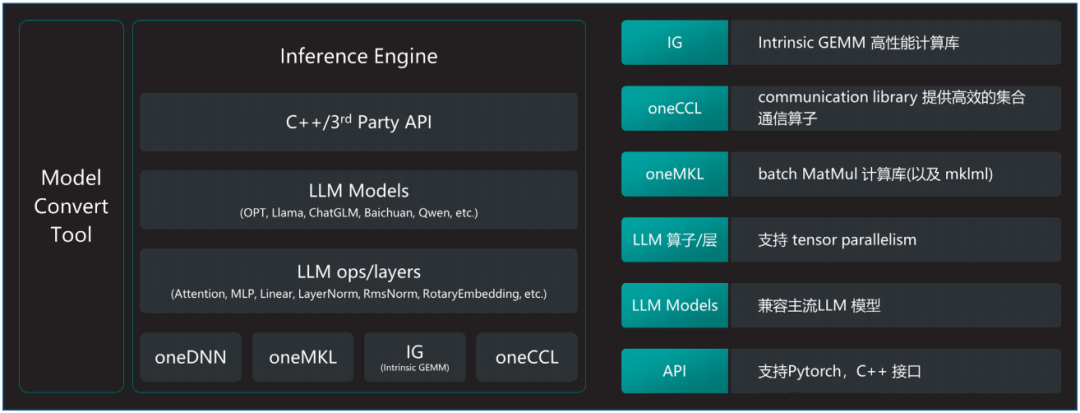
图3. 英特尔 至强 可扩展处理器LLM推理软件解决方案
具体的优化策略如下:

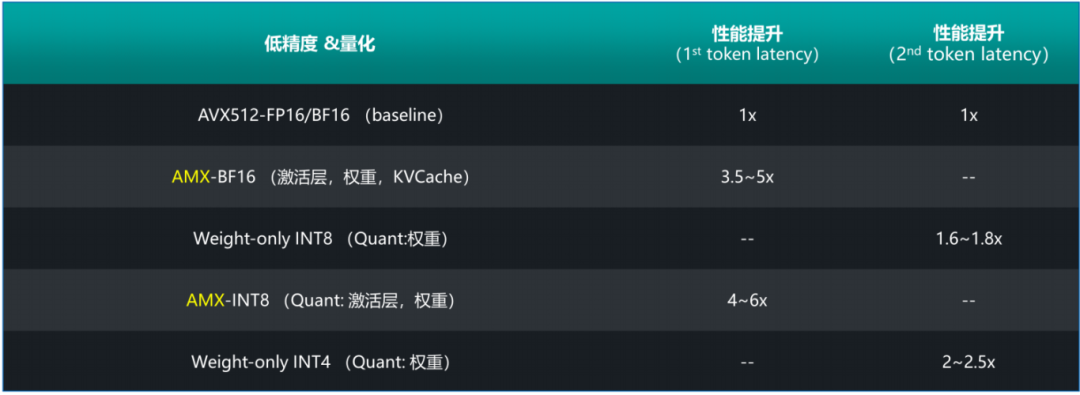
图4. 将模型转化为低精度数据格式可带来性能提升
在千帆大模型平台上实现CPU推理加速
当前千帆大模型平台已经引入了针对英特尔 至强 可扩展平台深度优化的LLM推理软件解决方案xFT,并将其作为后端推理引擎,助力用户在千帆大模型平台上实现基于CPU的LLM推理加速。目前,使用该方案针对超长上下文和长输出进行了优化,已经支持Llama-2-7B/13B,ChatGLM2-6B等模型部署在线服务(参见表1)。
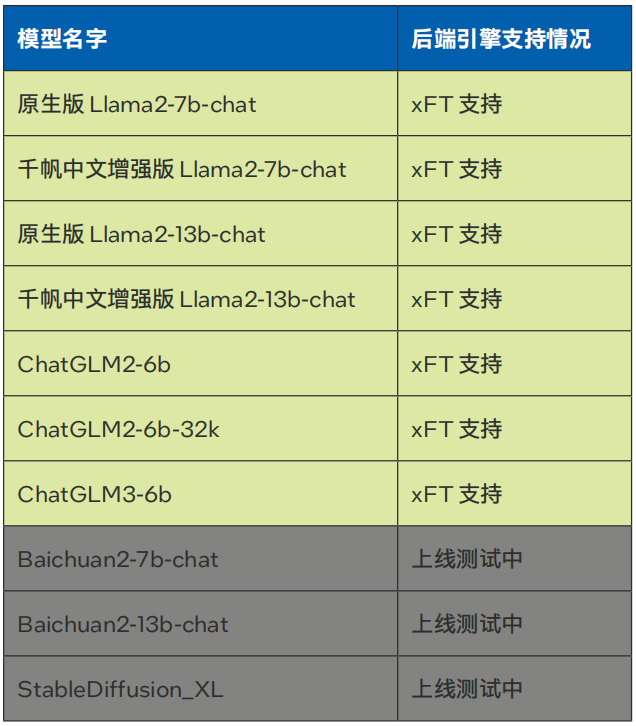
表1. 百度智能云千帆大模型平台xFasterTransformer后端支持模型种类
Llama-2-7b模型测试数据如图5和图6所示,第四代英特尔 至强 可扩展处理器上输出Token吞吐可达100TPS以上,相比第三代英特尔 至强 可扩展处理器提升了60%。在低延迟的场景,同等并发下,第四代英特尔 至强 可扩展处理器的首Token时延比第三代英特尔 至强 可扩展处理器可降低50%以上。在将处理器升级为第五代英特尔 至强 可扩展处理器之后,吞吐可提升45%左右,首Token时延下降50%左右1 。
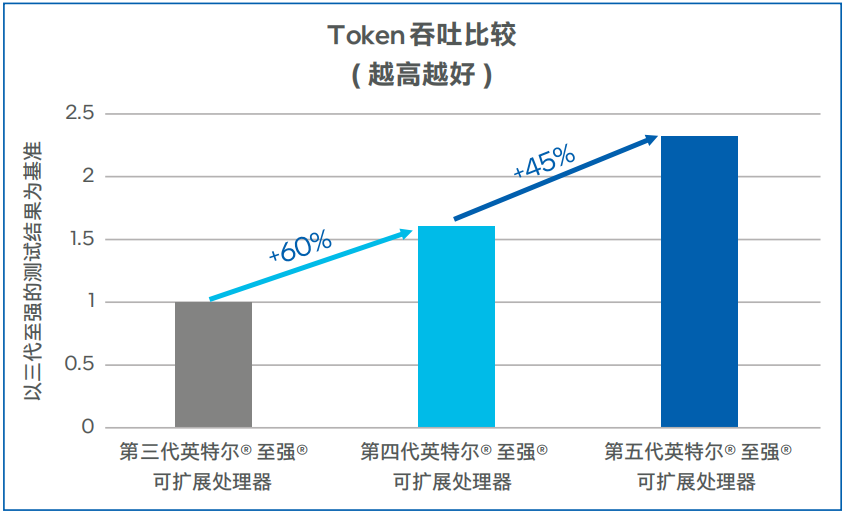
图5. Llama-2-7b模型输出Token吞吐
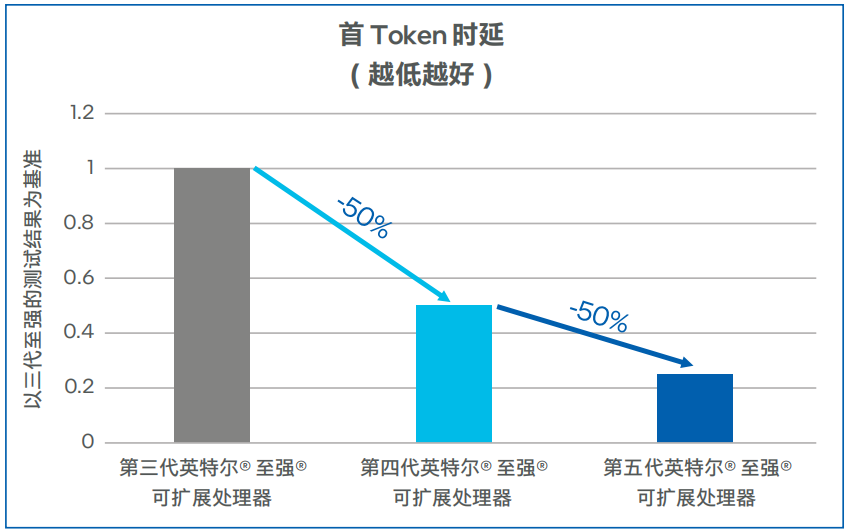
图6. Llama-2-7b模型首Token时延
方案效果
通过在千帆大模型平台中采用英特尔 至强 可扩展处理器进行LLM模型推理,方案效果如下:
•通过千帆大模型平台提供的全生命周期工具链,快速在英特尔 至强 可扩展平台中部署LLM模型推理服务;
•高效释放英特尔 至强 可扩展处理器的AI推理性能,降低LLM生成时延,提供更佳的服务体验;
•针对30B以下规模的LLM模型,皆可采用英特尔 至强 可扩展处理器结合xFT推理解决方案,获得良好性能体验;
•利用充足的CPU资源,降低对于AI加速卡的需求,从而降低LLM推理服务的总体拥有成本(TCO),特别是在离线的LLM推理场景中表现出色。
展 望
通过xFasterTransformer等软件方案,百度智能云千帆大模型平台充分利用了英特尔 至强 可扩展处理器的计算能力以及新一代AI内置加速引擎英特尔 AMX,成功解决了大模型推理中的计算密集型和访存受限型算子挑战,实现了基于CPU的LLM推理加速,助力用户更加高效地利用CPU资源。
未来,英特尔与百度将继续深化合作,推动大模型平台的发展,计划进一步优化LLM推理算法和实现,提升推理性能和计算资源效率,使得更多类型和规模的大模型能够在CPU平台上得到支持和加速。同时,双方将不断完善软硬件配套解决方案,提供更加全面和灵活的技术支持,满足用户在自然语言处理领域的不断增长的需求。
-
处理器
+关注
关注
68文章
19291浏览量
229906 -
英特尔
+关注
关注
61文章
9968浏览量
171808 -
大模型
+关注
关注
2文章
2459浏览量
2737
原文标题:看至强® 可扩展处理器如何为千帆大模型平台推理加速
文章出处:【微信号:英特尔中国,微信公众号:英特尔中国】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
英特尔携手百度智能云加速AI落地
英特尔与百度共同为AI时代打造高性能基础设施

百度智能云升级3款大模型应用:面向三类场景打造企业“超级员工”


百度智能云正式发布了《百度智能云水业大模型白皮书》

企业用大模型如何更具效价比?百度智能云发布5款大模型新品


使用基于Transformers的API在CPU上实现LLM高效推理





 工商网监
工商网监
评论